

Shell脚本编程
shell入门:扎好马步,走的更稳
自定义变量


位置变量



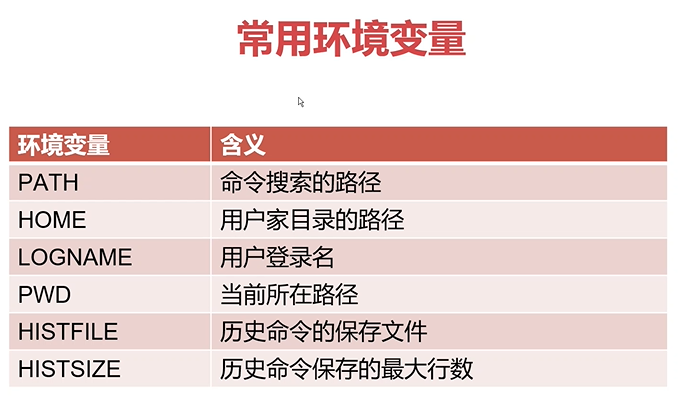
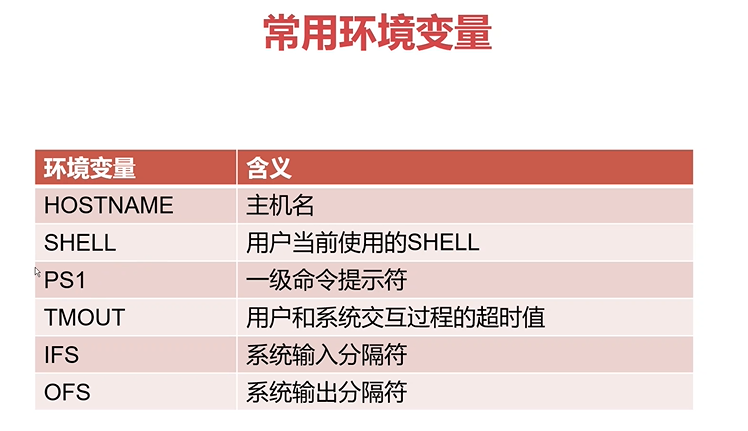
环境变量


管道

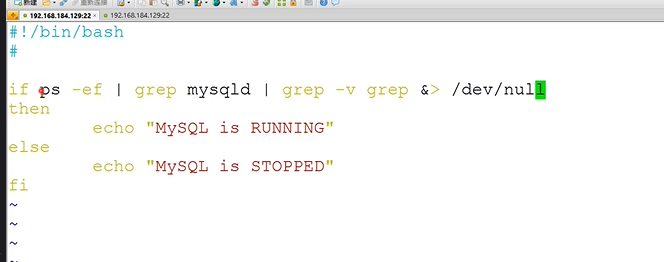
示例:ps -ef | grep nginx | grep -v grep
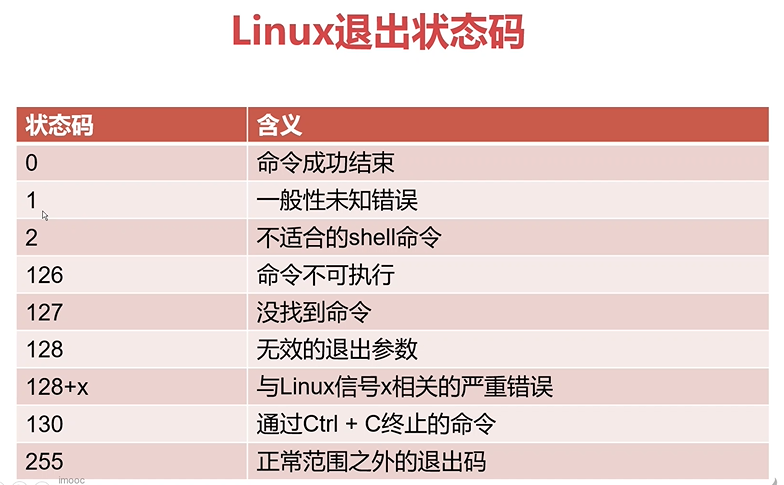
退出状态码


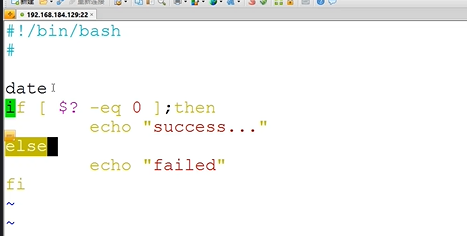
改变退出状态码的exit命令


程序的转折点:判断与控制
使用if-then语句


使用if-then-else语句

tips:
1."&>/dev/null"的作用
把所有输出重定向到垃圾桶中,不在输出到标准屏幕
2.为什么需要加"&"?
>等价于1>,这个仅仅只是将标准输出重定向,但是标准错误输出并没有重定向,因此如果想要把执行命令或者脚本过程所有信息重定向(不管正确还是错误),可以这样sh 1.sh 1> /dev/null 2> /dev/null,对应的也有简化写法 sh 1.sh &> /dev/null
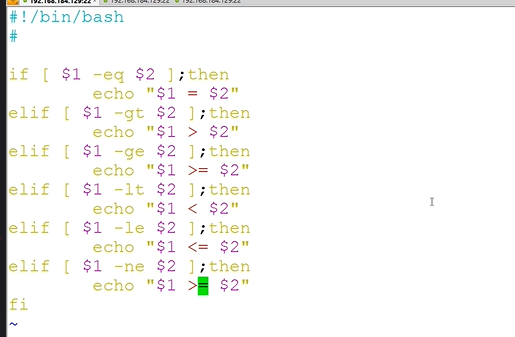
嵌套if


