【ACM】C++ 与 STL
2022LSNUACM_Winter_Week1Day1_Hoppz
C++ & STL
在标题后有 * 的建议看完后面的再回来阅读。
1、常用库函数
1.1、万能头
#include <bits/stdc++.h>
原理就是套娃。我自己写的一个万能头。
// C
#ifndef _GLIBCXX_NO_ASSERT
#include <cassert>
#endif
#include <cctype>
#include <cerrno>
#include <cfloat>
#include <ciso646>
#include <climits>
#include <clocale>
#include <cmath>
#include <csetjmp>
#include <csignal>
#include <cstdarg>
#include <cstddef>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <ctime>
#if __cplusplus >= 201103L
#include <ccomplex>
#include <cfenv>
#include <cinttypes>
#include <cstdalign>
#include <cstdbool>
#include <cstdint>
#include <ctgmath>
#include <cwchar>
#include <cwctype>
#endif
// C++
#include <algorithm>
#include <bitset>
#include <complex>
#include <deque>
#include <exception>
#include <fstream>
#include <functional>
#include <iomanip>
#include <ios>
#include <iosfwd>
#include <iostream>
#include <istream>
#include <iterator>
#include <limits>
#include <list>
#include <locale>
#include <map>
#include <memory>
#include <new>
#include <numeric>
#include <ostream>
#include <queue>
#include <set>
#include <sstream>
#include <stack>
#include <stdexcept>
#include <streambuf>
#include <string>
#include <typeinfo>
#include <utility>
#include <valarray>
#include <vector>
#if __cplusplus >= 201103L
#include <array>
#include <atomic>
#include <chrono>
#include <condition_variable>
#include <forward_list>
#include <future>
#include <initializer_list>
#include <mutex>
#include <random>
#include <ratio>
#include <regex>
#include <scoped_allocator>
#include <system_error>
#include <thread>
#include <tuple>
#include <typeindex>
#include <type_traits>
#include <unordered_map>
#include <unordered_set>
#endif
这个是他的位置

因为 Visual Studio 的 C++库中没有声明这个头文件。所以我就直接弄了一个。他的作用就是帮你写你常用的头文件,你就不用写这么多了,但是一定要清楚那个函数在那个库里面!!! 因为万一比赛的时候不支持头文件,那不是只有摆烂吗。
1.2、数据类型的简写
typedef long long ll;
typedef pair<int,int> pir;
ll a;
pir b;
1.3、关于宏
1.3.1、define
1.3.1.1、无参宏
在宏定义中没有参数
#define inf 0x3f3f3f3f
#define L T[rt].l
#define Mid ((T[rt].l +T[rt].r)>>1)
无参宏更像一种占位替换,他相当于直接把原来代码中的宏部分直接替换成后面的东西,仅作为字符串存储,并不会计算出他的结果。
#define N 2+2
int main()
{
int a=N*N;
printf("%d",a);
}
以我们的想法,输出的应该是 16,但是我们得到的是 8。他的计算逻辑是
直接把 N 替换到N*N 中。
所以在一些数值计算的时候一定记得加括号,同时在define语句的最后没有分号!!!
1.3.1.2、有参宏(宏函数)
C++语言允许宏带有参数。在宏定义中的参数称为形式参数,在宏调用中的参数称为实际参数。
对带参数的宏,在调用中,不仅要宏展开,而且要用实参去代换形参(有点类似printf 中的占位符)。
#define max(x,y) (x)>(y)?(x):(y); /// 实现 max 函数
值得注意的是,如果我们写一个函数形式的 max 函数是这样的:
int Max(int x, int y){return x > y ? x : y;}
区别在于,没有写变量类型!
所以这样的用法严格来说是不安全的,所以也仅仅只是我们比赛中可以这样写,但是项目中基本上不会这样写,更多的是看个人的习惯,但是一定要知道宏是不安全的!所以有些文章再说不推荐比赛的时候写宏就是这个道理。但是最主要是还是个人习惯,没必要争个胜负。
更安全的写法是用 template 后面不会扩展这个知识点,感兴趣的可以自己下去研究。
贴一个杨会的宏板子
//#pragma comment(linker,"/STACK:1024000000,1024000000")
//#pragma GCC optimize(2)
//#pragma GCC target ("sse4")
#include<bits/stdc++.h>
//typedef long long ll;
#define ull unsigned long long
//#define int __int128
#define int long long
#define F first
#define S second
#define endl "\n"//<<flush
#define eps 1e-6
#define base 131
#define lowbit(x) (x&(-x))
#define db double
#define PI acos(-1.0)
#define inf 0x3f3f3f3f
#define MAXN 0x7fffffff
#define INF 0x3f3f3f3f3f3f3f3f
#define _for(i, x, y) for (int i = x; i <= y; i++)
#define for_(i, x, y) for (int i = x; i >= y; i--)
#define ferma(a,b) pow(a%b,b-2)
#define mod(x) (x%mod+mod)%mod
#define pb push_back
#define decimal(x) cout << fixed << setprecision(x);
#define all(x) x.begin(),x.end()
#define rall(x) x.rbegin(),x.rend()
#define memset(a,b) memset(a,b,sizeof(a));
#define IOS ios::sync_with_stdio(false);cin.tie(0);
using namespace std;
#ifndef ONLINE_JUDGE
#include "local.h"
#endif
template<typename T> inline T fetch(){T ret;cin >> ret;return ret;}
template<typename T> inline vector<T> fetch_vec(int sz){vector<T> ret(sz);for(auto& it: ret)cin >> it;return ret;}
template<typename T> inline void makeUnique(vector<T>& v){sort(v.begin(), v.end());v.erase(unique(v.begin(), v.end()), v.end());}
template<typename T> inline T max_(T a,T b){if(a>b)return a;return b;}
template<typename T> inline T min_(T a,T b){if(a<b)return a;return b;}
void file()
{
#ifdef ONLINE_JUDGE
#else
freopen("D:/LSNU/codeforces/duipai/data.txt","r",stdin);
freopen("D:/LSNU/codeforces/duipai/WA.txt","w",stdout);
#endif
}
void Match()
{
#ifdef ONLINE_JUDGE
#else
Debug::Compare();
#endif // ONLINE_JUDGE
}
signed main()
{
IOS;
file();
}
Match();
return 0;
}
1.3.2、const
一般与数值有关的,我个人更加习惯用 const 来定义,这样数据的类型就得到了保障也更加安全。
const double eps = 1e-18; /// 表示 0.000000000000000001 区别 1e18
const int N = 1e5 + 10; /// 表示 100010 = 100000 + 10
const int maxp = 10;
const double pi = acos(-1); /// 表示圆周率
const double inf = 1e14; /// 1 后面跟上 14 个 0
同时在定义数组大小的时候,必须是 const 类型的数据才可以定义为数组的大小,常用形式为:
const int N = 2e5+10;
int a[N];
为什么+10?访问了未分配内存的空间!!!
在遍历的时候,或者计算的时候有的时候因为边界没有考虑完备,会遍历到没有定义的空间,所以为了更好的容错率一般多定义一点点。溢出的话,会报 Runtime Error 也就是直接卡死在那里,我遇到的 Runtion Error \(99\%\) 的情况都是数组越界。比如说
#include <bits/stdc++.h>
using namespace std;
vector<int> vec(100);
int main()
{
cout << vec[100] << endl;
return 0;
}
这里就访问了没有分配的内存。
1.3、输入,输出函数
在 c语言 中我们一般用 scanf 来输入, printf 来输出,我们会引入 <stdio.h> 这个头文件。
在 C++ 中我们一样可以用这两个来进行输入以及输出,但是我们更常用的是 cin 以及 cout 采用流式输出输出,需要引入 <iostream>。
输入
int a;
cin >>a;
输出
cout <<a <<endl;
cout << a << "\n"; // 与上面的功能相同
>> 叫做输入重定向,<<叫做输出重定向。endl 和 "\n"是一样的。
格式化输出
在 C语言 中我们可以用 %.10lf 来控制输出的精度,cout 的格式化输出较为麻烦一点
///非科学计数法输出
cout.setf(ios::fixed);
///设置输出小数点
cout << setprecision(4) << x <<endl;
一般遇到与精度有关的题的时候,我一般习惯不用流式输入输出,直接用标准输入输出。
1.3、与数学有关的库函数
1.3.1、max 与 min
虽然只是一个简单的比较大小但是都有非常非常多的写法,上述的宏定义,就不说了。
在 C++中我们可以直接用 <cmath> 库中的 max,min 函数。
#include <cmath>
#include <iostream>
using namespace std;
int main()
{
cout << max(1, 2) << endl;
return 0;
}
但是一般我们都直接用三目运算,a>b?a:b,或者写成内联函数的形式
inline int Max(int a, int b) { return a > b ? a : b; }
int main()
{
int a = 1, b = 2;
cout << Max(1, b) << endl;
// cout << (a > b ? a : b) << endl;
return 0;
}
内联函数会在编译的时候,在内联函数中的代码内嵌到原位置中,这样就可以提升运行的速度。
如果要比赛大小的数大于2怎么办?
在C++11中,支持使用大括号把要取大小的数都框起来,类似初始化数组的形式。
int ma = max({1,2,3,4,5,6})
如果我是要取得一个数组中的最大值和最小值呢?
1.3.2、max_element 与 min_element
要使用这两个函数,要引入 <algorithm>这个库,这两个函数的作用就是返回一个指向数组中的最大值或最小值的指针或迭代器,使用 * 取到地址、迭代器所对应的值。
int a[]={1,9,2,3,4};
int te = *max_element(a,a+5);
cout << te <<endl;
注意:诸如后面的
sort,lower_bound,这种对 \(l,r\) 区间进行操作的,都是在左闭右开 \([l,r)\) 的区间中进行操作,比如 $(a,a+5) $ 实际上是 \((a+0,a+5)\),我们知道在 C 语言中是从 \(0\) 开始的的,所以在有 \(5\) 个数字的数组中,最大下标是 \(4\),虽然是写的 \([0,5)\) 但是实际操作了的是 \([0,4]\) 。
1.3.3、pow 与 sqrt
首先,不要用 pow!!! 不要用 pow!!! 不要用 pow !!! 因为精度有问题。
pow(a,b)是用来求 a 的 b 次方等于多少,在校范围中,精度还是准确的,但是稍微打一点点,不会爆double,long long 他就不准确了,卡了整个集训队1个小时的教训。
这种误差在不同的C++标准中,可能不同,比如 CodeBlocks 采用的C++标准就会出现,但是Visual Studio 与 Visual Studio Code 都不会出现(这两不是同一个软件!!!)。
综上,自己手写个pow。
sqrt(a) 是用来一个数开二次方的结果,也就是取根号。
根据不用的数据类型可以选用:
- sqrt
- sqrtf
- sqrtl


关于精度
printf("%.30lf\n", sqrtl(2));
printf("%.30lf\n", sqrtf(2));
1.3.4 其他数学函数
/// 1、 三角函数
double sin(double); // 正弦
double cos(double); // 余弦
double tan(double); // 正切
/// 2 、反三角函数
double asin(double); // 结果介于[-PI / 2, PI / 2]
double acos(double); // 结果介于[0, PI]
double atan(double); // 反正切(主值),结果介于[-PI / 2, PI / 2]
double atan2(double, double); // 反正切(整圆值),结果介于[-PI, PI]
/// 3 、双曲三角函数
double sinh(double);
double cosh(double);
double tanh(double);
/// 4 、指数与对数
double frexp(double value, int* exp); // 这是一个将value值拆分成小数部分f和(以2为底的)指数部分exp,并返回小数部分f,即f * 2 ^ exp。其中f取值在0.5~1.0范围或者0。
double ldexp(double x, int exp); // 这个函数刚好跟上面那个frexp函数功能相反,它的返回值是x * 2 ^ exp
double modf(double value, double* iptr); // 拆分value值,返回它的小数部分,iptr指向整数部分。
double log(double); // 以e为底的对数
double log10(double); // 以10为底的对数
double log2(double); // 以2为底的对数
double pow(double x, double y); // 计算x的y次幂
float powf(float x, float y); // 功能与pow一致,只是输入与输出皆为浮点数
double exp(double); // 求取自然数e的幂
/// 5 、取整
double ceil(double); // 取上整,返回不比x小的最小整数
double floor(double); // 取下整,返回不比x大的最大整数,即 高斯函数[x]
/// 6 、绝对值
int abs(int i); // 求整型的绝对值
double fabs(double); // 求实型的绝对值
double cabs(struct complex znum); // 求复数的绝对值
/// 7 、标准化浮点数
double frexp(double f, int* p); // 标准化浮点数,f = x * 2 ^ p,已知f求x, p(x介于[0.5, 1])
double ldexp(double x, int p); // 与frexp相反,已知x, p求f
/// 8 、取整与取余
double modf(double, double*); // 将参数的整数部分通过指针回传,返回小数部分
double fmod(double, double); // 返回两参数相除的余数
/// 9 、其他
double hypot(double x, double y); // 已知直角三角形两个直角边长度,求斜边长度
double ldexp(double x, int exponent); // 计算x* (2的exponent次幂)
double poly(double x, int degree, double coeffs[]); // 计算多项式
1.4、upper_bound(),lower_bound()
只能升序使用,降序无法使用,同时返回的是指针或迭代器,需要引入<algorithm>
int a[] = { 1,2,4,4,6,7 };
int loc1 = lower_bound(a, a + 6, 3) - a;
int loc2 = lower_bound(a, a + 6, 4) - a;
int loc3 = upper_bound(a, a + 6, 3) - a;
auto loc4 = upper_bound(a, a + 6, 3);
cout << loc1 << endl;
cout << loc2 << endl;
cout << loc3 << endl;
cout << *loc4 << endl;
lower_bound(l,r,val)返回第一个等于val值的地址,如果没有就返回第一个大于val的地址。upper_bound(l,r,val)返回第一个大于val值的地址。
我们可以用最后返回的地址,减去首地址的方式来得到这个元素的下标,或者直接用解引用运算符来获取这个地址所代表的值。
1.5、sort()
我们最常用的基本上就是 sort 他的作用就是排序,但是内部实现是非常复杂的,他会根据不用的数据量来采用不用的排序算法,他的期望时间复杂度是非常优秀的,需引入<algorithm>。
sort(a,a+n)默认升序sort(a,a+n,less<int>())升序sort(a,a+n,greater<int>())降序
我们也可以自己写一个排列升序的比较函数
bool cmp(int a, int b){return a > b;}
int main()
{
int a[] = { 1,2,4,4,6,7 };
sort(a, a + 6, cmp);
