
性能调优之数据库(二)
特定语句的原理与调优
1.JOIN语句
1)种类、算法与原理
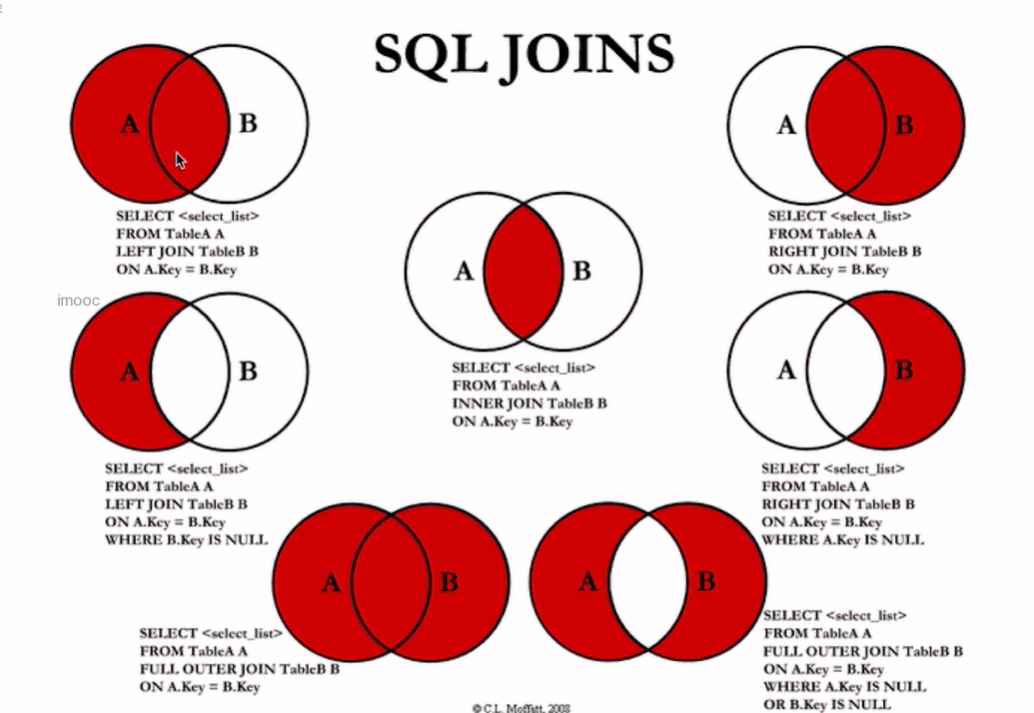
种类:
inner join:内连接
left join:左连接
right join:右连接
full outer join:全外连接
cross join:笛卡尔连接,如果cross join带有on 子句,就相当于inner join
JOIN算法:
1.Nested-Loop Join(NLJ):嵌套循环Join,相当于sql拆分的时候,最原始不可取的那种方法,嵌套for循环
2.Block Nested-Loop Join(BNLJ):块嵌套循环Join,先把外层结果通过join buffer缓存起来,相当于sql拆分的时候,把外层结果放到一个list当中,通过IN语句放到内存里面
使用join buffer的条件:


查询、修改join buffer的值及sql验证

3.Batched Key Access Join(BKA):批量键值访问,相当于2的基础上,把外层查询出来的结果根据主键id进行排序之后,在通过IN放到内层去,目的是把随机IO变成顺序IO,从而提交查询效率
mysql5.6引入
BKA的基石:Multi Range Read(MRR)
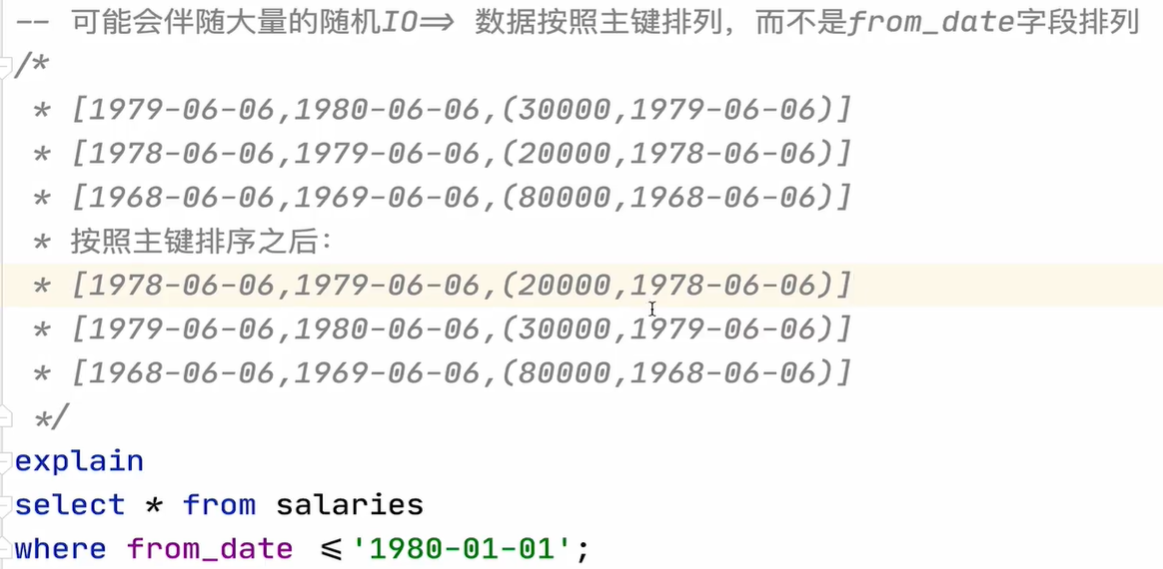
MRR核心:把随机IO转换成顺序IO,从而提升性能
MRR参数:

开启MRR:
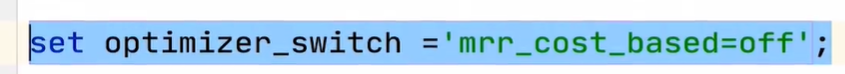
开启BKA:
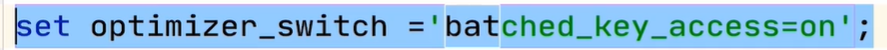
4.Hash Join
mysql8.0版本出现,用来替换掉BNLJ
join buffer缓存外部循环的hash表,内能循环遍历时到hash表匹配
hash join注意点:


2)JOIN语句优化
驱动表VS被驱动表:
外层循环的表是驱动表,内存循环的表是被驱动表
一般不需要人为关注,myqsl优化器会自动进行优化,把较小的表作为驱动表,以减少内层表循环扫描次数。
可以通过explain看到谁是驱动,谁是被驱动。id相同,从上到下执行,id不同,由大到小执行

Join调优原则
1.小表驱动大表,一般不需人为关注,关联查询优化器会自动选择最优的执行顺序。如果优化器抽风,可以使用STRAIGHT_JOIN

2.如果有where条件,应该尽可能使用索引,并减少外层循环的数据量
3.join的字段尽量创建索引
4.如果join字段在两张表的数据类型不同,会导致隐示转换,可能导致索引失效,从而引发全表扫描(可以通过mysql终端的show warnings查看细节)
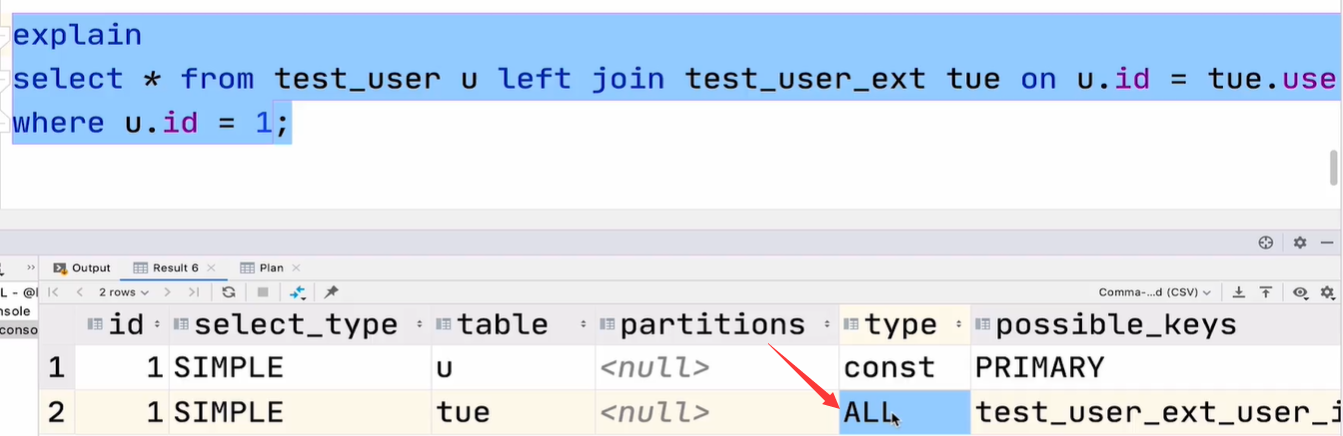
5.尽量减少扫描的行数(explain-rows),尽量控制在百万以内
6.参与join的表不要太多,阿里编程规约要求不超过三张,如果业务确实需要关联很多表,需要进行sql拆分
tips:sql拆分的好处?
1.复杂sql转变成简单sql,减少了mysql进行sql解释、分析、调优的开销
2.简单sql大多是主键索引,性能佳
3.拆分后的sql可读性,可分析性,可维护性都大大提高,杜绝一条sql搞定一切,编写复杂sql的能力并不值得炫耀
7.如果被驱动表的join字段用不了索引,且内存较为充足,可以考虑把join buffer设置的大一些,从而降低内层循环的次数
2.Limit语句优化
1)limit语句,当偏移量很大的时候,性能显著下降,因为全表扫描的rows很大

2)优化方案:
1.覆盖索引(全表扫描变成全索引扫描)
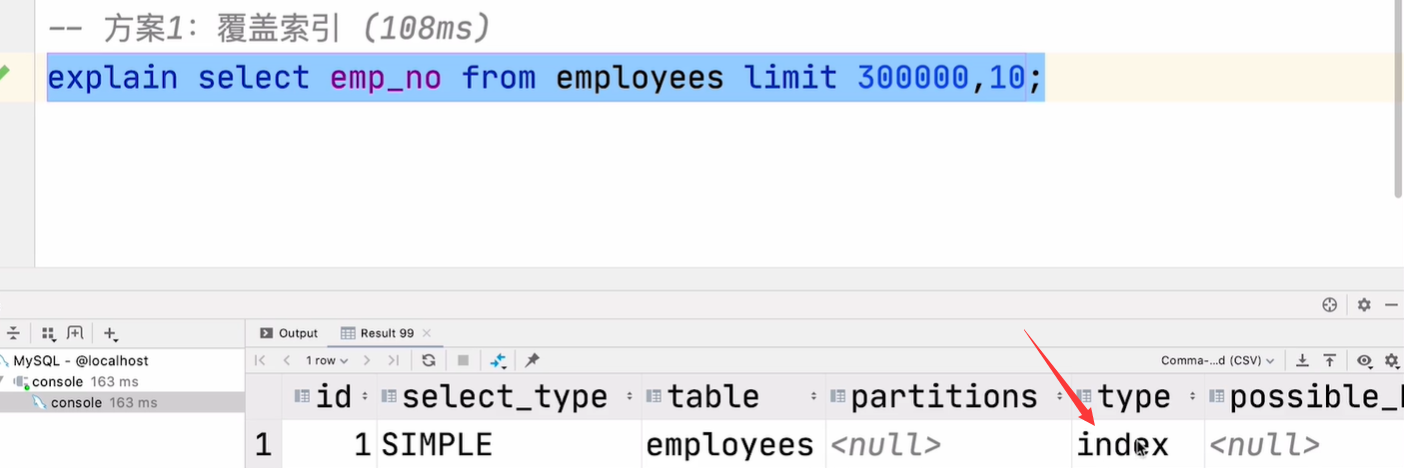
2.覆盖索引+join

3.覆盖索引+子查询

4.范围查询+limit语句

5.如果能获得起始主键值&结束主键值

6.禁止传入过大的页码,超过阈值,默认返回首页(参考百度,淘宝等)
3.COUNT语句优化
1)count(*)
2)count(字段)

3)count(1)

4)总结:
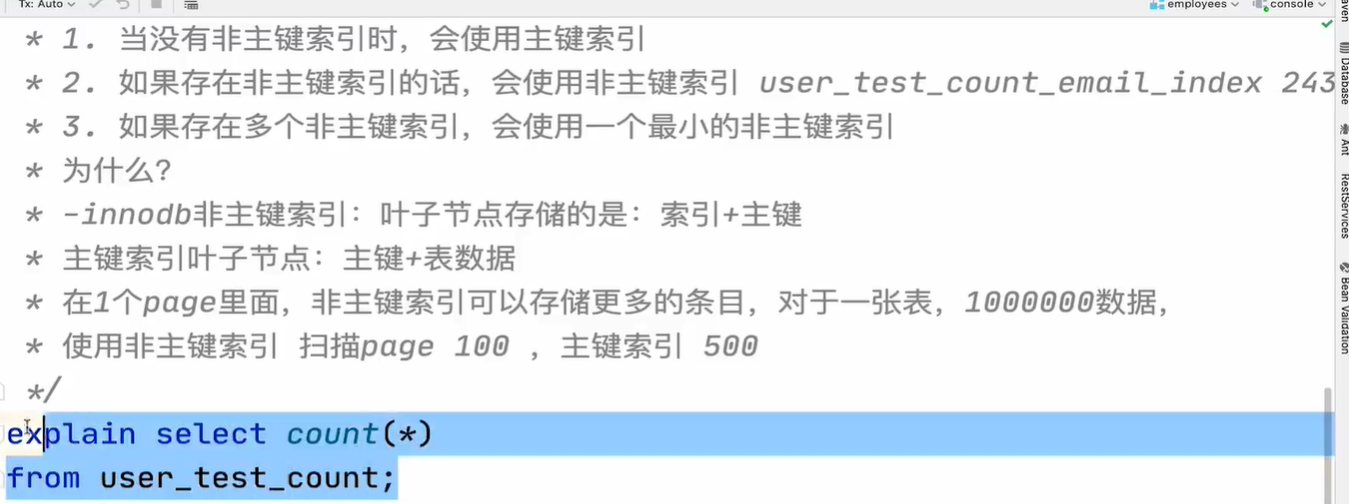
1.count(*)和count(1)一样
2.count(*)会选择最小的非主键索引,如果不存在任何的非主键索引,则会使用主键
3.count(*)不会排除为null的行,而count(字段)会排除
4.对于不带查询条件的count(*)语句,MyISAM和InnoDB(MySQL>=8.0.13)都做了优化
5.如果没有特殊需求,尽量使用count(*)
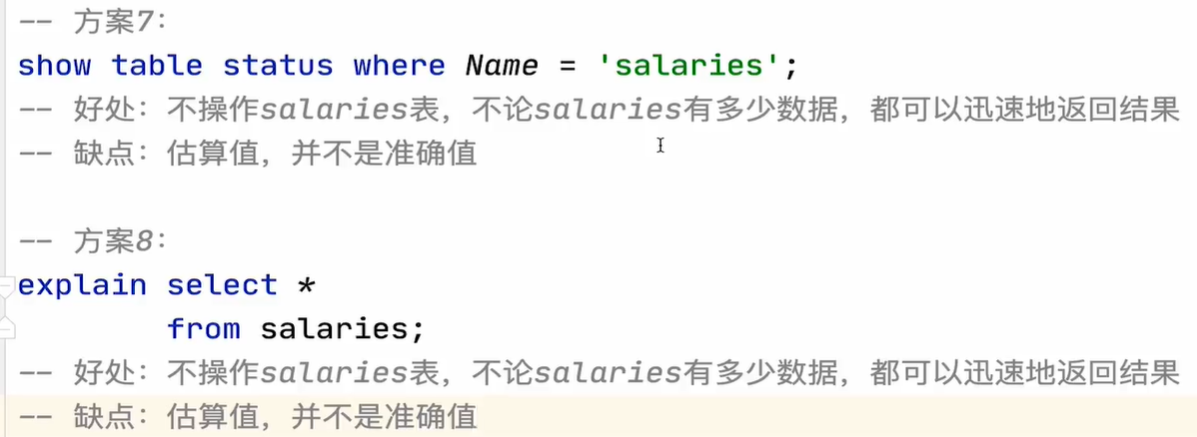
5)count语句优化方案:


4.ORDER BY语句优化
1)最好的方案:利用索引避免排序(如果sql进行explain之后,extra里面有using filesort字段,则意味着不可以利用索引进行避免排序)
原理:利用mysql索引本身的有序性,让mysql跳过排序过程




2)排序模式:
1.rowid排序(常规排序)



rowid排序的特点

tips:1)快速排序:
1.可以理解为二分递归排序
2.取一个中间值,把所有数与这个中间值进行比较,小的放在一边,大的放在另一边
3.把两边的数分别再取一个中间值,依次进行比较,小的放在一边 ,大的放在另一边,如此分割、排序,循环递归下去
4.直到每一个小块左边的数和右边的数相等,则完成排序
5.由于是一个递归算法,所以栈深度比较大,对栈内存开销比较严重
6.被认为是目前最好的一种内部排序算法
2) 归并算法:


速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列
2.全字段排序(优化排序)

全字段排序 VS rowid排序

算法如何选择?

3.打包字段排序

3)参数汇总
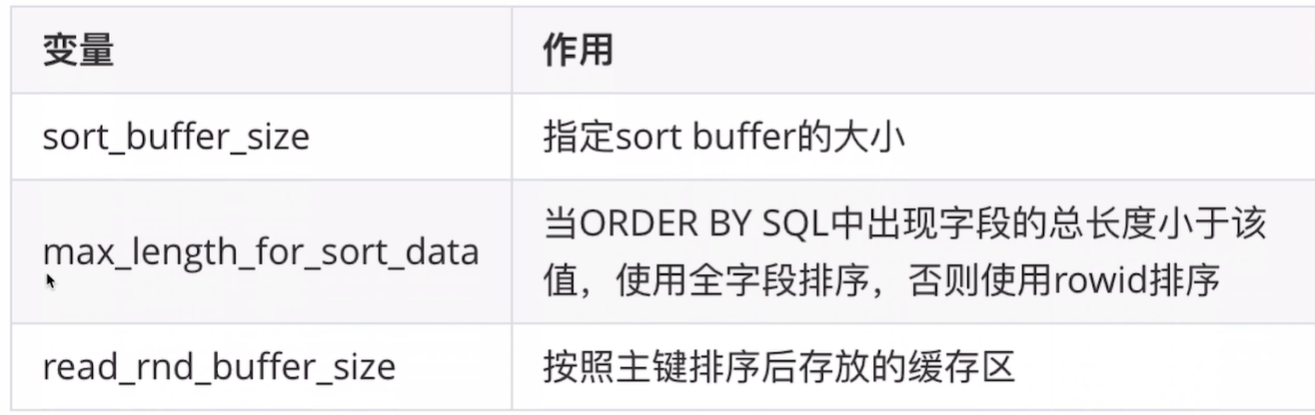
4)ORDER BY语句调优



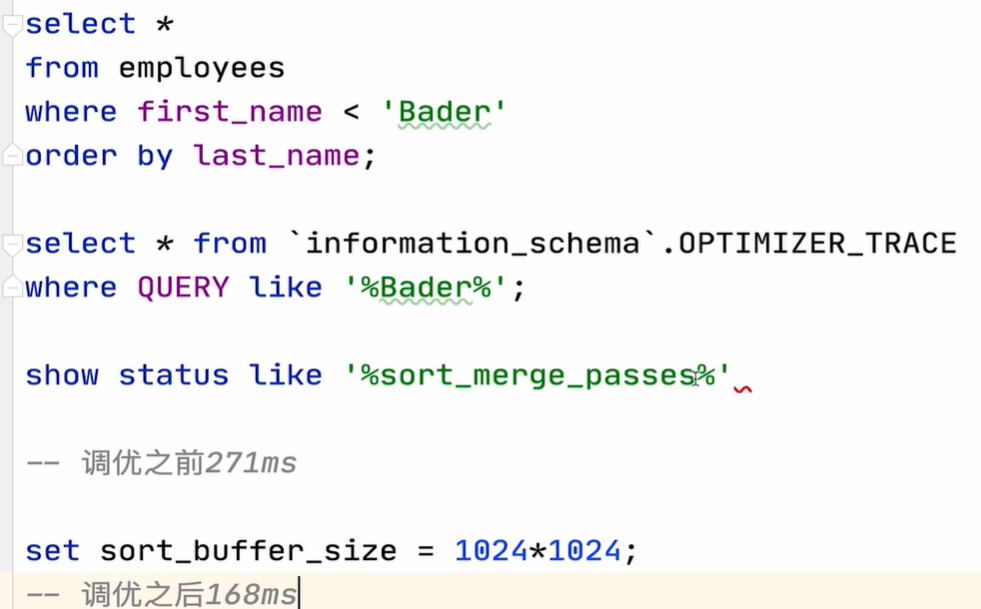
5)调优实战
5.GROUP BY语句
1)松散索引扫描:无需扫描所有满足条件的索引即可返回结果
使用松散索引扫描的条件






2)紧凑索引扫描:需要扫描满足条件的所有索引键才能返回结果
3)临时表

总结:

tips:松散/紧凑索引扫描有点类似于覆盖索引
表结构设计优化
数据库设计三范式:



1.数据库设计原则上需要满足三范式,目的是消除冗余
2.但有些时候,需要进行一些反模式设计,目的是加快查询效率,空间换时间
表设计原则:



