

1 判断
" ".join(["12", "12", "12"]) 会将列表 ["12", "12", "12"] 中的元素使用一个空格连接起来,
2,print("输出结果是{:08.2f}".format(14.345))
00014.35
%8d 默认右对齐包括小数点一共八位
3,在字符串前加字母r或R,表示原始字符串,其中的所有字符都表示原始的含义,而不会进行任何转义。
当你在字符串前加上 r 或 R 前缀时,Python 会将字符串中的反斜杠作为普通字符处理,而不会尝试将其解释为转义符
4,join() 方法只能用于字符串序列,也就是说,序列中的每个元素必须是字符串类型。
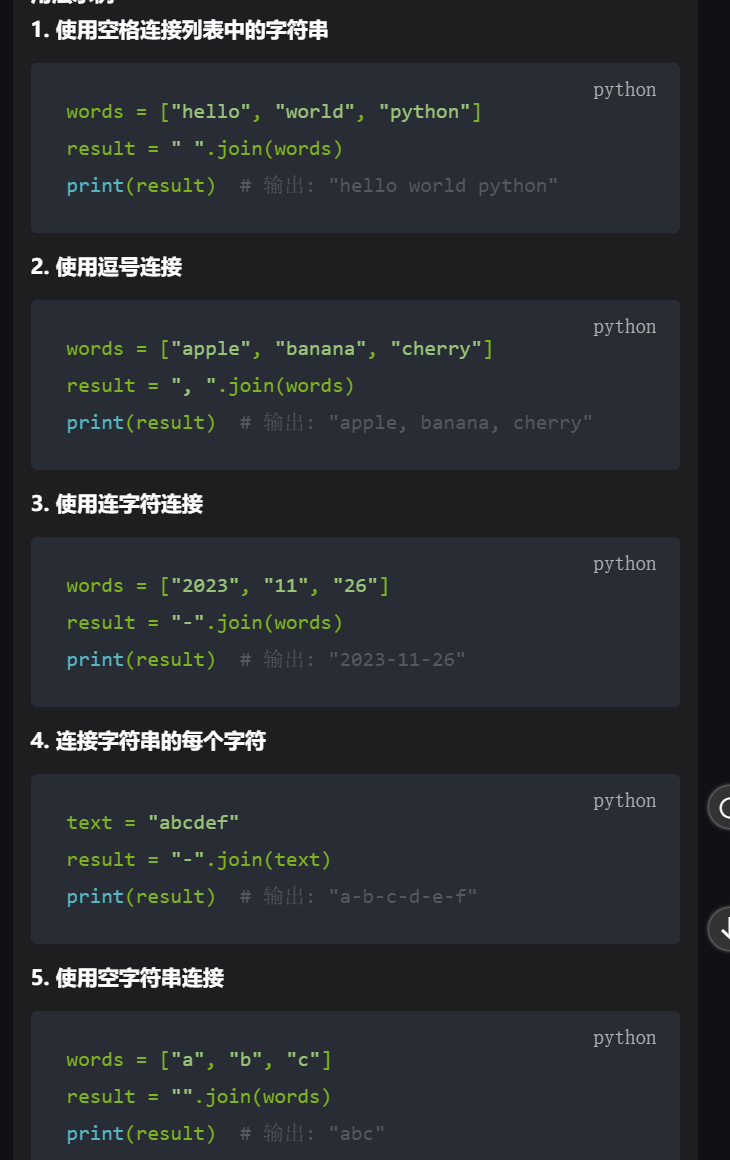
对于空序列会返回空字符串

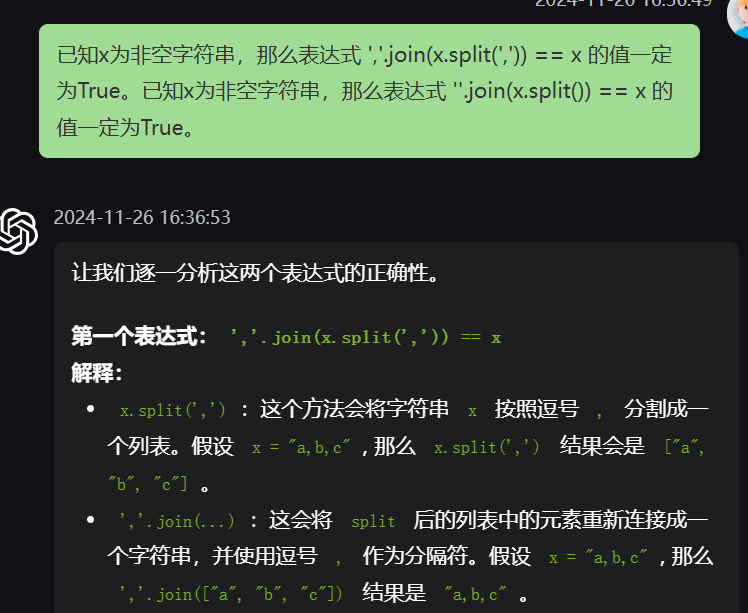
所以第一个对,第二个错
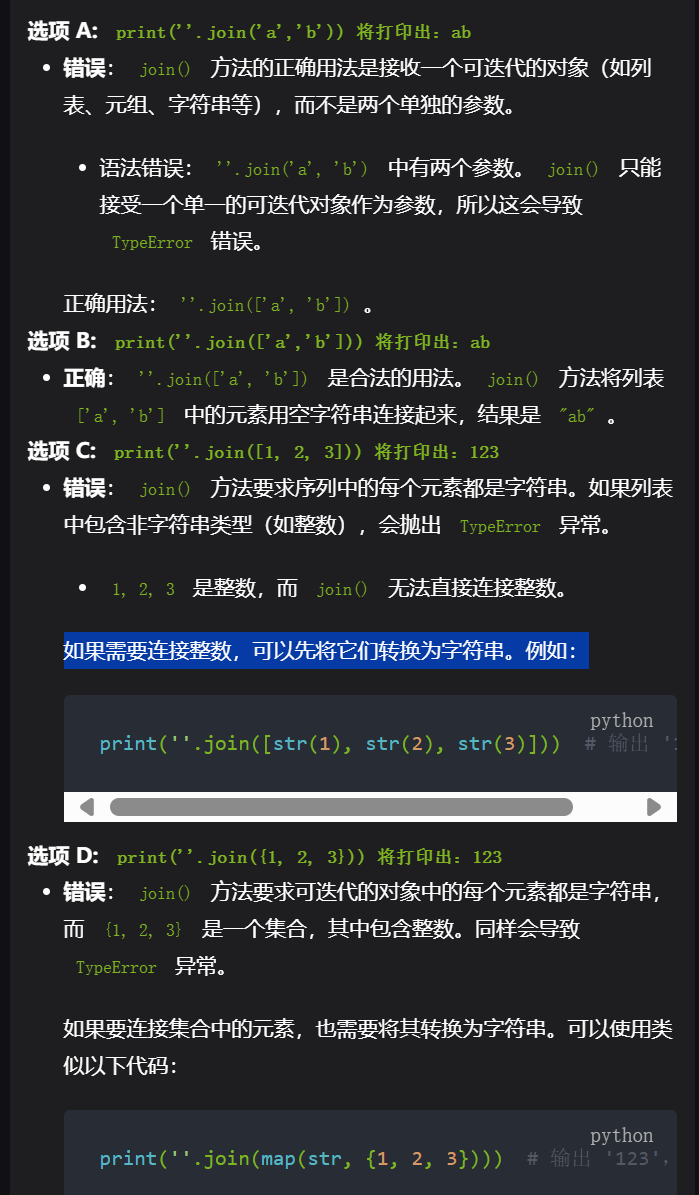
2 单选
1,当在字符串中使用特殊字符时,python使用( \ )作为转义字符.
