GPU Structure and Programing(CUDA)
- CUDA C只是对标准C进行了语言级的扩展,通过增加一些修饰符使编译器可以确定哪些代码在主机上运行,哪些代码在设备上运行
- GPU计算的应用前景很大程度上取决于能否从问题中发掘出大规模并行性
Kernel hardware mapping
kernel function -> GPU
block -> SM(one block can only be executed by one SM, but one SM can execute multiple blocks)
thread -> SP
main time consuming:
- kernel function startup
- thread block switch
Hardware structure
Grid、Block are login concepts, they are created by CUDA for programmers.
According to the real physical level, every SM in GPU will excute multiple blocks, and it will divides block into multiple warps. The basic execution unit of SM is warp.
Some official concepts about warp:
- A block assigned to an SM is further divided into 32 thread units called warps.
- The warp is the unit of thread scheduling in SMs.
- Each warp consists of 32 threads of consecutive threadIdx values: thread 0 through 31 form the first warp, 32 through 63 the second warp, and so on.
- An SM is designed to execute all threads in a warp following the Single Instruction, Multiple Data (SIMD) model
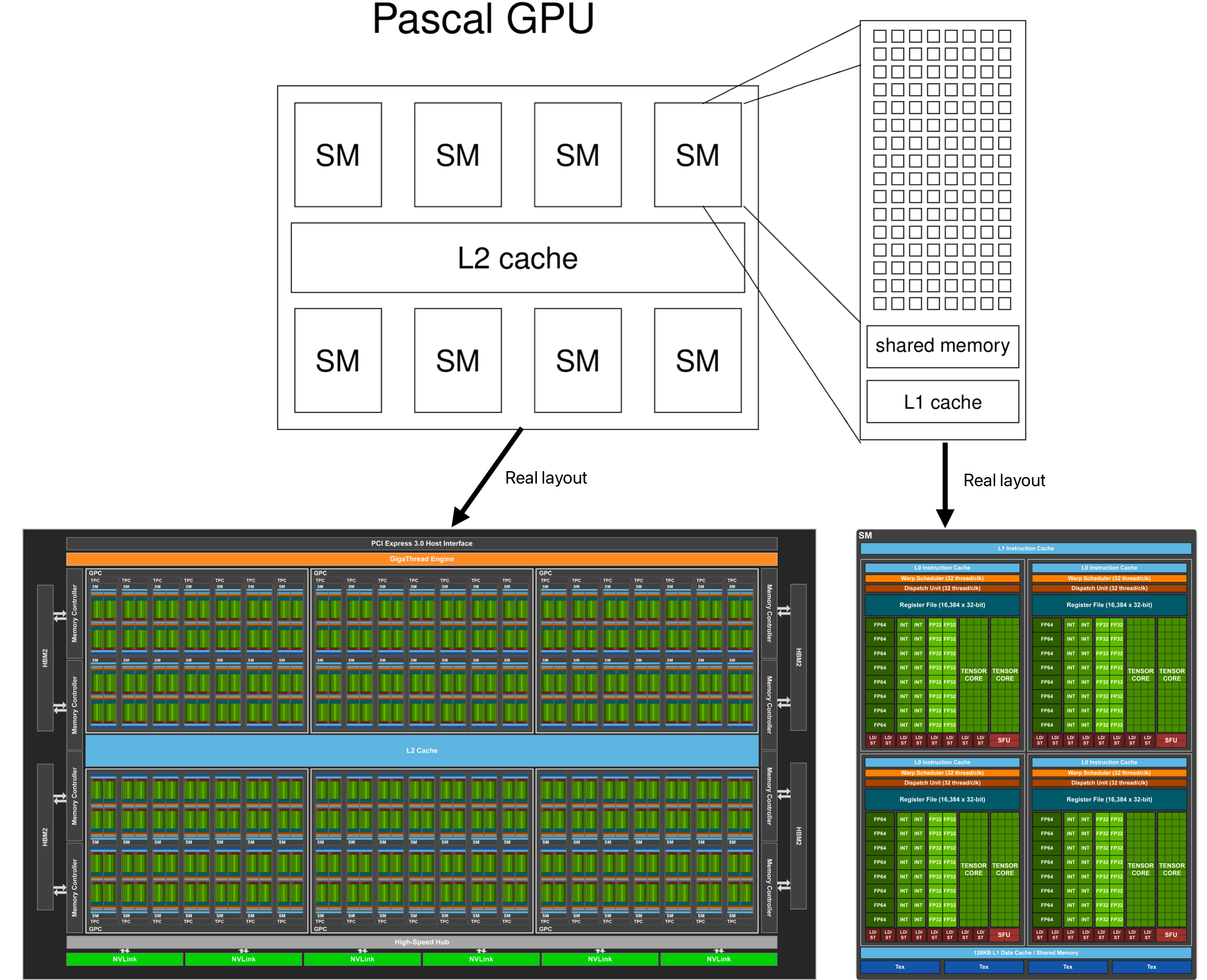
Memory structure
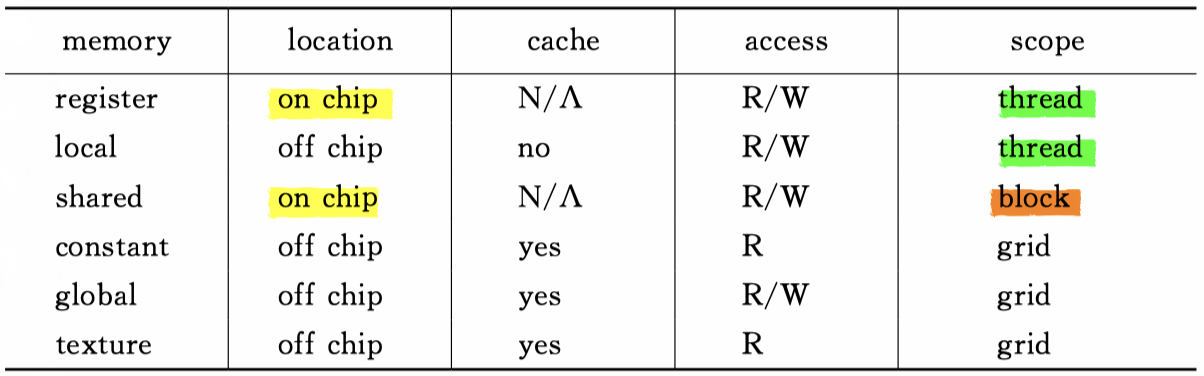
