地平线轨迹预测 QCNet 参考算法-V1.0
该示例为参考算法,仅作为在 征程6 上模型部署的设计参考,非量产算法。
01 简介
轨迹预测任务的目的是在给定历史轨迹的情况下预测未来轨迹。这项任务在自动驾驶、智能监控、运动分析等领域有着广泛应用。传统方法通常直接利用历史轨迹来预测未来,而忽略了预测目标的上下文或查询信息的影响。这种忽视可能导致预测精度的下降,特别是在复杂场景中。
QCNet(Query-Centric Network)引入了一种 query-centric 的预测机制,通过对查询进行显式建模,增强了对未来轨迹的预测能力。首先,通过处理所有场景元素的局部时空参考框架和学习独立于全局坐标的表示,可以缓存和复用先前计算的编码,另外不变的场景特征可以在所有目标 agent 之间共享,从而减少推理延迟。其次,使用无锚点查询来周期性检测场景上下文,并且在每次重复时解码一小段未来的轨迹点。这种基于查询的解码管道将无锚方法的灵活性融入到基于锚点的解决方案中,促进了多模态和长期时间预测的准确性。
本文将介绍轨迹预测算法 QCNet 在地平线 征程6 平台上的优化部署。
02 性能精度指标
模型参数:

性能精度表现:

03 公版模型介绍
由于轨迹预测的归一化要求,现有方法采用以 agent 为中心的编码范式来实现空间旋转平移不变性,其中每个代理都在由其当前时间步长位置和偏航角确定的局部坐标系中编码。但是观测窗口每次移动时,场景元素的几何属性需要根据 agent 最新状态的位置重新归一化,不断变化的时空坐标系统阻碍了先前计算编码的重用,即使观测窗口存在很大程度上的重叠。为了解决这个问题, QCNet 引入了以查询为中心的编码范式,为查询向量派生的每个场景元素建立一个局部时空坐标系,并在其局部参考系中处理查询元素的特征。然后,在进行基于注意力的场景上下文融合时,将相对时空位置注入 Key 和 Value 元素中。下图展示了场景元素的局部坐标系示例:
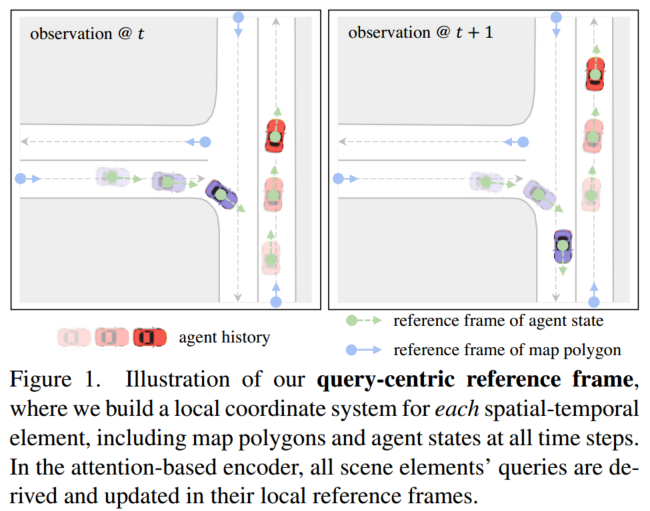
QCNet 主要由编码器和解码器组成,其作用分别为:
- 编码器:对输入的场景元素进行编码,采用了目前流行的 factorized attention 实现了时间维度 attention、Agent-Map cross attention 和 Agent与Agent 间隔的 attention;
- 解码器:借鉴 DETR 的解码器,将编码器的输出解码为每个目标 agent 的 K 个未来轨迹。
3.1 以查询为中心的场景上下文编码
QCNet 首先进行了场景元素编码、相对位置编码和地图编码,对于每个 agent 状态和 map 上的每个采样点,将傅里叶特征与语义属性(例如:agent 的类别)连接起来,并通过 MLP 进行编码,为了进一步生成车道和人行横道的多边形级表示,采用基于注意力的池化对每个地图多边形内采样点进行。这些操作产生形状为[A, T, D]的 agent 编码和形状为[M, D]的 map 编码,其中 D 表示隐藏的特征维度。为了帮助 agent 编码捕获更多信息,编码器还考虑了跨 agent 时间 step、agent 之间以及 agent 与 map 之间的注意力并重复多次。如下图所示:

3.2 基于查询的轨迹解码
轨迹预测的第二步是利用编码器输出的场景编码来解码每个目标 agent 的 K 个未来轨迹。受目标检测任务的启发,采用类似 detr 的解码器来处理这种一对多问题,并且利用了一个递归的、无锚点的 proposal 模块来生成自适应轨迹锚点,然后是一个基于锚点的模块,进一步完善初始 proposals。相关流程如下所示:
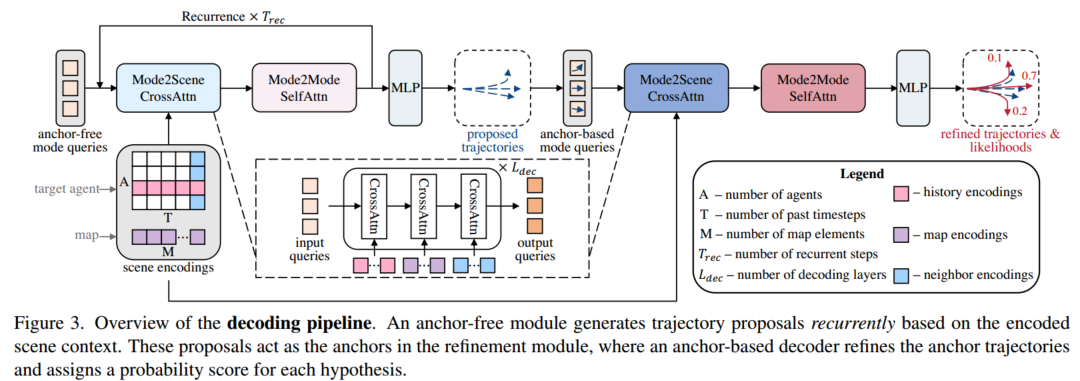
04 地平线部署优化
整体情况:
QCNet 网络主要由 MapEncoder, AgentEncoder, QCDecoder 构成,其中 MapEncoder 计算地图元素 embedding,AgentEncoder 计算 agent 元素 embedding,核心组件为 FourierEmbedding 和 AttentionLayer。
改动点:
- 优化 FourierEmbedding 结构,去除其中的所有 edge_index,直接计算形状为[B, lenq, lenk, D]的相对信息 r;
- 将 AttentionLayer 中的 query 形状设为[B, lenq, 1, D] , key 形状为[B, 1, lenk, D], r 形状为[B, lenq, lenk, D],利于性能提升;
4.1 性能优化
4.1.1 代码重构
FourierEmbedding 将每个场景元素的极坐标转换成傅里叶特征,以方便高频信号的学习。但是公版 QCNet 使用了大量 edge_index 索引操作, 使得模型中存在大量 BPU 暂不支持的 index_select、scatter 等操作。QCNet 参考算法重构了代码,去除了 FourierEmbedding 中的所有 edge_index,agent_encoder 编码器注意力层的 query 形状设为[B, lenq, 1, D] , key 形状为[B, 1, lenk, D], r 形状为[B, lenq, lenk, D],相关代码如下所示:
def _attn_block(
self,
x_src,
x_dst,
r,
mask=None,
extra_1dim=False,
):
B = x_src.shape[0]
if extra_1dim:
...
else:
if x_src.dim() == 4 and x_dst.dim() == 3:
lenq, lenk = x_dst.shape[1], x_src.shape[2]
kdim1 = lenq
qdim = 1
elif x_src.dim() == 3:
kdim1 = qdim = 1
lenq = x_dst.shape[1]
lenk = x_src.shape[1]
#重构q,k,v,rk,rv的shape
q = self.to_q(x_dst).view(
B, lenq, qdim, self.num_heads, self.head_dim
) # [B,pl, 1, h, d]
k = self.to_k(x_src).view(
B, kdim1, lenk, self.num_heads, self.head_dim
) # [B,pl, pt, h, d]
v = self.to_v(x_src).view(
B, kdim1, lenk, self.num_heads, self.head_dim
) # [B,pl, pt, h, d]
if self.has_pos_emb:
rk = self.to_k_r(r).view(
B, lenq, lenk, self.num_heads, self.head_dim
)
rv = self.to_v_r(r).view(
B, lenq, lenk, self.num_heads, self.head_dim
)
if self.has_pos_emb:
k = k + rk
v = v + rv
#计算相似性
sim = q * k
sim = sim.sum(dim=-1)
#self.scale = head_dim ** -0.5
sim = sim * self.scale # [B, pl, pt, h]
if mask is not None:
sim = torch.where(
mask.unsqueeze(-1),
sim,
self.quant(torch.tensor(-100.0).to(mask.device)),)
attn = torch.softmax(sim, dim=-2) # [B, pl, pt, h]
...
