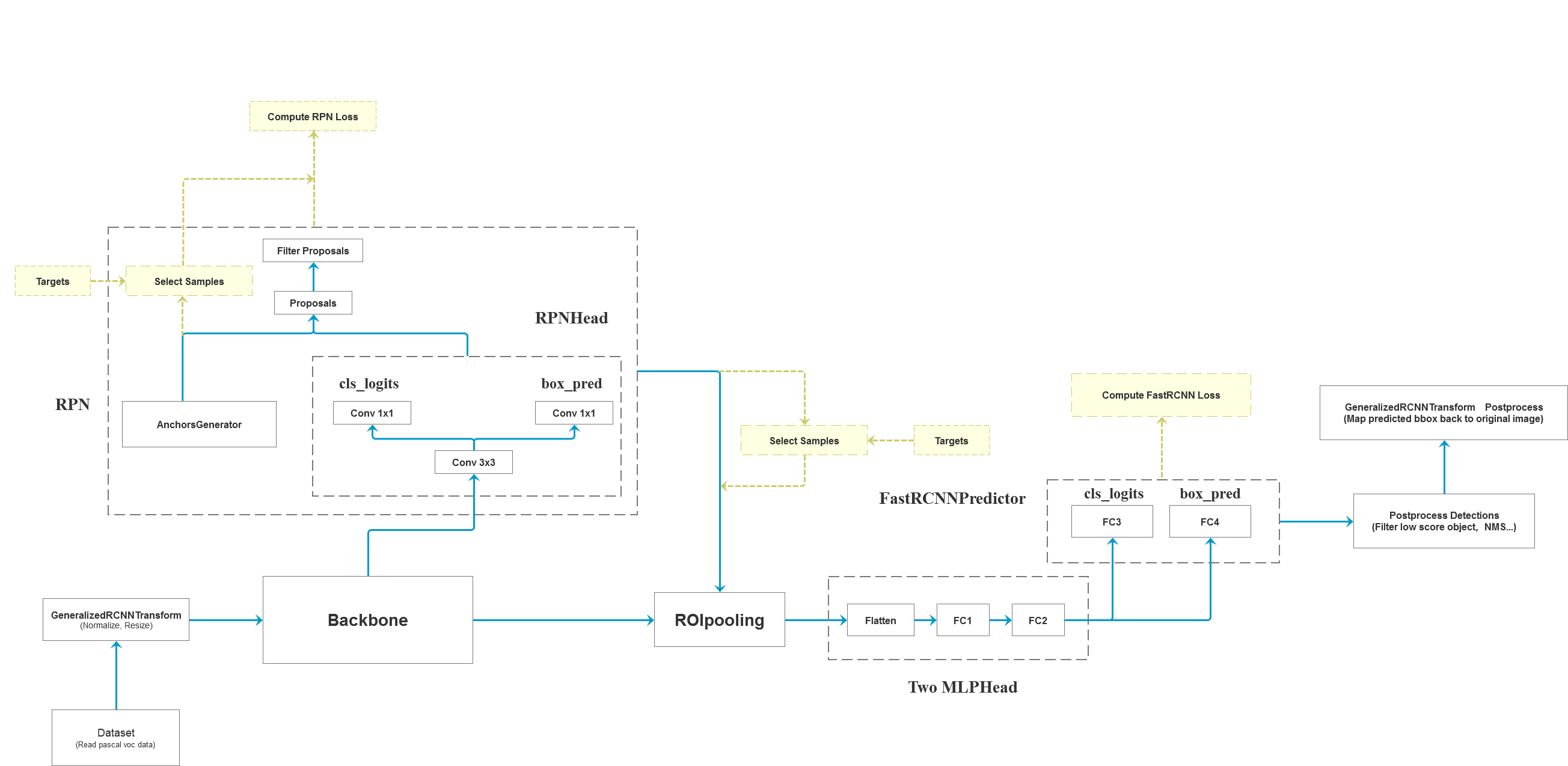
Faster R-CNN 代码解析
网络
def forward(self,
images, # type: List[Tensor]
targets=None # type: Optional[List[Dict[str, Tensor]]]
):
# type: (...) -> Tuple[ImageList, Optional[List[Dict[str, Tensor]]]]
images = [img for img in images]
for i in range(len(images)):
image = images[i] #
target_index = targets[i] if targets is not None else None
if image.dim() != 3:
raise ValueError("images is expected to be a list of 3d tensors "
"of shape [C, H, W], got {}".format(image.shape))
image = self.normalize(image) # 对图像进行标准化处理
image, target_index = self.resize(image, target_index) # 对图像和对应的bboxes缩放到指定范围
images[i] = image
if targets is not None and target_index is not None:
targets[i] = target_index
# 记录resize后的图像尺寸
image_sizes = [img.shape[-2:] for img in images] # ([3,1066,800])...
images = self.batch_images(images) # 将images打包成一个batch
image_sizes_list = torch.jit.annotate(List[Tuple[int, int]], []) # ([8,3,1216,1088])
for image_size in image_sizes:
assert len(image_size) == 2
image_sizes_list.append((image_size[0], image_size[1]))
image_list = ImageList(images, image_sizes_list)
return image_list, targets
def normalize(self, image):
"""标准化处理"""
dtype, device = image.dtype, image.device
mean = torch.as_tensor(self.image_mean, dtype=dtype, device=device)
std = torch.as_tensor(self.image_std, dtype=dtype, device=device)
# [:, None, None]: shape [3] -> [3, 1, 1]
return (image - mean[:, None, None]) / std[:, None, None]
def batch_images(self, images, size_divisible=32):
# type: (List[Tensor], int) -> Tensor
"""
将一批图像打包成一个batch返回(注意batch中每个tensor的shape是相同的)
Args:
images: 输入的一批图片
size_divisible: 将图像高和宽调整到该数的整数倍
Returns:
batched_imgs: 打包成一个batch后的tensor数据
"""
if torchvision._is_tracing():
# batch_images() does not export well to ONNX
# call _onnx_batch_images() instead
return self._onnx_batch_images(images, size_divisible)
# 分别计算一个batch中所有图片中的最大channel, height, width
max_size = self.max_by_axis([list(img.shape) for img in images])
stride = float(size_divisible)
# max_size = list(max_size)
# 将height向上调整到stride的整数倍 -- 向上靠近32的倍数
max_size[1] = int(math.ceil(float(max_size[1]) / stride) * stride)
# 将width向上调整到stride的整数倍
max_size[2] = int(math.ceil(float(max_size[2]) / stride) * stride)
# [batch, channel, height, width] list 合并
batch_shape = [len(images)] + max_size
# 创建shape为batch_shape且值全部为0的tensor
batched_imgs = images[0].new_full(batch_shape, 0)
for img, pad_img in zip(images, batched_imgs):
# 将输入images中的每张图片复制到新的batched_imgs的每张图片中,对齐左上角,保证bboxes的坐标不变
# 这样保证输入到网络中一个batch的每张图片的shape相同
# copy_: Copies the elements from src into self tensor and returns self
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
return batched_imgs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号