
容器之k8s(三)
k8s集群监控

metrics解决方案:prometheus(节点CPU,内存等数据收集)+grafana(可视化展示)
tracing解决方案:zipkin
logging解决方案:elk->efk
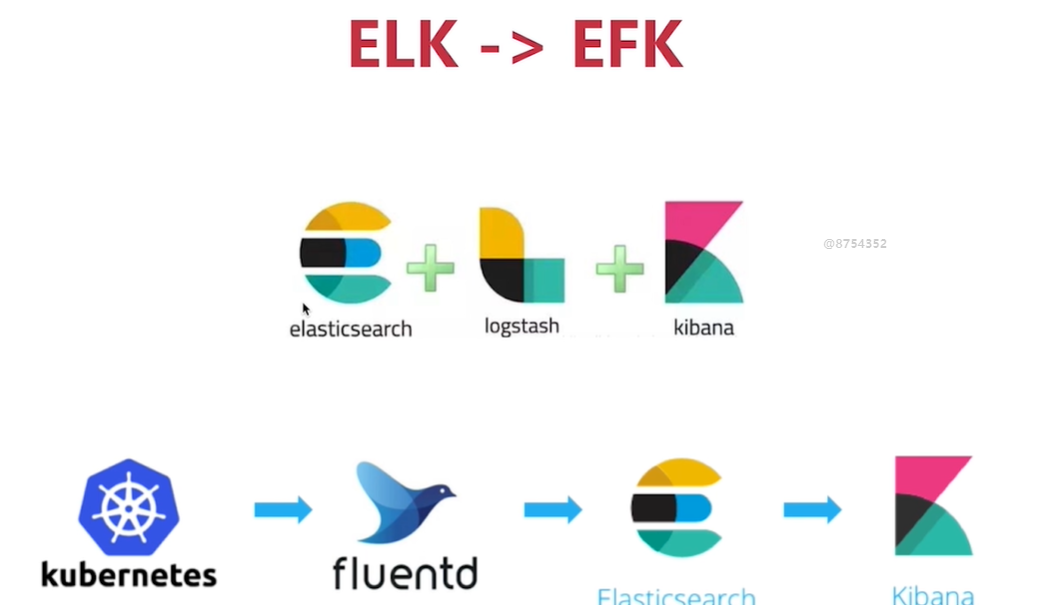 fluentd性能更佳
fluentd性能更佳
1.使用Helm安装prometheus operator
1)helm部署
1.官网下载压缩包:https://github.com/kubernetes/helm/releases,选择2.16.12版本
2.解压:tar -zxvf helm-2.16.12.tar.gz
3.把helm指令放到bin目录下:mv helm-2.9.0/helm /usr/local/bin/helm
4.安装tiller:helm init (此时出现坑,提示tiller pod 不存在,发现是镜像拉取失败导致,在node1节点上重新拉取镜像,修改镜像源为阿里,问题解决,参考文档:https://www.cnblogs.com/wswind/p/12703279.html)