cout << a[0] << endl;
}
同时对于一个结构体,我们也可以安不同的标准来进行排序。
在一次考试中,我想以数学为第一排序,如果数学相同,就以语文为第二排序,如果语文相同就以英文为第三排序,排序标准是成绩高的排在前面。
struct Node { int ma; int ch; int en; //bool operator < (Node b) { // if (ma == b.ma) { // if (ch == b.ch) { // return en > b.en; // } // return ch > b.ch; // }; // return ma > b.ma; //} }; bool cmp(Node a, Node b) { if (a.ma == b.ma) { if (a.ch == b.ch) { return a.en > b.en; } return a.ch > b.ch; }; return a.ma > b.ma; } int main() { Node stu[5]; stu[0] = { 99,99,2 }; stu[1] = { 88,100,100 }; stu[2] = { 99,2,99 }; stu[3] = { 99,99,100 }; stu[4] = { 100,100,100 }; sort(stu, stu + 5,cmp); /* * 或者我们把注释的解除,直接用 * sort(stu,stu+5); * 效果是一样的 */ for (int i = 0; i < 5; i++) { cout << stu[i].ma << ' ' << stu[i].ch << ' ' << stu[i].en << endl; } }
1.6、unique()
首先,这个函数只能对相同元素在并邻在一块的序列进行去重。不能对相同元素七零八落地分布的一般序列进行去重,可以对一般数组进行排序后再用
unique实现去重目的即可,因为排好序的的序列里面相同元素一定存储在连续的地址块。
他的作用是把不重复的元素移到前面来,需要引入<algorithm>,比如说
\(\{1,2,2,3,5,5,6,7\}\) 在进行 unique 之后,就会变成
\(\{1,2,3,5,6,7,6,7\}\)最后返回一个指向第二个 6 的指针(假定为 p),在这个指针之后的所有元素都是不需要的,也就是说,我们的新的去重后的数组变成了 \([a,p)\) (a,p均为指针)
int a[] = { 1,2,2,3,5,5,6,7 };
unique(a, a + 8);
for (int i = 0; i < 8; i++) cout << a[i] << ' '; cout << endl;
1.7、memset()
需引入<cstring>这个函数的作用是把一个数组中的一个区间全部变成一个值,但是这个值只能是一个两位重复的16进制数 比如说 0x13131313,0x3f3f3f3f ,0x00000000,但是输入的时候只用输入 0x13。
memset(a,0x13,sizeof a) 第一个参数是输出需要赋值的首地址,第二个是值,第三个是需要初始化的范围,从首地址开始后面的多大的范围内。
memset(a, 0x13, sizeof a);
cout << a[0] << ' ' << 0x13131313 << ' ' << 0x13 << endl;
所以,想要赋值为 1 的话,是不行的。
memset(a, 0x1, sizeof a);
cout << a[0] << ' ' << 0x01010101 << ' ' << 0x1 << endl;
但是很多时候其实写一个 for循环就好了,这个只是有的时候比较方便,比如说 0,和 0x3f3f3f3f。
1.8、reverse()
需引入<algorithm> ,作用是把一个数组中的一个区间反转。
int a[] = {1,2,3};
reverse(a, a + 3);
for (int i = 0; i < 3; i++)cout << a[i] << ' '; cout << endl;
2、string
2.1、什么是 string
string 中文名称 字符串 ,他的底层就是 char [] ,但是为了使字符串的操作更加方便,专门衍生出一个新的数据类型 string ,但是他自带了很多的方法,便于我们对字符串进行操作。
2.2、读入与输出 string
string s;
cin >> s; // 不能读入一行中的空格
getline(cin,s); // 能读入空格
cout <<s <<endl;
2.3、字典序与大小比较
我们按照 ASCII码定义字符串的大小;
字典序,就是按照字典(ASCII码)中出现的先后顺序进行排序。比如说:
"cba" 按照字典序排列后 变成 "abc"。
这个对于一个字符串内部的字典序排序,那么对于一个字符串数组,我们安装字典序排列是怎么样的呢?
对于字符串,先比较首字符,首字母小的排前面,如果首字母相同,再比较第二个字符,以此类推。
比如说: "abc","cbb","abd","cbbb" 排列后的结果为:
"abc","abd","cbb",cbbb
2.4、一些作用于 string 的函数
- 交换两个字符串
string a = "233", b = "322";
swap(a, b);
cout<< a << endl;
- 添加,赋值字符串
string s = "";
s += "a";
cout << s << endl;
s += "b";
cout << s << endl;
s.append("233");
cout << s << endl;
s.push_back('s'); // 注意和 append 的区别
cout << s << endl;
- 插入字符串
string s = "13";
s.insert(1, "22");
cout << s << endl;
- 删除字符串
string s = "1223";
s.erase(1,2);
cout << s << endl;
- 比较字符串的内容(字典序大小)
string a = "abc", b = "abd";
if (a > b)cout << 1;
else if (a < b) cout << 2;
else if (a == b) cout << 3;
else if (a >= b) cout << 4;
else if (a <= b) cout << 4;
else if( a.empty() ) cout << 5; // 如果字符串为空返回 true,反之 false
- 返回字符串大小(长度)
string a = "abc";
cout << a.size() << ' ' << a.length() << endl;
- 取子串
string a = "abcdef";
// 从下标 1 开始,后面 3 位
string sub = a.substr(1, 3);
cout << sub << endl;
- 搜寻某子串或字符
string a = "abcdef";
// 从下标 1 开始,后面 3 位
if (a.find("h") == string::npos) {
cout << "Not Find" << endl;
}
if (a.find("h") == -1) {
cout << "Not Find" << endl;
}
cout << a.find("cd") << endl;
找到的话,返回起始子串的起始下标,未找到返回 string::npos 其实就是 -1。
3、C++特性
3.1、解绑
ios::sync_with_stdio(false);
C++ 为了保证程序在使用了 printf 和 cout 时不发生冲突,进行了兼容性处理。cin、cout之所以效率低,就是因为先把要输出的东西存入缓冲区,再输出,导致效率降低。因此,很多人都会选择使用 scanf 和 printf 以加快运行速度。如果我们不同时使用这两种输出方法的话,为了提高运行速度,我们可以将其解除绑定,这样做了之后就不能同时混用cout 和 printf。
cin.tie(0);cout.tie(0);
同时,C++ 在默认的情况下 cin 与 cout 也是绑定的,每次执行 << 操作符的时候都要调用 flush,这样会增加 I/O 负担。可以通过tie(0)(0表示NULL)来解除 cin 与 cout 的绑定,进一步加快执行效率。
切记,解绑后不要在使用 scanf 和 printf 函数 !!!
3.2、auto 数据类型*
这个东西可以自动的把定义变量变成赋值变量的类型。这里我们用<typeinfo>来帮助我们输出数据的类型。
#include <typeinfo>
#include <bits/stdc++.h>
using namespace std;
int main()
{
auto te = 3.1415926;
cout << typeid(te).name() << endl;
return 0;
}
这样有很多很多的好处,比如说后面我们要学的STL容器 中的迭代器,每个容器的迭代器,要写很长,我们直接一个 auto 就可以搞定,比如说:
#include <typeinfo>
#include <bits/stdc++.h>
using namespace std;
int main()
{
vector<int> vec;
vec.push_back(1);
vector<int>::iterator it = vec.begin();
cout << *it << endl;
/// 对比
auto itt = vec.begin();
cout << *itt << endl;
cout << typeid(it).name() << endl;
cout << typeid(itt).name() << endl;
return 0;
}
还有就是我们后面在学队列的时候也会常用
queue<pair<int, int>> que;
while (!que.empty()) {
auto no = que.front();
que.pop();
...