2,字符串查找
find() 方法用于查找子字符串在主字符串中首次出现的位置。如果子字符串不存在于主字符串中,find() 方法将返回 -1。
index() 方法用于查找子字符串在主字符串中首次出现的位置。如果子字符串不存在于主字符串中,index() 方法会引发一个 ValueError 异常。
3,py没有字符串的contact方法

4,切片
str1[-6:-1]不包括-1
5,
capitalize()方法是用来将字符串将字符串首字母变为大写
title()将字符串每个单词首字母变为大写
6,格式化输出
print('{:0>10d}'.format(var))
0表示用0填充
表示右对齐
print(str(var).rjust(10, '0'))
这是将 var 转换为字符串后,使用 rjust() 方法进行右对齐,并用零填充。
print(str(var).zfill(10))
zfill() 方法用于将字符串填充为指定宽度,并且用零填充。它会在字符串的左侧填充零,直到达到指定的宽度。
7,字符串去除两端字母
strip() 方法用于去除字符串两端的字符(默认去除空白字符)。
print(var.strip('bcdfa'))
strip('bcdfa') 会从 var 的两端去除
字符集 'bcdfa' 中的任何字符。
string.ascii_lowercase 包含了所有小写字母:'abcdefghijklmnopqrstuvwxyz'。
会从 var 的两端去除所有的小写字母(包括 'a' 到 'z'),而不会影响中间的数字。
print(var.strip(string.ascii_lowercase))
print(var.strip(string.ascii_letters))
string.ascii_letters 包含了所有的字母(包括大写和小写字母):'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'。
使用 strip(string.ascii_letters) 会从 var 的两端去除所有字母(不区分大小写),因此会去除所有的字母,不仅仅是小写字母。
8,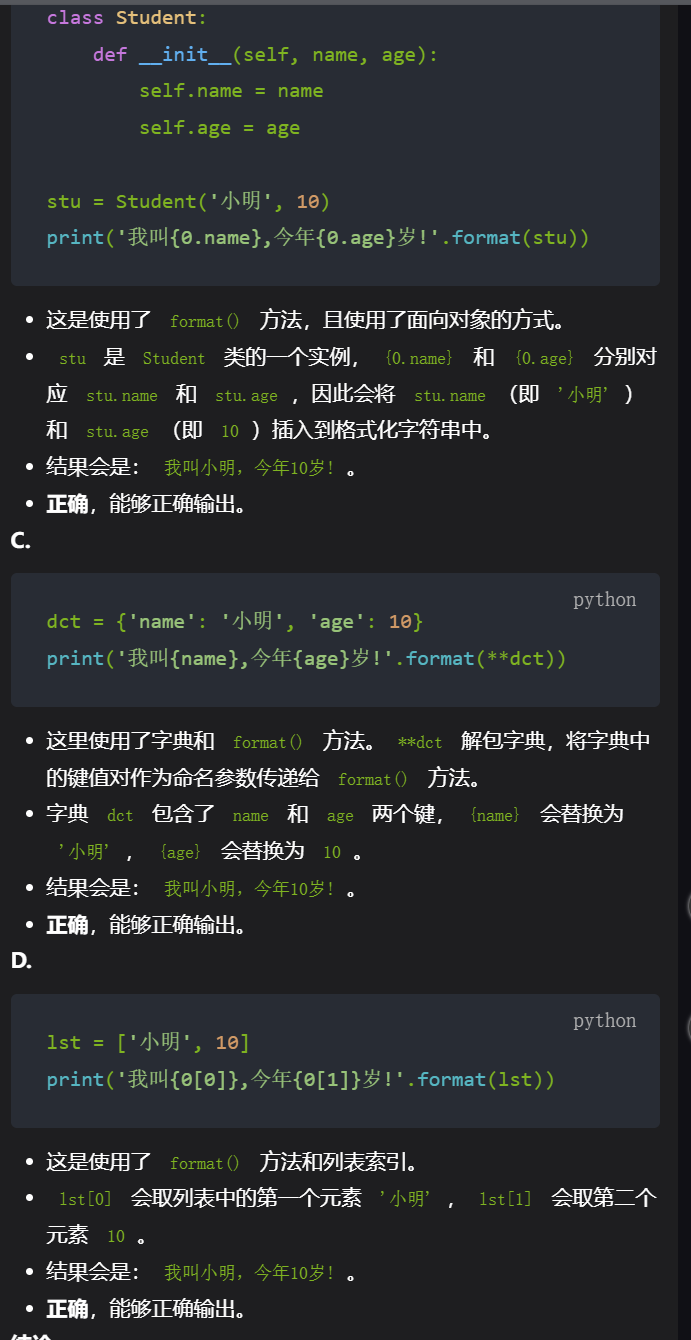
3 选择
4 填空
5 编程
1,
#输入
l=list(input().split())
#输入按空格分隔
l=[chr(int(i)) for i in input().split()]
#chr(int(i)):默认输入为字符串,先转化为数字再转化为字母
s=[c for c in input().upper() if c.isalnum()]
l.sort()
#字母升序排序
print(*l,sep='<')
'''
*l:使用星号操作符将列表 l 中的元素解包为独立的参数,即将列表中的每个元素作为单独的参数传递给 print() 函数。
sep=' ':指定在打印多个参数时,使用空格 '<' 作为分隔符,打印<。
'''
2),回文
s=[c for c in input().upper() if c.isalnum()]
#仅保留那些是字母数字(英文字符或数字)的字符,
#过滤掉空格、标点符号等非字母数字字符
if s == s[::-1]:
#原列表 s 是否与它的反向列表相等,相等则代表是回文串
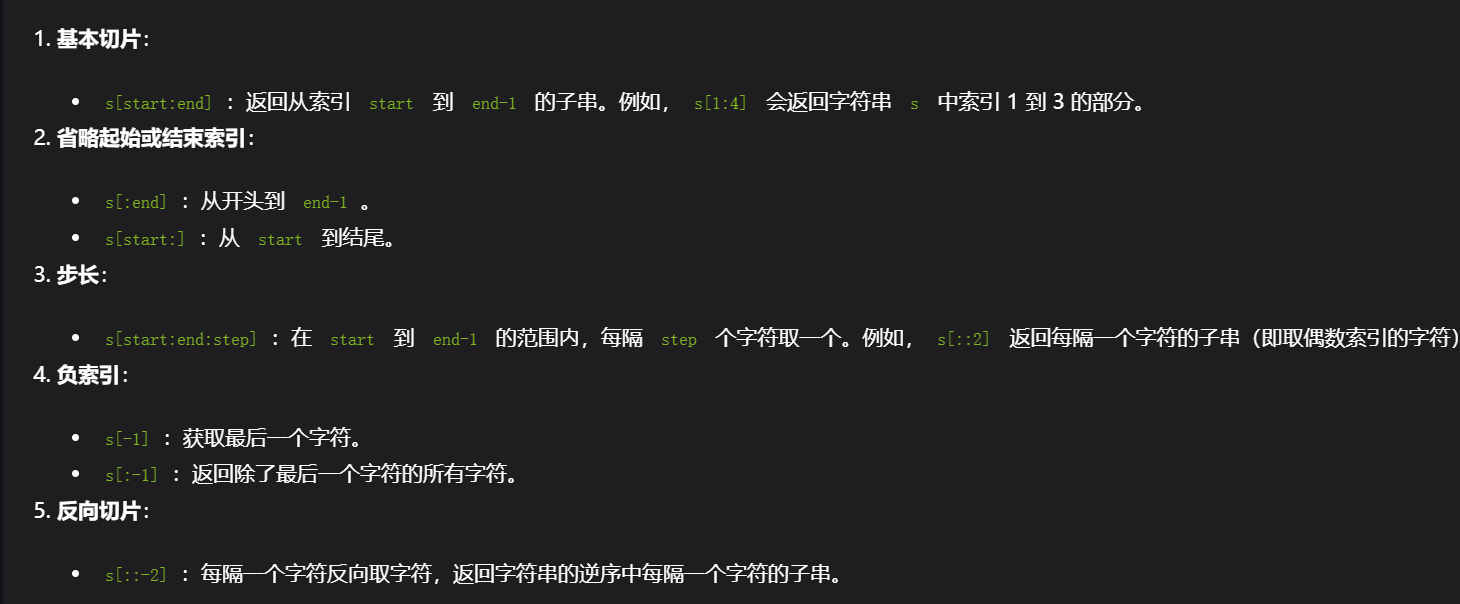
3),切片操作
切片操作 [:]
s[::-1]实现逆序
s[2::]去除前两位
4)删除字符
s=input().strip()
c=input().strip()
#开头和结尾的空白字符
if c.isalpha():
s=s.replace(c.upper(),'').replace(c.lower(),'')
//如果是字母,移除所有大小写
else:
s=s.replace(c,'')
#不是字母直接移除
print("result: %s" %(s))
5)元素最后出现的位置
l=list(input())
c=max(l)
#字典序的最大字符
p=len(l)-1-l[::-1].index(c)
#l[::-1].index(c) 找到反向列表中字符 c 的第一个出现位置
#en(l) - 1 是计算列表的最后一个索引。
#字符 c 在原列表中的最后出现位置。
print("%c %d" %(c,p))
6)最长元素长度
n,l=int(input()),[]
#l被初始化为空列表
for i in range(n):
l.append(input().strip())
#去除首尾空格后添加到列表中
l.sort(key=len,reverse=True)
#指定排序的关键字为字符串的长度,reverse=True
#表示按降序排列
print("length=%d" % len(l[0]))
7),二进制统计01个数
n=int(input())
s=bin(n).lstrip('0')
#转化为二进制,去除左端所有0
print(s.count('1'),s.count('0'))
8)二进制相加
a=int(input())
b=int(input())
s1=bin(a)[2::]
s2=bin(b)[2::]
s3=bin(a+b)[2::]
#去掉前缀 '0b',只保留二进制部分
print("%08d" % int(s1))
print("%08d" % int(s2))
print('-'*8)
#打印一个横线,08d表示至少8位
print("%08d" % int(s3))
9)map自动使用int
# x, y = map(int, input().split()) # 将输入的两个值转换为整数
# # 计算 x 和 y 的异或结果,并统计其二进制表示中 '1' 的个数
# print(bin(x ^ y).count('1'))
x,y=input().split()
#默认就是字符串类型,这时不需要map
print(bin(int(x)^int(y)).count('1'))
def hanming(x,y):
return bin(x^y).count('1')
x,y=map(int,input().split())
#会对 input().split() 生成的字符串列表
#中的每个元素应用 int 函数,这样更方便
print(hanming(x,y)
10)进制转化
l,l1,l2=list(input()),"0123456789abcdeABCDEF",""
#读取一个字符,初始化l1为所有合法字符,l2为空字符
for c in l:
if c in l1:
l2+=c
n1=l2.lower()
n2=int(n1,16)
#十六进制字符串 n1 转换为十进制整数 n2。
n3=oct(n2)[2::]
# 将十进制数 n2 转换为八进制字符串,结果会以 '0o' 开头
#通过 [2::] 切片去掉前缀,只保留八进制数的部分。
n4=bin(n2)[2::]
#bin(n2) 将十进制数 n2 转换为二进制字符串,
#结果同样会以 '0b' 开头。使用 [2::] 切片去掉前缀。
print(n1,n2,n3,n4)
s=hex(int(input()))
#转换为十六进制字符串,格式为0x
s.count(c)
#字符串中c出现的次数
11)split默认返回列表
l=list(input().split())
# l = [input().split()]
# split默认返回列表如果加中括号会变成[['1','2']]
#输入按空格分隔
l.sort()
#字母升序排序
print(*l,sep=' ',end='')
'''
*l:使用星号操作符将列表 l 中的元素解包为独立的参数,即将列表中的每个元素作为单独的参数传递给 print() 函数。
sep=' ':指定在打印多个参数时,使用空格 ' ' 作为分隔符。
'''

