YOLO V5
网络结构
网络结构主要由以下几个部分组成:
-
Backbone:
New CSP-Darknet53 -
Neck:
SPPF, New CSP-PAN -
Head:
Yolov3 Head下图是yolov5l的网络结构:
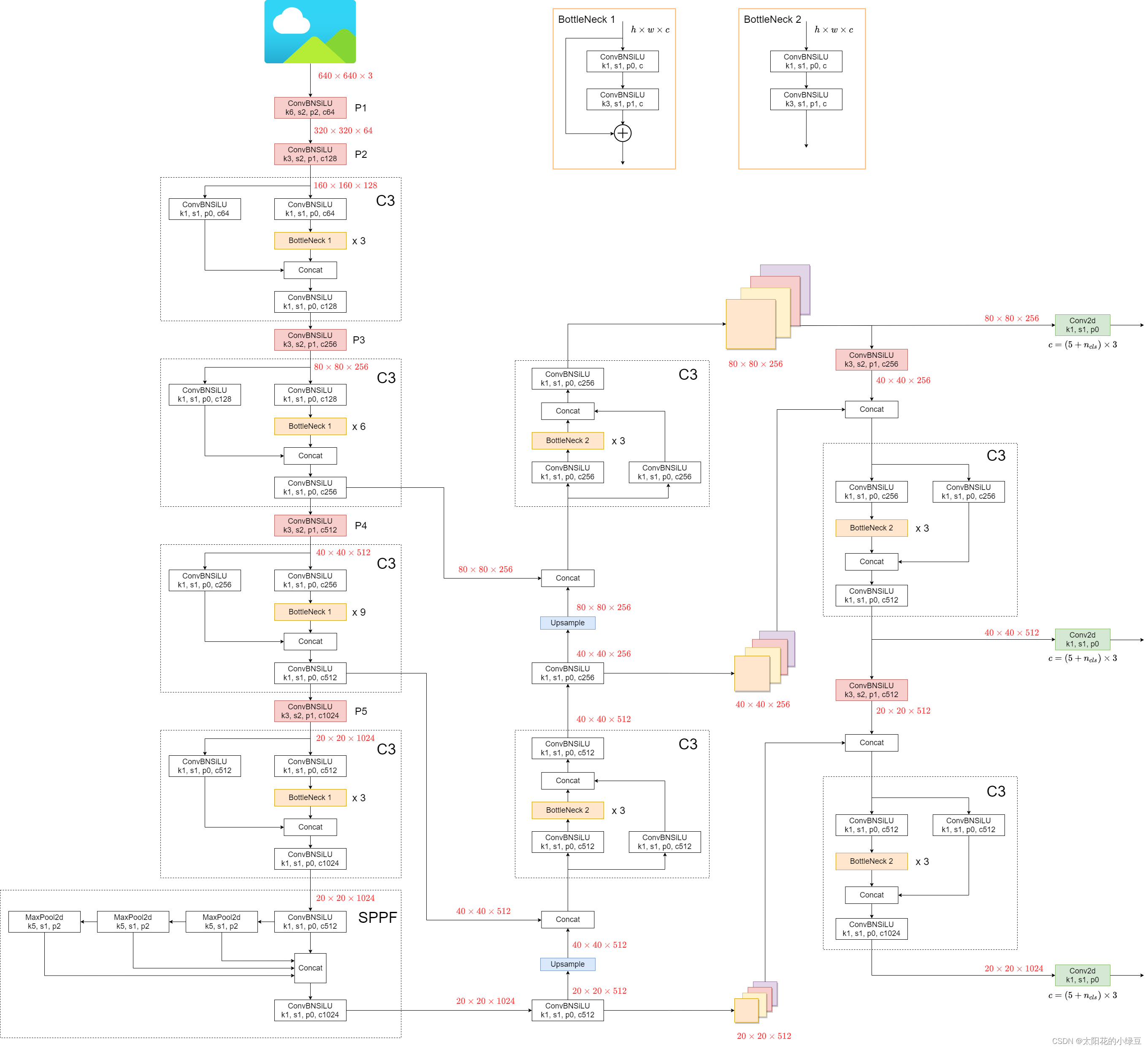
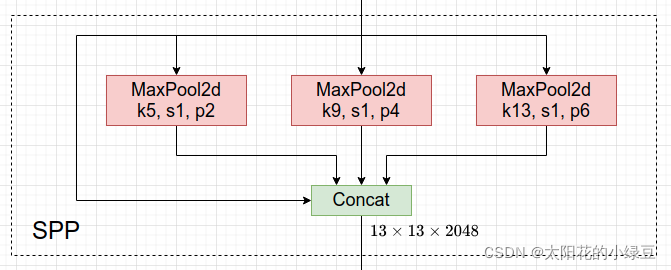
在Neck部分,作者将SPP换为了SPPF,两者作用相同,但后者效率更高。SPP结构如下,是将输入并行通过多个不同大小的Maxpool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
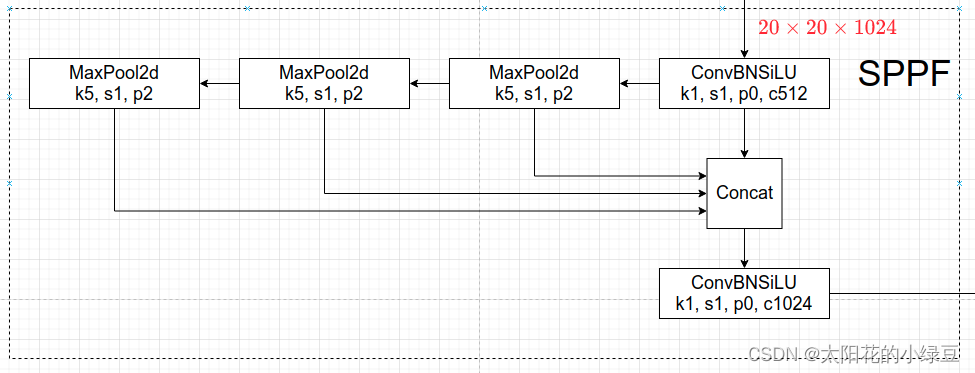
而在SPPF中,是将输入串行通过多个5x5大小的Maxpool层,这里需要注意的是串行两个5x5大小的Maxpool层和一个9x9大小的Maxpool层计算结果是一样的,串行3个5x5大小的Maxpool层和一个13x13大小的Maxpool层计算结果是一样的。
数据增强
- Mosaic : 将四张图片合成为一张图片
- Copy paste :将部分目标随机的粘贴到图片中,前提是数据要有
segments数据才行,即每个目标的实例分割信息。 - Random affine(Rotation, Scale, Translation, Shear):随机进行仿射变换
- Mixup :将两张图片按照一定的透明度融合在一起
- Albumentations:滤波、直方图均衡化、改变图片质量
- Agument HSV(Hue, Saturation, Value):随机调整色度、饱和度以及明度
- Random horizontal filp : 随机水平翻转
训练策略
- Multi-scale training(0.5~1.5x),多尺度训练,假设设置输入图片的大小为640 × 640 640 \times 640640×640,训练时采用尺寸是在0.5 × 640 ∼ 1.5 × 640 0.5 \times 640 \sim 1.5 \times 6400.5×640∼1.5×640之间随机取值,注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)。
- AutoAnchor(For training custom data),训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成Anchors模板
- Warmup and Cosine LR scheduler,训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。
- EMA(Exponential Moving Average),可以理解为给训练的参数加了一个动量,让它更新过程更加平滑。
- Mixed precision,混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。
- Evolve hyper-parameters,超参数优化,没有炼丹经验的人勿碰,保持默认就好。
损失计算
yolo v5 的损失主要由3各部分组成:
-
Classes loss: 分类损失,采用的是BCE loss,注意只计算正样本的分类损失
-
Objectness loss: obj损失,采用的也是BCE loss,这里的
obj指的是网络预测的目标边界框与GT Box的CIoU。 -
Location loss: 定位损失,采用的是CIou loss,注意只计算正样本的定位损失。
\[\text { Loss }=\lambda_1 \mathrm{~L}_{\mathrm{cls}}+\lambda_2 \mathrm{~L}_{\mathrm{obj}}+\lambda_3 \mathrm{~L}_{\mathrm{loc}} \]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号