if extra_1dim:
inputs = out.view(B, ex_dim, -1, self.num_heads * self.head_dim)
else:
inputs = out.view(B, -1, self.num_heads * self.head_dim)
x = torch.cat([inputs, x_dst], dim=-1)
g = torch.sigmoid(self.to_g(x))
#重构代码后,edge_index也就不需要了,省去了仅能用CPU运行的索引类算子
#agg = self.propagate(edge_index=edge_index, x_dst=x_dst, q=q, k=k, v=v, r=r)
agg = inputs + g * (self.to_s(x_dst) - inputs)
return self.to_out(agg)
代码路径:`/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/rattention.py
4.1.2 FourierConvEmbedding
为了提升性能,主要对 FourierConvEmbedding 做了以下改进:
- Embedding 和 Linear 层全部替换为了对 BPU 更友好的 Conv1x1;
- 删除 self.mlps 层中的 LayerNorm,对精度基本无影响;
- 将公版代码中的
torch.stack(continuous_embs).sum(dim=0)直接优化为了 add 操作,从而获得了比较大的性能收益。
对应代码如下所示:
class FourierConvEmbedding(nn.Module):
def __init__(
self, input_dim: int, hidden_dim: int, num_freq_bands: int
) -> None:
super(FourierConvEmbedding, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
#nn.Embedding替换为了Conv1x1
self.freqs = nn.ModuleList( [
nn.Conv2d(1, num_freq_bands, kernel_size=1, bias=False)
for _ in range(input_dim)])
#Linear层替换为了Conv1x1
self.mlps = nn.ModuleList(
[nn.Sequential(
nn.Conv2d(
num_freq_bands * 2 + 1, hidden_dim, kernel_size=1),
#删除LayerNorm
#nn.LayerNorm(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=1),)
for _ in range(input_dim)
]
)
#Linear层替换为了Conv1x1
self.to_out = nn.Sequential(
LayerNorm((hidden_dim, 1, 1), dim=1),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, 1),
)
...
def forward(
self,
continuous_inputs: Optional[torch.Tensor] = None,
categorical_embs: Optional[List[torch.Tensor]] = None,
) -> torch.Tensor:
if continuous_inputs is None:
...
else:
continuous_embs = 0
for i in range(self.input_dim):
...
if i == 0:
continuous_embs = self.mlps[i](x)
else:
#将stack+sum的操作替换为add
continuous_embs = continuous_embs + self.mlps[i](x)
# x = torch.stack(continuous_embs, dim=0).sum(dim=0)
x = continuous_embs
if categorical_embs is not None:
#将stack+sum的操作替换为add
# x = x + torch.stack(categorical_embs, dim=0).sum(dim=0)
x = x + categorical_embs
return self.to_out(x)
代码路径:`/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/fourier_embedding.py
4.1.3 RAttentionLayer
为了提升性能,去除 RAttentionLayer 的对相对时空编码 r 的 LayerNorm,相关代码如下:
class RAttentionLayer(nn.Module):
def __init__(
self,
...
def forward(self, x, r, mask=None, extra_dim=False):
if isinstance(x, torch.Tensor):
...
else:
x_src, x_dst = x
...
x = x[1]
#取消了公版中对相对时空编码r的LayerNorm
#if self.has_pos_emb and r is not None:
#r = self.attn_prenorm_r(r)
attn = self._attn_block(
x_src, x_dst, r, mask=mask, extra_1dim=extra_dim
) # [B, pl, h*d]
x = x + self.attn_postnorm(attn)
x2 = self.ff_prenorm(x)
x = x + self.ff_postnorm(self.ff_mlp(x2))
return x
代码路径:`/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/rattention.py
4.2 量化精度优化
4.2.1 FourierConvEmbedding
QCNetMapEncoder 和QCNetAgentEncode 的输入中存在距离计算、torch.norm 等对量化不友好的操作,为了提升量化精度,将输入全部置于预处理中,相关代码如下所示:
class QCNetOEAgentEncoderStream(nn.Module):
def __init__(
self,
...
