

备注:本文使用的范例代码来自《系统设计师教程》(王春森主编),本文性质属于我的对引用代码的注释和分析,因此并非原创。本文的部分先发表于中国编程论坛。
(一)用栈前序遍历树
对这篇文章的来源性说明:理论和代码来源,《系统设计师教程》(王春森主编),文章内容来自我对书中代码的分析和手工注释。
( 本文献给小师妹:littlehead(我是大好人))
名词:栈,遍历,前序遍历,树。
(1)准备:树的定义省略。但是由于数的定义属于递归型定义,即树的每个子节点又是一棵树,所以这个递归型的定义使对树的很多操作通常都可以用递归算法来实现。对数节点的定义,一个节点含有一个数据,这里以一个字符数据作为示范,假设一个节点最多含有M个子节点(M成为树的次数),则节点定义为:
typedef struct tnode
{
char data;
struct tnode *child[M];
} TNODE;
我们对用根节点指针来持有和处理一棵树:即:
TNODE *root;
前序遍历和后序遍历:遍历值得是依次输出所有节点数据。前序后序中的序指的是本节点和其子节点之间的输出顺序关系。对于普通树来说存在前序,后序两种遍历。对二叉树来说又有中序遍历。
(2)我们先给出前序遍历的伪码为:
void pre_order(TNODE *t, int m) //m为数次数
{
if(t!=NULL) 打印t; //先输出本节点
for(i=0;i<m;i++)
pre_order(t->child[i],m); //前序输出所有子节点
}
/*--------------------------------
root-> 1
/ | \
2 3 4
/ \ |
5 6 7
/ \
8 9
----------------------------------*/
对于图1所示的树,则其前序遍历和后序遍历如下:
( 本文献给小师妹:littlehead(我是大好人))
名词:栈,遍历,前序遍历,树。
(1)准备:树的定义省略。但是由于数的定义属于递归型定义,即树的每个子节点又是一棵树,所以这个递归型的定义使对树的很多操作通常都可以用递归算法来实现。对数节点的定义,一个节点含有一个数据,这里以一个字符数据作为示范,假设一个节点最多含有M个子节点(M成为树的次数),则节点定义为:
typedef struct tnode
{
char data;
struct tnode *child[M];
} TNODE;
我们对用根节点指针来持有和处理一棵树:即:
TNODE *root;
前序遍历和后序遍历:遍历值得是依次输出所有节点数据。前序后序中的序指的是本节点和其子节点之间的输出顺序关系。对于普通树来说存在前序,后序两种遍历。对二叉树来说又有中序遍历。
(2)我们先给出前序遍历的伪码为:
void pre_order(TNODE *t, int m) //m为数次数
{
if(t!=NULL) 打印t; //先输出本节点
for(i=0;i<m;i++)
pre_order(t->child[i],m); //前序输出所有子节点
}
/*--------------------------------
root-> 1
/ | \
2 3 4
/ \ |
5 6 7
/ \
8 9
----------------------------------*/
对于图1所示的树,则其前序遍历和后序遍历如下:

前序:1,2,5,6,3,4,7,8,9;
后序:5,6,2,3,8,9,7,4,1;
(3)采用栈来代替递归函数的方法如下:
方法:每出栈一个节点,打印该节点,然后则将其所有子节点逆序(从右到左)入栈。
初始栈状态:根节点入栈。栈中仅有根节点。栈顶指针top=1;
结束条件:栈为空。即栈顶指针top=0;
其相关代码如下 :
后序:5,6,2,3,8,9,7,4,1;
(3)采用栈来代替递归函数的方法如下:
方法:每出栈一个节点,打印该节点,然后则将其所有子节点逆序(从右到左)入栈。
初始栈状态:根节点入栈。栈中仅有根节点。栈顶指针top=1;
结束条件:栈为空。即栈顶指针top=0;
其相关代码如下 :
遍历时的栈中节点状态如图2所示(蓝色箭头表示栈顶,每一行表示栈在当前的一个状态)。