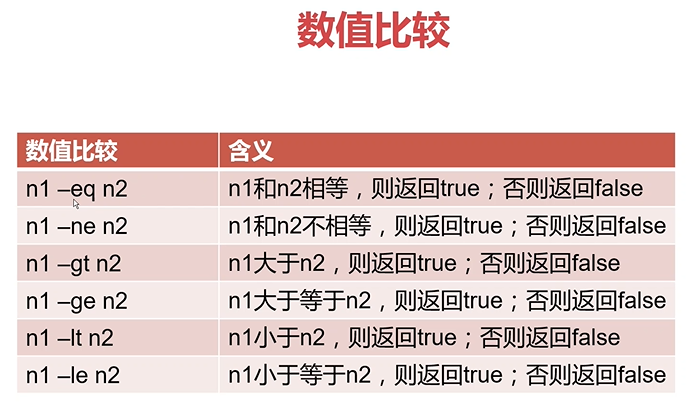
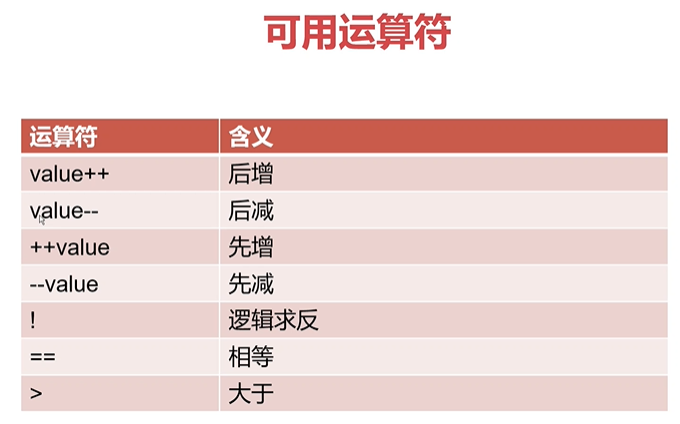
条件测试-数值比较
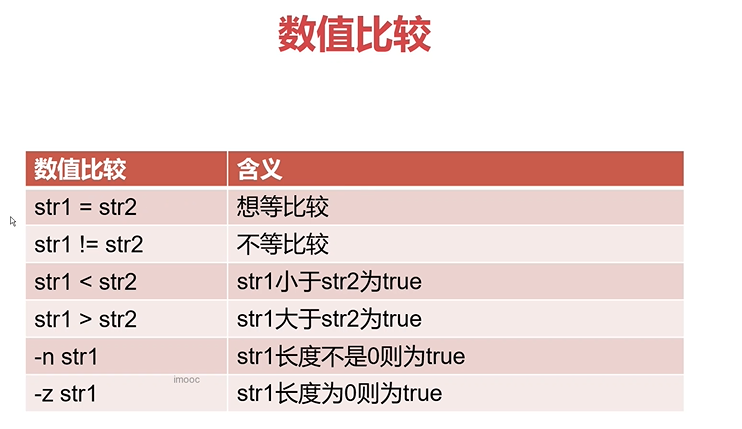
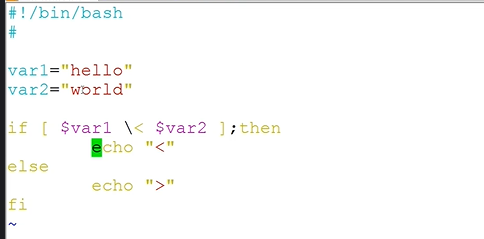
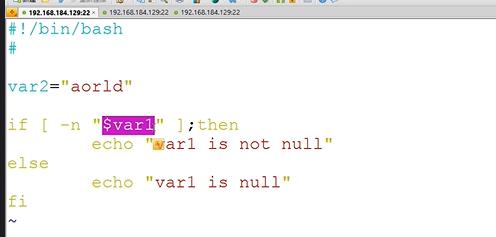
条件测试-字符串比较
tips:
1.注意">","<"符号在shell中是重定向符号,需要进行转义
2.只有字符串比较才可以使用">","<",如果在数值比较中使用">"或者"<",也会被默认当成字符串间的比较,从而无法得到预期结果
2.注意"$var1"要加上双引号,否则当var1未定义时,会变成"if [ -n ];then"
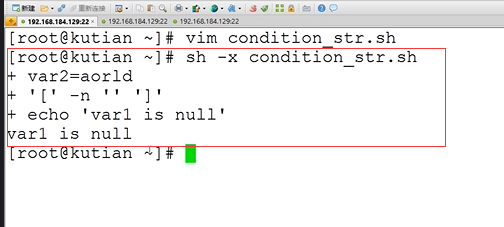
3.sh -x 可以查看详细执行过程
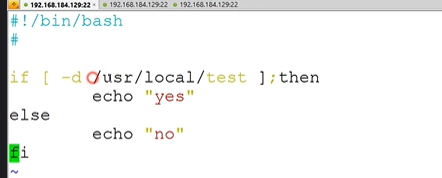
条件测试-文件比较