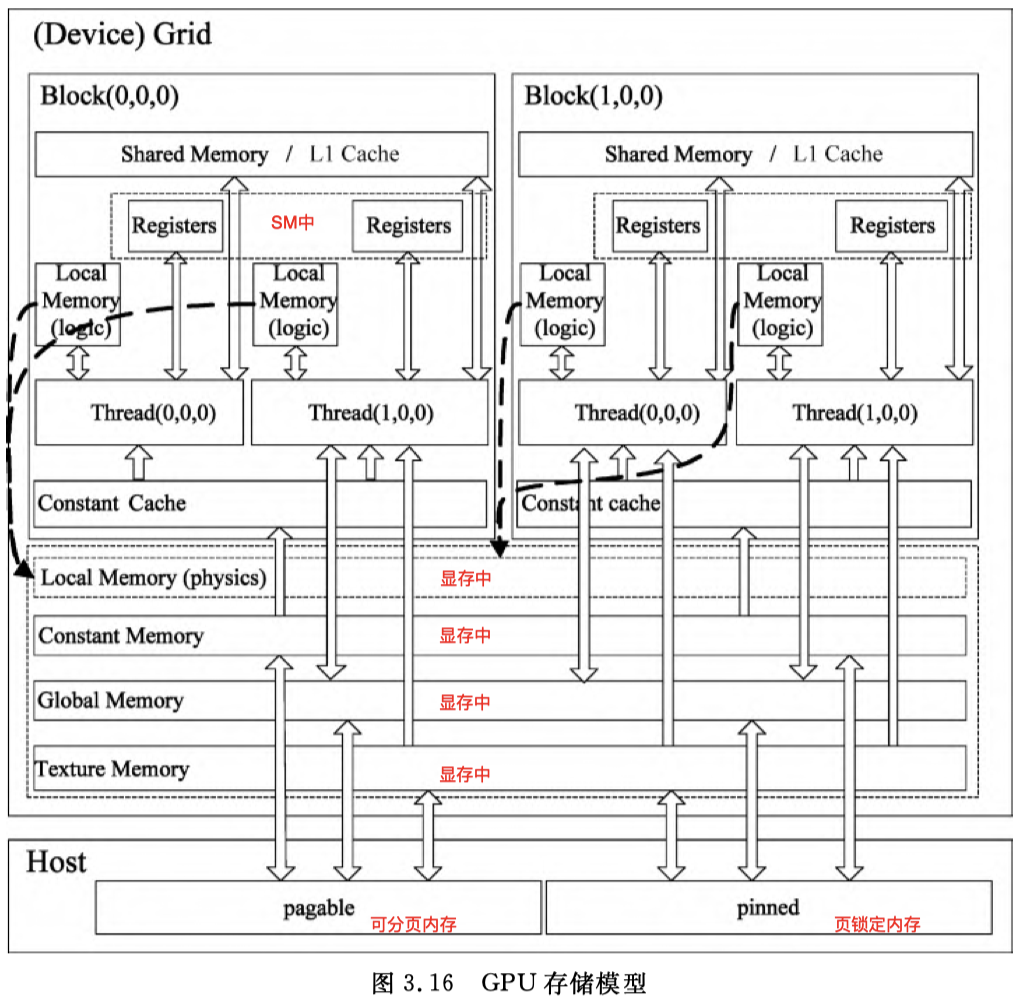
How to detect the using situation of the different types of memory?
-
Use nvcc compilation option
--ptxas-option=-v
--ptxas-optionis used to specify options directly to ptxas(the PTX optimizing assembler, its location in the whole compilation process can be seen at CUDA Compilation) -
Use nvcc compilation option
-keep -
Use
nvprofcommandnvprof --print-gpu-trace <program path>
Shared Memory
Create Shared Memory
- 静态shared memory,使用
__shared__限定符创建时就指定存储空间的大小
__shared__ float array[1024];
- 动态shared memory,不确定空间大小,需要动态申请时
extern __shared__ float array[1024];
需要在kernel函数调用时,指定申请的shared memory的大小
kernel<<<gridSize, blockSize, sizeof(float) * 1024>>>( … );
在C/C++中,存在一个变长数组(Variable Length Arrays,VLA)的概念,允许使用变量来指定数组的大小。
但是实际测试,变量指定数组大小应用于kernel函数时,会报错"error: expression must have a constant value"
Bank Conflict
Software structure
All CUDA threads in a grid execute the same kernel function;
It is easy to explain it. When we want to call a kernel function, we will specify the grid and block structure using the dim3 data type. It means that we want to use all these threads where locate in the grid to execute this kernel function.
In general, a grid is a three-dimensional array of blocks1, and each block is a three dimensional array of threads.
From a code implementation perspective, these two three-dimensional arrays are both a dim3 type parameter, which is a C struct with three unsigned integer fields: x, y, and z.
The first execution configuration parameter specifies the dimensions of the grid in the number of blocks. And the second specifies the dimensions of each block in the number of threads.
For example, as the following code shows, there is a grid and a block. The grid consists of 32 blocks, and it is a linear structure. The block consists of 128 threads, and it is also a linear structure.
dim3 dimGrid(32, 1, 1);
dim3 dimBlock(128, 1, 1);
vecAddKernel<<<dimGrid, dimBlock>>>(...);
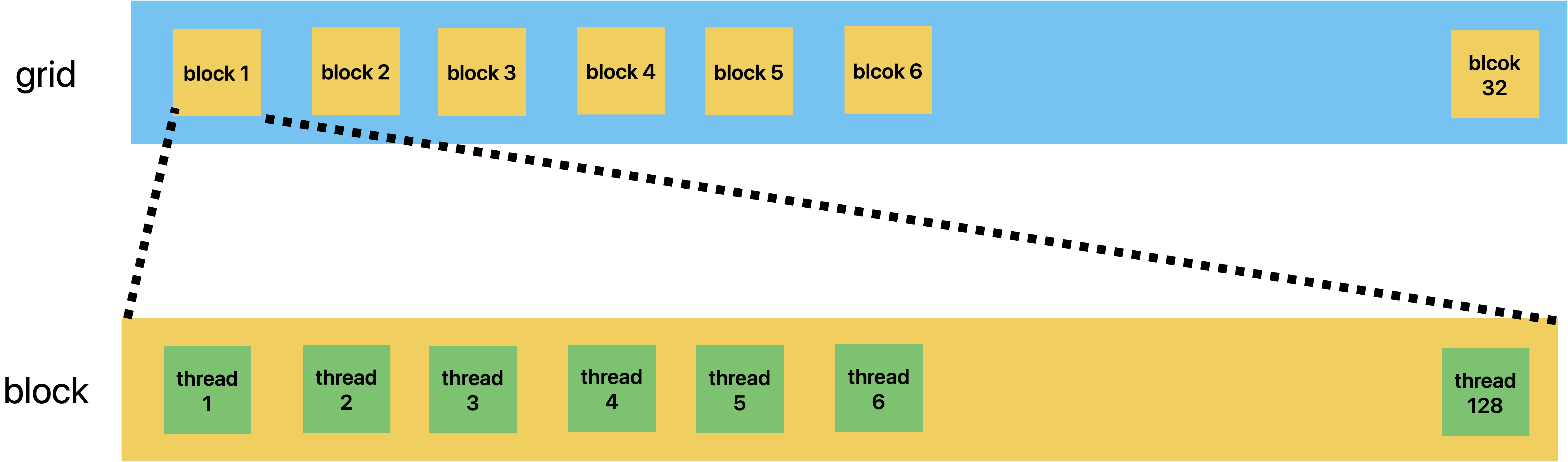
About the more detail specifications please see official technical specifications
Warp
The multiprocessor creates, manages, schedules, and executes threads in groups of 32 parallel threads called warps.
一个SM可能执行多个block。虽然说不同block之间可以并行执行(不过要求在不同SM上才可以并行),但是映射到同一个SM的block,它上面的warp是不能并行执行的,只能相互等待。
Software stack

Kernel Function
Because the execution of the kernel function is asynchronous, that means the subsequent codes don't know when the result will be returned by kernel funcion, so the type of returen value of kernel funciont must be void.
- CPU以及系统内存成为主机,GPU及其内存成为设备
- GPU设备上执行的函数称为核函数(Kernel)
- 核函数调用时<<<para1,para2>>>中的para1表示设备在执行核函数时使用的并行线程块的数量,通俗来说总共将创建para1个核函数来运行代码,共para1个并行执行环境,para1个线程块。这para1个线程块称为一个线程格(Grid)
- 核函数中存在一个CUDA运行时已经预先定义的内置变量blockIdx,表示当前执行设备代码的线程块索引
The difficulty of writing parallel programs comes from arranging the structure of grid、block and thread so that they can adapt the programs.
What we ought to know is that the kernel funtion is just like a big loop in logic, it will enumerate the whole grid in threads.
Note: This perspective is just from code, it is not the true execution logic.
指针
主机指针只能访问主机代码中的内存,设备指针只能访问设备代码中的内存
设备指针
虽然cudaMalloc()同malloc(),cudaFree()同free()非常相似,但是设备指针同主机指针之间并不完全相同,设备指针的使用规则如下
cudaMalloc()分配的指针可以传递给设备函数,设备代码可以使用该指针进行内存读/写操作(解引用)cudaMalloc()分配的指针可以传递给主机函数,主机代码不可以使用该指针进行内存读/写操作(解引用)
主机指针与设备指针数据拷贝
- 主机->主机:
memcpy() - 主机->设备:
cudaMemcpy()指定参数cudaMemcpyHostToDevice - 设备->主机:
cudaMemcpy()指定参数cudaMemcpyDeviceToHost - 设备->设备:
cudaMemcpy()指定参数cudaMemcpyDeviceToDevice
The communication between CPU and GPU is asynchronous for high performance. So need to use the synchronous mechnisms for them.
