性能调优之jvm(理论篇一)
JVM内存结构
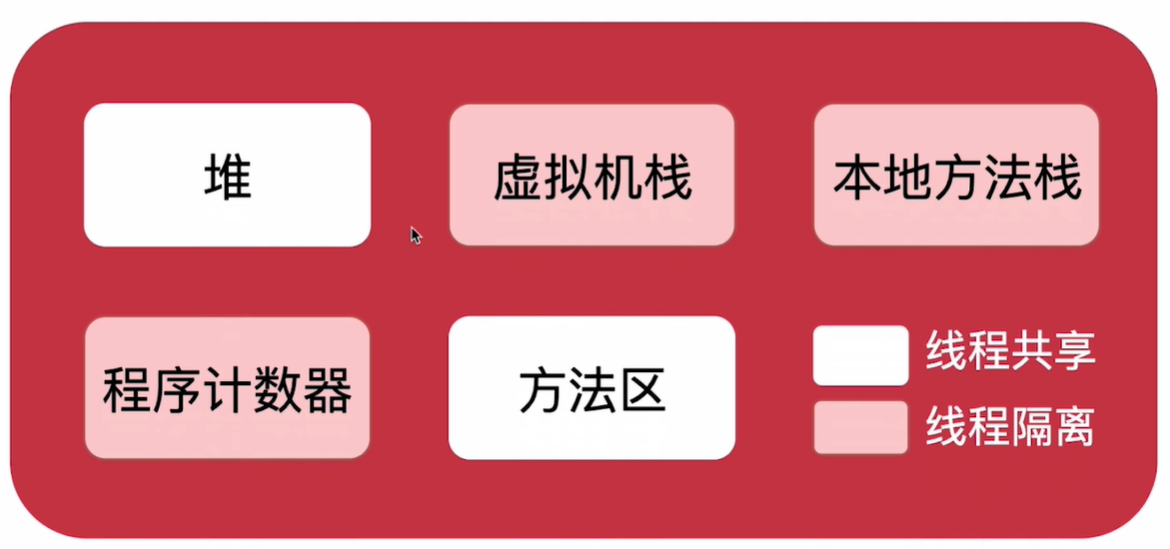
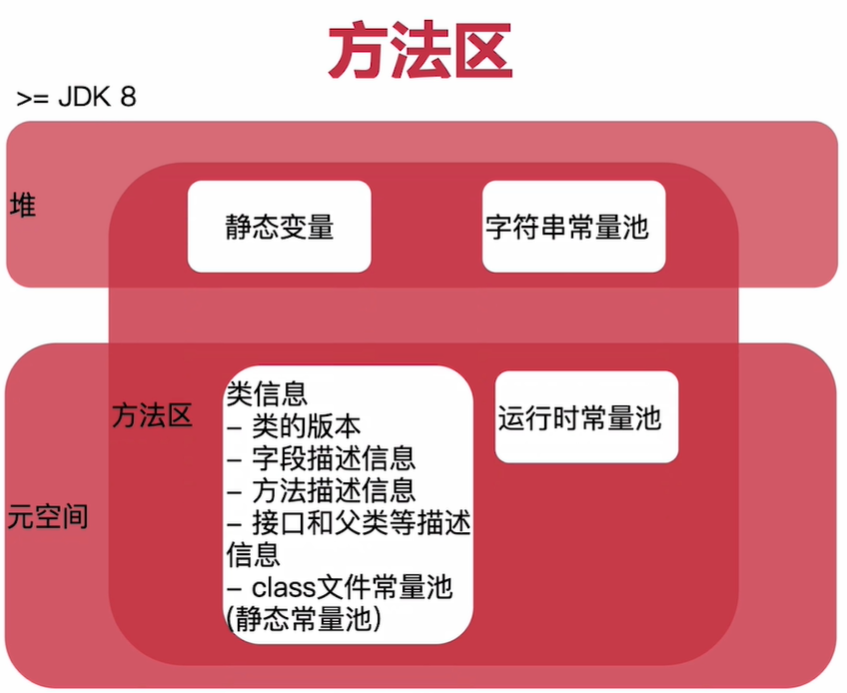
tips:堆和方法区是线程共享的,栈是线程隔离的
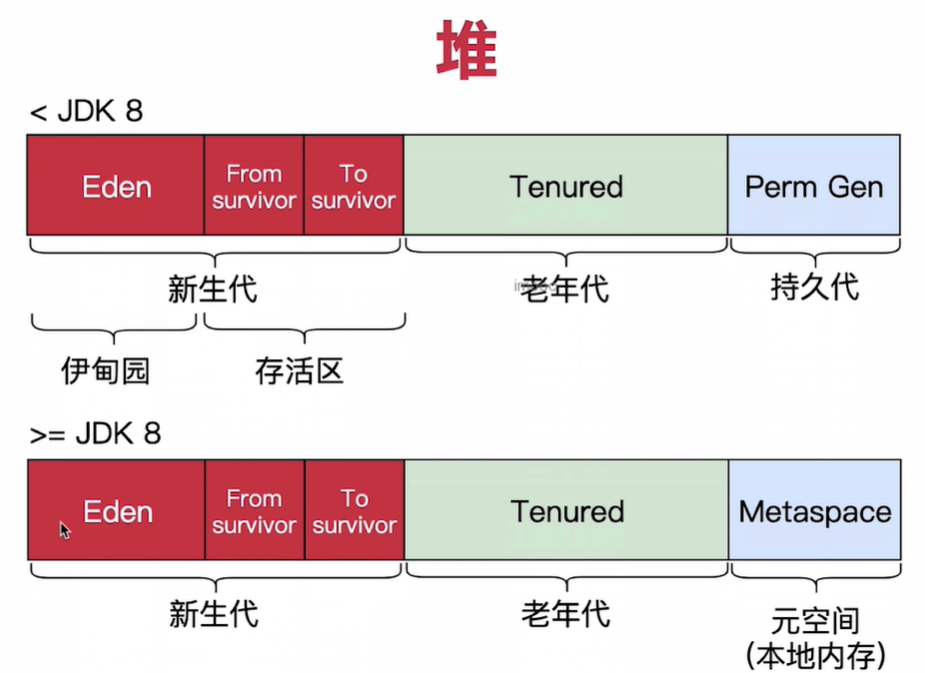
1.堆:jvm内存中最大的一块内存空间,绝大多数的对象都是存储在堆内存中
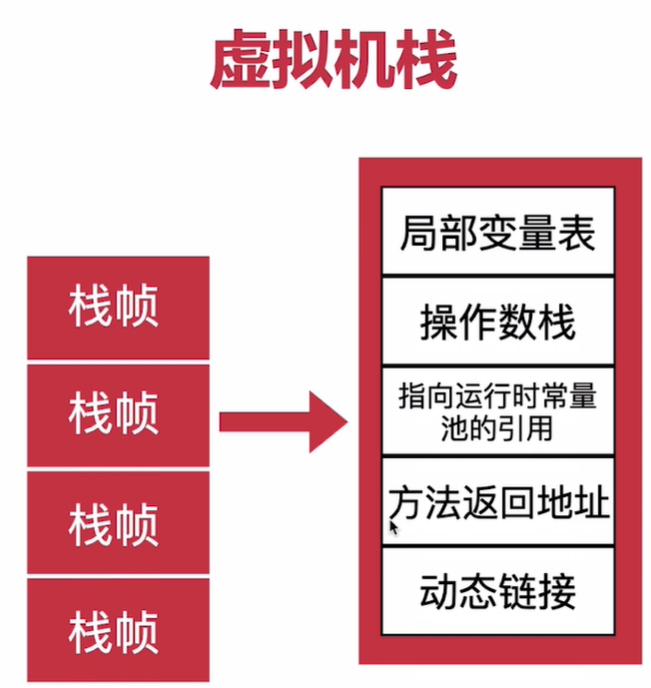
2.虚拟机栈
3.本地方法栈:功能与虚拟机栈类似,虚拟机栈管理的是java方法,本地方法栈管理的是native方法,native方法是由C语言来实现的。
4.程序计数器:用来记录各个线程执行的字节码的地址。像分支,循环,跳转,异常,线程恢复等操作都需要依赖程序计数器。
tips:为什么要有程序计数器?
因为java是一种多线程语言,当线程数大于CPU核心线程数时,会发生cpu资源的竞争,如果一个线程还没执行完,cpu资源被抢走了,当再次竞争到cpu资源的时候,需要知道之前程序执行到哪里了,这就是程序计数器要做的工作。
5.方法区:方法区并不是一个物理上的区域,而是一个逻辑上的区域,jdk8之后,一部分在堆中,一部分元空间中(本地内存),原因是这一部分空间大小不好估计,放在jvm内存中容易造成内存溢出或者空间浪费。



Demo demo = new Demo();
真正的demo对象在堆中,demo引用在栈中,值是一个指针,指向堆中的demo对象。

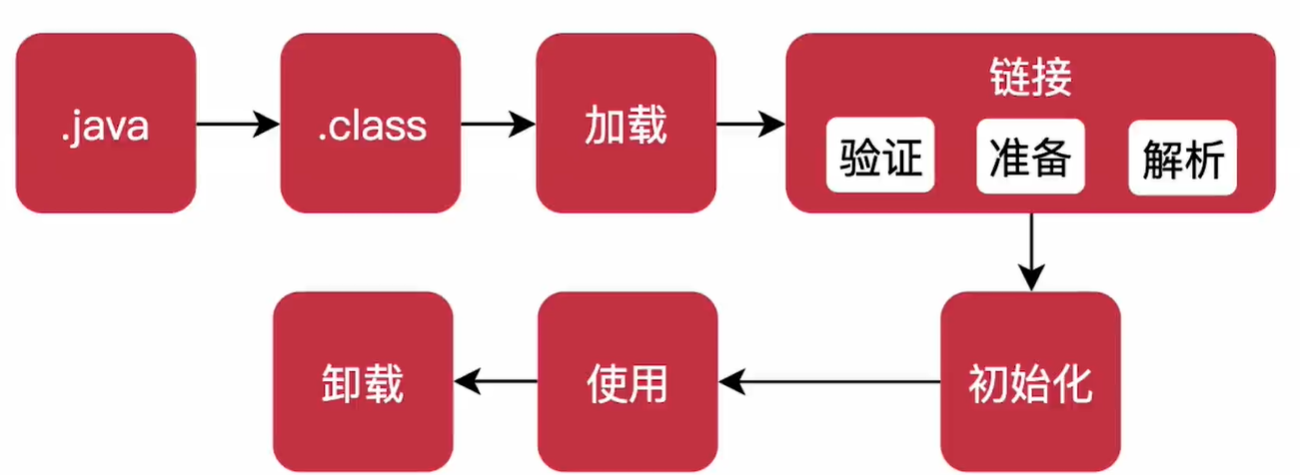
类的加载过程





编译器优化机制
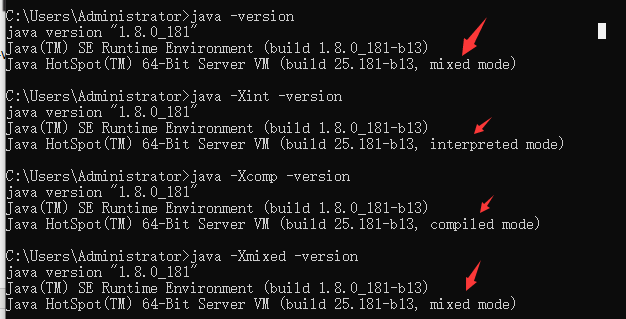
1.字节码运行方式有两种,解释执行和编译执行。

2.可以通过java -version查看运行模式,也可以通过java -Xint -version等修改运行模式
3.一开始由解释器解释执行,当虚拟机发现热点代码时,会使用即时编译器将其编译成机器码,并进行各层次的优化