复合条件测试


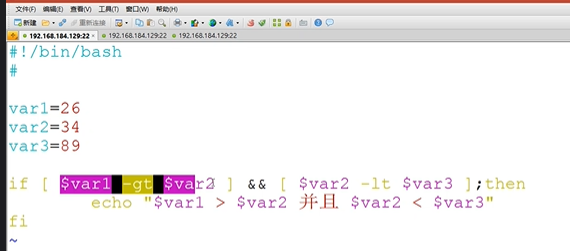
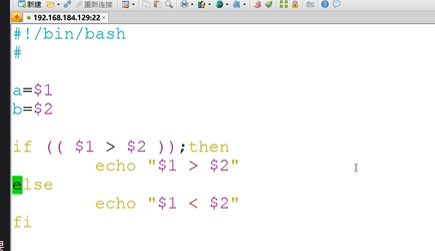
if-then中使用双括号



if-then中使用双方括号


case命令

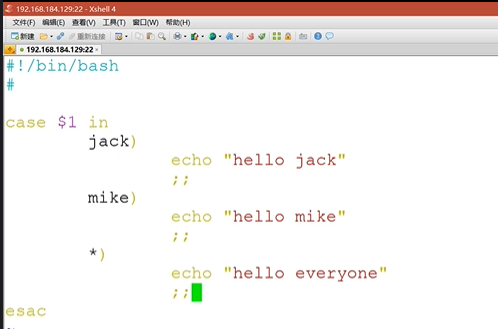
tips:
1.注意有双分号";;"用来表示一个枚举情形的结束
2.注意结尾有esac,实际上就是"case"反过来
3.可以使用数字,字符串,或者正则表达式作为枚举值
一切编程的基石:循环与控制
for命令

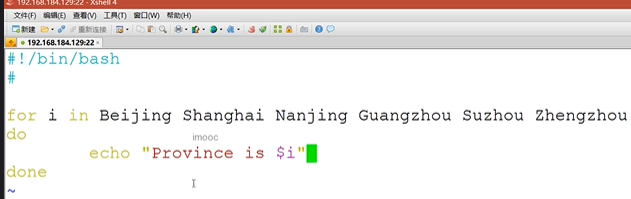
for循环读取列表值
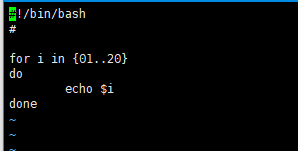
for循环读取变量的值
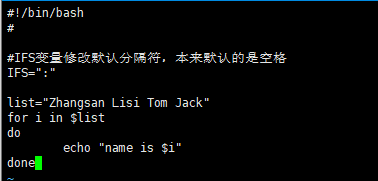
for循环从命令执行结果读取值

C语言风格的for命令

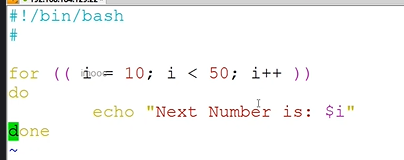
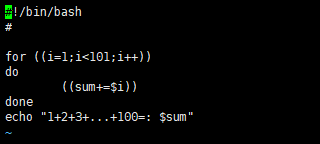
while循环命令


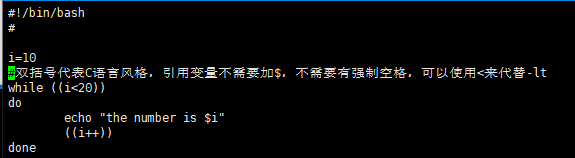
until命令

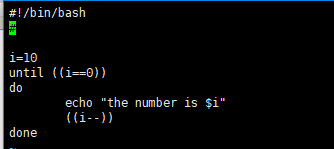
tips:while和untile的区别:
1.while是满足条件时执行
2.until是直到满足条件时终止(并不是先执行一次再判断,如果一开始就满足了终止条件,则一次都不会执行,不同于VB语言)
循环控制的break指令
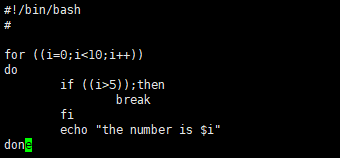
tips:
break指令通过指定参数可以跳出多重循环,默认跳出当前循环,即默认参数为1. 举例:break 2 表示跳出两层循环
循环控制的continue指令
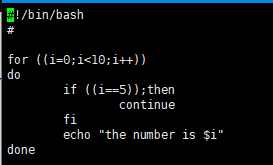
·tips:
break和continue的区别:
1.break是跳出循环体
2.continue是跳出当次循环,执行下一次循环
3.两者都可以通过参数,默认为1
处理循环的输出