Function type
__host____global____device__
When you don't specify the type of function, the default is the __host__
Host can call __global__, __global can call __device__, __device__ can call __device__
Memory
CUDA C提供了与C语言在语言级别上的集成,主机代码和设备代码由不同的编译器负责编译,设备函数调用样式上接近主机函数调用
cudaMemcpy() will synchronize automatically, so if the last line code is cudaMemcpy(), we needn't to use the cudaDeviceSynchronize()
Different devices corresponding to different memory functions
| Location | memory allocate | memory release |
|---|---|---|
| Host | malloc/new | free/delete |
| Device | cudaMalloc | cudaFree |
| Unified Memory | cudaMallocManaged | cudaFree |
Which memory types do we have ?
Host and device has different authorities to use the memory. The following table describes their authorities.
| Memory type | Host | Device |
|---|---|---|
| Global memory | W/R | W/R |
| Constant memory | W/R | R |
Why we need unified memory ?
- Additional transfers between host and device memory increase the latency and reduce the throughput.
- Device memory is small compared with the host memory. Allocating the large data from host memory to device memory is difficult.
Annotate: W means Write and R means Read
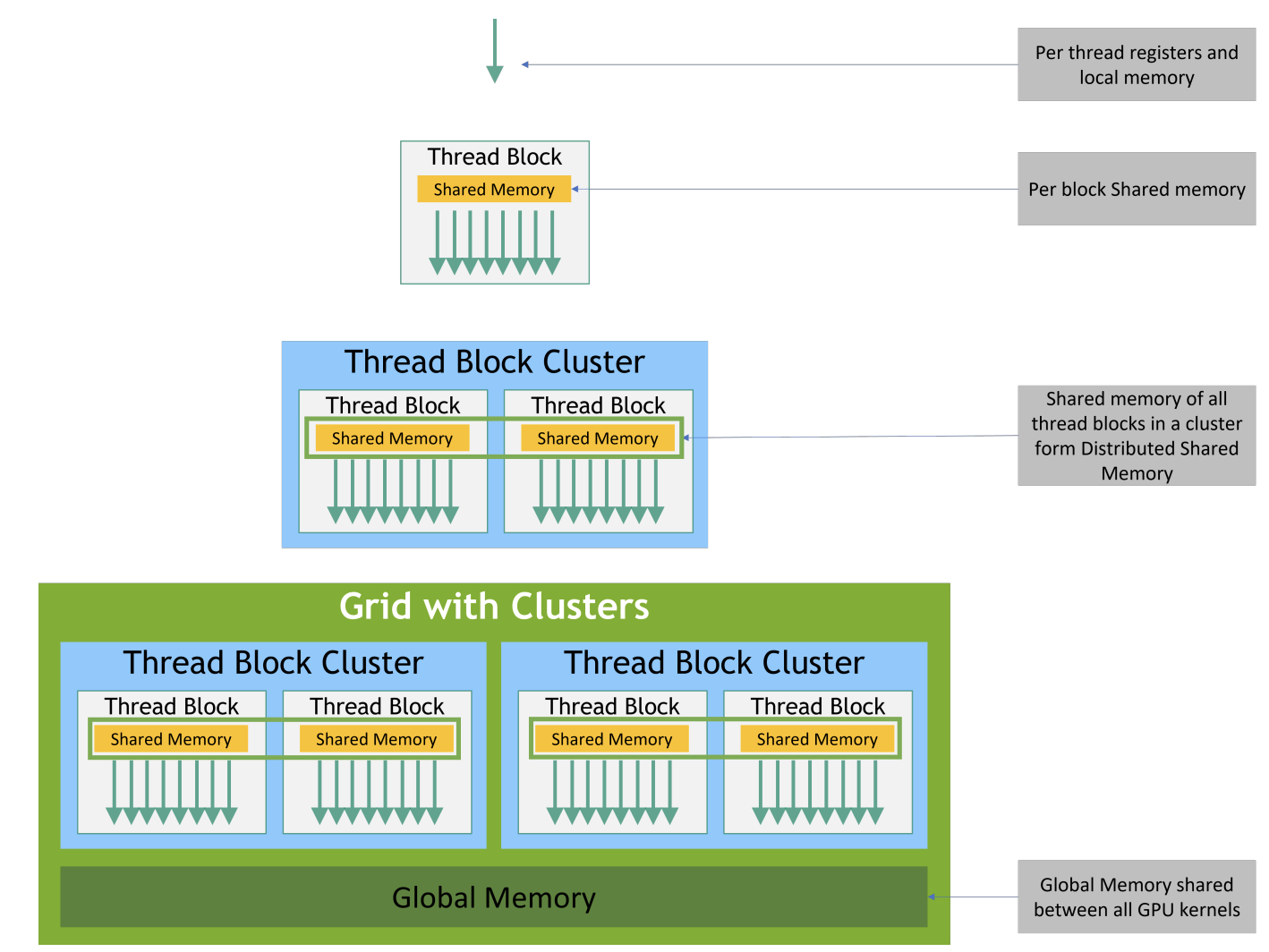
Common Parallelization methods
- Grid-stride loop
This method is used to solve the problem, the parallelism(并行度) is more than the quantity of threads.
In some situations, we can create many threads so that satisfied the parallelism, that we can allocate a separate thread for every threads.
But if the parallelism is more than the quantity of threads and we still use the above strategy, we will get the following result.
