

在我调试和研究 netscape 系浏览器插件开发时,注意到了这个问题。即,在对象布局已知(即对象之间具有继承关系)时,不同类型对象的指针进行转换(不管是隐式的从下向上转换,还是强制的从上到下转换)时,编译器会根据对象布局对相应的指针的值进行调整。不管是 microsoft 的编译器,还是 gcc 编译器都会做这个动作,因为这和 C++ 对象模型有关。
举一个简单的例子,如下代码:
#include <stdio.h> class A { public: int x; void foo1() { printf("A:foo1 \n"); }; }; class B : public A { public: double y; virtual void foo2() { printf("B:foo2 \n"); }; }; int main(int argc, char* argv[]) { B* pb = (B*)0x00480010; A* pa = pb; printf(" pb:%p\n pa:%p\n", pb, pa); getchar(); return 0; }
上面的代码内容为,B 继承于 A,A 没有虚函数,B 有虚函数。因此A对象的起始位置,不包含虚函数表指针。而 B 对象的起始位置,包含虚函数表指针。在 VC 2005 中,会输出:
pb:00480010
pa:00480018
可以看到两个地址之间的差值为 8 bytes。两个对象的地址并不相等,是因为虚函数表指针的关系。虚函数表指针通常占 4 Bytes。而输出结果中这个差值和对象布局有关,即也和编译器的选项中,对象的对齐的设置相关。但总之,这两个地址存在一个编译时确定的差值。在不同的条件下,这个差值也可能是 4 bytes。例如如果 B 对象的成员 y 改为 int 类型。这个差值就为 4 bytes。
在上面的 demo 中,指针类型从 B* 隐式转换到了 A*,地址值增加了 8 Bytes。如果指针类型从 A* 强制转换到 B*,这个地址也会进行相反的调整。观察汇编代码可以看到,这个地址值的偏移调整是编译器在编译时插入的操作,由 ADD / SUB 指令完成。这里,就不再显示其汇编代码了。
值得一提的是,在 C++ 中,struct 和 class 本质上没有区别,仅仅是成员的默认访问级别不同。所以上面的代码中,把任何一个对象在声明时,使用 class 或者 struct 关键字,都不影响结论。
上面的例子简要的说明了在对象具有继承关系时,指针转换过程中,地址值可能发生调整,这个动作是编译器完成的。上面的例子,对象之间的地址差异,是由对象头部是否含有虚函数表指针造成的。下面我要举一个更详细的例子来进一步说明这个问题。即,如果一个对象实例包含多个子对象(具有多个父类)时的地址调整。以及为什么在这种情况下,对象的析构函数必须为 virtual 函数。
第二个例子的代码如下:
#include <string.h> #include <stdio.h> //Parent 1 class P1 { public: int m_x1; int m_x2; int m_x3; public: P1() { m_x1 = 0x12345678; m_x2 = 0xAABBCCDD; m_x3 = 0xEEFF0011; printf("P1 constructor.\n"); } virtual ~P1() { printf("P1 destructor.\n"); } virtual void SayHi() { printf("P1: hello!\n"); } }; //Parent 2: 16 Bytes class P2 { public: char m_name[12]; public: P2() { strcpy(m_name, "Jack"); printf("P2 constructor.\n"); } virtual ~P2() { printf("P2 destructor.\n"); } virtual void ShowName() { printf("P2 name: %s\n", m_name); } }; //Parent 3: 16 Bytes class P3 { public: char m_nick[12]; public: P3() { strcpy(m_nick, "fafa"); printf("P3 constructor.\n"); } virtual ~P3() { printf("P3 destructor.\n"); } virtual void ShowNick() { printf("P3 Nick: %s\n", m_nick); } }; //Child1 class C1 : public P1, public P2, public P3 { public: int m_y1; int m_y2; int m_y3; int m_y4; public: C1() { m_y1 = 0x01; m_y2 = 0x02; m_y3 = 0x03; m_y4 = 0x04; printf("C1 constructor.\n"); } virtual ~C1() { printf("C1 destructor.\n"); } virtual void SayHi() { printf("C1: SayHi\n"); } virtual void C1_Func_01() { printf("C1: C1_Func_01\n"); } }; int main(int argc, char* argv[]) { C1 *c1 = new C1(); P1 *p1 = c1; P2 *p2 = c1; P3 *p3 = c1; p1->SayHi(); printf("c1: %p\np1: %p\np2: %p\np3: %p\n", c1, p1, p2, p3); //show object's binary data unsigned char* pBytes = (unsigned char*)(c1); //_CrtMemBlockHeader *pHead = pHdr(pBytes); size_t cb = sizeof(C1); unsigned int i; for(i = 0; i < cb; i++) { printf("%02X ", pBytes[i] & 0xFF); if((i & 0xF) == 0xF) printf("\n"); } printf("\n"); //_CrtDumpMemoryLeaks(); delete p2; return 0; }
第二个例子的主要内容是:子类 C1,具有三个父类:P1,P2,P3。所有类均具有虚析构函数,即对象实例有虚函数表指针。下图显示的是,类的继承关系:
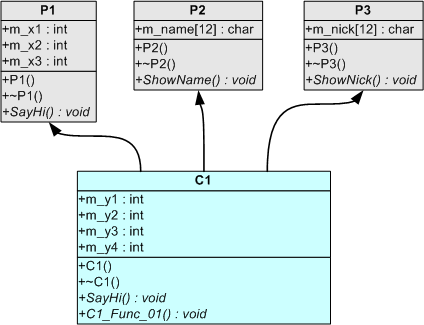
图 1. 第二个范例中的类继承关系
当类 C1 被构造时,它将含有三个子对象:P1,P2,P3。我们知道,第一个父类 P1 的虚函数表指针,是采用了 C1 的虚函数表指针的,即子类具有对父类虚函数的覆盖能力,这就是 C++ 中实现多态的重要部分。因此在 C1 对象实例中,实际上没有 P1 的虚函数表指针。而是直接采用了子类的。那么 P2 和 P3 也是 C1 的父类,P2 和 P3 的虚函数表内容如何获取呢?这就涉及到了 C++ 对象模型。
P2,P3 的虚函数表不能和 C1 的虚函数表内容合并,这会使得编译器很难实现对 P2,P3 的虚函数的调用。而是将其向后偏移,即除了第一个父类,其他父类要在对象中各自保留一个独立的虚函数表指针。即对象具有 P2,P3 的独立视角。在这个例子中,对象一共具有三个虚函数表指针,三个视角:P1/C1,P2,P3。对象模型如下图所示:

图2. 具有多个“独立”子对象的对象模型
请注意图中,在 P2,P3 的析构函数,都有插入了地址调整代码。这样,当我们用 P2 或 P3 的指针,指向一个实际的 C1 实例时,对这个指针调用 delete,都能够以正确的实例地址调用到 C1 的析构函数。
在此范例中,C1 具有三个“独立”的子对象 P1~P3,这里“独立”的意思是指 P1~P3 没有从属性的继承关系(即 P1~P3 之间,没有一个类是另一个类的祖先/后代)。这就使得在模型中,子对象的地址发生向后偏移,而不能共用同一个虚函数表指针/视角。
上图给出 C1 的实例的对象模型。当把指向 C1 的指针,转换到指向 P2 或 P3 的指针时,前面已经说过,这时候编译器已经插入了对地址值的调整。在这个例子中,我通过设置成员变量占用空间的大小,使得地址偏移值分别为 0x10,0x20。上面的代码产生的输出如下(在 Windows 中使用 VC 编译或在 Linux 下使用 g++ 编译得到的结果相似,仅对象被动态分配的地址值不同 ):
P1 constructor. P2 constructor. P3 constructor. C1 constructor. C1: SayHi c1: 003E5068 p1: 003E5068 p2: 003E5078 p3: 003E5088 B8 76 41 00 78 56 34 12 DD CC BB AA 11 00 FF EE A8 76 41 00 4A 61 63 6B 00 CD CD CD CD CD CD CD 98 76 41 00 66 61 66 61 00 CD CD CD CD CD CD CD 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 C1 destructor. P3 destructor. P2 destructor. P1 destructor.
在输出的中间部分,给出了对象的二进制内容,即将其 dump。可以看到第一行为 P1/C1 视角。第二行为 P2 视角,第三行为 P3 视角。第四行为 C1 的成员变量。
同时可以看到,再对 P2* 的指针调用 delete 时,对象能够正确的析构。这是因为编译器在构造 C1 对象时,因为 P2,P3 的析构函数是虚函数,所以编译器对其析构函数也加入了地址调整处理。由于编译器已知 P2,P3 相对于 C1 的布局,所以它知道对象真正的内存起点,因此它在代码段中插入了对应的 trunk 代码,即将对象地址减去偏移值后,得到对象实际地址,然后跳转到 C1 的析构函数。以上结论是通过反汇编 debug 版本的输出结果得到的。这里,对汇编代码的展示和分析省略。
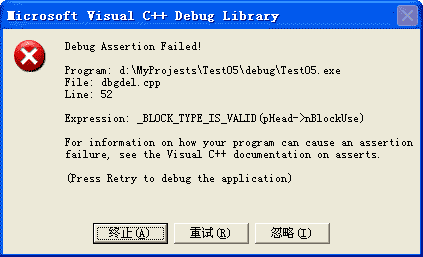
假设去掉 P2 的析构函数的 virtual 关键字,则运行上面的代码就会弹出错误。因此这时编译器直接把 P2 指针的值当做一个实际的 P2 对象地址,来进行析构,即它会尝试 free 这个地址值。而很显然这样是错误的。在 debug 模式下,会弹出如下的 assertion fail 对话框:
因此,从上面的例子中可以看到,类的虚构函数为什么要定义成虚函数。在 effective c++ 书中,对此是这样说的,如果虚构函数不是虚的,则这个对象可能只是被半析构。当然对于一个普通的单一继承的对象来说,如果实例只有一个虚函数表指针,如果子类中都是基本数据类型不需要额外处理,实际上这样也不会导致什么问题。因为分配内存时,在内存前面的信息块已经描述了内存的大小。所以释放内存的环节不会出错。但如果子类对象的成员中也需要释放,则这时会发生问题。例如某个成员指向动态申请的内存,则很显然这时它们会成为内存泄露状态。
结论:
通过以上分析,可以看到,
(1)在具有继承关系的类型之间进行指针类型转换,编译器在转换时添加了地址调整。
(2)当存在多个父类且父类虚构函数是虚函数时,由于子对象相对于对象基址发生了偏移,所以编译器也会为每个具有偏移的父类视角(没有排在父类列表的首位),插入一段 trunk 代码,先调整地址为实际对象地址,然后再跳转到实际对象的析构函数,从而保证对象正确被析构。
补充讨论:
在第二个例子中,编译器在 C1 的构造和析构函数中,也会同样进行相关的地址调整。例如在 C1 的构造函数中,编译器负责插入对 C1 的所有父类的构造函数的调用(构造/析构函数只负责传入的对象地址进行初始化,不负责内存分配/释放)。由于 P2,P3 视角相对于对象 C1 的地址存在偏移,所以调用 P2,P3的构造函数时,也会相应的调整对象地址到对应视角,这是显而易见的。如下是 C1 的构造函数的 VC debug 版本的反汇编片段:
可以看到,在分别调用 P1,P2,P3 的构造函数时,构造函数实际上也为对象头部填充了虚函数表的地址(这时候 P2,P3 构造函数填充的都是实际的 P2,P3 的虚函数表地址),然后编译器负责的部分,对 P1,P2,P3 的虚函数表指针再次赋值。这时候 P1 的虚函数表指针实际指向了 C1 的虚函数表。P2,P3 视角的虚函数表指向了专为 C1 定制的虚函数表(这些定制的虚函数表,只有析构函数入口是特殊的,其他部分和原虚函数表内容相同)。
mov [ebp+var_14], ecx mov ecx, [ebp+var_14] call sub_4110AA ; 调用 P1_Constructor mov [ebp+var_4], 0 mov ecx, [ebp+var_14] add ecx, 10h call sub_4110B9 ; 调用 P2_Contructor mov byte ptr [ebp+var_4], 1 mov ecx, [ebp+var_14] add ecx, 20h call sub_4110BE ; 调用 P3_Contructor mov eax, [ebp+var_14] mov dword ptr [eax], offset off_4176B8 ; 重设 P1/C1 vftable 地址 mov eax, [ebp+var_14] mov dword ptr [eax+10h], offset off_4176A8 ; 重设 P2 视角 vftable 地址 mov eax, [ebp+var_14] mov dword ptr [eax+20h], offset off_417698 ; 重设 P3 视角 vftable 地址 mov eax, [ebp+var_14] ; 以下是用户编写的 C1 构造函数的内容 mov dword ptr [eax+30h], 1 mov eax, [ebp+var_14] mov dword ptr [eax+34h], 2 mov eax, [ebp+var_14] mov dword ptr [eax+38h], 3 mov eax, [ebp+var_14] mov dword ptr [eax+3Ch], 4 mov esi, esp push offset aC1Constructor_ ; "C1 constructor.\n" call ds:printf add esp, 4
如果父类 P1 的析构函数是非虚的,子类 C1 的析构函数是虚的,这时候的行为是比较古怪的,即 C1 的虚函数表中也没有 C1 的析构函数了(看起来要让子类具有虚析构函数,它的父类也必须首先具有虚析构函数才行)。这时候如果用 P1 指针,析构 C1 对象,则实际上只会调用 P1 的析构函数,然后(假设对象由 new 操作符分配)由 delete 运算符负责释放对象所占用的内存。即造成 C1 对象被半析构的结果。这是 P1 的虚函数表被 C1 重叠覆盖的较好结果。如果对象视角之间存在偏移(例如用 P2 指针 delete C1 对象,且 P2 的析构函数为非虚),则 delete 时,由于释放内存时的地址,并不是实际分配时返回的地址,因此可以肯定,必然导致运行时错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号