变量的高级用法
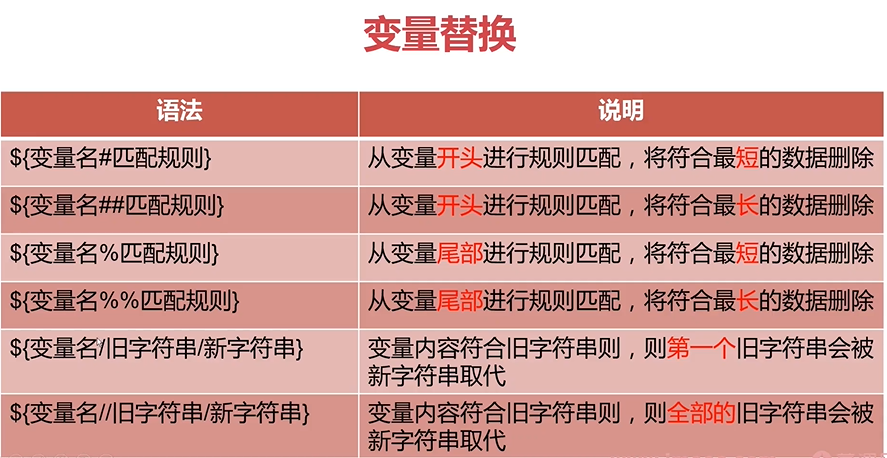
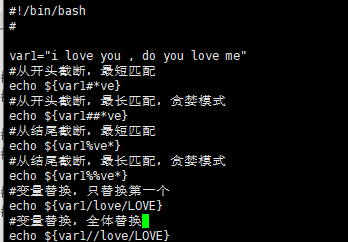
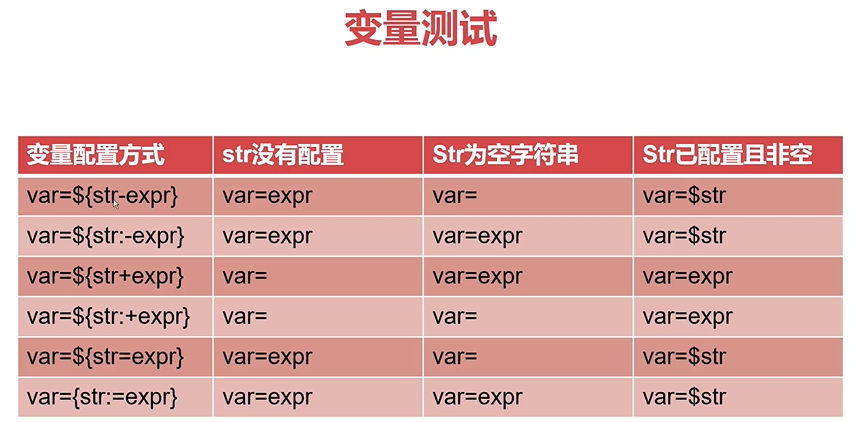
变量替换和测试


字符串处理



1、计算字符串长度
方法一:${#string}
方法二:expr length $string
例子:
var1="Hello World"
len=${#var1}
len=`expr length "$string"`
2、获取字符索引位置
方法:expr index "$string" substr
例子:
var1="quicstart is a app"
ind=`expr index "$var1" start`
3、获取子串长度
方法:expr match "$string" substr
例子:
var1="quicstart is a app"
sub_len=`expr match "$var1" app`
4、抽取字符串中的子串
方法一:
(1)、${string:position}
(2)、${string:position:length}
(3)、${string: -position} 或者 ${string:(position)}
方法二:
expr substr $string $position $length
例子:
var1="kafka hadoop yarn mapreduce"
substr1=${var1:10}
substr2=${var1:10:6}
substr3=${var1: -5}
substr4=${var1: -10:4}
substr5=`expr substr "$var1" 5 10`
注意:使用expr,索引计数是从1开始计算;使用${string:position},索引计数是从0开始计数
字符串处理完整脚本
#!/bin/bash
#
string="Bigdata process framework is Hadoop,Hadoop is an open source project"
function tips_info
{
echo "*****************************"
echo "*** (1) 打印string长度"
echo "*** (2) 在整个字符串中删除Hadoop"
echo "*** (3) 替换第一个Hadoop为Mapreduce"
echo "*** (4) 替换全部Hadoop为Mapreduce"
echo "******************************************"
}
function print_len
{
echo "${#string}"
}
function del_hadoop
{
echo "${string//Hadoop/}"
}
function rep_hadoop_mapreduce_first
{
echo "${string/Hadoop/Mapreduce}"
}
function rep_hadoop_mapreduce_all
{
echo "${string//Hadoop/Mapreduce}"
}
while true
do
echo "【string=\"$string\"】"
tips_info
#输入交互,并赋值给choice变量
read -p "Please Switch a Choice: " choice
case "$choice" in
1)
print_len
;;
2)
del_hadoop
;;
3)
rep_hadoop_mapreduce_first
;;
4)
rep_hadoop_mapreduce_all
;;
q|Q)
exit
;;
*)
echo "error,illegal input,legal input only in {1|2|3|4|q|Q}"
;;
esac
done
命令替换

例子1:
获取系统得所有用户并输出
#!/bin/bash
#
index=1
for user in `cat /etc/passwd | cut -d ":" -f 1`
do
echo "This is $index user: $user"
index=$(($index + 1))
done
例子2:
根据系统时间计算今年或明年
echo "This is $(date +%Y) year"
echo "This is $(($(date +%Y) + 1)) year"
例子3:
根据系统时间获取今年还剩下多少星期,已经过了多少星期
date +%j
echo "This year have passed $(date +%j) days"
echo "This year have passed $(($(date +%j)/7)) weeks"
echo "There is $((365 - $(date +%j))) days before new year"
echo "There is $(((365 - $(date +%j))/7)) days before new year"
例子4:
判定nginx进程是否存在,若不存在则自动拉起该进程
#!/bin/bash
#
nginx_process_num=$(ps -ef | grep nginx | grep -v grep | wc -l)
if [ $nginx_process_num -eq 0 ];then
systemctl start nginx
fi
总结:``和$()两者是等价的,但推荐初学者使用$(),易于掌握;缺点是极少数UNIX可能不支持,但``都是支持的
$(())主要用来进行整数运算,包括加减乘除,引用变量前面可以加$,也可以不加$
$(( (100 + 30) / 13 ))
num1=20;num2=30
((num++));
((num--))
$(($num1+$num2*2))
有类型变量

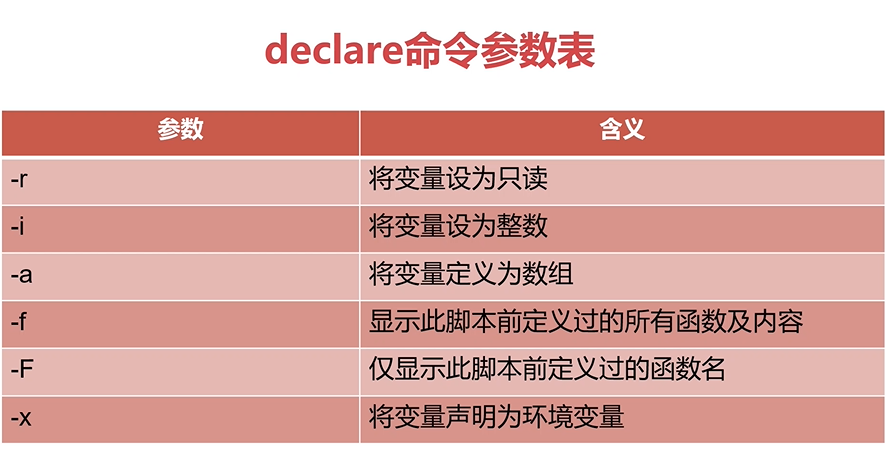
1、declare -r #声明变量为只读类型
declare -r var="hello"
var="world" -bash: var: readonly variable
2、declare -i #声明变量类型为整型
num1=2001
num2=$num1+1
echo $num2
declare -i num2
num2=$num1+1
echo $num2
3、declare -f 在脚本中显示定义的函数和内容 (无效)
4、declare -F 在脚本中显示定义的函数(无效)
5、declare -a
array=("jones" "mike" "kobe" "jordan")
输出数组内容:
echo ${array[@]} 输出全部内容
echo ${array[1]} 输出下标索引为1的内容
获取数组长度:
echo ${#array[@]} 数组内元素个数
echo ${#array[2]} 数组内下标索引为2的元素长度
给数组某个下标赋值:
array[0]="lily" 给数组下标索引为1的元素赋值为lily
array[20]="hanmeimei" 在数组尾部添加一个新元素
删除元素:
unset array[2] 清除元素
unset array 清空整个数组
分片访问:
${array[@]:1:4} 显示数组下标索引从1开始到3的3个元素,不显示索引为4的元素
内容替换:
${array[@]/an/AN} 将数组中所有元素内包含kobe的子串替换为mcgrady
数组遍历:
for v in ${array[@]}
do
echo $v
done
6、declare -x
声明为环境变量,可以在脚本中直接使用
取消声明的变量:
declare +r(无效)
declare +i
declare +a
declare +X
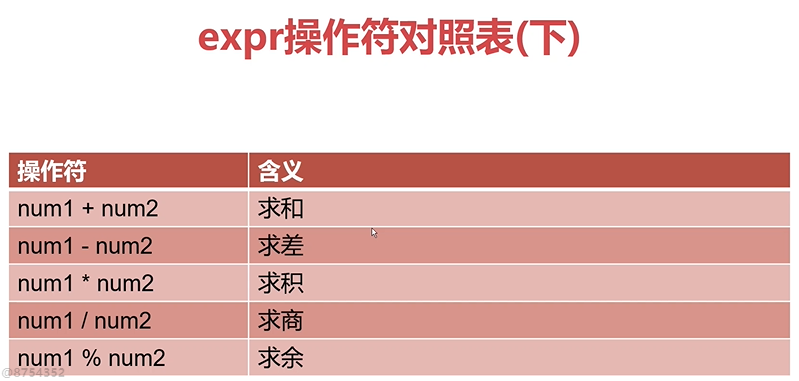
bash数学运算之expr


num1=20
num2=100
expr $num1 \| $num2
expr $num1 \& $num2
expr $num1 \< $num2
expr $num1 \< $num2
expr $num1 \<= $num2
expr $num1 \> $num2
expr $num1 \>= $num2
expr $num1 = $num2
expr $num1 != $num2
expr $num1 + $num2
expr $num1 - $num2
expr $num1 \* $num2
expr $num1 / $num2
expr $num1 % $num2
练习例子:
提示用户输入一个正整数num,然后计算1+2+3+...+sum的值;必须对num是否为正整数做判断,不符合应当允许再此输入

bash数学运算之bc

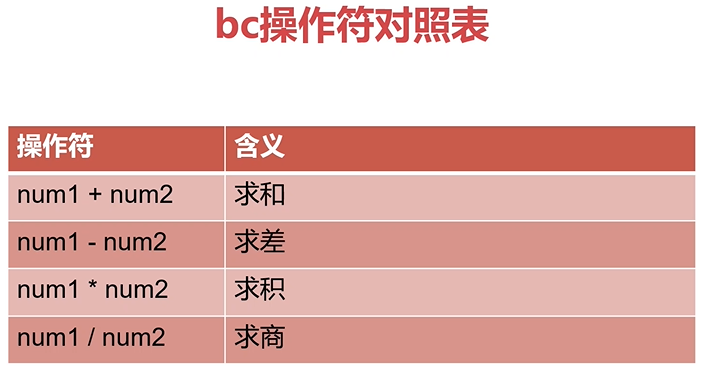

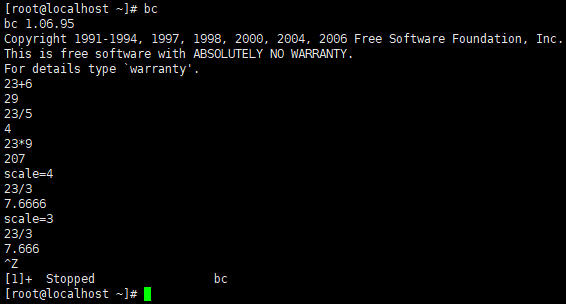
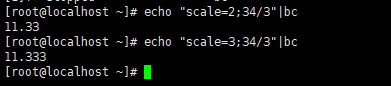