}
这样也更加快捷,但是这样的话,代码的可读性会降低!!!
3.3、加强 for 循环*
加强 for 循环,在其他的语言中如 Java ,JavaScirpt 中叫做 forEach 当然最新的C++版本中也引入了 for_each函数。他依赖于上面的 auto 数据类型。
3.3.1、容器中的单变量应用
vector<int> vec(10,1);
for (auto it : vec) {
it = 3;
cout << it << endl;
}
我们运行后可以发现,这里的值输出的任然是 1。所以单一的用 auto it 来遍历是无法修改原始容器中的数据的。要使用 & 取地址符,就像在函数中传递参数一样。
vector<int> vec(10,1);
for (auto &it : vec) {
it = 3;
cout << it << endl;
}
3.3.2、容器中多变量的应用
map<string, int> mp;
mp["a"] = 1;
mp["b"] = 2;
for (auto it : mp) {
cout << it.first << ' ' << it.second << endl;
}
for (auto [a, b] : mp) {
cout << a << ' ' << b << endl;
}
后面的那种形式是 C++17 的新特性,如果用的C++版本低于 C++17是无法使用的!!!
4、C++ STL
4.1、什么是STL
C++标准
首先需要介绍的是 C++ 本身的版本。由于 C++ 本身只是一门语言,而不同的编译器对 C++ 的实现方法各不一致,因此需要标准化来约束编译器的实现,使得 C++ 代码在不同的编译器下表现一致。
标准模板库 STL
标准模板库(英文:Standard Template Library,缩写:STL),是一个C++软件库,大量影响了C++标准程序库但并非是其的一部分。其中包含4个组件,分别为算法、容器、函数、迭代器。
模板是C++程序设计语言中的一个重要特征,而标准模板库正是基于此特征。标准模板库使得C++编程语言在有了同Java一样强大的类库的同时,保有了更大的可扩展性。
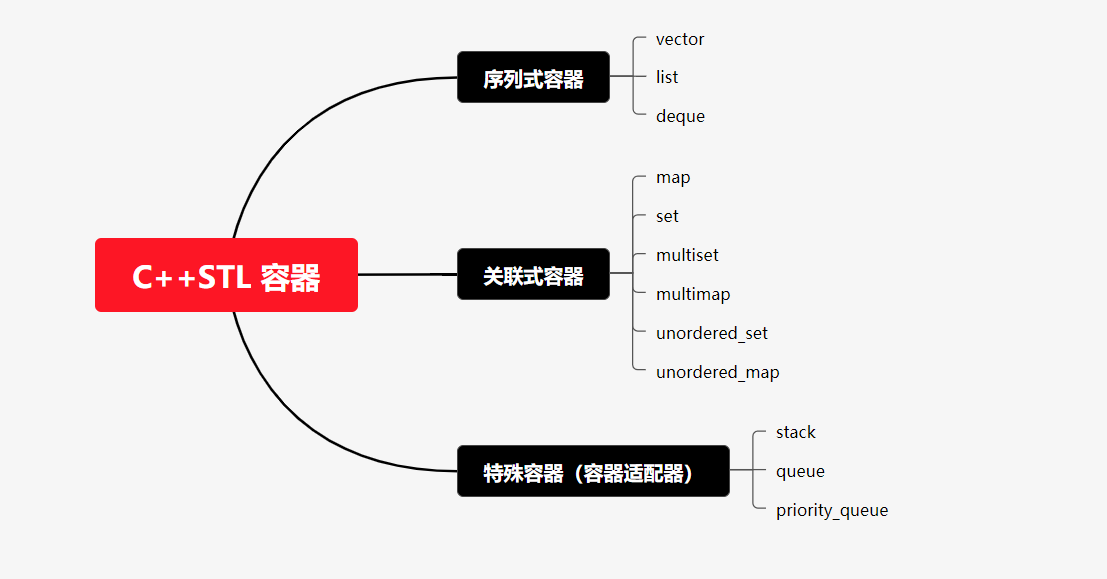
STL 将在数据上执行的操作与要执行操作的数据分开,分别以如下概念指代:
- 容器:包含、放置数据的地方。
- 迭代器:在容器中指出一个位置、或成对使用以划定一个区域,用来限定操作所涉及到的数据范围。
- 算法:要执行的操作。
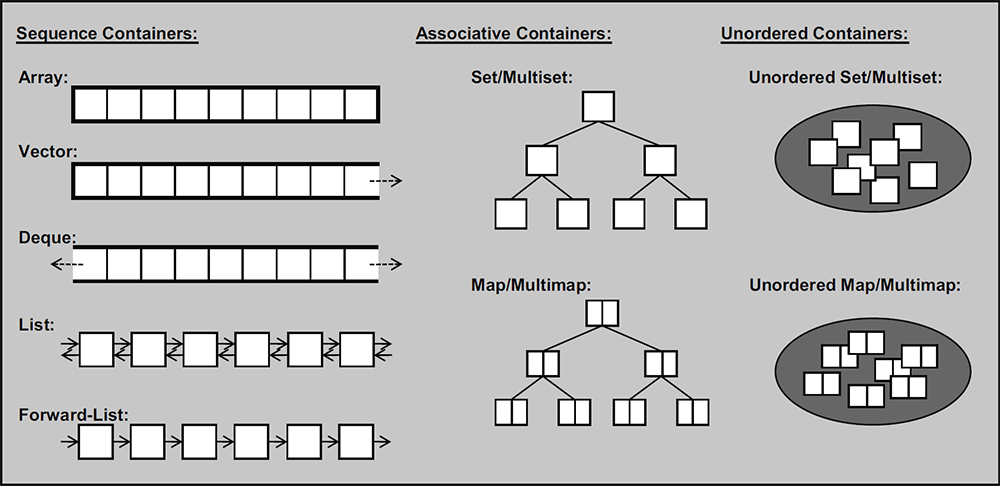
4.2、容器
在计算机科学中,容器以一种遵循特定访问规则的系统的方法来存储对象。
思考:我们之前的存储对象有些什么? 数组, 单个元素。
4.2.1、vector
std::vector 是 STL 提供的 内存连续的、可变长度 的数组(亦称列表)数据结构。能够提供线性复杂度的插入和删除,以及常数复杂度的随机访问。
-
为什么使用vector?