) -> None:
super().__init__()
def build_cur_r_inputs(self, data, cur):
pos_pl = data["map_polygon"]["position"] / 10.0
orient_pl = data["map_polygon"]["orientation"]
pos_a = data["agent"]["position"][:, :, :cur] / 10.0 # [B, A, HT, 2]
head_a = data["agent"]["heading"][:, :, :cur] # [B, A, HT]
vel = data["agent"]["velocity"][:, :, :cur, : self.input_dim] / 10.0
...
def build_cur_embs(self, data, cur, map_data, x_a_his, categorical_embs):
B, A = data["agent"]["valid_mask"].shape[:2]
D = self.hidden_dim
ST = self.time_span
pl_N = map_data["x_pl"].shape[1]
mask_a_cur = data["agent"]["valid_mask"][:, :, cur - 1]
....
代码路径:/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/qcnet/agent_st_modeule.py
4.2.2 量化配置
首先使用 QAT 的精度 debug 工具获取量化敏感节点,然后在 Calibration 和量化训练时,对 20% 敏感节点配置为 int16 量化,相关代码如下:
if os.path.exists(sensitive_path2):
sensitive_table1 = torch.load(sensitive_path1)
sensitive_table2 = torch.load(sensitive_path2)
cali_qconfig_setter = (
sensitive_op_calibration_8bit_weight_16bit_act_qconfig_setter(
sensitive_table1,
ratio=0.2,
),
sensitive_op_calibration_8bit_weight_16bit_act_qconfig_setter(
sensitive_table2,
ratio=0.2,
),
default_calibration_qconfig_setter,
)
qat_qconfig_setter = (
sensitive_op_qat_8bit_weight_16bit_fixed_act_qconfig_setter(
sensitive_table1,
ratio=0.2,
),
sensitive_op_qat_8bit_weight_16bit_fixed_act_qconfig_setter(
sensitive_table2,
ratio=0.2,
),
default_qat_fixed_act_qconfig_setter,
)
print("Load sensitive table!")
4.3 不支持算子替换
4.3.1 cumsum
公版模型的QCNetDecoder中使用了 征程6 暂不支持的 torch.cumsum 算子,参考算法中将其替换为了 Conv1x1,相关代码如下:
self.loc_cumsum_conv = nn.Conv2d(
self.num_future_steps,
self.num_future_steps,
kernel_size=1,
bias=False,
)
self.scale_cumsum_conv = nn.Conv2d(
self.num_future_steps,
self.num_future_steps,
kernel_size=1,
bias=False,
)
代码路径:/usr/local/python3.10/dist-packages/hat/models/models/task_moddules/qcnet/qc_decoder.py
*** ***
*4.3.2 取余操作*
公版的 AgentEncoder 使用了处于操作“%”用于 wrap_angle,此操作当前仅支持在 CPU 上运行,为了提升性能,将其替换为了 torch.where 操作,代码对比如下所示:
公版:
def wrap_angle(
angle: torch.Tensor,
min_val: float = -math.pi,
max_val: float = math.pi) -> torch.Tensor:
return min_val + (angle + max_val) % (max_val - min_val)
参考算法:
def wrap_angle(
angle: torch.Tensor, min_val: float = -math.pi, max_val: float = math.pi
) -> torch.Tensor:
angle = torch.where(angle < min_val, angle + 2 * math.pi, angle)
angle = torch.where(angle > max_val, angle - 2 * math.pi, angle)
return angle
代码路径:/usr/local/python3.10/dist-packages/hat/models/models/task_moddules/qcnet/utils.py
05 总结与建议
**5.1 *index_select 和 scatter 算子*
**
征程6 仅支持 index_select 和 scatter 索引类算子的 CPU 运行,计算效率较低。QCNet 通过重构代码的形式,优化掉了 index_select 和 scatter 操作,实现了性能的提升。
5.2 ScatterND算子
模型中 nn.embedding 操作引入了目前仅支持在 CPU上 运行的 GatherND 算子,后续将考虑进行优化。
06 附录
- 论文:QCNet
- 公版模型代码:https://github.com/ZikangZhou/QCNet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号