脚本中使用bc运算的语法:
echo "options;expression" | bc
num1=23.5
num2=50
var1=`echo "scale=2;$num1 * $num2" | bc`
函数的高级用法
函数定义和使用



向函数传递参数



函数返回值




局部变量和全局变量


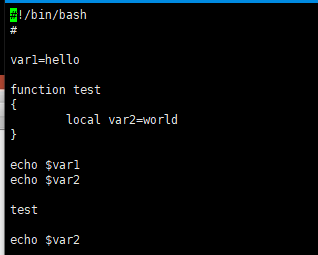

要点1:Shell脚本中,默认所有变量都是全局变量;即使函数内部定义的变量,一旦函数调用后,改变了就将一直存在,直到脚本执行完毕
要点2:定义局部变量,使用local关键字;
要点3:函数内部,变量会自动覆盖外部变量
编程习惯原则:
1、尽量在函数内部使用local关键字,将变量的作用于限制在函数内部
2、命名变量名时尽可能遵循实义性的,尽量做到见名知意
函数库

一个完整定义的函数库示例:
#!/bin/echo Warning:This is a library which should not be executed,only be sourced in you scripts
#
function print_platform
{
local osname=`uname -s`
PLATFORM=UNKNOW
case "$osname" in
"FreeBSD")
PLATFORM="FreeBSD"
;;
"SunOS")
PLATFORM="Solaris"
;;
"Linux")
PLATFORM="Linux"
;;
esac
echo $PLATFORM
}
引入函数库方法:在脚本中 .{函数库文件绝对路径}


shell编程中的常用工具
文件查找之find命令

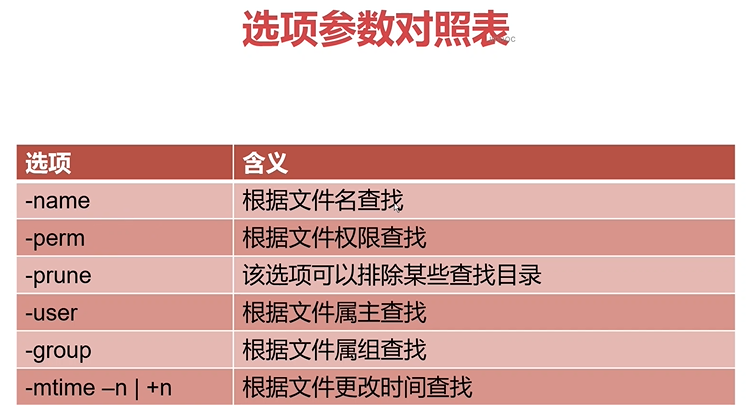
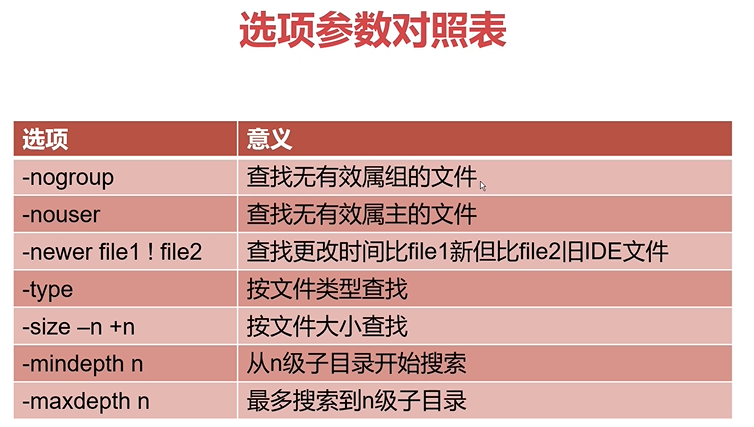
常用选项:
-name 查找/etc目录下以conf结尾的文件 find /etc -name '*conf'
-iname 查找当前目录下文件名为aa的文件,不区分大小写 find . -iname aa
-user 查找文件属主为hdfs的所有文件 find . -user hdfs
-group 查找文件属组为yarn的所有文件 find . -group yarn
-type
f 文件 find . -type f
d 目录 find . -type d
c 字符设备文件 find . -type c
b 块设备文件 find . -type b
l 链接文件 find . -type l
p 管道文件 find . -type p
-size
-n 大小于小于n的文件
+n 大小大于n的文件
例子1:查找/etc目录下小于10000字节的文件 find /etc -size -10000c
例子2:查找/etc目录下大于1M的文件 find /etc -size +1M
-mtime
-n n天以内修改的文件
+n n天以外修改的文件
n 正好n天修改的文件
例子1:查找/etc目录下5天之内修改且以conf结尾的文件 find /etc -mtime -5 -name '*.conf'
例子2:查找/etc目录下10天之前修改且属主为root的文件 find /etc -mtime +10 -user root
-mmin
-n n分钟以内修改的文件
+n n分钟以外修改的文件
例子1:查找/etc目录下30分钟之前修改的文件 find /etc -mmin +30
例子2:查找/etc目录下30分钟之内修改的目录 find /etc -mmin -30 -type d
-mindepth n 表示从n级子目录开始搜索
例子:在/etc下的3级子目录开始搜索 find /etc -mindepth 3
-maxdepth n 表示最多搜索到n-1级子目录
例子1:在/etc下搜索符合条件的文件,但最多搜索到2级子目录 find /etc -maxdepth 3 -name '*.conf'
例子2:
find ./etc/ -type f -name '*.conf' -size +10k -maxdepth 2
操作:
-print 打印输出
-exec 对搜索到的文件执行特定的操作,格式为-exec 'command' {} \;
例子1:搜索/etc下的文件(非目录),文件名以conf结尾,且大于10k,然后将其删除
find ./etc/ -type f -name '*.conf' -size +10k -exec rm -f {} \;
例子2:将/var/log/目录下以log结尾的文件,且更改时间在7天以上的删除
find /var/log/ -name '*.log' -mtime +7 -exec rm -rf {} \;
例子3:搜索条件和例子1一样,只是不删除,而是将其复制到/root/conf目录下
find ./etc/ -size +10k -type f -name '*.conf' -exec cp {} /root/conf/ \;
-ok 和exec功能一样,只是每次操作都会给用户提示
例子1:查找当前目录下,属主不是hdfs的所有文件
find . -not -user hdfs | find . ! -user hdfs
例子2:查找当前目录下,属主属于hdfs,且大小大于300字节的文件
find . -type f -a -user hdfs -a -size +300c
例子3:查找当前目录下的属主为hdfs或者以conf结尾的普通文件
find . -type f -a -user hdfs -o -name '*.conf'
find . -type f -a -user hdfs -o -name '*.conf' -exec ls -rlt {} \;
find . -type f -a \( -user hdfs -o -name '*.conf' \) -exec ls -rlt {} \;
完整脚本练习:
需求描述:提示用户输入一个目录,然后继续提示用户输入一个搜索文件的查询条件(文件名、文件大小),然后脚本可以将符合搜索条件的文件打印出来
继续提示用户是拷贝或删除这些文件,如果删除,则执行删除操作,同时将删除的文件记录到一个remove.list文件中;
如果是拷贝,则继续提示用户输入一个目标目录,然后执行拷贝动作
find,locate,whereis和which总结及适用场景分析





