

性能调优之数据库(一)
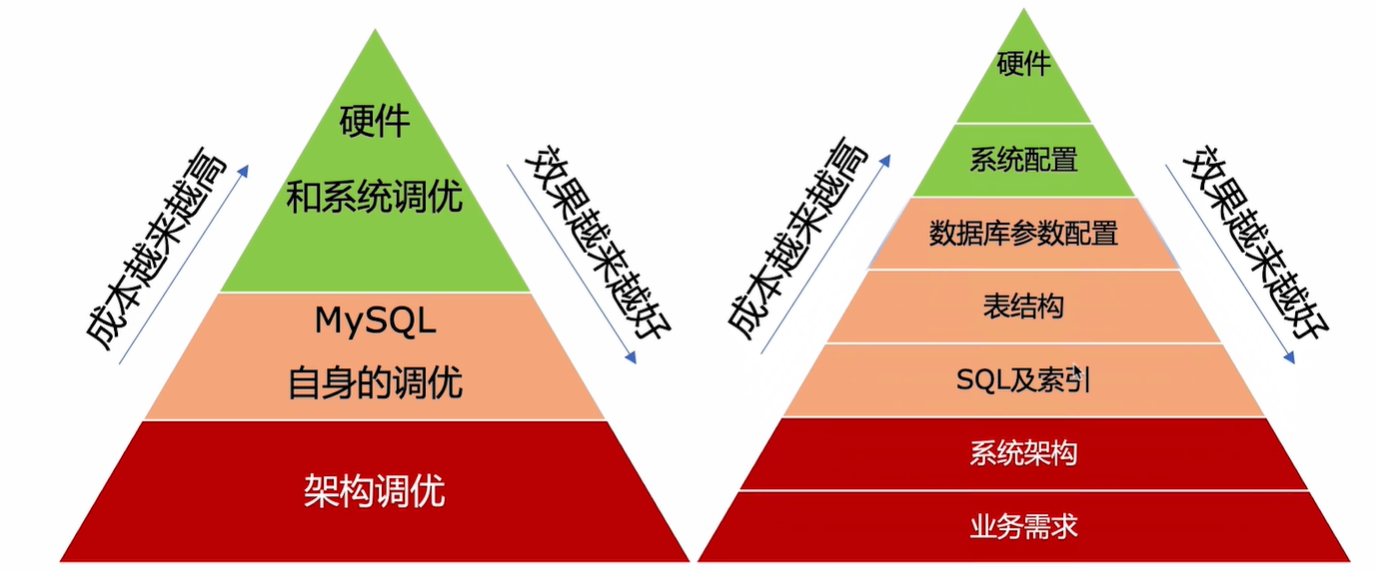
mysql性能调优金字塔法则
mysql慢查询日志
1.慢查询日志是mysql内置的功能,可以记录执行超过一定时间的sql语句
2.超过500ms算慢
2.详见手记https://class.imooc.com/lesson/1260#mid=36668
EXPLAIN详解
1.格式:EXPLAIN+sql语句
2.比较重要的参数:
type:连接类型,all全表扫描性能最差,ref向上算是比较优秀
key_len:索引长度,越短越好
rows:扫描行数,越少越好
extra:附加信息,有两个比较重要
using filesort:直接使用文件排序,没有使用索引。出现此字段需要优化
using temporary:创建临时表,一般当查询包含不同列的group by 和order by时会出现,需要优化
3.当explain出现多条结果的时候,id不同,从大到小执行,id相同,从上到下执行
4.详见手记https://class.imooc.com/lesson/1260#mid=36669
SQL性能分析
1.EXPLAIN分析可以满足大多数场景的需求,如果想要更加细致的分析sql,则需要深入sql内部
2.三种方式,详见手记https://class.imooc.com/lesson/1260#mid=36670
1)show profile:简单方便,已废弃,目前可用(推荐)
2)infomation_schema.profiling:本质同show profile
3)performance_schema:未来趋势
OPTIMIZER_TRACE
1.作用:
1.跟踪优化器做出的各种决策
2.了解优化器的执行细节
3.理解sql执行过程,进而优化sql
2.mysql5.6新功能,默认关闭
3.使用详见手记https://class.imooc.com/lesson/1260#mid=36671
数据库诊断命令
1.作用:sql诊断可以通过慢查询日志,explain,show profile,optimizer_trace来实现,但是数据库本身也有可能出现问题,此时需要用到数据库诊断命令
2.详见手记https://class.imooc.com/lesson/1260#mid=36672
数据库调优理论
1.索引数据结构
1)B+-Tree
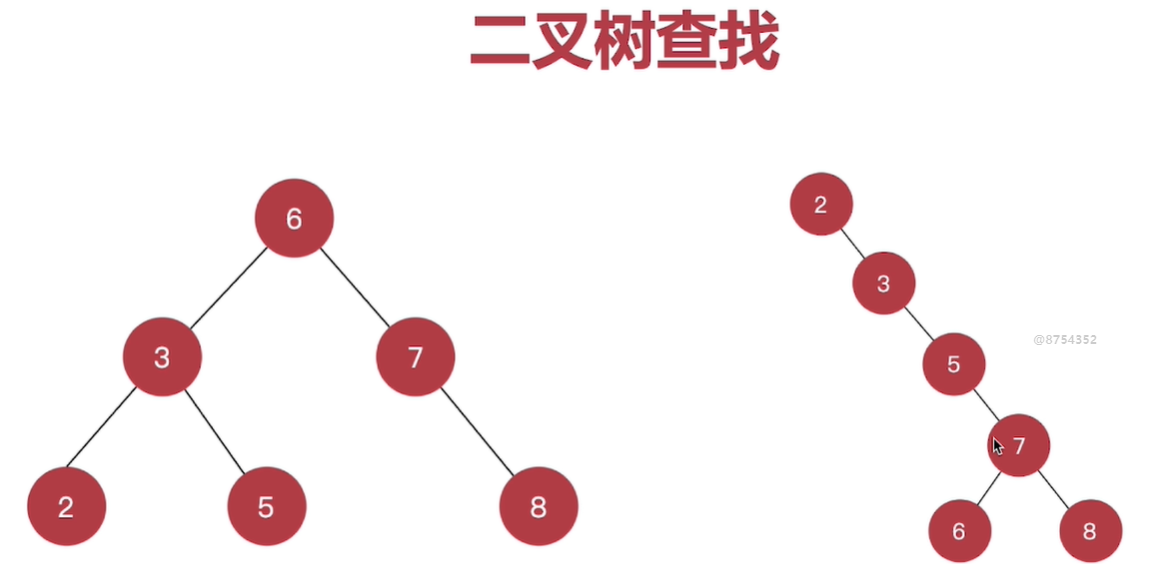
演进过程:二叉树->平衡二叉查找树->B-Tree->B+Tree

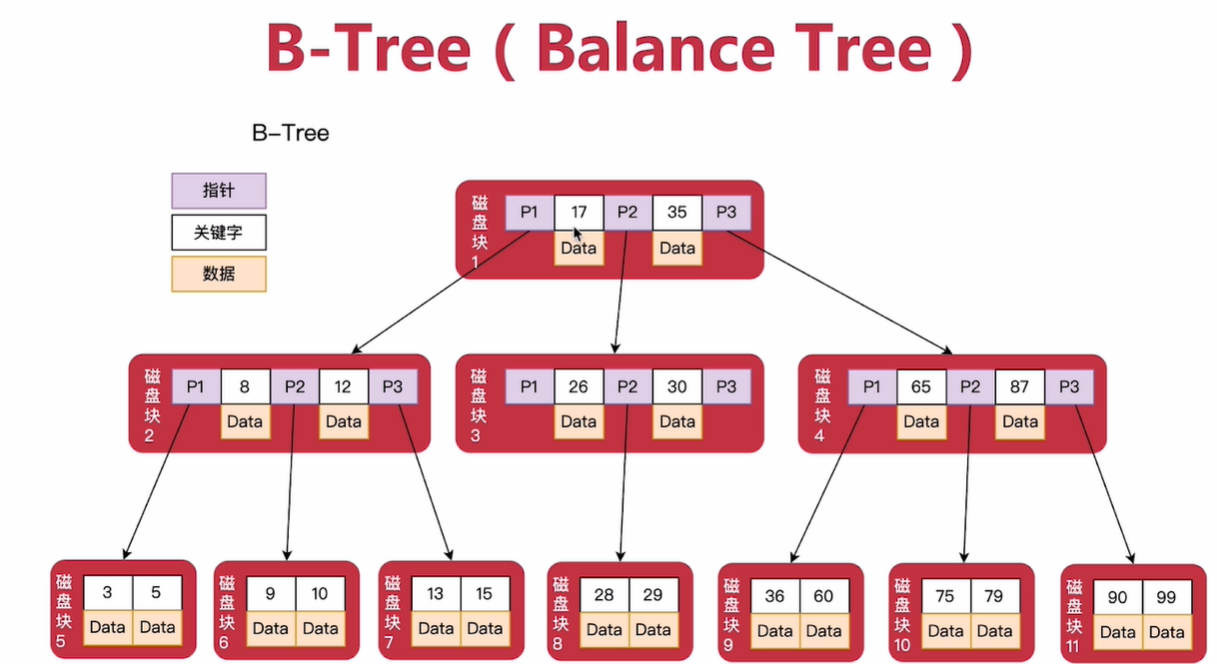


tips:B-Tree第四个特点的含义:一个中间节点包含了n个关键字,会同时包含n+1个指针

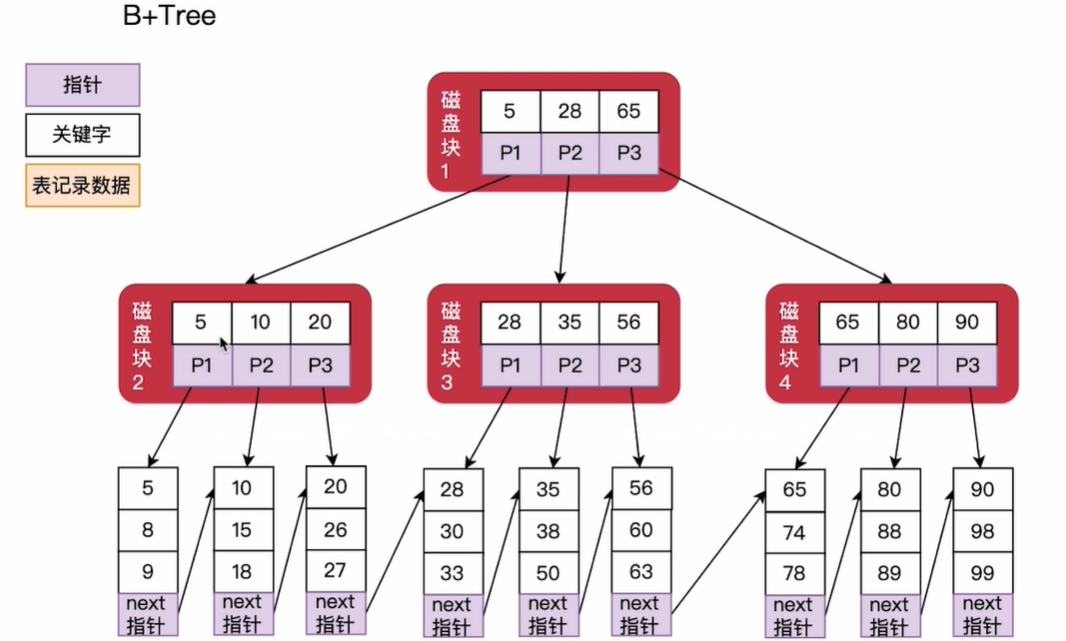


B-Tree VS B+Tree
1.精确查找性能差不多,B-Tree有时候更好,但遍历深度不太稳定
2.范围查找,B+Tree性能优于B-Tree



2)Hash索引,类似于HashMap
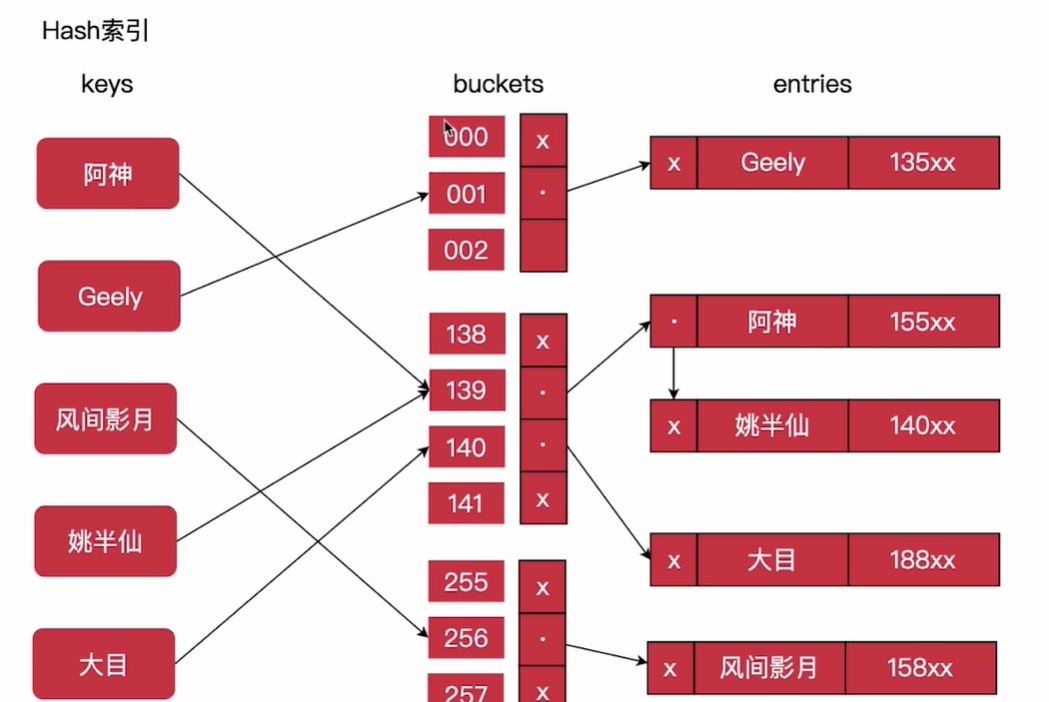

tips:自适应Hash索引:当一个索引使用的非常频繁,InnoDB内存中会基于B+Tree索引之上,再为其创建一个Hash索引,从而提升查询效率
3)空间索引(R-Tree索引):
1.mysql5.7之后开始支持
2.但是对于GIS支持的不够完善,更流行使用PostGresql
4)全文索引(Full-Text)
1.5.7之前全文索引不支持中文,经常搭配Sphinx
2.5.7之后,内置ngram,支持中文
3.业界更多的使用ES来做全文搜索
2.B-Tree(B+Tree)&Hash索引特性与限制
1)B-Tree(B+Tree)索引特性

tips:前缀匹配时,左模糊查询无法走索引
2)B-Tree(B+Tree)索引限制
1.最左前缀原则:
索引按照最左优先的原则匹配索引,不满足下列三个条件时,都无法完全使用索引。所以在性能调优的时候,索引列的顺序很重要
联合索引相比于单列索引,可以减少查询深度,所以经常组合查询的几个列,要考虑建立联合索引

3)Hash索引特性:性能要比B-Tree索引好
4)Hash索引限制:


3.创建索引的原则
1)建议创建索引的场景
1.经常出现在where条件的字段
2.需要分组/排序的字段
3.distinct所使用的字段
4.字段的值有唯一性约束
5.对于多表查询,链接字段应创建索引,且字段类型务必一致,否则会触发隐式转换,可能导致索引失效
2)不建议常见索引的场景
1.where子句用不到的字段
2.表的记录非常少
3.有大量的重复数据,选择性低的字段(例如性别字段)
4.频繁更新的字段,如果创建索引要考虑其索引维护开销,数据更新的时候,索引也需要更新,所以对于更新非常频繁,但是查询却很少的字段,不建议创建索引
4.索引失效与解决方案








tips:not null的好处
1.更好的使用索引
2.减少检测值是否为null的开销
3.可以节省存储空间,每个字段可以节省1byte,这是因为如果定义为允许为空,那儿需要一个额外的byte去记录这个字段是否为空

5.索引调优技巧
1)长字段的索引调优
方案一:“伪Hash索引”
把长字段的hash值作为一个字段存储进来,本质上还是B-Tree索引
查询的时候where条件使用该hash字段+原来的长字段(防止hash冲突)

局限性:该方案对于右模糊查询的like语句无能为力,例如where first_name like "Face%" , 因为记录的是整个字段值的hash值

方案二:前缀索引or“后缀索引”
前缀索引可以解决上面方案的局限性

关于前缀索引的完整性选择


后缀索引

2)使用组合索引的技巧
单列索引:
分别求出结果,然后取并集
使用explain查看结果,发现type是index_merge
可以通过OPTIMIZER TRACE看到详细的执行过程
组合索引:
使用explain查看结果,发现type是ref
单列索引VS组合索引

3)覆盖索引
定义:对于索引X,select的字段,只需从索引中就能获得,无需到表数据里获取,这样的索引就叫做覆盖索引
性能:

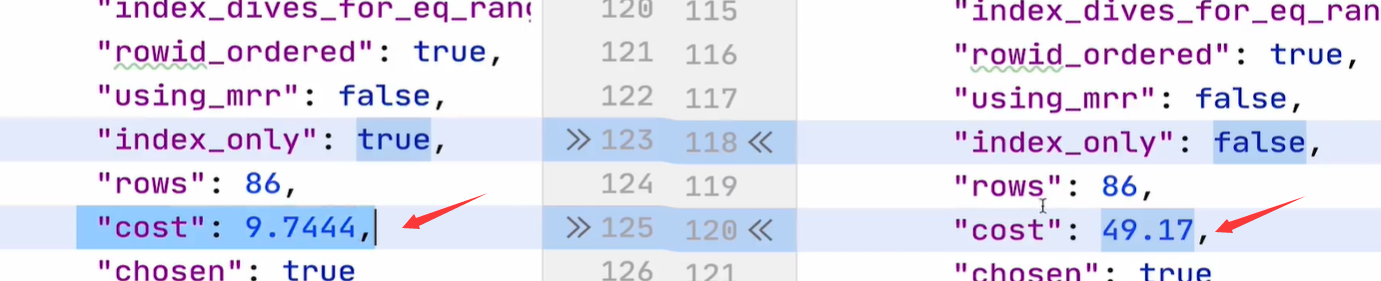
tips:是否使用覆盖索引,对于性能开销的影响还是比较大的。
优化:

4)冗余、重复索引、未使用的索引、排序的优化
索引本身是有开销的,影响增删改的性能
重复索引:


冗余索引:

冗余索引特例(排序的优化):

tips:由于最左前缀原则,此sql需要额外创建一个from_date的冗余索引,order by才能使用到索引!
未使用的索引:累赘,直接删除!
