mysql-Innodb笔记
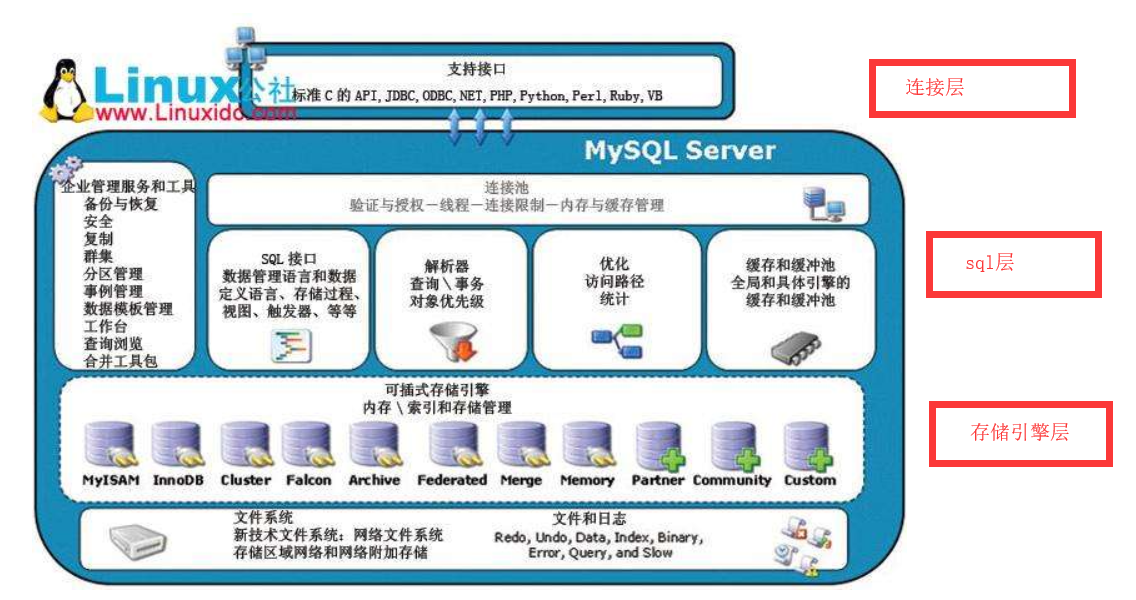
1 Mysql的体系结构和存储引擎分类
Innodb 使用多版本并发控制(MVCC)来获取高并发性,默认repeatable级别,支持事务
MyISAM支持不事务 ,缓存池 只缓存索引文件,不缓存数据文件。 MYD 数据文件,MYI索引文件,旧版本支持缓存索引的缓冲区最大4GB,新版本大4GB。
Memory作为临时表或者中间表的存储引擎,如果中间表超过memory存储引擎中间表的限制,则使用MyISAM,此时不缓存数据文件,查询性能下降。
Achieve 不支持事务,高速插入和压缩功能
...
show engines\G; 查看支持的存储引擎;
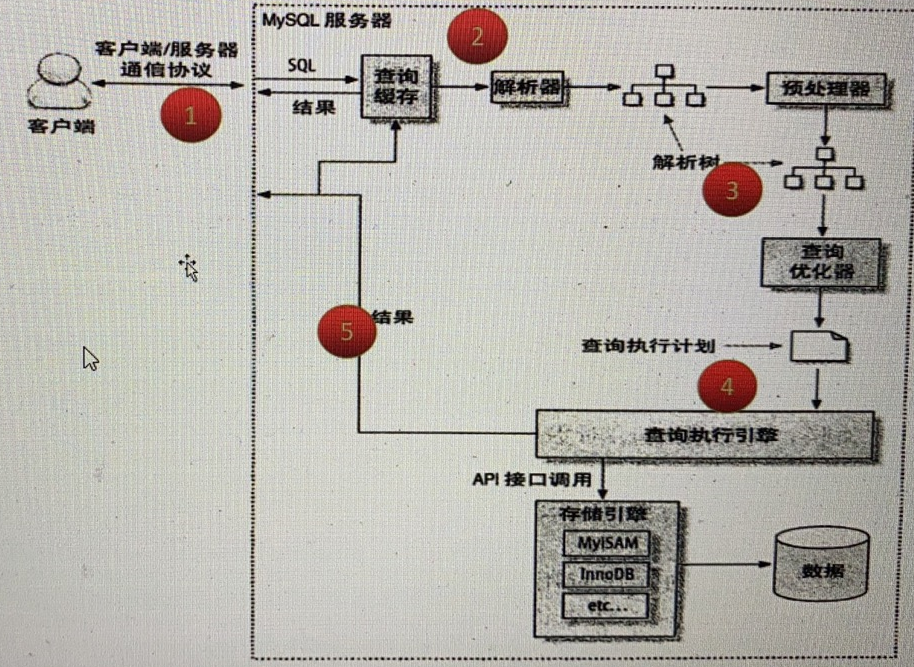
2 Innodb体系结构
2.1 后台线程
——Master Thread
核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲,undo页的回收,由以下几个loop组成
main loop(工作loop) 每秒执行任务 每10秒执行任务 :合并插入缓存,刷新脏页到磁盘,刷新日志缓存到磁盘,删除undo页
background(后台loop) 没用用户活动 或者关闭数据库连接 ,不断刷新100个页,可能跳到flush loop中
flush(flush loop) flush操作,可能跳到suspend loop
suspend(暂停loop)
——IO Thread
大量使用Async IO来处理IO的请求,可以极大提高数据库的性能。而IO Thread的主要工作是负责IO请求的回调处理。较早之前版本有4个IO Thread 分别是write , read , insert buffer,log IO Thread
——Purge Thread
事务被提交后,其所使用的undolog可能不再需要,因此需要Purge Thread来及时回收已经分配的undo页。
——Page Cleaner Thread
作用是将之前版本的脏页刷新操作放入单独的线程来完成。其目的为了减轻Master Thread的负担,从而进一步提高InnoDB存储引擎的性能
2.2内存
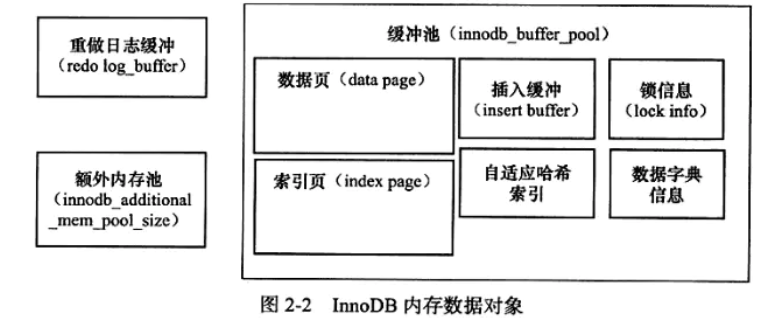
缓存池中: 数据页、索引页、undo页、插入缓冲页,自适应哈希索引,数据字典和锁信息。
2.3 checkpoint技术
WAL策略,事务提交时先写redo log,在修改页 ,保证ACID中的D。
执行checkpoint 刷新脏页。
2.4关键特性
插入缓冲
一级索引 顺序io
二级索引 随机io
二级非唯一索引可以使用,就是为了减少随机io,先保存在i_buf里,在合并写入
唯一需要先查询,再插入 违背减少随机io的原则。
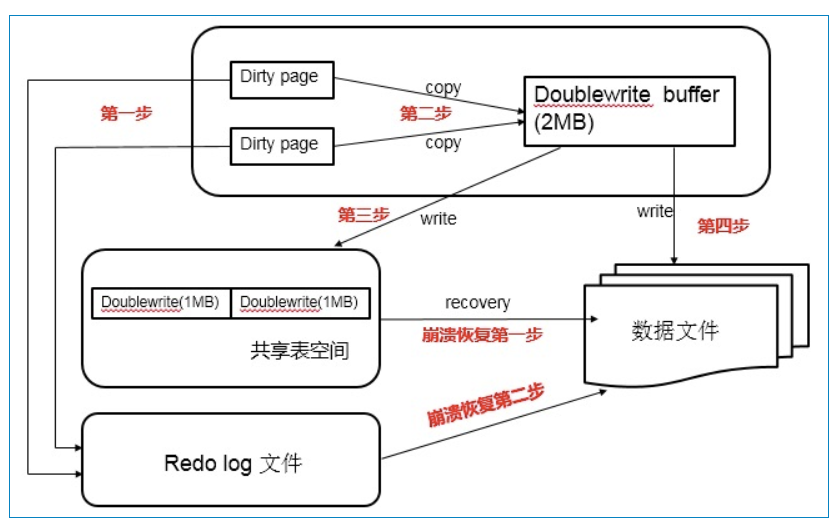
两次写 mysql页-16k, os页-4K 数据丢失
自适应哈希索引
InnoDB存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应(adaptive)的。
自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
不需要将整个表都建哈希索引,InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
异步IO
同时发送
合并page,一次回复
刷新相邻页
刷新脏页的时候,检测相邻页 如果时脏页 一起刷新
3 文件
错误日志 show variables like 'log_error'\G;
慢查询日志 show variables like 'long_slow_queries'\G; long_query_time
查询日志
二进制日志 bin log 备份恢复,主从复制,审计sql
Innodb文件