(二)用队列按层次遍历树
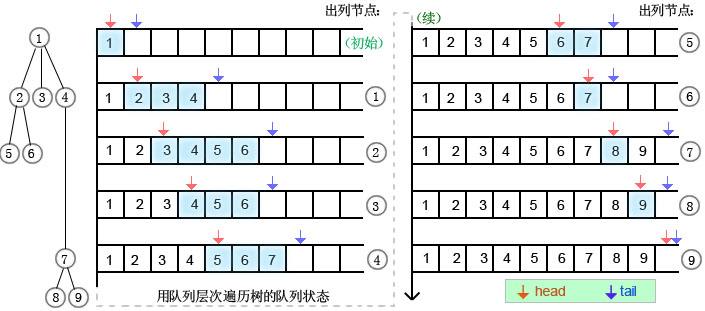
(1)按层次遍历树。层次,即相当于资源管理器的文件夹深度,见前文图1中的纵坐标。由于在示例树中的节点编号就是按照层次来给出的,所以按层次遍历这棵树的结果就是:1,2,3,4,5,6,7,8,9。
由于我们在遍历过程中处于树的某个局部,因此我们需要引入一个辅助数据结构来帮助我们完成遍历。考虑到层次遍历的特点是,每一层次的所有子节点应该集中在一起,当访问某个节点时,其下一层次的子节点应该处于等待被访问的状态。因此我们应该引入队列作为辅助存储。
方法如下:

队列我们同样用一个数组来模拟,并且需要两个变量head和tail来标识队列的有效区间,队列的特点是FIFO(先入先出),因此,子序列入队是顺序入队(和前文中用栈前序不同,由于栈的特点是FILO或者LIFO,所以子节点是逆序入栈的)。有效队列在数组中处于移动状态,在head,tail在移动到数组末尾时,重新指向数组前部,所以代码中这里有个索引自增后对队列长度取余的运算,因此实际上这里的队列在逻辑上是环形的,也就是数组的首尾相接,因此只有向队首或者向队尾两种移动方向的区别,而队列位于数组的什么位置并不重要(比如队列可能会一部分位于数组末端,一部分位于数组起始处,在内存视角上看不是连续的,但在逻辑上依然是连续的)。
下面我们看相关的代码:
(2)关于树的少许补充:
2.1 二叉查找树和堆的结构看起来一样,但是区别是,二叉查找树:左子<=根<=右子; 而堆是:子节点<=根。另外,堆在逻辑上是树形,但存储是用数组存储的(节点按层次连续存入数组)。
2.2 中序遍历二叉查找树,输出的一个有序结果。
2.3 用作图法按前序,后序遍历树的规律:
假设我们把二叉树的一个节点提取出来,我们看出,从节点中心垂直向上定义为0度角,逆时针正向,则节点的左右子树分支分别为120度(左子树)和240(右子树)。则我们可以用作图法得到各种序遍历的节点输出角度:从根节点上方向左下方画一条线外围住所有节点直到返回根节点,当线条经历到节点的以下角度时输出该节点(如图3所示,前序输出为1,2,4,5,3,6):
前序输出角度:60度;
中序(仅针对二叉树):180度;
后序:300度。
2.1 二叉查找树和堆的结构看起来一样,但是区别是,二叉查找树:左子<=根<=右子; 而堆是:子节点<=根。另外,堆在逻辑上是树形,但存储是用数组存储的(节点按层次连续存入数组)。
2.2 中序遍历二叉查找树,输出的一个有序结果。
2.3 用作图法按前序,后序遍历树的规律:
假设我们把二叉树的一个节点提取出来,我们看出,从节点中心垂直向上定义为0度角,逆时针正向,则节点的左右子树分支分别为120度(左子树)和240(右子树)。则我们可以用作图法得到各种序遍历的节点输出角度:从根节点上方向左下方画一条线外围住所有节点直到返回根节点,当线条经历到节点的以下角度时输出该节点(如图3所示,前序输出为1,2,4,5,3,6):
前序输出角度:60度;
中序(仅针对二叉树):180度;
后序:300度。

(三)图的遍历
图是一种复杂数据结构,图需要存储节点与节点之间的关联关系,主要有矩阵和链表两种存储方法。这里采用链表,针对每个节点都存储一个链表,链表中表示的是所有和该节点有链接的其他节点号。因此我们需要一个指针数组来存储所有链表。代码如下:
针对下面这张图:

程序的输出如下:
dfs: 0, 4, 3, 2, 1, (深度优先遍历)
bfs: 0, 4, 3, 1, 2, (广度优先遍历)
Graph g: (图g的所有节点链表)
g[0]: 4 - 3 - 1 - NULL
g[1]: 4 - 2 - 0 - NULL
g[2]: 4 - 3 - 1 - NULL
g[3]: 4 - 0 - 2 - NULL
g[4]: 3 - 2 - 1 - 0 - NULL