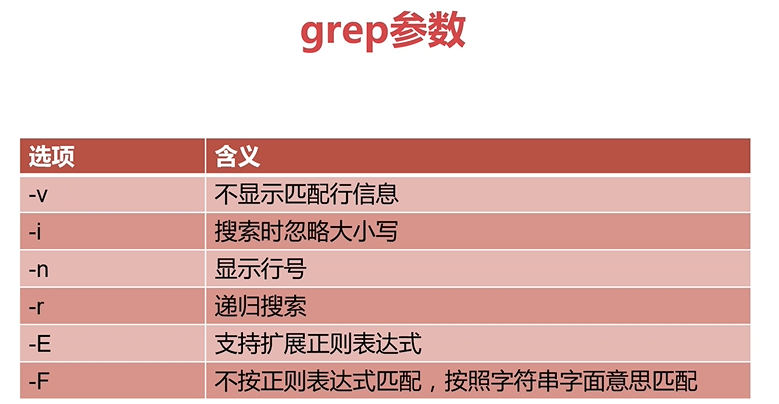
文本处理三剑客之grep
grep和egrep

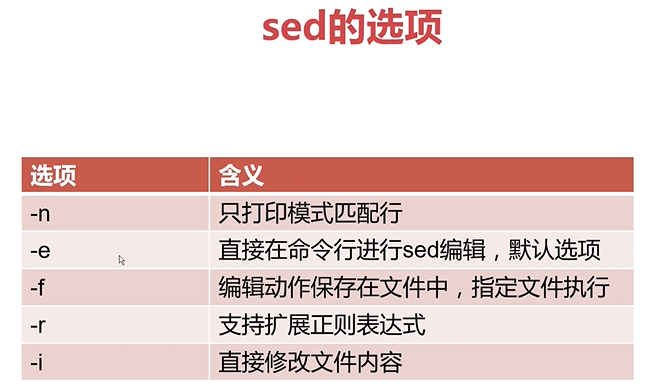
文本处理三剑客之sed
sed的工作模式


sed的选项
sed中的pattern详解
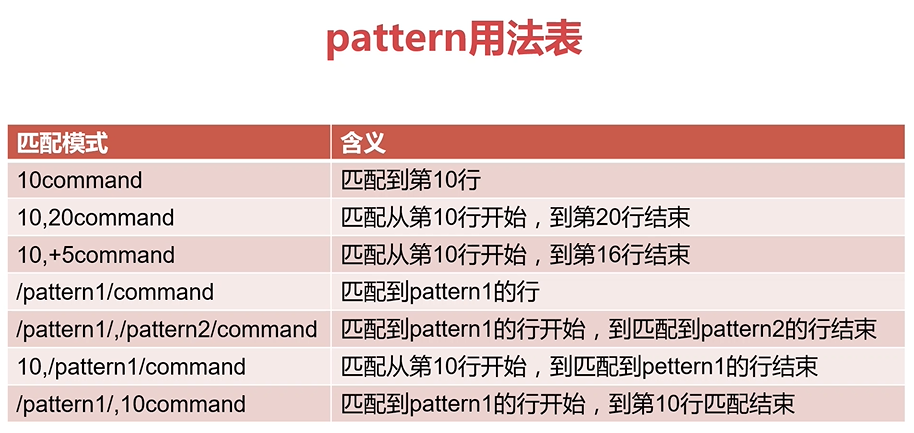
1、LineNumber ------------------直接指定行号
sed -n "17p" file 打印file文件的第17行
2、StartLine,EndLine ------------------指定起始行号和结束行号
sed -n "10,20p" file 打印file文件的10到20行
3、StartLine,+N ------------------指定起始行号,然后后面N行
sed -n "10,+p" file 打印file文件中从第10行开始,往后面加5行的所有行
4、/pattern1/ ------------------正则表达式匹配的行
sed -n "/^root/p" file 打印file文件中以root开头的行
5、/pattern1/,/pattern2/ ------------------从匹配到pattern1的行,到匹配到pattern2的行
sed -n "/^ftp/,/^mail/p" file 打印file文件中第一个匹配到以ftp开头的行,到第二个匹配到以mail开头的行
6、LineNumber,/pattern1/ -----------------从指定行号开始匹配,直到匹配到pattern1的行
sed -n "4,/^hdfs/p" file 打印file文件中从第4行开始匹配,直到以hdfs开头的行匹配到就结束
7、/pattern1/,LineNumber -----------------从pattern1匹配的行开始,直到匹配到指定行号位置结束
sed -n "/root/,10p" file 打印file文件中匹配root的行,直到第10行结束