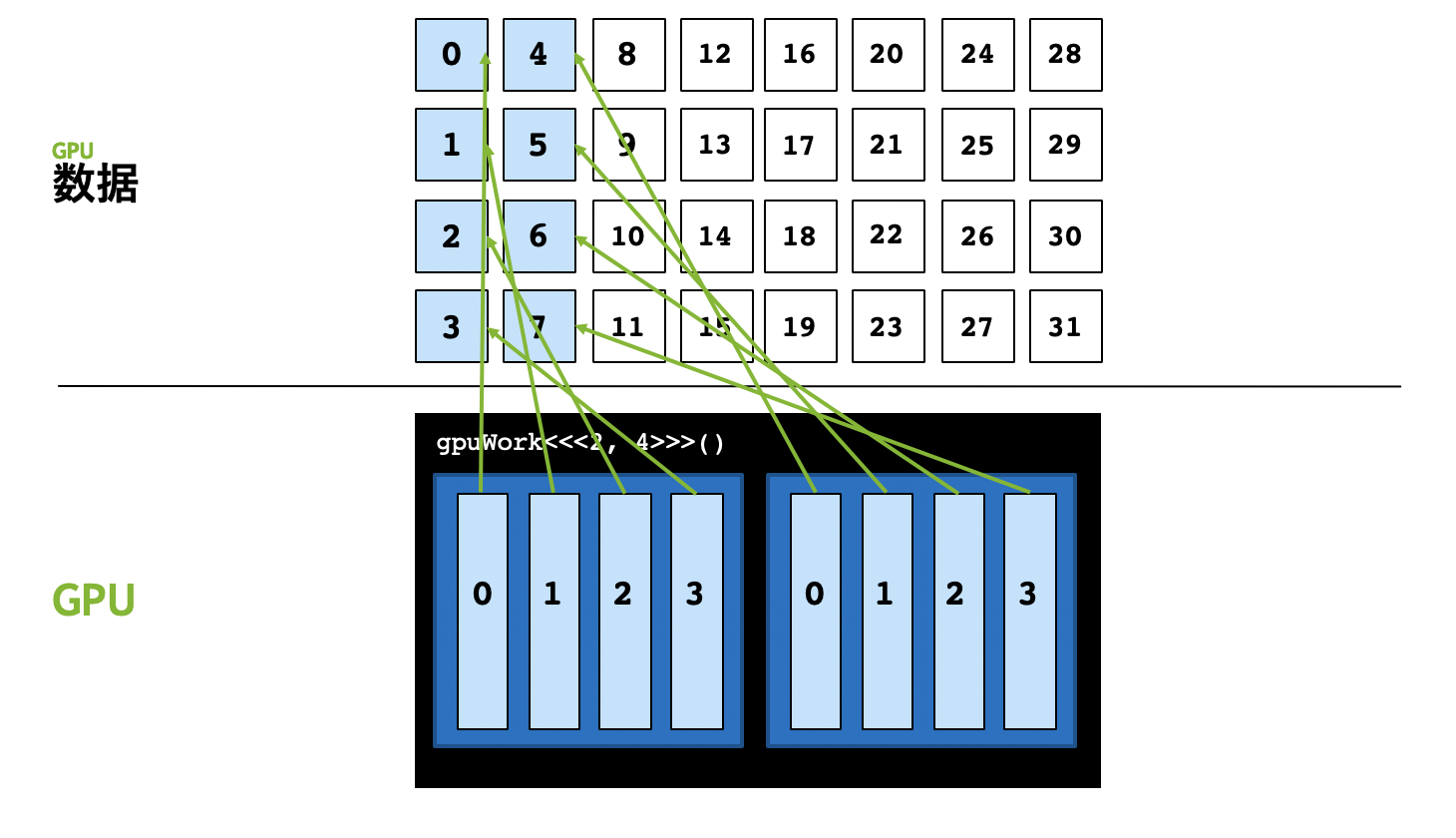
The parallelism is 32, but we just have 8 threads, we can't allocate a separate thread for every threads.
Grid-stride loop provide a new approach to solve this problem. At first, we studt the content of this method and we will think the core principle of this method.
The process of grid-stride loop looks like the following figure.
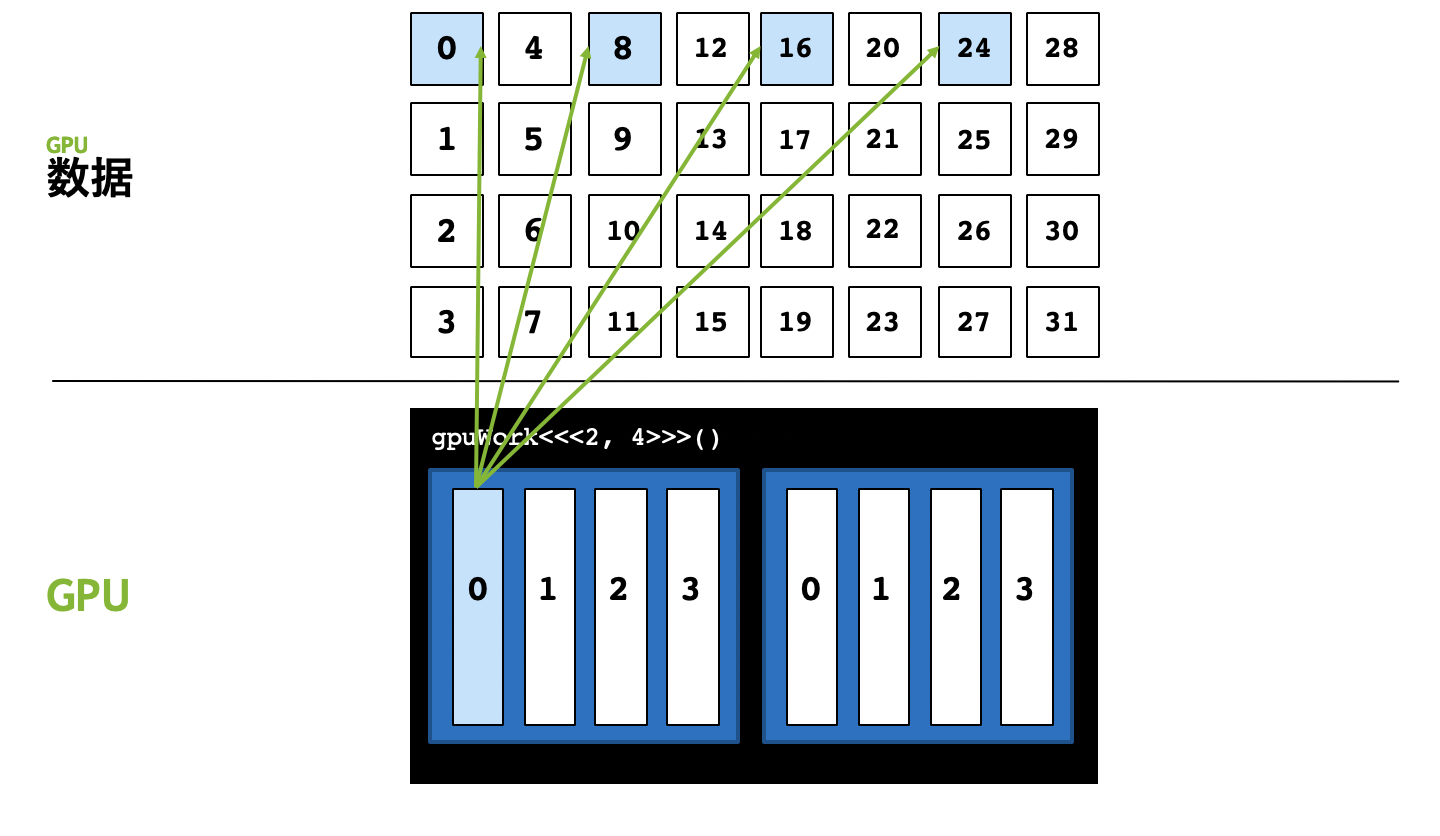
In short, the core approach to implement it is for (size_t i = threadIdx.x; i < n; i += <total number of threads>. When the number of threads is smaller than parallelism, we can't use the traditional method to implement the parallel, simply speaking, the distribution of thread can't satisfied the parallelism.
Grid-stride loop uses
- Another way to solve the data conflict
The most obvious answer is using mutex or atomic operation. But as we all know, whether it's mutex or atomic, they both have some consuming.
We know that the data conflict comes from shared data, different thread maybe use the same data at the same time. So an approach to avoid happening this problem is that control different threads use different data.
According to the process of Grid-stride loop, we notice that different threads use the different datas which have different locations. We can specify a fixed location to store a thread's data to avoid using the mutex or atomic.
A good example is array summation. As the following code shows.
#include <iostream>
#include <vector>
#include <cuda_runtime.h>
#include "CudaAllocator.h"
#include "ticktock.h"
#include <stdio.h>
__global__ void parallel_sum(int *arr, int *sum, int n) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n / 4;
i += gridDim.x * blockDim.x)
{
for (int j = 0; i + j < n; j += gridDim.x * blockDim.x) {
sum[i] += arr[i + j];
}
}
}
int main() {
int n = 1 << 4;
// unified memory
std::vector<int, CudaAllocator<int>> arr(n);
std::vector<int, CudaAllocator<int>> sum(n / 4);
for (size_t i = 0; i < n; i++) {
arr[i] = i;
}
// 设置共n/4个thread,每个block为4个thread,因此block数量为n / 4 / 4
dim3 blockSize(4);
dim3 gridSize(n / 4 / 4);
parallel_sum<<<gridSize, blockSize>>> (arr.data(), sum.data(), n);
cudaDeviceSynchronize();
int final_sum{0};
for (int i = 0; i < n / 4; i++)
final_sum += sum[i];
std::cout << "sum = " << final_sum << std::endl;
return 0;
}
Synchronization
CPU programing needs synchronous mechanism, GPU programing also needs it.
Atomic
We can learn about the execution logic by refering to C++ atomic and details of function by refering to CUDA C++ Programming Guide.
C++ Encapsulation
As we all know, the style of many CUDA APIs is C-style, we need to learn about how to use it conjunction with C++.
How does the std::vector standard template library use the Device(GPU) memory ?
Many examples use the original pointer to point a Device memory. But if we want to use a std::vector or other standard template library that locates in Device memory, we can't use the cudaMalloc() or cudaMallocManaged().
Taking the std::vector as an example, next, we will discuss the method of allocating Device memory for containers.
Whether it's principle or usage methods is too complex to understand in a short time. So pause it for a period of time. When we must need to learn its principle we study it again. We can learn about it from 一篇文章搞懂STL中的空间配置器allocator. In short, std::allocator integrates the memory management and object management by using four member function.
GPU execution core
一个kernel函数在逻辑上以block为单位映射到SM中,物理上以warp为单位解析指令将指令分发到具体的运算单元(SP/core, SFU, DP)或访存单元(LD/ST)。
SM中活动的warp数量占物理warp数量的比率为occupancy(占用率)。
CUDA Compilation
涉及到两部分内容,一部分是cuda面对编译问题时的设计架构,另一方面是cuda实际的编译流程
首先对CUDA程序的编译流程进行简要介绍,下图是NVIDIA CUDA Compiler Driver NVCC - The CUDA Compilation Trajectory中给出的cuda编译流程。
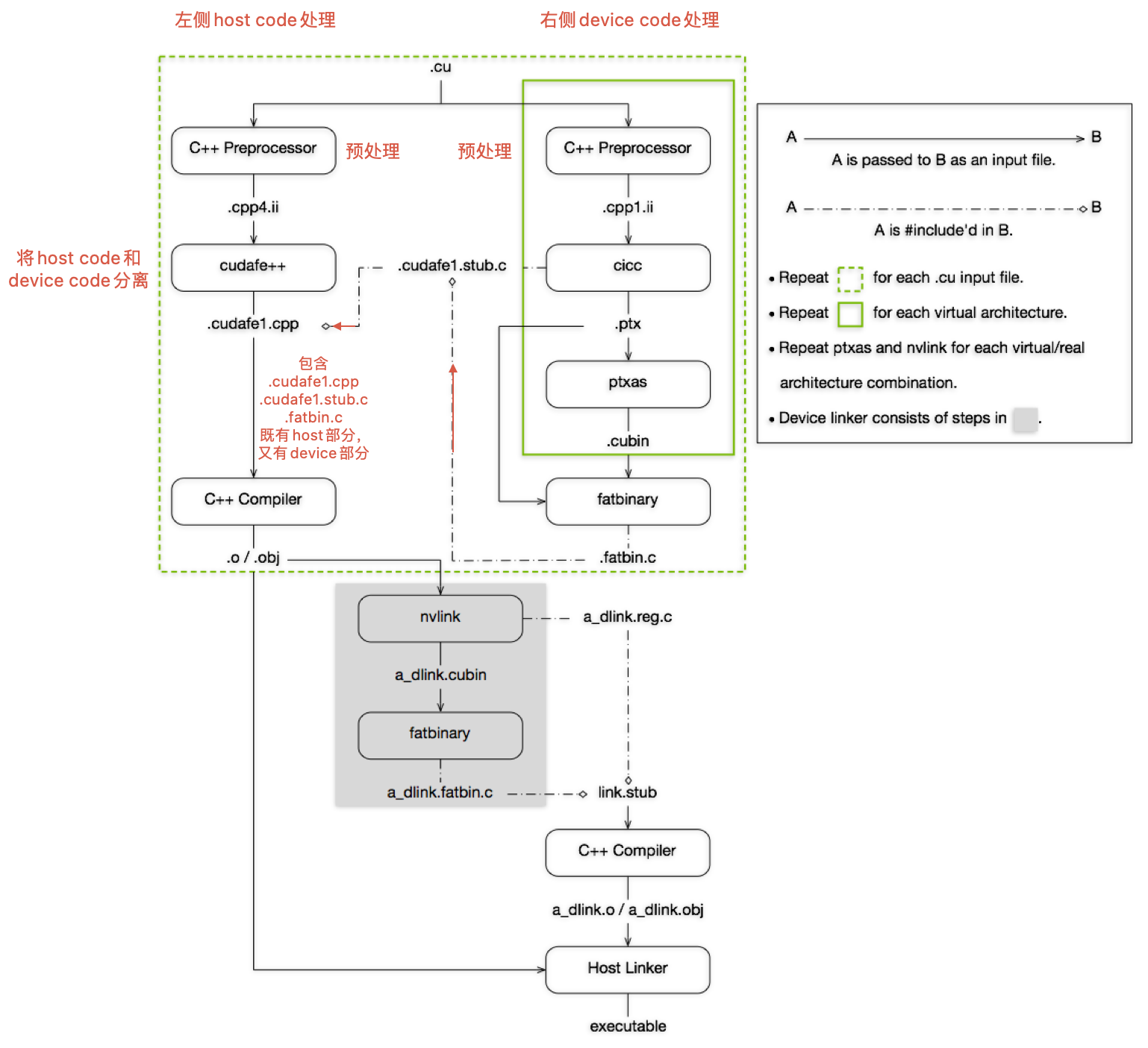
上图可以结合实际流程和用到的指令来理解,这些可以通过nvcc -dryrun <cuda program name>来获取到
-dryrun: List the compilation sub-commands without executing them.
生成的中间文件,可以通过nvcc -keep来获取到
-keep: Keep all intermediate files that are generated during internal compilation steps.
下面结合编译流程主要说明以下几个问题:
- 何为PTX,为何会设计它
- 何为SASS,为何会设计它
因为硬件在发展过程中,设计和架构可能会发生很大的改变,为了避免在硬件更新时软件发生较大的改变,一种常用的设计策略是抽象。即把真实的物理架构抽象为逻辑架构,开发者仅需要关注逻辑架构,从逻辑到物理的映射由框架开发商完成。
CUDA处理这个问题时采用的也是这种策略。其将结构分为两种:
- 虚拟GPU结构(Virtual Architecture)
- 真实GPU结构(Real Architecture)
PTX实际就是Virtual Architecture的汇编产物,它是一种指令集,由于考虑的只是逻辑架构,因此它可以在不同物理架构的GPU上使用。而SASS则是对应的Real Architecture,它是实际运行在物理设备上的指令集。在实际编译过程中,它们分别对应着生成.ptx和.cubin两个文件的过程,简图如下所示。
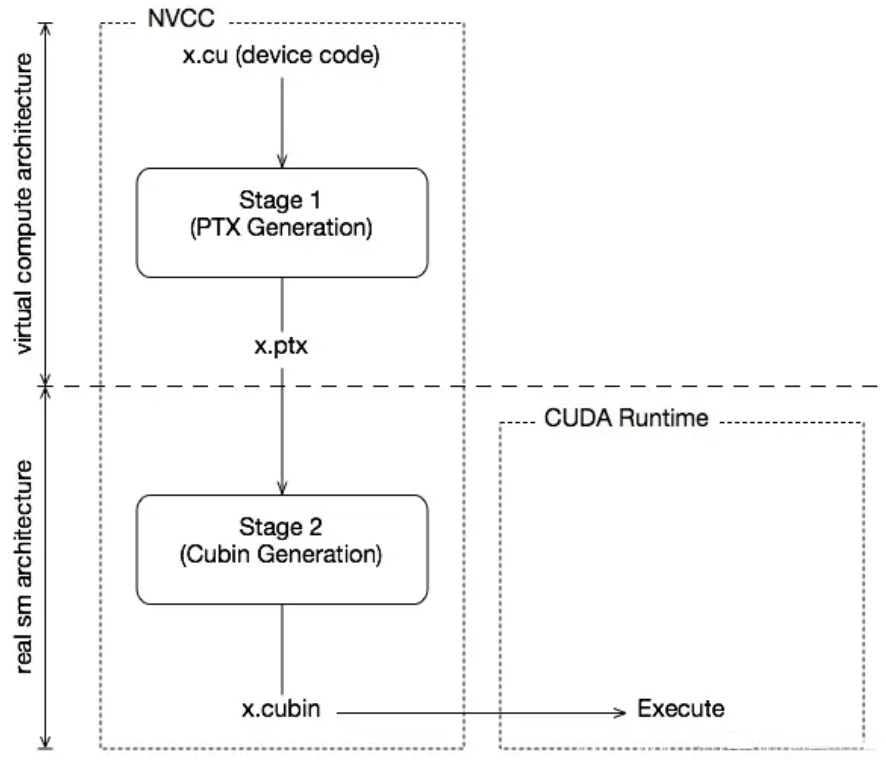
同时在编译时,也可以通过选项来指定不同的Virtual Architecture和Real Architecture。-arch=compute_52(-arch = --gpu-architecture)是指对虚拟GPU体系结构进行配置,生成相应的ptx。 -code=sm_52(-code = --gpu-code)是对实际结构进行配置。要求Virtual Architecture的版本要低于Real Architecture的版本,这一点是不难理解的。
cicc -arch=compute_52 "sample.cpp1.ii" -o "sample.ptx"
ptxas -arch=sm_52 "sample.ptx" -o "sample.sm_52.cubin"
可以发现上述示例命令中的选项和描述并不对应,第2条指令使用-arch但是却指定了一个Real Architecture的版本。
当省略-code选项时,-arch选项指定的可以是Real Architecture的版本,此时由nvcc自行确定一个Virtual Architecture的合适版本
这一点内容详见官方文档--gpu-architecture (-arch)和--gpu-code code (-code)
Reference
- [1] NVCC与PTX
GPGPU-Sim
How to run
- Use the command
lddto make sure the application's executable file is dynamically linked to CUDA runtime library - Copy the contents of configs/QuadroFX5800/ or configs/GTX480/ to your application's working directory.
These files configure the microarchitecture models to resemble the respective GPGPU architectures.
- Run a CUDA application on the simulator
source setup_environment <build_type>
Source code organization structure
Gpgpu-sim的源码位于gpgpu-sim_distribution/src/gpgpu-sim。
目前,我们主要关注其中和配置相关的内容,我们通过修改gpgpu-simi的源码(增加一个配置项),重新编译并用其执行程序来简单理解gpgpu-sim对于配置项的设置方式。
- 修改
gpu-sim.cc:gpgpu_sim_config::reg_options(),在其中添加一个配置项
option_parser_register(opp, "-magic_number", OPT_INT32, &magic_number_opt, "A dummy magic number", "0");
- 修改
gpu-sim.h,在配置项对应结构体中添加对应字段
int magic_number_opt;
- 重新编译gpgpu-sim项目
- 将编译后生成的
gpgpusim.config拷贝到待执行cuda程序路径下 - 修改待执行cuda程序路径下的
gpgpusim.config配置文件,添加配置项
-magic_number 25
- 执行cuda程序,在输出信息中就可以看到新增的配置项
-magic_number 25 # A dummy magic number
如何使用CUDA加速程序
目前理解到的CUDA加速程序的两个关键问题是:
- 任务并行化
寻找到任务中可以并行完成的部分,制定某种策略将任务合理分配到每个线程中。此过程期望解决的是计算瓶颈(cpu-bound)问题。
1.1 udacity的视频主要讲解的就是这部分
1.2 小彭课程第6讲也是这部分
主要就是讲解一些并行原语
- 访存优化
此过程期望解决的是内存瓶颈(memory-bound)问题。
2.1 gpu的存储模型(《大众高性能》)
2.2 小彭课程第7讲
Reference
附加内容:
- If want to use ptxplus (native ISA) change the following options in the configuration file
-gpgpu_ptx_use_cuobjdump 1
-gpgpu_ptx_convert_to_ptxplus 1
- If want to use GPUWatch change the following options in the configuration file
-power_simulation_enabled 1 (1=Enabled, 0=Not enabled)
-gpuwattch_xml_file.xml
CUDA Related Documents
Reference
- [1] CUDA C++ Programming Guide
- [2] Does NVCC include header files automatically?
- [3] 网格跨步
- [4] CUDA Runtime API Documentation (Please note the version of coda)
- [5] CUDA编程方法论-知乎专栏
- [6] CUDA Crash Course - Youtube


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理