4.hotspot即时编译器有两种,C1和C2,C1简单快速,又称为client compiler,C2编译器为长期运行的服务器端程序做性能调优,又被称为server compiler
5.虚拟机会进行分层编译(级别越高,启动越慢,开销越大,峰值性能越高):
0:解释
1:简单C1
2:受限制的C1
3:完全C1编译
4:C2编译
6.找到热点代码的方式有两种:
1.基于采样
2.基于计数器(hotspot基于这一种),计数器有两种,方法调用计数器,回边计数器,流程图如下:
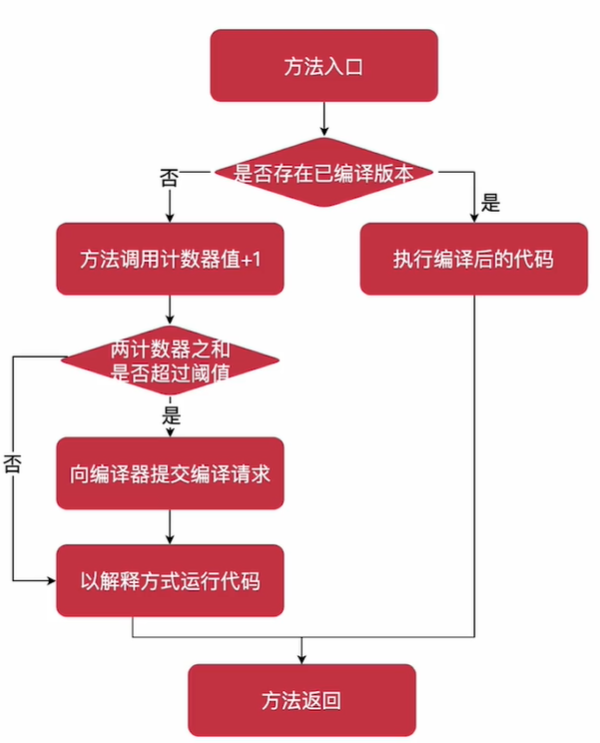
方法调用计数器统计的并不是绝对次数,而是一定时间窗口内的次数,超过时间,次数会减半,也就是存在热度半衰期
编译器优化之方法内联
定义:

作用:减少进栈出栈的开销
条件:
1.方法体足够小

2.被调用方法运行时的实现可被唯一确定
jvm
注意点:
1.方法体要足够小
2.尽量使用final,private,static等关键字修饰方法,避免因为多态,需要对方法做额外的检查
3.一些场景下,可以通过JVM参数修改阈值,从而让更多方法内联