5.安装普罗米修斯:helm install --name prometheus-operator --set rbacEnable=true --namespace=monitoring stable/prometheus-operator(此时出现坑,尚未解决。。。)

坑已经解决,原因是default账户权限不足,需要额外创建tiller账户并赋予admin权限,然后重新helm init,并指定serviceacoount为tiller。参考文档:https://blog.51cto.com/michaelkang/2432714
具体步骤:
1)kubectl create serviceaccount --namespace kube-system tiller
2)kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
3)kubectl delete deployment tiller-deploy --namespace kube-system
4)helm init --service-account tiller
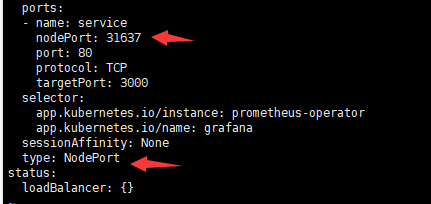
2)service修改
kubectl edit service prometheus-operarot-grafana --namespace=monitoring,将type改为NodePort并指定一个端口号(如果不指定,会随机分配一个,需要再次edit进来可以看到分配的端口号,或者describe也可以)
![]()
3)输入ip+端口号,进行登陆:
![]()
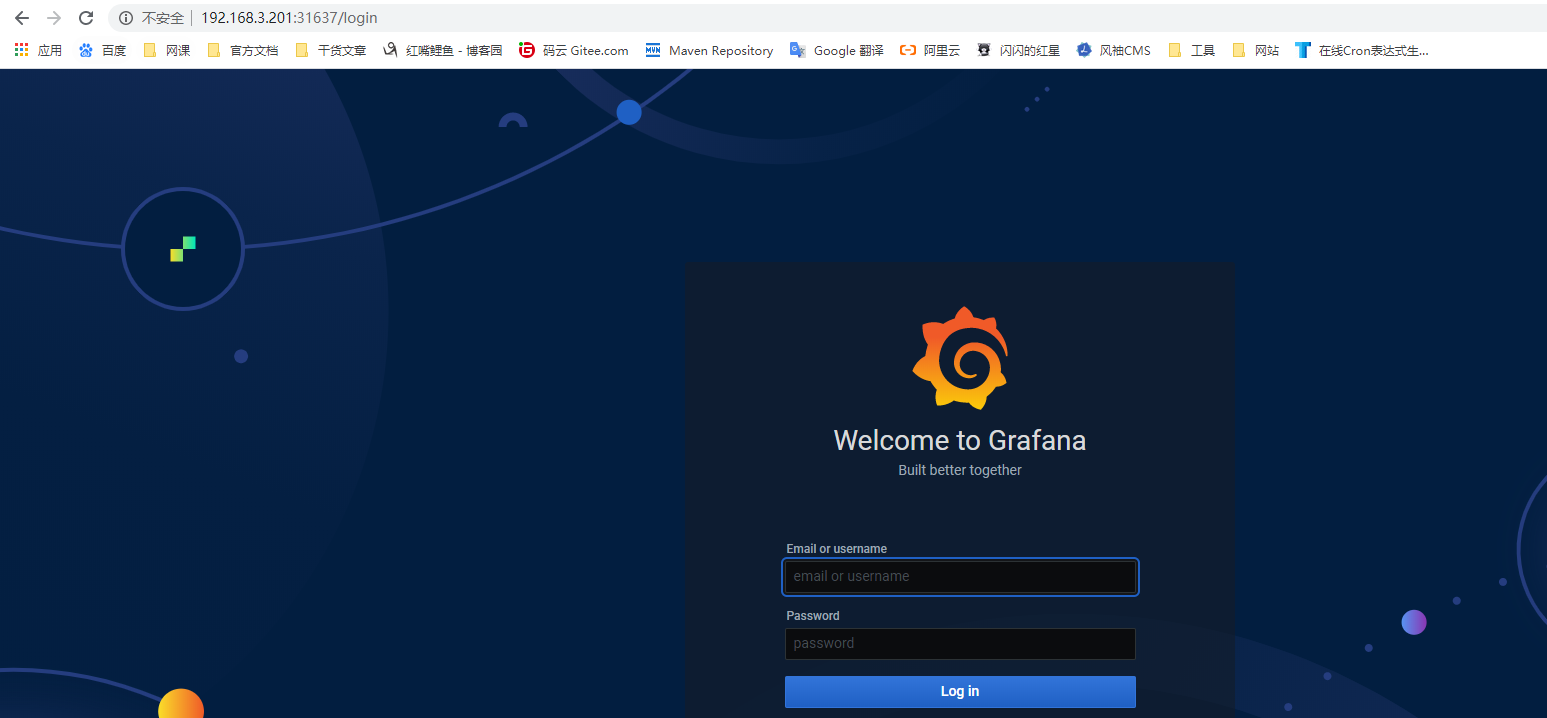
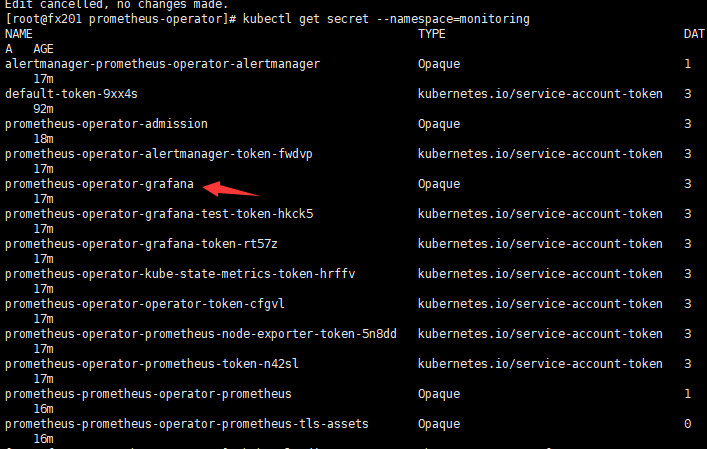
4)登陆密码查询
1.找到grafana的secret名称:kubectl get secret --namespace=monitoring
![]()
2.查询该secret: kubectl edit secret prometheus-operator-grafana
![]()
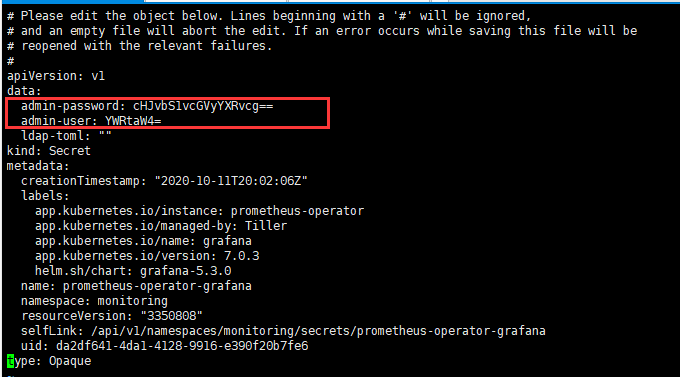
3.将 user和password进行base64反编译,登陆。
 ,密码为prom-operator
,密码为prom-operator
 ,账号为admin
,账号为admin 
登陆成功
4.再次踩坑,grafana看不到任何数据,报502bad gateway,问题尚未解决。。。
2.安装EFK
1)yaml批量下载
1.在github的k8s官网上下载对应的六个yaml文件
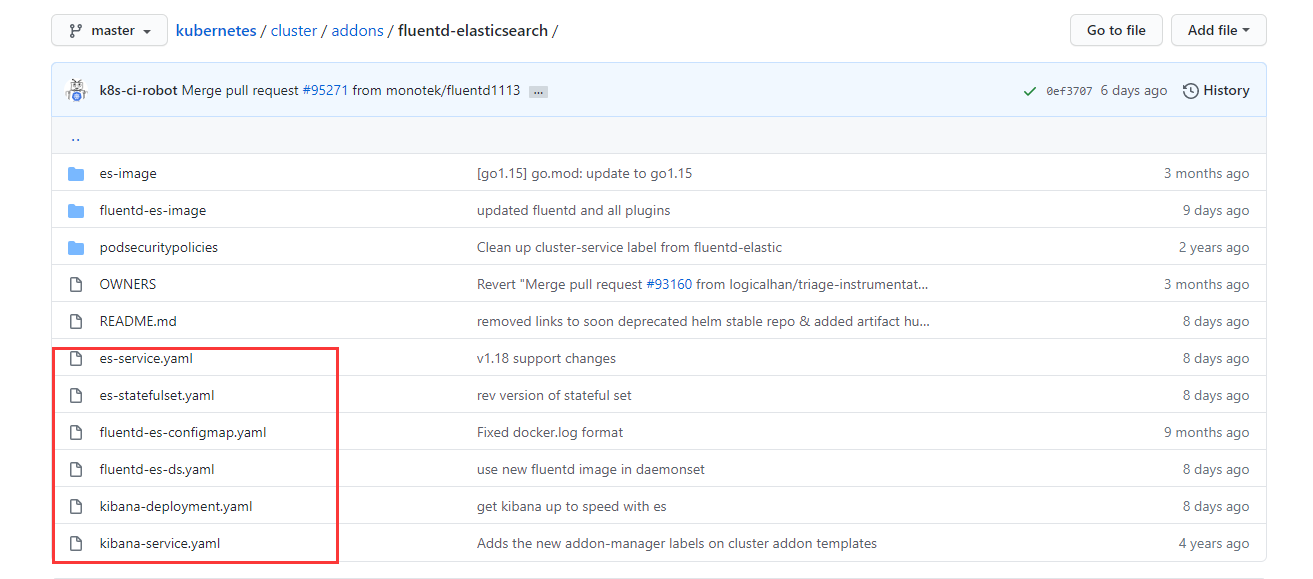
2.创建efk目录,将六个yaml文件放在该目录下
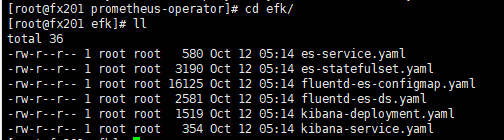
3.修改配置并批量部署
1)vi kibana-deployment.yaml,注释掉下面两行

2)vi kibana-service.yaml,修改成nodeport模式,并指定端口号
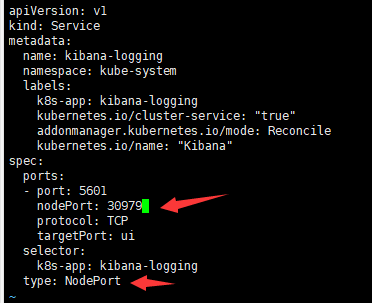
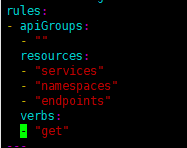
3)(踩坑)修改es-statefulset.yaml,里面有格式错误,改成如下写法
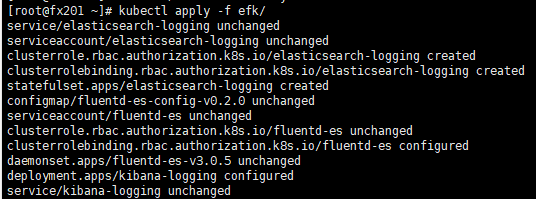
4)yaml批量部署:vim efk/es-statefulset.yaml
5)访问192.168.3.201:30979,成功
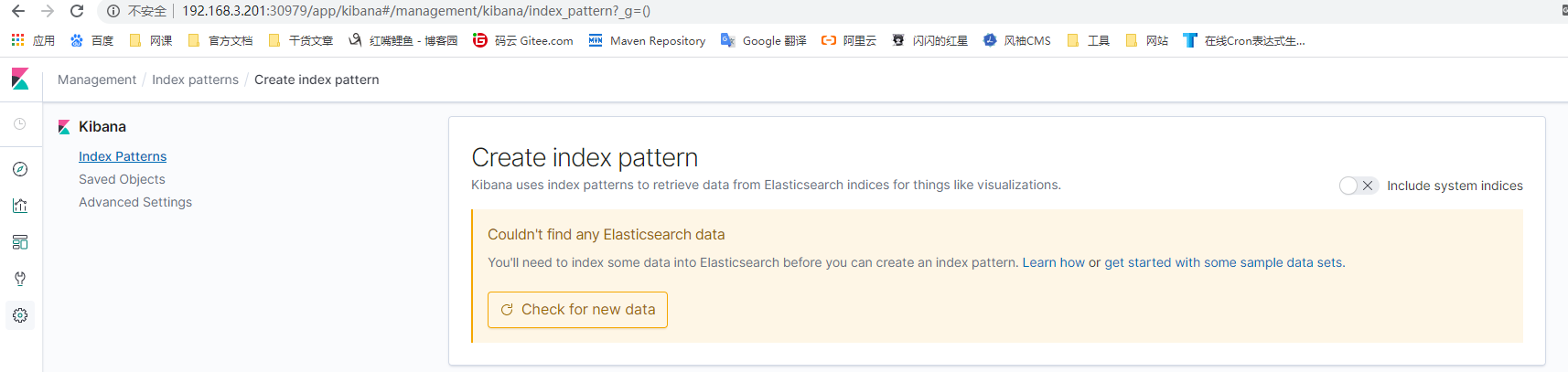
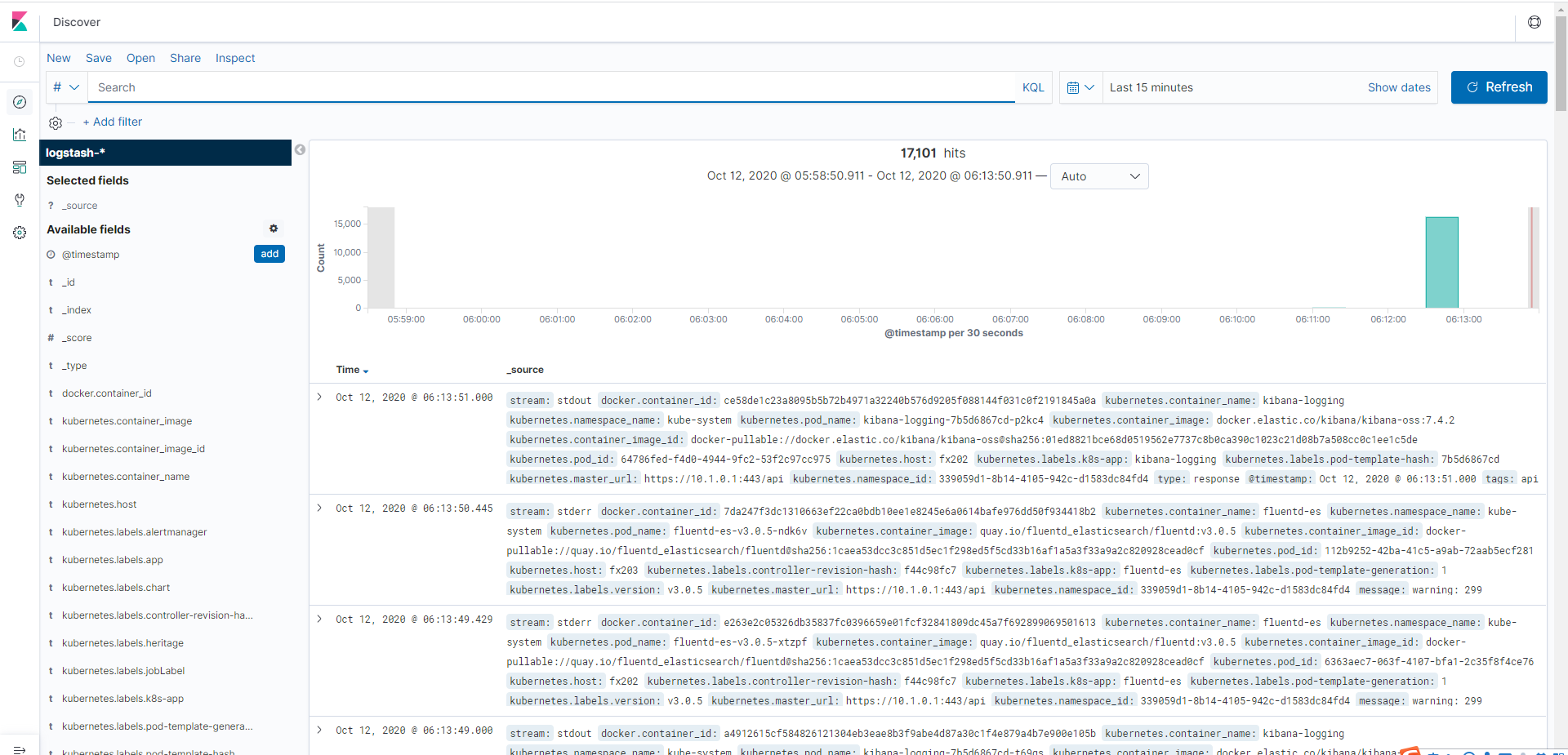
6)设置好index,成功看到日志信息
大型集群优化方案(上千节点)
网络协议:不用法兰绒大二层网络开销,改用calico