重做日志日志 statement/row/mixed redo log buffer -> redo log group -> redo log file1 |redo log file2 用作恢复 file1 file2 不同分区 高可用
恢复日志
4 Innodb逻辑存储结构
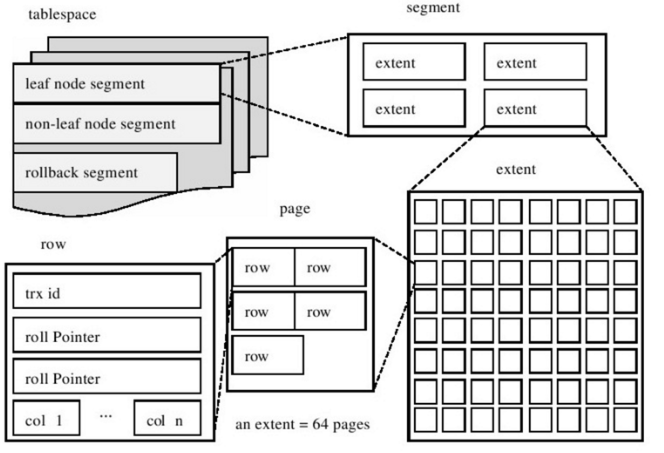
表空间 多个段 :数据段,索引段,回滚段
段 每个段4个区
区extent 1MB = 64个页
页page 16k
数据页结构
File Header
Page Header
user record 数据行
tail file
行 16k/2-200 一页最多7000多行数据
5 索引和算法
索引:加速数据检索而创建的分散存储的数据结构,减少查询数据量 ,随机io 变成 顺序io
索引 磁盘数据
1 0x123456 1 0x123456 zhangsan 19岁 。。。
2 0x123457 。。。
teacher(id) teacher表
2000w的表索引文件1-2G
二分查找 logN
平衡树 B树 太深 太小
B+树插入和删除 优点 天然排序 非叶子节点不保存数据,磁盘io减少,也就是读写能力变强
B+树索引
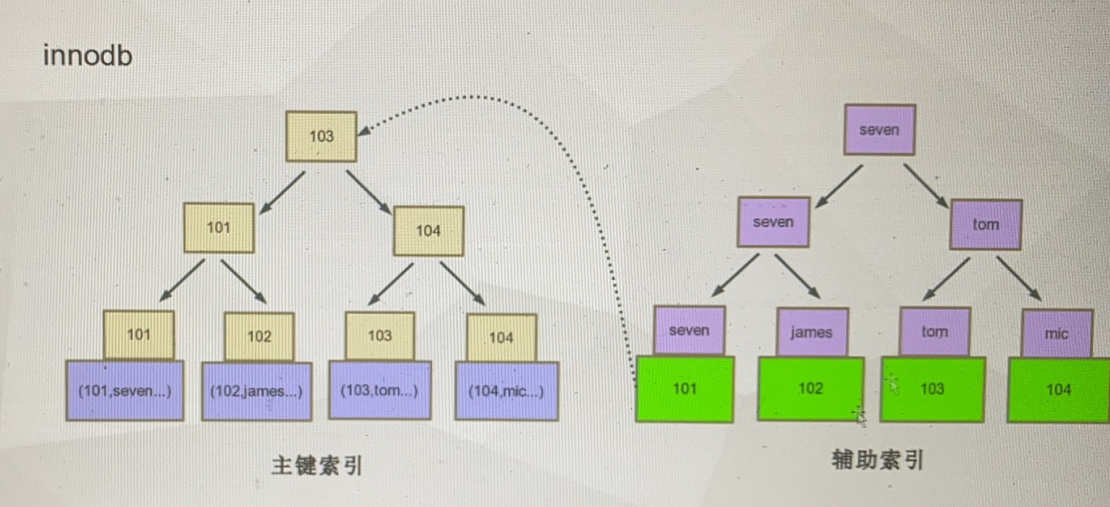