可能带来的风险:
CodeCache(用来存放编译后机器码的地方,默认大小仅为240M)溢出,导致JVM退化成解释模式执行
内联优化对性能带来的提升:
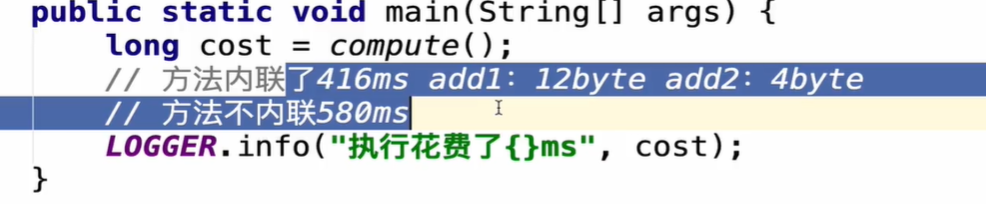
内联相关JVM参数:
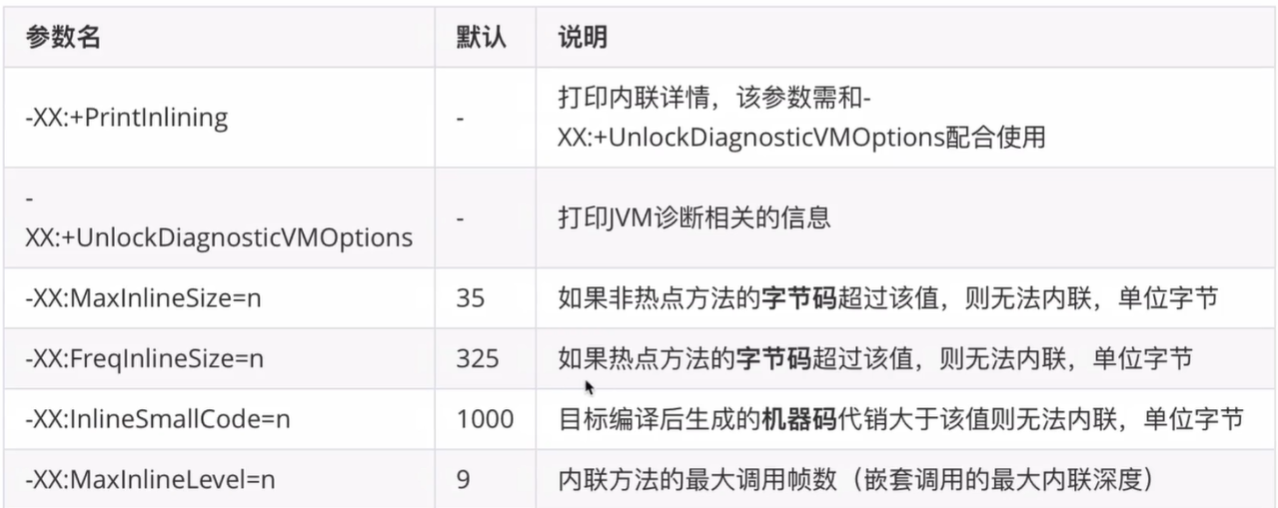
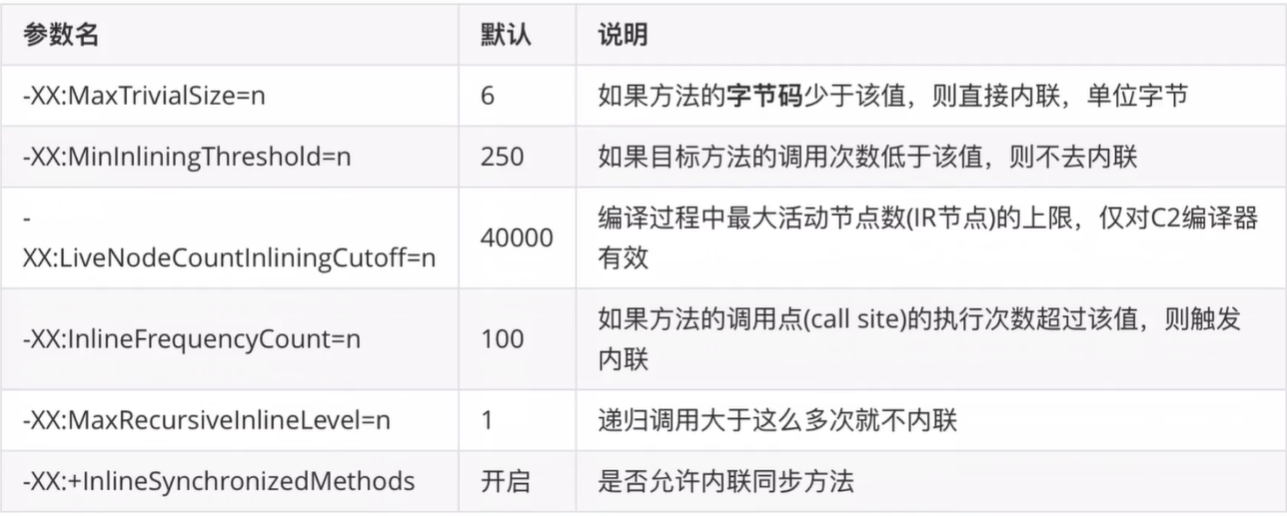
使用建议:
1.通常情况下不建议随意修改这些参数,使用默认值即可
2.当出现性能瓶颈的时候,要想到通过内联的方式进行调优
逃逸分析,标量替换,栈上分配
1.逃逸分析
定义:分析变量能否逃出其作用域
类型:
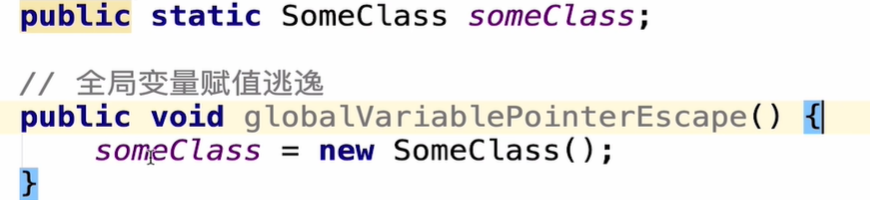
1.全局变量赋值逃逸
2.方法返回值逃逸

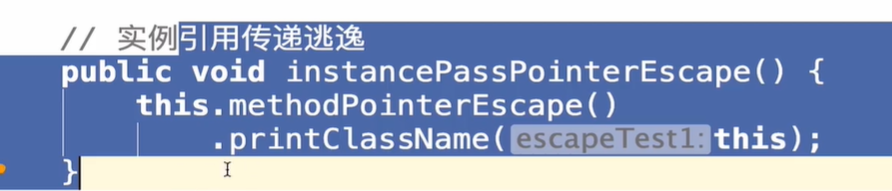
3.实例引用逃逸
4.线程逃逸

逃逸状态标记:
1.全局级别逃逸:一个对象可能从方法或当前线程中逃逸
对象被作为方法的返回值 -> 方法返回值逃逸
对象作为静态字段或成员变量 -> 全局变量赋值逃逸
如果重写了某个类的finalize()方法,那么这个类的对象都会被标记成全局逃逸状态并且一定会放在堆内存中
2.参数级别逃逸
对象被作为参数传递给一个方法,但是在这个方法之外无法访问/对其他线程不可见 -> 实例引用逃逸
3.无逃逸:一个对象不会逃逸
2.标量替换
标量定义:不能被进一步分解的量
基础数据类型
对象引用
聚合量定义:可以被进一步分解的量,例如字符串(底层是byte数组)
标量替换定义:通过逃逸分析确定该对象不会被外部访问,并且对象可以被进一步分解时,JVM不会创建该对象,而是创建它的成员变量来代替
示例:
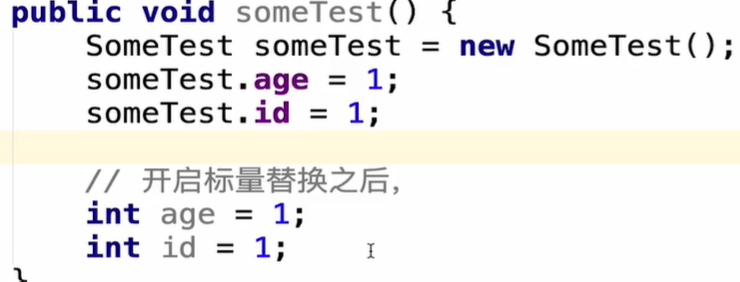
作用:减少对象创建,节省内存开销
3.栈上分配
定义:
1.java里面绝大多数对象都是存放在堆里面的,当对象没用的时候,靠垃圾回收器去回收对象
2.如果通过逃逸分析,能够确认对象不会被外部访问,就会在栈上分配对象
作用:对象所占用的空间就会在栈针出栈的时候被销毁了,可以降低GC工作压力
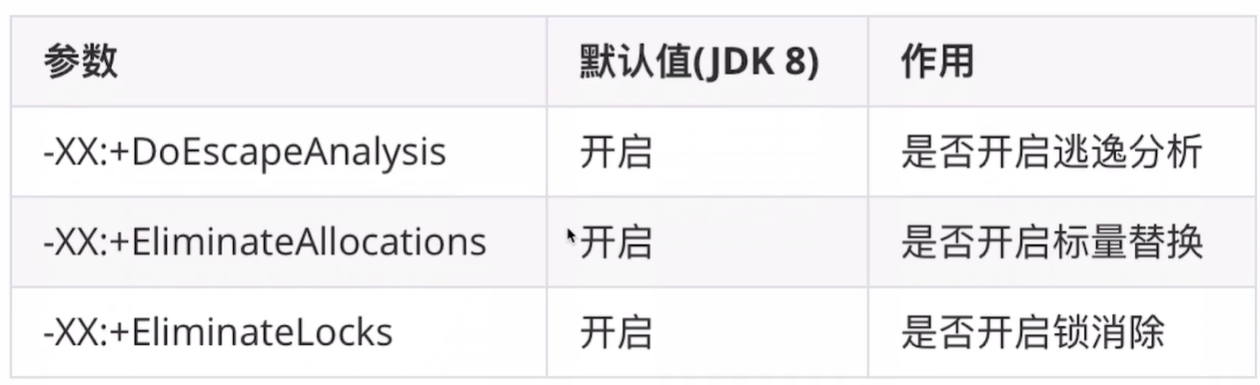
4.相关JVM参数: