
四则运算生成器——感想
1.预估时间及实际花费时间表格
理想太丰满,显示太骨干
|
PSP2.1 |
Personal Software Process Stages |
Time |
|
Planning |
计划 |
|
|
· Estimate |
· 估计这个任务需要多少时间 |
15h |
|
Development |
开发 |
|
|
· Analysis |
· 需求分析 (包括学习新技术) |
2h |
|
· Design Spec |
· 生成设计文档 |
2h |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
3h |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
1h |
|
· Design |
· 具体设计 |
0.5h |
|
· Coding |
· 具体编码 |
10h |
|
· Code Review |
· 代码复审 |
2h |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
5h |
|
Reporting |
报告 |
|
|
· Test Report |
· 测试报告 |
1h |
|
· Size Measurement |
· 计算工作量 |
0.5h |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
0.5h |
|
合计 |
27.5h |
2.算法思路
这次的题目其实是两个程序(很不能理解这么做的目的。。。。),一个任务是:自己生成四则运算表达式,自己运算出答案,另一个任务是:根据所给的题目文件及答案文件,判断正误。
最初我认为第一个任务是比较简单的,因为当时觉得比较运算符之间的优先级是比较麻烦的, 要先转化成后缀,再进行计算,一直想避免这个问题,最终还是没绕过。第一个任务中,思路主要
是:在生成一个算式之前,先生成一个随机数,来判断这个算式中将要有几个运算符,而整数与分数的生成也是靠一个随机数决定的,很重要的一点是整数也看成分数(整数/1)进行运算。然后再
每次的循环中,随机生成一个数字与运算符,并利用运算符进行决定是否添加括号(随机数真的是一个很神奇的东西),这些都生成以后,就要调用deal()函数判断子式是否为负(小学生不懂
负数。。。),并以此决定是否舍弃本次生成的数字和运算符;
在一个式子生成以后,重头戏来了,查重!!我想了很多的方法,但对于我的程序来说,操作起来都比较困难,最终,我选择了一个很“贱”的方法,直接比较答案,每生成一个式子,就令它的答
案与之前所有的式子的答案进行比较,如果发现相等,那么不好意思,本次生成的式子就可以滚蛋了,直接舍去!我试验了一下,生成100道题目时,查重答案的操作会多生成20道题;生成1000道
时,会多生成将近300道;但生成10000道题目时,会多生成将近7000道!!咳咳,这不是重点,重点是没有重复的题目了(我也觉得这个效率有点低),然后就OK了。
第二个任务相对于第一个来说,就是相当之简单了,只要扫描题目文件,并套用第一个任务里的函数就可以实现了。
3.程序分析
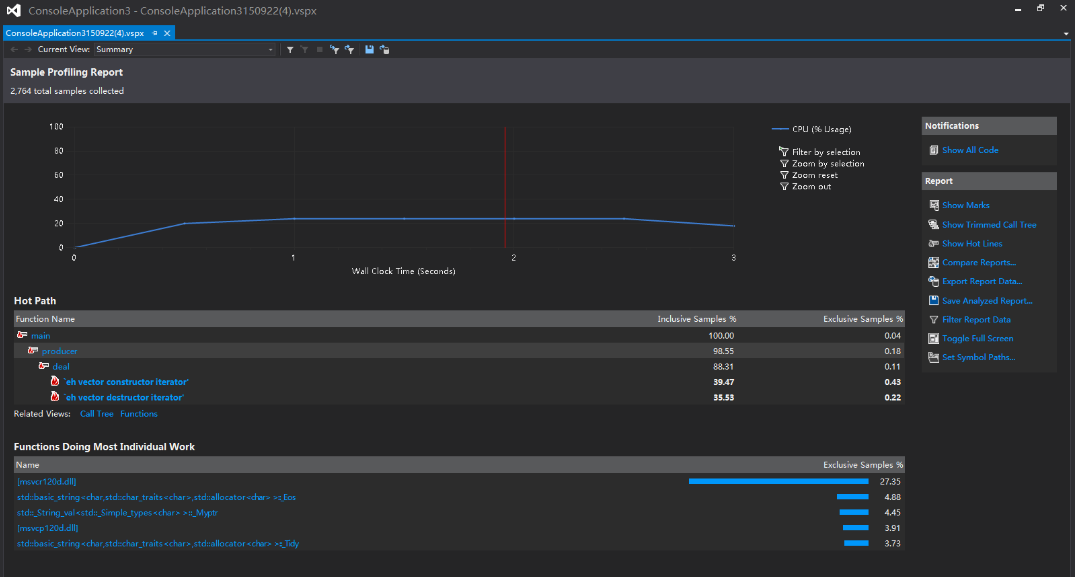
