并行编程模型和库等相关内容
在讨论并行编程之前,需要首先纠正一个概念,即“多线程只能是并发执行的”。
在本科阶段的操作系统的课程学习中,特意有强调过并发和并行的区别,并发是指在一段时间内多个任务(指的是线程或进程)按照时间片轮转的方式依次执行,某一时刻仅有一个任务在执行;而并行是指任务同时执行,即某一时刻是存在多个任务共同执行的。
首先说这种说法本身并没有错误,并发和并行的概念也确实如此。但是最初提到多线程,我们认为多个线程之间是并发执行的,产生这种想法的原因在于我们一直将分析的基础定在了单核CPU上。
在单核CPU时代,并发和并行是两个不相关的概念,多线程确实只能做到并发而不能并行。但是进入多核CPU时代后,单核上可以通过多线程并发,在不同核心之间能够做到线程之间的并行。因此说多线程和并行编程两个并不冲突,OpenMP恰恰也属于一种多线程模型,与C++提供的线程库不同之处在于,OpenMP把线程的控制权交给了编译过程,并不需要程序员自行管理这种复杂易出错的过程。
综上所述,我们应当认识到多线程和并行并不是两个不相关的概念,多线程恰恰是属于并行编程实现方式的一种。
而我们往往会疑惑,直接使用C++提供的线程库难道也可以做到并行吗,我们并没有在代码中指定任何和线程是如何合理分配到多个CPU核心上相关的内容。实际上创建并启动线程后,线程的调度和分配到多个 CPU 核心上的过程是由操作系统和硬件自动管理的,开发人员的任务是把任务要计算的内容合理地分配到多个线程中,以便在多核 CPU 上充分发挥性能。而OpenMP等方式则是利用各自的机制合理分配计算任务到多个线程中,然后在操作系统的管理下,将线程分配到多个CPU核心上进行计算。
MPI 和 OpenMP 都属于并行计算库,不局限于特定的硬件
CUDA和HIP都是针对特定硬件的编程平台
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的用于并行计算的编程模型和平台。它主要用于NVIDIA的GPU(图形处理器)架构上,如NVIDIA的Tesla、Quadro和GeForce系列显卡。CUDA程序通常使用NVIDIA提供的编译器和工具链进行开发和优化。
HIP(Heterogeneous-Compute Interface for Portability)是由AMD开发的用于并行计算的编程接口。它旨在提供跨不同硬件平台的可移植性,包括AMD的GPU和CPU。HIP可以在AMD的GPU架构上,如Radeon和FirePro系列显卡,以及x86 CPU上进行开发。
HIP 可以看为 AMD 对标 NVDIA 的 CUDA而推出的一种编程模型,HIP 和 CUDA 二者的组成部分基本是一一对应的,甚至可以通过转换工具直接将程序在二者之间进行转换。
二者之间的对应关系如下图所示
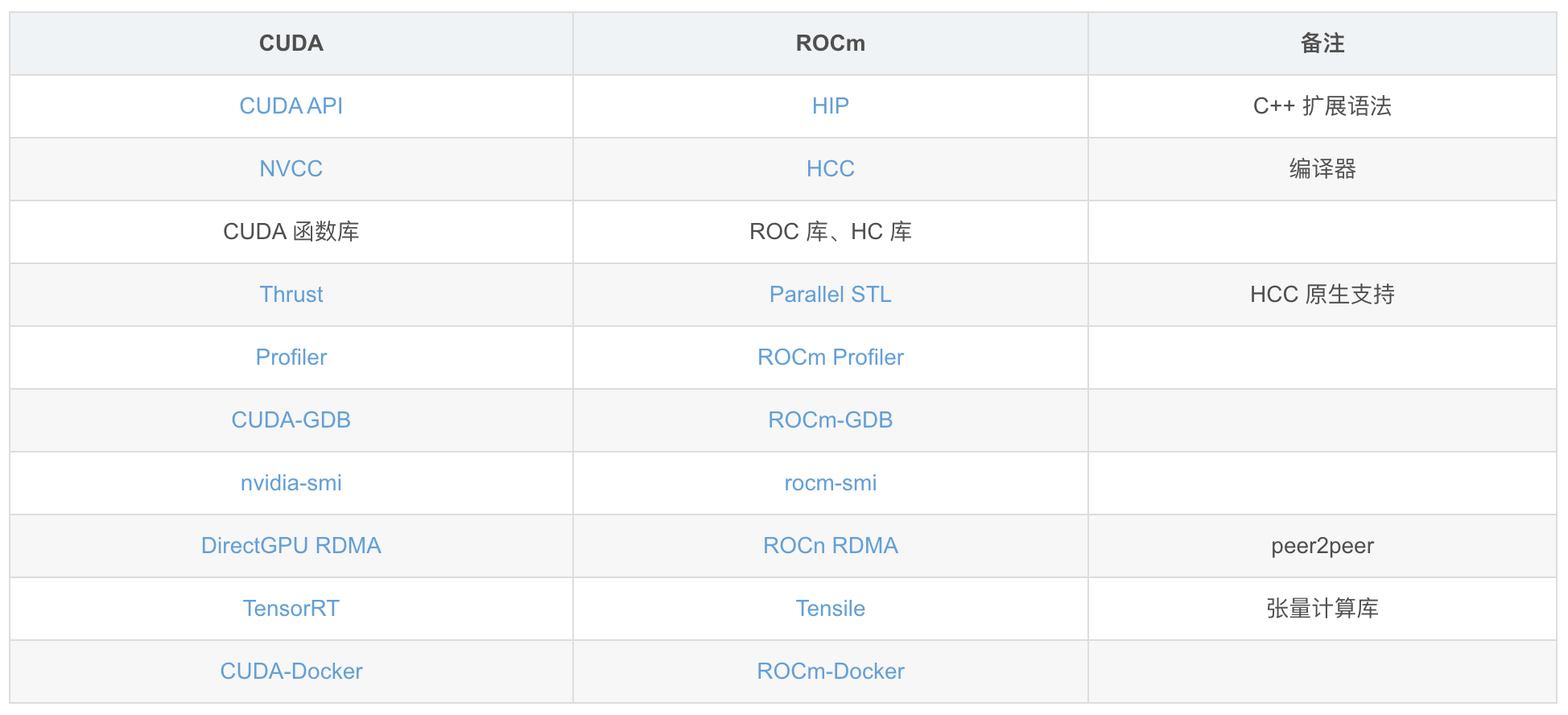
除了以上常见的并行编程模型和库之外,还包含以下内容
- OpenCL:OpenCL是一个跨平台的并行编程框架,可用于编写可在不同硬件上运行的并行计算应用程序。它支持各种设备,包括GPU、CPU、FPGA等。
- SYCL:SYCL(Single-source C++)是一种基于C++的并行编程模型,用于编写高性能并行代码。SYCL通过将并行计算任务表示为C++函数对象,并使用简洁的C++代码来描述数据依赖关系,实现了简化的并行编程。
- Chapel:Chapel是一种新型的并行编程语言,旨在简化并行计算的开发。它提供了高级的并行构造,如任务并行、数据并行和工作流,并支持多种硬件平台。
- TBB:TBB(Threading Building Blocks)是一个面向C++的并行编程库,用于实现可扩展的并行算法。TBB提供了一组高级的并行原语和算法,可以在多核处理器上利用任务并行。
相关企业
相关库
相关大牛
Reference
- [1] CUDA 和 HIP 对比


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理