- vector 重写了比较运算符和赋值运算符
- vector 的可变长性
- vector的内存是动态分配的
-
vector的定义以及初始化
vector<int> a; /// 定义一个可边长度的数组,注意没有写数组大小 vector<int> a(10); /// 定义一个长度为10的可变长数组,用 () 来声明了初始化时的长度 vector<int> a(10,1); /// 定义一个长度为10 ,同时每一位的数据是 1 的数组。vector不仅仅支持定义基础数据类型的可变长数组,还可以定义自定义结构体的可变长数组。struct Node { string name; int val; }; vector<Node> vec(10,{"Hoppz",100});定义二维结构体的几种方式:
vector<int> a[10]; /// 注意区别上面 () 定义的数组 vector< vector<int> > vec(10); vector< vector<int> > arr(7,vector<int>(8,1));有几个需要注意的点:
- 第一行定义的方式是无法
-
元素访问
vector提供了如下几种方法进行元素访问at()
v.at(pos)返回容器中下标为pos的引用。如果数组越界抛出std::out_of_range类型的异常。operator[]
v[pos]返回容器中下标为pos的引用。不执行越界检查。front()
v.front()返回首元素的引用。back()
v.back()返回末尾元素的引用。data()
v.data()返回指向数组第一个元素的指针。 -
vector中的迭代器
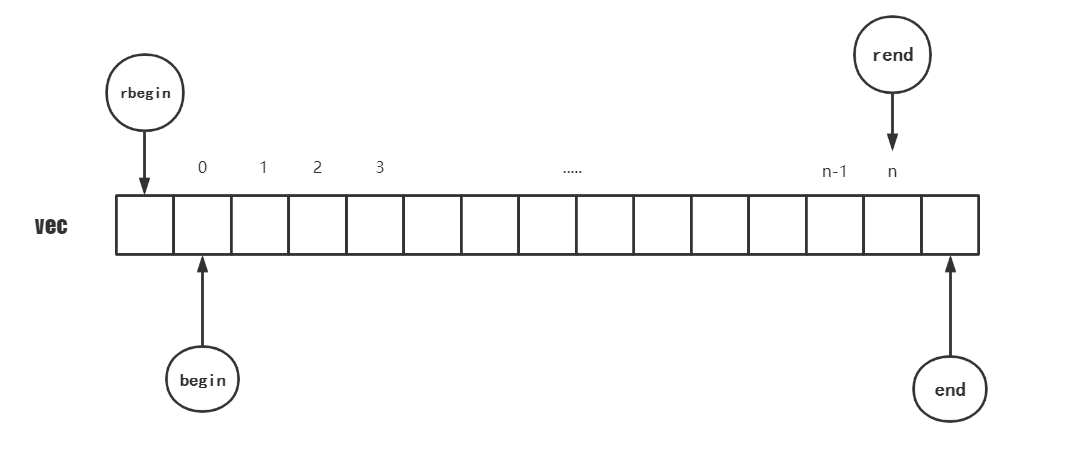
-
与长度有关的 函数
empty()返回一个bool值,即v.begin() == v.end(),true为空,false为非空。size()返回容器长度(元素数量),即std::distance(v.begin(), v.end())。
-
元素的删除及修改
-clear()清除所有元素
-insert()支持在某个迭代器位置插入元素、可以插入多个。复杂度与pos距离末尾长度成线性而非常数的
-erase()删除某个迭代器或者区间的元素,返回最后被删除的迭代器。复杂度与insert一致。
-push_back()在末尾插入一个元素,均摊复杂度为 常数,最坏为线性复杂度。
-pop_back()删除末尾元素,常数复杂度。
vector<int> vec;
vec.push_back(1);
vec.push_back(2);
vec.push_back(3);
cout << vec.size() << endl;
if (!vec.empty()) cout << "not empty" << endl;
vec.insert(vec.begin(), 2);
vec.erase(vec.begin(), vec.end() - 2);
cout << vec.front() <<endl;
4.2.2、deque
deque 为一个给定类型的元素进行线性处理,像 vector 一样,它能够快速地随机访问任一个元素,并且能够高效地插入和删除容器的头部以及尾部元素。但是 vector 是不可以对头部元素进行处理的。
在头部的操作与尾部一样,push_front ,pop_front,其他很多东西都很类似,就不做过多赘述了。
4.2.3、set
set 是关联容器,是一个自动排序,不可重复,的集合,在 搜索 、移除 和 插入 操作上拥有对数复杂度 \(nlog(n)\) 。set 内部通常采用平衡二叉树实现。平衡二叉树的特性使得 set 非常适合处理需要同时兼顾查找、插入与删除的情况。
-
插入与删除
insert(x)当容器中没有等价元素的时候,将元素 x 插入到set中。erase(x)删除值为 x 的 所有 元素,返回删除元素的个数。( 与后面的multiset 有区别)erase(pos)删除迭代器为 pos 的元素,要求迭代器必须合法。erase(first,last)删除迭代器在 范围内的所有元素。clear()清空set。
-
查询操作
count(x)返回set内键为 x 的元素数量。find(x)在set内存在键为 x 的元素时会返回该元素的迭代器,否则返回end()迭代器。lower_bound(x)返回指向首个不小于给定键的元素的迭代器。如果不存在这样 的元素,返回end()。upper_bound(x)返回指向首个大于给定键的元素的迭代器。如果不存在这样的元素,返回end()。empty()返回容器是否为空。size()返回容器内元素个数。
set<int> se;
se.insert(3);
se.insert(2);
se.insert(1);
// cout << se[0] << endl; 不支持
cout << *se.begin() << endl; /// set默认按照升序排列,所以最前面就是最小的值
cout << *(--se.end()) << endl;
for (auto it : se) { cout << it << ' '; }cout << endl;
se.erase(1);
cout << *se.begin() << endl;
// 返回的是迭代器
if (se.find(1) == se.end()) cout << "not find this key" << endl;
// 返回的是这个数的数量
if (se.count(2) != 0) cout << "find this key" << endl;
- set 在贪心中使用
在贪心算法中经常会需要出现类似 找出并删除最小的大于等于某个值的元素。这种操作能轻松地通过 set 来完成。
```c++
// 现存可用的元素
set
// 需要大于等于的值
int x;
// 查找最小的大于等于x的元素
set
if (it == se.end()) {
// 不存在这样的元素,则进行相应操作……
} else {
// 找到了这样的元素,将其从现存可用元素中移除
se.erase(it);
// 进行相应操作……
}
```
例1
Bees Alice and Alesya gave beekeeper Polina famous card game "Set" as a Christmas present. The deck consists of cards that vary in four features across three options for each kind of feature: number of shapes, shape, shading, and color. In this game, some combinations of three cards are said to make up a set. For every feature — color, number, shape, and shading — the three cards must display that feature as either all the same, or pairwise different. The picture below shows how sets look.
Polina came up with a new game called "Hyperset". In her game, there are nn cards with kk features, each feature has three possible values: "S", "E", or "T". The original "Set" game can be viewed as "Hyperset" with $ k=4$.
Similarly to the original game, three cards form a set, if all features are the same for all cards or are pairwise different. The goal of the game is to compute the number of ways to choose three cards that form a set.
Unfortunately, winter holidays have come to an end, and it's time for Polina to go to school. Help Polina find the number of sets among the cards lying on the table.
Input
The first line of each test contains two integers nn and kk (\(1≤n≤1500\), \(1≤k≤30\) — number of cards and number of features.
Each of the following nn lines contains a card description: a string consisting of kk letters "S", "E", "T". The ii-th character of this string decribes the ii-th feature of that card. All cards are distinct.
Output
Output a single integer — the number of ways to choose three cards that form a set.
Examples
input
3 3 SET ETS TSEoutput
1input
3 4 SETE ETSE TSESoutput
0input
5 4 SETT TEST EEET ESTE STESoutput
2Note
In the third example test, these two triples of cards are sets:
- "SETT", "TEST", "EEET"
- "TEST", "ESTE", "STES"

#include <bits/stdc++.h>
using namespace std;
int n,m,ans;
string s[2000];
set<string> se;
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
cin >>n >> m;
for(int i = 0; i < n ; i++){
cin >> s[i];
se.insert(s[i]);
}
for(int i = 0 ; i < n ; i++){
for(int j = i + 1 ; j < n ; j++){
string te = "";
for(int k = 0 ; k < m; k++){
if( s[i][k] == s[j][k] ){
te += s[i][k];
}
else{
if( (int)(s[i][k] + s[j][k]) == 167 ){
te+='E';
}
else if( (int)(s[i][k] + s[j][k]) == 152 ){
te+='T';
}
else te += 'S';
}
}
if( se.find(te) != se.end()){
ans++;
//cout <<s[i] << endl <<s[j] << endl << te << endl << endl;
}
}
}
cout << ans/3 <<endl;
return 0;
}
4.2.4、map
-
什么是键值对

在将后者与前者结合起来就是map了
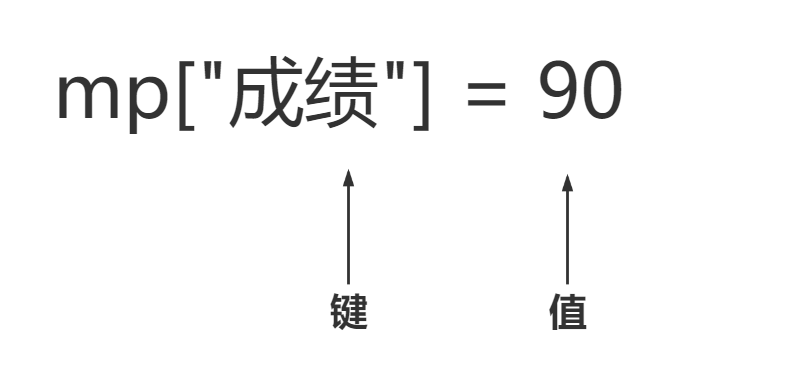
-
map
map是有序键值对容器,它的元素的键是唯一的。搜索、移除和插入操作拥有对数复杂度。map通常实现为红黑树。你可能需要存储一些键值对,例如存储学生姓名对应的分数:
Tom 0,Bob 100,Alan 100。但是由于数组下标只能为非负整数,所以无法用姓名作为下标来存储,这个时候最简单的办法就是使用 STL 中的map了! -
插入与删除操作
- 可以直接通过下标访问来进行查询或插入操作。例如
mp["Alan"]=100。 - 通过向
map中插入一个类型为pair<Key, T>的值可以达到插入元素的目的,例如mp.insert(pair<string,int>("Alan",100));或者mp.insert({key,value}) erase(key)函数会删除键为key的 所有 元素。返回值为删除元素的数量。erase(pos): 删除迭代器为 pos 的元素,要求迭代器必须合法。erase(first,last): 删除迭代器在 \([first,last)]\) 范围内的所有元素。clear()函数会清空整个容器。
下标访问中的注意事项
在利用下标访问
map中的某个元素时,如果map中不存在相应键的元素,会自动在map中插入一个新元素(一般都是用次方法插入),并将其值设置为默认值(对于整数,值为零;对于有默认构造函数的类型,会调用默认构造函数进行初始化)。当下标访问操作过于频繁时,容器中会出现大量无意义元素,影响
map的效率。因此一般情况下推荐使用find()函数来寻找特定键的元素。 - 可以直接通过下标访问来进行查询或插入操作。例如
-
查询操作
count(x): 返回容器内键为 x 的元素数量。复杂度为 (关于容器大小对数复杂度,加上匹配个数)。find(x): 若容器内存在键为 x 的元素,会返回该元素的迭代器;否则返回end()。lower_bound(x): 返回指向首个不小于给定键的元素的迭代器。upper_bound(x): 返回指向首个大于给定键的元素的迭代器。若容器内所有元素均小于或等于给定键,返回end()。empty(): 返回容器是否为空。size(): 返回容器内元素个数。
map_demo01
map<string,int> mp;
mp["Hoppz"] = 233;
mp["Gary"] = 111;
mp["qiubi"] = 222;
cout << mp["Hoppz"] << endl;
for (auto it : mp) {
cout << it.first << ' ' << it.second << endl;
}
mp["aa"] = 22;
mp["ab"] = 23;
cout << endl;
for (auto it : mp) {
cout << it.first << ' ' << it.second << endl;
}
map_demo02
map<string,int> mp;
mp["Hoppz"] = 233;
mp["Gary"] = 111;
mp["qiubi"] = 222;
if (mp["qiuqiu"] == 233) {
cout << "qiuqiu" << endl;
}
if (mp.count("qxq")) {
cout << "qxa" << endl;
}
for (auto it : mp) {
cout << it.first << ' ' << it.second << endl;
}
例2
A Dyson Sphere is a hypothetical megastructure that completely encompasses a star and captures a large percentage of its power output. The concept is a thought experiment that attempts to explain how a spacefaring civilization would meet its energy requirements once those requirements exceed what can be generated from the home planet’s resources alone. Only a tiny fraction of a star’s energy emissions reach the surface of any orbiting planet. Building structures encircling a star would enable a civilization to harvest far more energy.
One day, Moca has another idea for a thought experiment. Assume there is a special box called Dyson Box. The gravitational field in this box is unstable. The direction of the gravity inside the box can not be determined until it is opened.
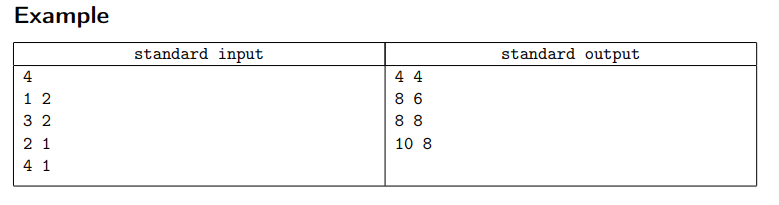
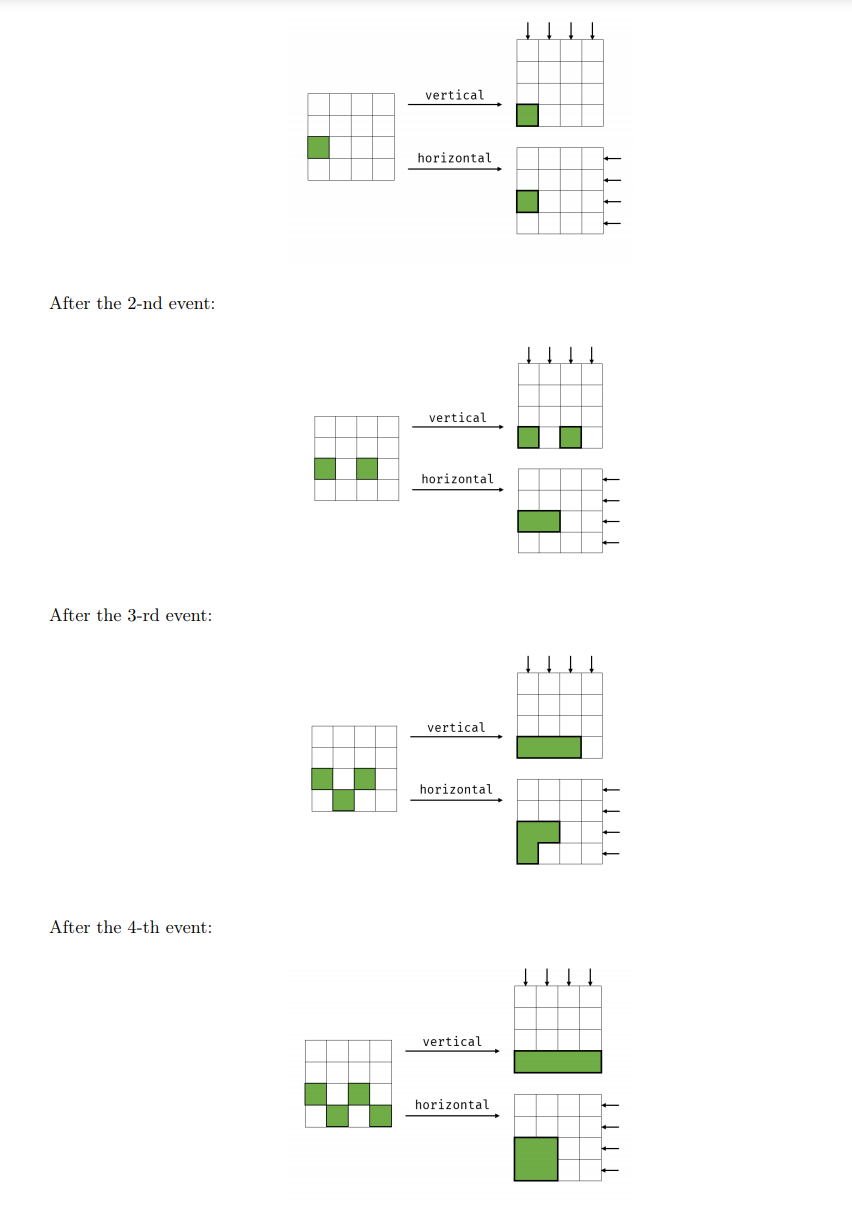
The inside of the box can be formed as a 2-dimensional grid, while the bottom left corner’s coordinate is $ (0, 0)$ and the upper right corner’s coordinate is (\(2 · 10^5,2 · 10^5\) ). There will be n events. In the i-th event, a new cube will appear, whose upper right corner’s coordinate is (\(x_i , y_i\)) and bottom left corner’s coordinate is (\(x_i − 1, y_i − 1\)).
There are two directions of gravity in the box, vertical and horizontal. Suppose Moca opens the box after the i-th event. In that case, she has $ \frac{1} {2}$ probability of seeing the direction of the gravity inside the box is vertical, and the other $ \frac{1} {2}$ probability is horizontal. And then, she will measure the total length of the outline of all the cubes. If the direction of gravity is horizontal, all the cubes inside will move horizontally to the left under its influence. Similarly, vertical gravity will cause all the cubes to move downward.
Moca hates probability, so that she is asking for your help. If you have known the coordinates of all the cubes in chronological order, can you calculate the total length of these two cases after each event?
Input
The first line contains one integer n (1 ≤ n ≤ 2 · 105 ) – the number of cubes. Each of the following n lines describes a cube with two integers xi , yi (1 ≤ xi , yi ≤ 2 · 105 ). It is guaranteed that no two cubes have the same coordinates.
Output
For each of the n cubes, print one line containing two integers – two answers when the the direction of gravity is vertical and horizontal.
Note
In the only example, the inside of the box is as below, and the bold lines mark the outline of all the cubes. After the 1-st event:
4.2.5、pair
这里补充一个数据类型 pair ,可以把它理解为为 first ,second 两个值的一个数组,这两个值可以是不同的数据类型比如,pair<string,int>,他的实现是基于 struct 结构体的,所以我们在访问他的数据的时候不用调用方法,当然我们也可以自己写一个 struct 。
struct Node
{
string first;
int second;
};
pair<string,int> pir;
// 两者都可以
- 定义
pair<string,int> pir; /// 定义一个 first 为 string类型,second 为 int 类型的 pair
pair<string, vector<int>> /// 定义一个 first 为 string类型 ,second 为 vector<int> 数组的一个 pair
- 赋值
在C++ 11中我们可以直接用 {} 来对其进行赋值,但是如果不支持 C++11 ,不支持 {} 赋值的话,可以用 make_pair() 函数进行赋值。
pair<string,int> pir = {"Hoppz",233};
pir = make_pir("Hoppz",233);
- 调用
如果我们要调用元素的值我们可以直接用成员运算符. 来访问,大家可以理解为上面提到的,struct Node 这个结构体访问他的 first,second 变量。
pair<string,int> pir = {"Hoppz",233};
pir.first = "Gary";
pir.second = "23333";
cout << pir.fisrt << ' ' << pir.second <<endl;
- 数组
我们可以定义一个 pair 数组,就和普通的数组一样。
const int N= 2e5+10;
pair<string,int> pir[N];
4.3、Struct 重写 & 在 STL容器中的应用
#include <iostream>
#include <iomanip>
#include <cstdio>
#include <set>
#include <algorithm>
using namespace std;
struct Point
{
double x,y;
Point(double _x,double _y){
x = _x,y = _y;
}
bool operator < (const Point& b) const{
if( x == b.x ){
return y< b.y;
}
return x < b.x;
}
Point(){}
};
int main()
{
set<Point> se;
se.insert({3,24325});
se.insert({283,25});
se.insert({21453,2435});
se.insert({213,35});
for(auto it :se){
cout << it.x << ' ' <<it .y <<endl;
}
return 0;
}
4.4、例题
4.4.1、体测
原题链接 :A-Two Point Removal_第 46 届 ICPC 国际大学生程序设计竞赛亚洲区域赛(上海)热身赛
//
// Created by Hoppz on 2021/12/2.
//
#include <bits/stdc++.h>
using namespace std;
struct Node
{
double x,y;
bool operator < (Node b){ return x < b.x; }
};
double dis(double x1,double y1,double x2,double y2){ return sqrt( (x1-x2)*(x1-x2) + (y1-y2)*(y1-y2) ); }
vector<Node> vec;
int main()
{
double n,m;
scanf("%lf%lf",&n,&m);
vec.push_back({0,0});
for(int i = 0; i < m ; i++){
double x,y;
scanf("%lf%lf",&x,&y);
vec.push_back({x,y});
}vec.push_back({n,0});
sort(vec.begin(),vec.end());
double ma = 0,ans = 0,loc = 0,tel=0,ter=0,teres=0;
for(int i = 1; i <= m ; i++){
double l = dis( vec[i-1].x , vec[i-1].y , vec[i].x , vec[i].y );
double r = dis( vec[i+1].x , vec[i+1].y , vec[i].x , vec[i].y );
double res = dis( vec[i+1].x , vec[i+1].y , vec[i-1].x , vec[i-1].y );
if( l+r-res > ma ){
tel = l,ter = r,teres = res,ma = l+r-res;
}
ans += l;
}
ans += dis( vec[m+1].x , vec[m+1].y , vec[m].x , vec[m].y );
ans -= ma;
printf("%.4f\n",ans);
return 0;
}
4.4.2、Problem - A - Codeforces
有 \(n\) 个不同的巧克力棒,第 \(i\) 个巧克力棒的价格是 \(a_i\)美元。 如果巧克力棒的成本严格超过 \(r\) 美元,Divan 认为它太贵了。 同样,如果一块巧克力的成本严格低于 \(1\) 美元,他认为它太便宜了。 Divan 不会买太便宜或太贵的酒吧。 同时 Divan 最多会花 \(k\) 美元来买巧克力棒,求他最多可以买多少个巧克力棒。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6+10;
typedef long long ll;
void solve()
{
ll n,l,r,k,ans=0;
cin >> n >> l >>r >> k;
vector<ll> vec;
for(int i = 0; i < n ; i++){
ll te;
cin >> te;
if( te >= l && te <= r ){
vec.push_back(te);
}
}
sort(vec.begin() ,vec.end() );
for(auto it :vec){
if( it <= k ){
k-= it;ans++;
}
}
cout << ans << endl;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int t;
cin >> t;
while(t--){
solve();
}
return 0;
}
4.4.3、Problem - C - Codeforces
/**
* Author : Hoppz
* Date : 2021-11-15-22.37.55
*/
#include <bits/stdc++.h>
#define L (T[rt].l)
#define R (T[rt].r)
#define Mid (T[rt].l + T[rt].r >> 1)
#define ls (rt<<1)
#define rs (rt<<1+1)
#define Lazy (T[rt].lazy)
using namespace std;
typedef long long ll;
typedef pair<int,int> pir;
const double pi = acos(-1);
const ll inf = (long long)1e18;
const int N = 1e5+10;
void solve()
{
int n;
cin >> n;
vector<int> a(n),b(n);
for(int i = 0 ; i < n ; i++) cin >> a[i];
for(int i = 0 ; i < n ; i++) cin >> b[i];
sort(a.begin(),a.end());
sort(b.begin(),b.end());
int flag = 1;
for(int i = 0; i < n ; i++){
if( b[i] - a[i] == 1 || b[i] - a[i] == 0 ){
continue;
} else {
flag = 0;
break;
}
}
if( flag ) puts("YES");
else puts("NO");
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int t;
cin >> t;
while(t--){
solve();
}
return 0;
}
5、习题
5.1、Problem - A - Codeforces
#include <bits/stdc++.h>
using namespace std;
void solve()
{
string s;
cin >> s;
if (s.length() & 1) {
puts("NO");
return;
}
string a = s.substr(0, (s.length() >> 1));
string b = s.substr((s.length() >> 1), (s.length() >> 1));
if (a == b) puts("YES");
else puts("NO");
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
int t;
cin >> t;
while (t--) {
solve();
}
}
5.2、Problem - 1617A - Codeforces
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 2e5 + 10;
void solve()
{
string a, b,ans="";
cin >> a >> b;
sort(a.begin(), a.end());
int na = 0, nb = 0, nc = 0,loc=-1;
for (int i = 0; i < a.length(); i++) {
if (a[i] == 'a') na++;
else if (a[i] == 'b') nb++;
else if (a[i] == 'c') nc++;
else {
loc = i;
break;
}
}
if (b == "abc" && na && nb && nc) {
for (int i = 0; i < na; i++) {
cout << "a";
}
for (int i = 0; i < nc; i++) {
cout << "c";
}
for (int i = 0; i < nb; i++) {
cout << "b";
}
if (loc != -1) {
for (int i = loc; i < a.length(); i++) {
cout << a[i];
}
}
cout << endl;
}
else {
cout << a << endl;
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
int t;
cin >> t;
while (t--) {
solve();
}
return 0;
}
5.3、Problem - A - Codeforces
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 2e5 + 10;
void solve()
{
string a, b,ans="";
cin >> a >> b;
sort(a.begin(), a.end());
int na = 0, nb = 0, nc = 0,loc=-1;
for (int i = 0; i < a.length(); i++) {
if (a[i] == 'a') na++;
else if (a[i] == 'b') nb++;
else if (a[i] == 'c') nc++;
else {
loc = i;
break;
}
}
if (b == "abc" && na && nb && nc) {
for (int i = 0; i < na; i++) {
cout << "a";
}
for (int i = 0; i < nc; i++) {
cout << "c";
}
for (int i = 0; i < nb; i++) {
cout << "b";
}
if (loc != -1) {
for (int i = loc; i < a.length(); i++) {
cout << a[i];
}
}
cout << endl;
}
else {
cout << a << endl;
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
int t;
cin >> t;
while (t--) {
solve();
}
return 0;
}
5.4、Problem - 1623B - Codeforces
代码
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 2e5 + 10;
struct Node
{
int l, r, len, id,ans;
}a[1010];
bool cmp1(Node a, Node b)
{
if (a.len == b.len) return a.l < b.l;
return a.len < b.len;
}
bool cmp2(Node a, Node b)
{
return a.id < b.id;
}
bool st[1010];
void solve()
{
int n;
cin >> n;
memset(st, 0, sizeof st);
for (int i = 0; i < n; i++) {
cin >> a[i].l >> a[i].r;
a[i].len = a[i].r - a[i].l + 1;
a[i].id = i;
}
sort(a, a + n, cmp1);
for (int i = 0; i < n; i++) {
for (int j = a[i].l; j <= a[i].r; j++) {
if (st[j] == 0) {
st[j] = 1;
a[i].ans = j;
break;
}
}
}
//sort(a, a + n, cmp2);
for (int i = 0; i < n; i++) {
cout << a[i].l << ' ' << a[i].r << ' ' << a[i].ans << endl;
}cout << endl;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
int t;
cin >> t;
while (t--) {
solve();
}
return 0;
}
5.5、Problem - C - Codeforces
#include <bits/stdc++.h>
using namespace std;
int main() {
int c;
cin >> c;
for (int i = 0; i < c; i++) {
int n, k;
cin >> n >> k;
vector<int> x(n);
for (int j = 0; j < n; j++) {
cin >> x[j];
}
vector<int> a, b;
for (int j = 0; j < n; j++) {
if (x[j] < 0) {
a.push_back(-x[j]);
}
if (x[j] > 0) {
b.push_back(x[j]);
}
}
sort(a.begin(), a.end());
sort(b.begin(), b.end());
int cnta = a.size();
int cntb = b.size();
long long ans = 0;
for (int j = cnta - 1; j >= 0; j -= k) {
ans += a[j] * 2;
}
for (int j = cntb - 1; j >= 0; j -= k) {
ans += b[j] * 2;
}
int mx = 0;
if (cnta > 0) {
mx = max(mx, a[cnta - 1]);
}
if (cntb > 0) {
mx = max(mx, b[cntb - 1]);
}
ans -= mx;
cout << ans << endl;
}
}
5.6、Expression Evaluation Error
题意: 给一个 \(n , s\) ,\(n\) 为一个数列的和,\(s\)为这个数列中数的个数,现在把 \(n\) 拆分成 \(s\) 个数,我们把这 s 个数视为 11 进制 求和,要使得这个11进制的数最大
题解: 对于10拆成9 + 1 ,会发现损失了1,所以我们要尽可能的保留最高位的数,并且要保证,之后可以拆成1 n-(s-i)就是在做这一步
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e5 +10;
int mypow(int x)
{
int res = 1;
for(int i = 0 ; i < x ; i++){
res *= 10;
}
return res;
}
void solve()
{
int n,s;
cin >> n >> s;
for(int i= 1; i < s ; i++){
/// n-(s-i) 确保了最后可以补 1
int x = mypow(int(log10(n - (s - i))) );
cout << x << " ";
n -= x;
}
cout << n <<endl;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int t;
cin >>t;
while(t--){
solve();
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号