yolo v3
前言
相较于yolo v2,作者在v2基础上做了一些改进。一是特征提取部分采用darknet-53代替了原来的darknet-19,利用特征金字塔网络实现了多尺度检测,分类方法用逻辑回归代替了softmax。做到了又快有准。
Darknet-53
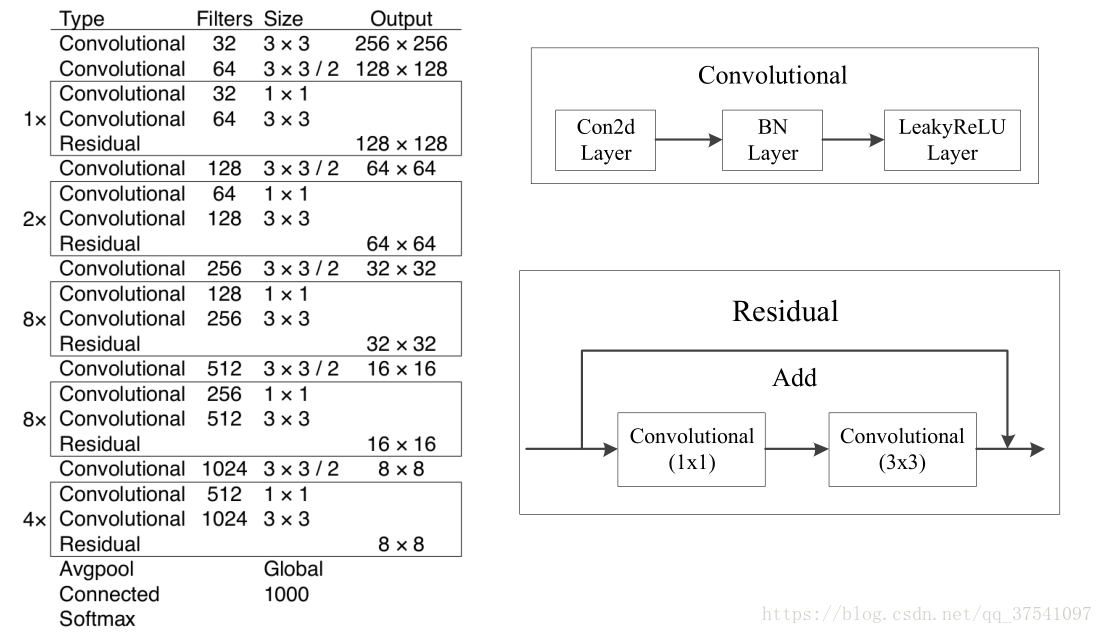
如上图所示:Darknet-53主要是由一系列的1x1和3x3的卷积层组成(每个卷积层后都会跟一个BN层和一个LeakyReLU层)。
yolo v3模型结构
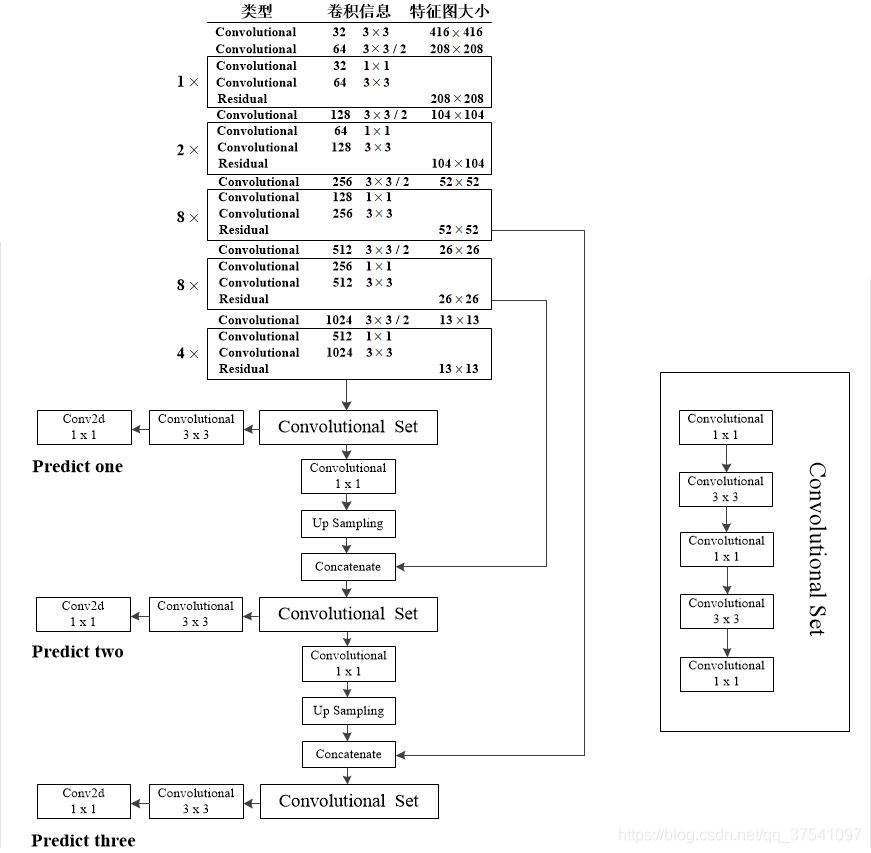
从上图可以看出,yolo v3输出了三个不同大小的特征图,从上到下分别对应深层、中层和浅层的特征。深层的特征尺寸小,感受野大,有利于检测大尺度物体,而浅层的特征图则与之相反,更便于检测小尺度物体,这一点类似于FPN结构。
YOLOv3依然沿用了预选框Anchor,由于特征图数量不再是一个,因此匹配方法也要相应地进行改变。具体做法是:依然使用聚类算法得到9中不同大小宽高的先验框,然后按照下图所示的方法进行先验框的分配,这样,每一个特征图上的一个点只需要3个先验框,而不是YOLOv2中的5个。


由于这每一层的特征图都会预测3中尺寸不同的边界框,而每一个边界框有x,y,w,h,confidence一共5个参数,而且边界个网格还需要预测80中类别信息(coco数据集有80类),对于nxn的特征矩阵,也就是nxn个网格,所以网络输出的张量应该是:N ×N ×[3∗(4 + 1 + 80)]。
yolo v3损失函数
yolo v3 的损失函数只要分为3个部分:目标定位损失\(\mathrm{L}_{\mathrm{loc}}(\mathrm{t}, \mathrm{g})\),目标置信度损失\(\mathrm{L}_{\text {conf }}(\mathrm{o}, \mathrm{c})\)和目标分类损失\(\mathrm{L}_{\mathrm{cla}}(\mathrm{O}, \mathrm{C})\)。其中\(\lambda_1, \lambda_2, \lambda_3\)是平衡系数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号