应用管理:不用yaml,改用helm统一管理
并行管理:master,worker,management,proxy节点分离
k8s全链路高可用升级
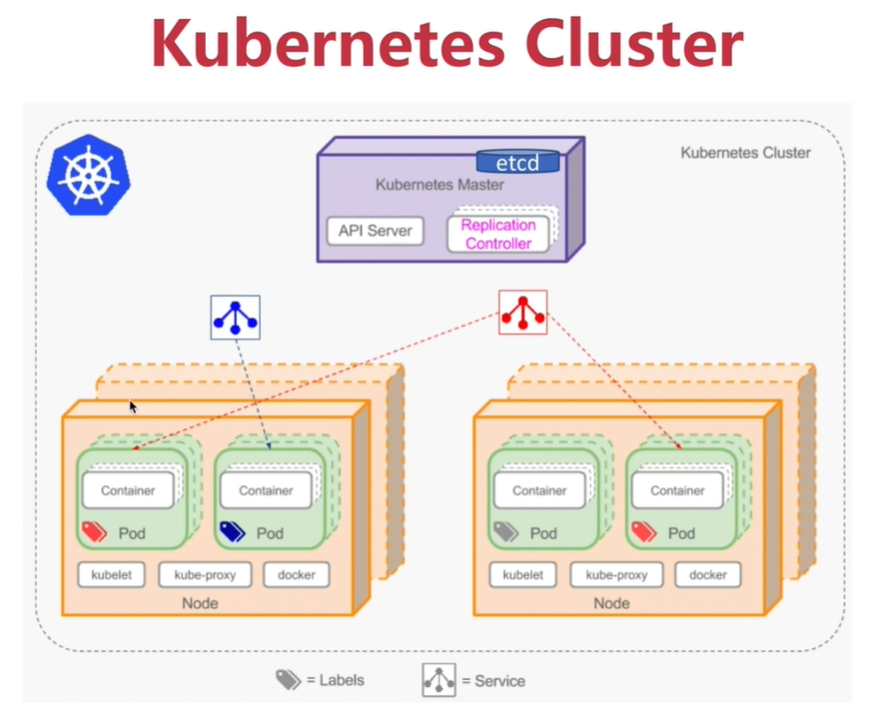
1.node节点高可用
1)node节点本身就有多个,只要保证deployment的replicas数量大于2
2)kube-dns高可用,避免只启动单个dns的pod,要跨节点部署多个
2.etcd高可用,第三种方案比较少用,推荐前两种,第一种方案最佳

3.kube-apiserver高可用,外部负载均衡(基于公有云的F5或者A10),内部负载均衡(ha-proxy+keepalived或者nginx集群)
,
4.master节点其他模块高可用

5.很多企业并没有实现master真正的高可用,应为绝大多数压力是在node节点上。master节点可以采用更好的硬件设备+主备来间接实现高可用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号