
基于低位嵌入的音频数字水印
文献中提到的方式是要将音频信号分帧,再做离散小波变换、离散余弦变换等,但分帧后的数据为一维矩阵,按此类型将无法继续进行变换(只能通过矩阵变换处理)文献中并未提及后续处理的解决办法。
本次尝试基于矩阵分割合并,在音频数据特定某段的低位嵌入图像信息,原则上只要保持二值化对应数值的相对大小就可以实现提取,至于嵌入位置也可以随机选取,只要长度适宜。
之所以没有采用最低有效位,是因为在float32格式下,较低位信息提取困难。
嵌入部分:
import librosa import numpy as np import soundfile import cv2 # 图像嵌入的尺寸 w = 100 h = 100 # 读入二值化图像 waterImg = cv2.imread("C:\\Users\\2value.bmp", 0) waterImg = cv2.resize(waterImg, (w, h)) y, sr = librosa.load("C:\\Users\\split.wav") Y = np.split(y, (w*h, )) y1 = Y[0] # y2 = Y[1] # print(y1.shape) # print(y2.shape) Y1 = y1.reshape(w, h) for i in range(w): for j in range(h): if waterImg[i][j] == 255: Y1[i][j] = Y1[i][j] + 0.1**4 else: Y1[i][j] = Y1[i][j] - 0.1**4 y1_new = Y1.reshape(w*h) y = np.hstack((y1_new, y2)) soundfile.write("C:\\Users\\new.wav", y, sr)
提取部分
import librosa import numpy as np from PIL import Image y1, sr1 = librosa.load("C:\\Users\\split.wav") y2, sr2 = librosa.load("C:\\Users\\new.wav") w = 100 h = 100 Y1 = np.split(y1, (w*h, )) Y2 = np.split(y2, (w*h, )) Y1_1 = Y1[0] Y2_1 = Y2[0] Y1 = Y1_1.reshape(w, h) Y2 = Y2_1.reshape(w, h) newImg = np.zeros((w, h), dtype='uint8') for i in range(w): for j in range(h): if (Y1[i][j] > Y2[i][j]): newImg[i][j] = 0 elif(Y1[i][j] <= Y2[i][j]): newImg[i][j] = 255 waterImg = Image.fromarray(newImg) waterImg = waterImg.resize((w, h), Image.ANTIALIAS) waterImg = waterImg.convert("L") waterImg.save('C:\\Users\\audio.bmp')
结果示例
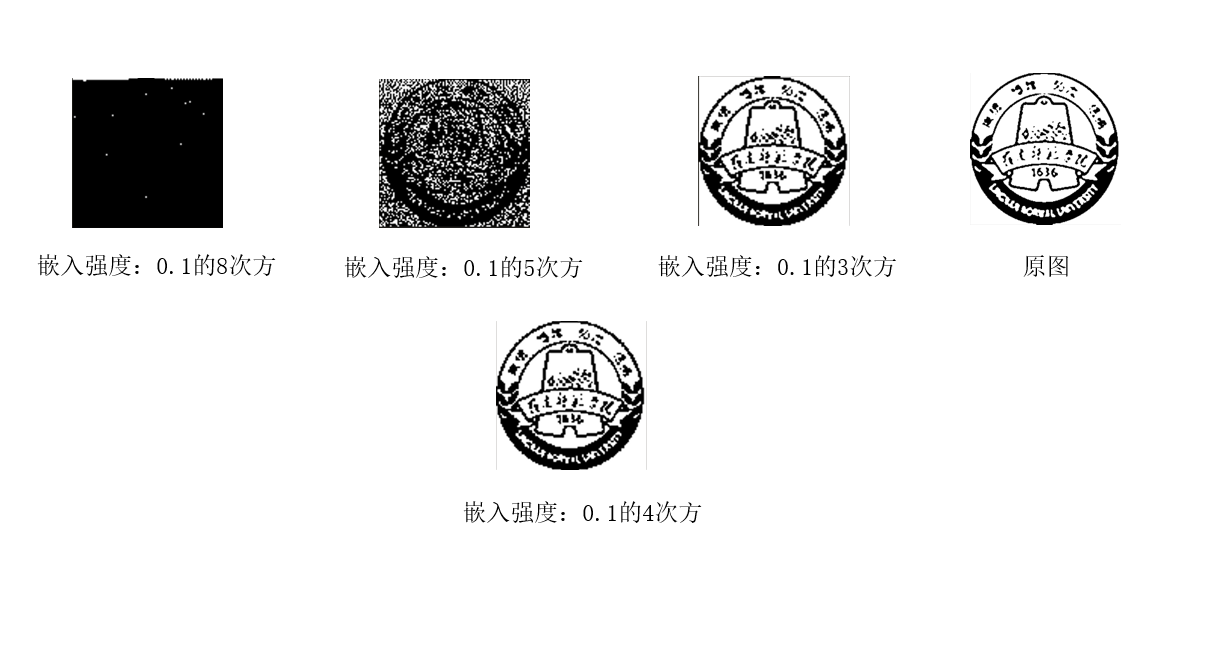
嵌入强度为0.1的4次方时综合效果最好。
代码中采用的音频读写方式会丢失双声道信息。
y, sr = librosa.load("C:\\Users\\split.wav",mono=False)
可以添加参数获取双声道数据,但双声道写入音频的方式暂时还没找到。
除了这种针对音频信息矩阵变换的方式,同理也可以将水印图像进行降维处理然后嵌入音频数据当中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号