这是在测试—r 10 -n 1000的命令时,所生成的图,在to_string上花了较长的时间,在提升程序的性能中,也想了很多的方法,但最终都没有很大程度的提高,只在部分
函数中提高了一点性能,没办法。。。。
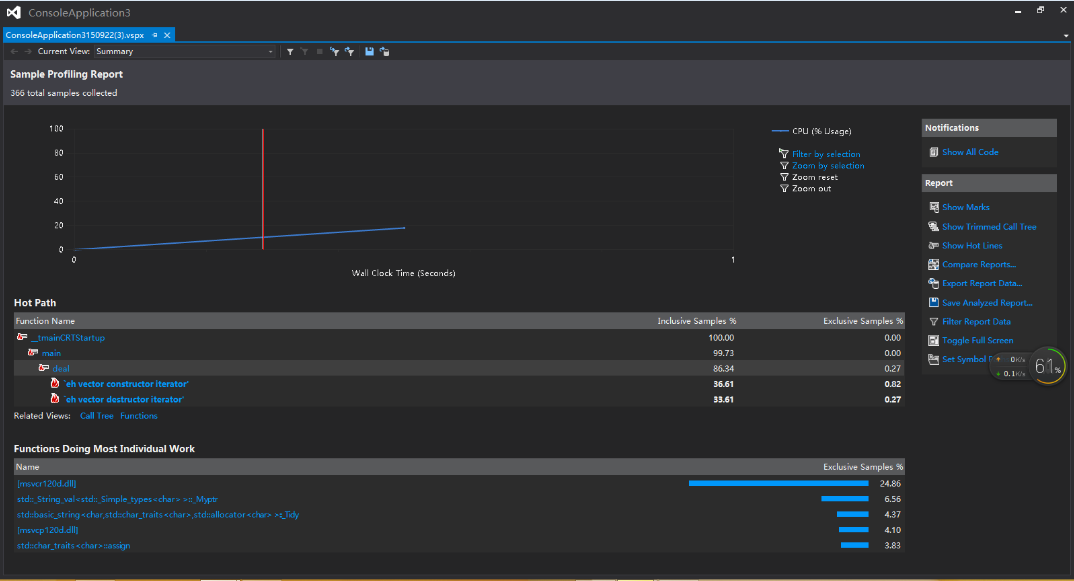
这是测试-e 1.txt -a 2.txt 命令时,生成的图
在程序生成的过程中,也发现了几个重要的问题(对于我而言):
1.分数运算的问题
由于程序涉及到分数的问题,所以在计算中,会出现通分,约分之类的问题;
2.存储数据的问题
由于int有范围,在运算过程中可能出现超过int型范围的数字;
3.substr()函数
substr()函数在C++中与java中,是有差别的(这一个点坑死我了),substr(int 1,int 2) 2表明的含义是:要截取的字符串的长度,并不是java中的字符位置;
4.strtok()函数
这个函数类似于java中的spilt(),char *strtok(char s[], const char *delim);
分解字符串为一组字符串。s为要分解的字符串,delim为分隔符字符串。
4.测试用例
1. 测试-r x1 - n x2 命令时:
x1不能大于100,虽然程序亲测1000以内的也可以生成,但是时间太长,不算!
2. SIZEYUNSUAN.exe -n 10000 -r 100
//生成10000个式子,范围是100以内
3. SIZEYUNSUAN.exe -e exercise.txt -a answer.txt
//校验两个文件里面的答案,生成结果在Grade.txt
4. SIZEYUNSUAN.exe -n 10
//提示需输入正确并完整的参数
5. SIZEYUNSUAN.exe -r 10
//提示需输入正确并完整的参数
6. SIZEYUNSUAN.exe -e exercise.txt
//提示需输入正确并完整的参数
7. SIZEYUNSUAN.exe -a answer.txt
//提示需输入正确并完整的参数
8. SIZEYUNSUAN.exe -n 10001 -r 100
//提示需输入正确的题目个数
9. SIZEYUNSUAN.exe -n 1000 -r -1
//提示需输入正确的数的范围
10. SIZEYUNSUAN.exe -e 1.txt -a answer.txt
//提示文件1.txt不存在
11. SIZEYUNSUAN.exe -e exercise.txt -a 2.txt
//提示文件2.txt不存在
SIZEYUNSUAN.exe -n 10000 -r 100 -e exercise1.txt -a answer1.txt
//生成题目并完成校验,两个功能依次完成
5.个人感悟
理想很丰满,现实很骨干,我第一次看到题目的时候,虽觉得有点麻烦,但还是觉得比较容易写的,就用了一个下午的时间写完了整个程序,然后发现。。。。。。和要求差
的有点多,在推倒重写和维持以前的思路这二者之间挣扎了很久,最终还是“屈服”了——重写!
虽说“历经艰难”,但还是完成了,觉得还是学到了很多,没有deadline的逼迫,是不会在这么短的时间里写出来的。