聚集索引 主键索引 顺序存储 范围查找很快 frm 和idb文件 数据挂在主键索引下面;
myisam 索引和数据分开存储
 myisam 如右图:
myisam 如右图: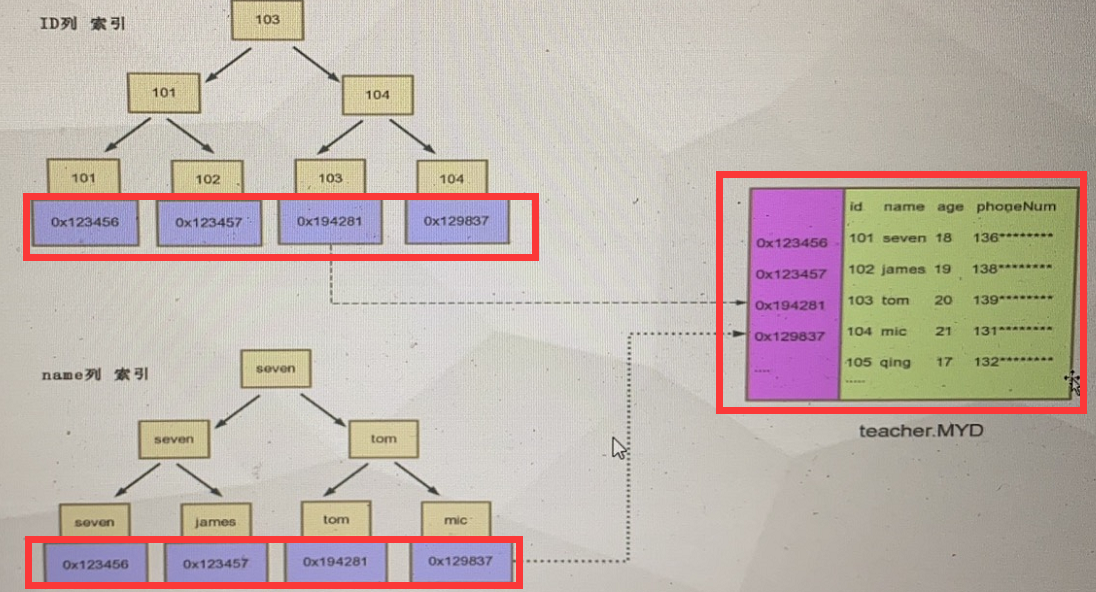
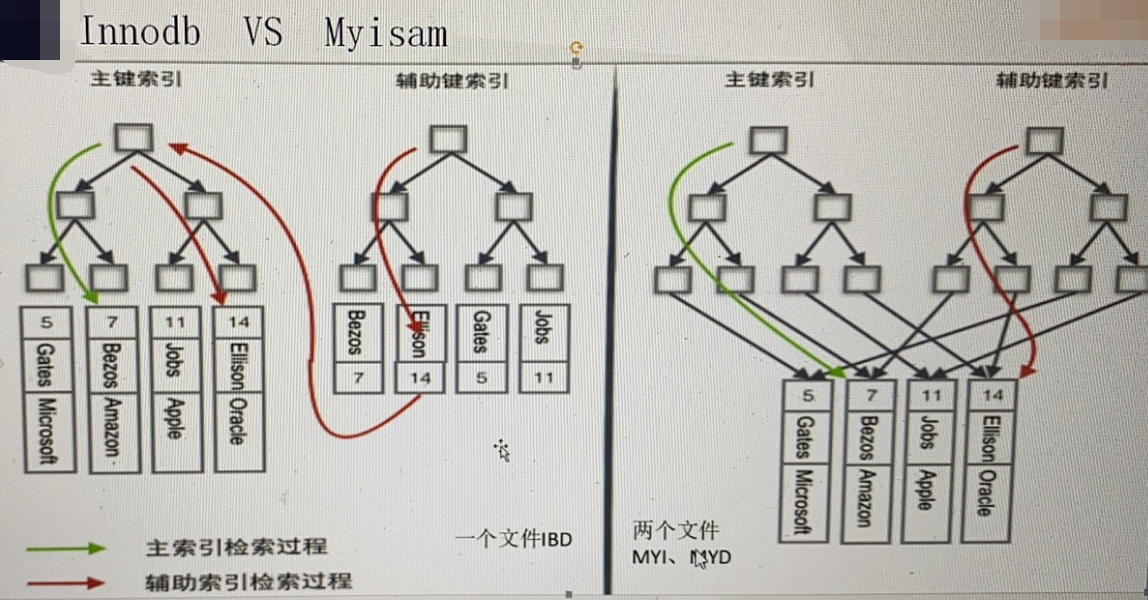
辅助索引 非聚集索引 二级索引
索引分裂
联合索引 最左匹配原则
覆盖索引 不查找完整数据 不需要查找聚集索引
Hash算法
Hash表 根据查询频率 innode做的优化 O(1)
自适应hash索引
6 锁
共享锁 S select * in share mode 其他事务只能读不能修改
排他锁 X select ** for update | insert | update |delete 其他事务不能读 也不能修改
意向排他锁 IX 如果想对行进行X锁 先要对数据库 表 页加上IX锁
行锁 实际是给索引项加锁;使用到索引时 使用行锁 ;没有使用则使用表锁;
意向共享锁 IS
行锁的三种算法
record lock 单行 主键 命中记录 锁单行
gap lock 范围锁 记录不存在 退化为gap锁
next-key lock 查询的列是唯一索引的列 ,此时加锁 select * from t where a=5 for update, 另一个会话插入4 ok ,退化为record lock
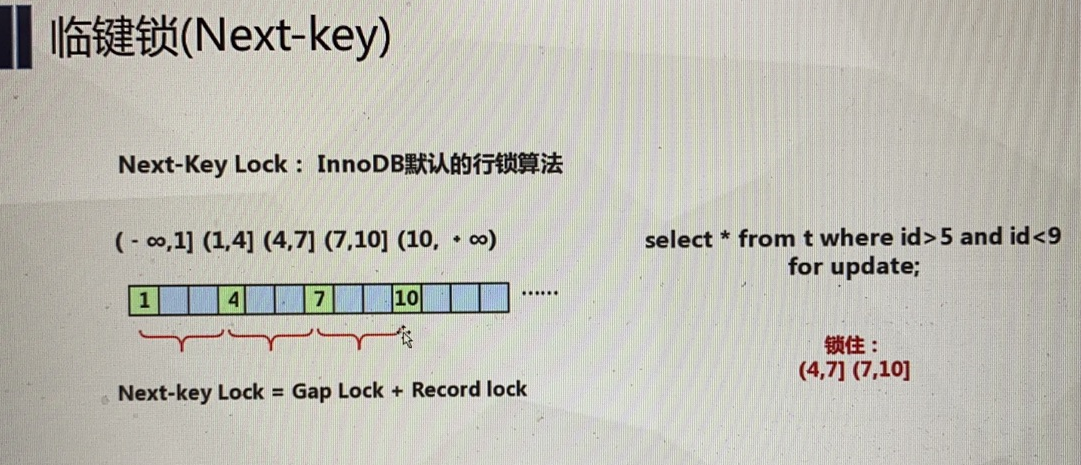
锁问题
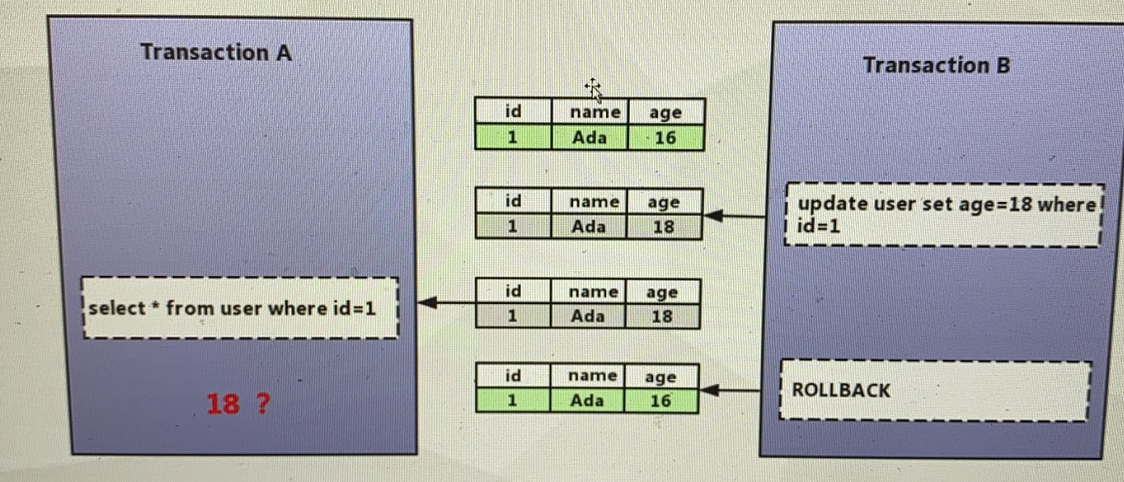
脏读 读到脏数据,读到其他事物未提交的数据 隔离级别为 read uncommited 违反隔离性 x锁
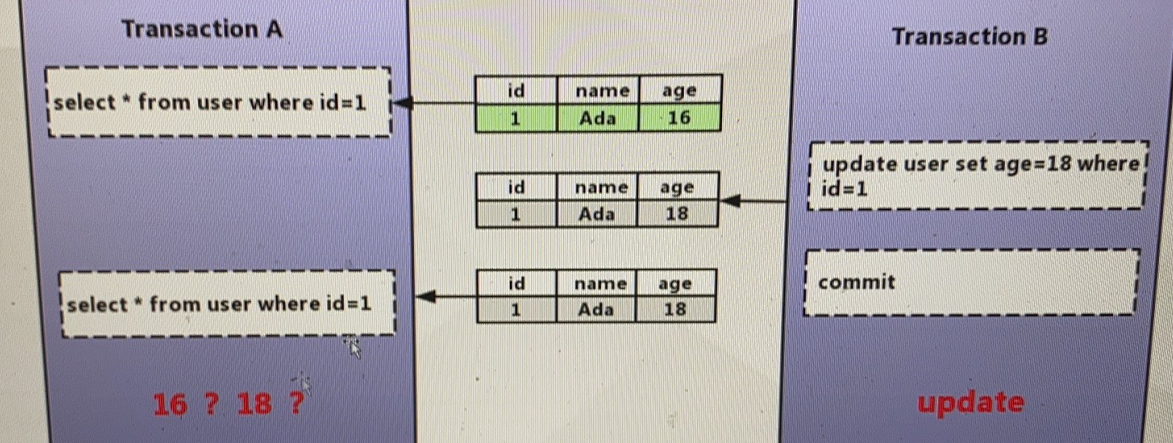
不可重复读 一次事务读到2次的结果不同 read commited 违反一致性 s锁
默认为read repeatable 采用next-key算法 避免不可重复读
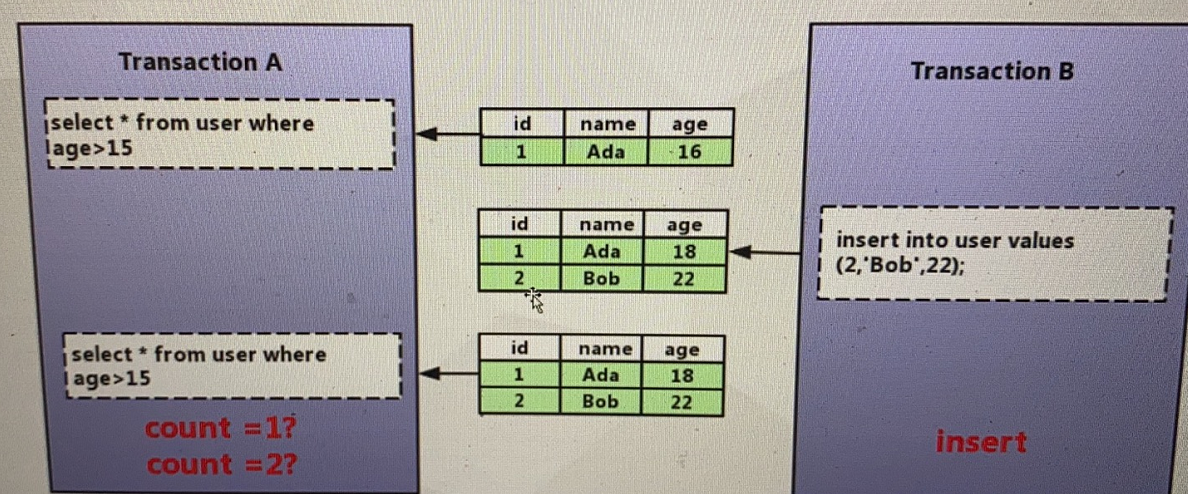
幻读 next-key lock
死锁
7 事务
A 2条语句一起成功 一起失败
C 一致性
I 隔离性
D 提交就永久保存
实现原理
redo 保证事务的持久性 重点是恢复 。
undo 帮助事务回滚(逻辑回滚,执行一个相反的操作,如果是物理回滚会影响其他事物)和mvcc(多个行快照版本)的功能 保存了事务之前的数据 用作快照
insert indo log insert purge后可以立刻删除
update undo log update delete 需要提供mvcc的功能 不能立刻删除
purge
fsync到磁盘
group commit
合并提交
快照读 select undo
当前读 select for update
事务控制语句
start Transcation | begin | set session autocommit=off;
commit
rollback
set transcation
隔离级别
三范式
1每一列不能拆分
2每一行可以根据主键区分
3每一行不包含其他非主键信息 (也就是说不容许冗余字段 做不到)
MVCC
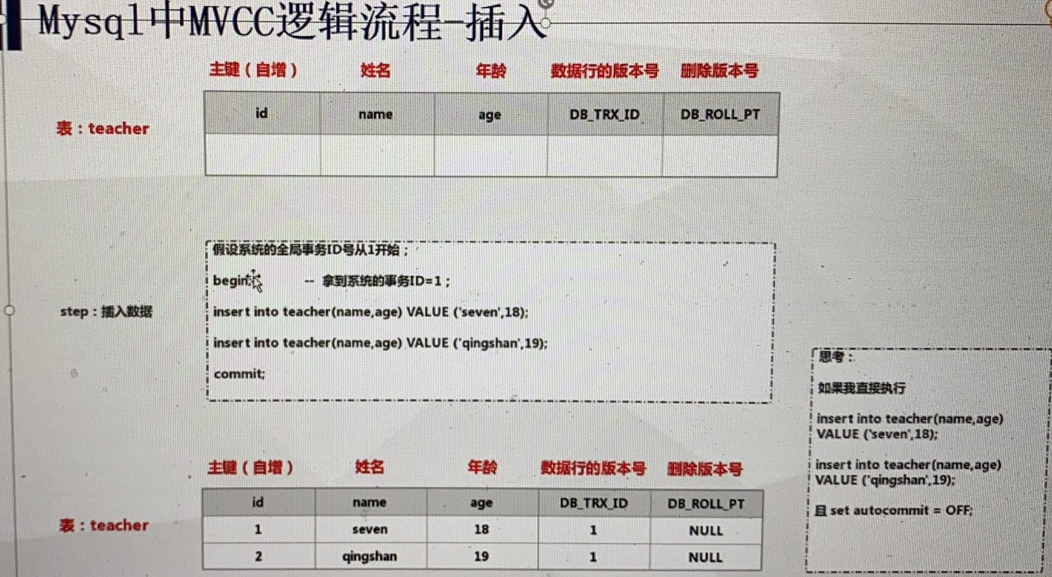
8 优化手段
索引优化
索引列不用函数
减少join数量
范围查询
不要使用 select *
最左匹配 :like 【最左匹配原则】
使用覆盖索引
使用联合索引
建立离散度高的索引 【离散度原则】
索引列的大小,定义越小 页数据越多,可以减少查询深度 电话号码(11位) 不要定义太大【空间最少原则】
explain分析
拆分 合并
调大查询缓存 show variables like '%query_cache%';
日统计
周统计
月统计
大数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号