sed中的编辑命令详解
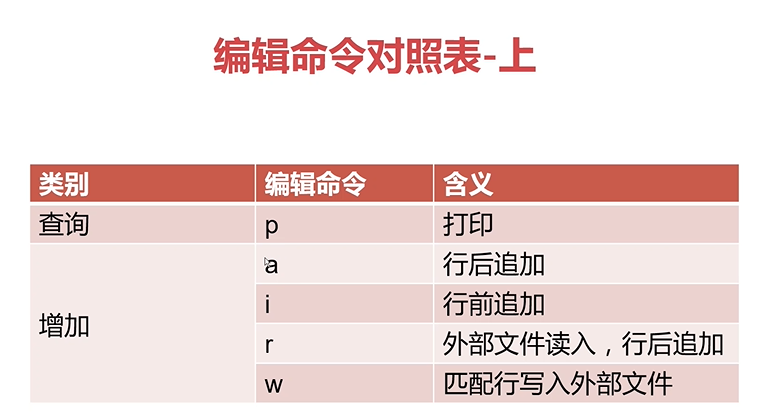
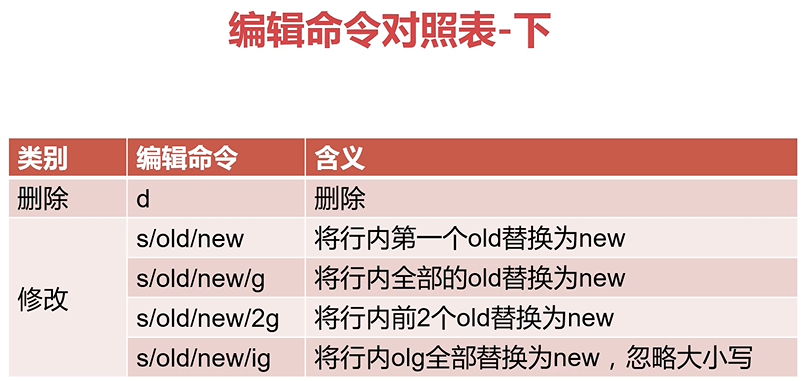
tips:图片中s/old/new/2g的含义有错,s/old/new/2g表示从第二个old开始全部替换成new,s/old/new/2则表示行内前两个替换为new
sed中什么是反向引用
sed -i 's/had..p/&s/g' &表示反向引用,即把前面ha..p匹配到的结果原封不动的引用过来,在后面添加s
sed -i 's/\(had..p\)/\1O/g' \1也表示反向引用,但是前面的had..p必须用括号括起来,而且括号要进行转义。
sed -i 's/\(had\)...../\1doop/g' \1比&要更加灵活,支持部分引用,该式表示had后面跟任意五个字符的字符串替换成haddoop,其中had做了部分引用,这是&做不到的
sed中引用变量时注意事项:
(1)、匹配模式中存在默认变量,则必须使用单引号
(2)、sed中需要引入自定义变量时,如果外面使用单引号,则自定义变量也必须使用单引号
利用sed查找文件内容
利用sed删除文件内容
利用sed追加文件内容
文本处理三剑客之awk
awk的工作模式
awk的内置变量
awk格式化输出之printf
awk模式匹配的两种用法
awk中表达式的用法
awk动作中的条件及循环语句
awk中的字符串函数
awk中的常用选项
awk中数组的用法
一个复杂的awk处理生产数据的例子
使用awk最典型的应用场景
shell脚本操作数据库实战
安装mysql数据库,导入测试数据
shell脚本与mysql数据库交互(增删改查)
利用shell脚本将文本数据导入到mysql中
备份mysql数据,并通过FTP将其传输到远端主机
大型脚本工具开发实战
脚本工具功能概述
拆分脚本功能,抽象函数
功能函数一代代码实现
功能函数二代代码实现
功能函数三代代码实现
功能函数四代代码实现
程序主流程设计及代码实现
