The following pseudo code can explain the git data model clearly.
Firstly, we will talk about the three models in git.
// a file is a set of datatype blob = array<byte>
// a directory which concludes files and directoriestype tree = map<string, tree | blob>
// every commit concludes a parent, metadata and top treetype commit = struct {
parent: array<commit>
author: string
message: string
snapshot: tree
}
How should we understand the bolb, tree and commit?
I will introduce this tutorial from a macro perspective.
The experiment process is diveded into three parts.
Introduces the concept of blob
1.1 Use the command git-hash-object to understand the object id of blob
1.2 Use the process of editing the test.txt to understand the version control preliminarily
Create test.txt, then write some content (such as "version 1") to it and last create a object id for it
Edit the content of test.txt (such as the content becomes to "version 2") and create a new object id for it
Delete the original file test.txt, you will find you can use the content id to restore the content of test.txt
Introduce the concept of tree
2.1 Add the test.txt (the content is "version 1") to index (staging area)
2.2 Create a object id for current staging area
2.3 Create a new file named new.txt
2.4 Add the test.txt (the content is "version 2") and new.txt to index
2.5 Create a object id for current staging area
2.6 Add the first object of staging area to the second object of staging area
Learn about the concept of commit
3.1 Commit the first tree
3.2 Commit the second tree and specify the parent commit is the first commit
3.3 Commit the third tree and specify the parent commit is the second commit
The commands which are used in experiment are placed in the commends at the end of the text
After the experiment, we will have a deeper understanding of these three data models.
A premise is that git need to complete the requirements of version control.
At an abstract level, blob、tree and commit are three data models in git.
At an physical level, Blob、tree and commit are a ordinary binary file that saves the content and other information of file or directory. The uniqueness of them lies in the name, they were named by the hash value of the content and other information, which is calld object id of the file.
In order to get a depper understanding of these statements, we need to pay attention to the actual physical file of these models.
When we create a blob for a file, we will find that a new file shows up in the .git/objects. Although we delete the original file, we can use blob to restore it. In other words, the blob save the content of the file.
Creating a tree concludes two parts, the first one is to put some files or directories into staging area, after this operation, we will find a new file named index shows up in the .git. The second one is to create a tree for staging area, we will find a new file shows up in the .git/objects, its format is same as a blob.
When we create a commit for a tree (a commit can only be created for a tree), we will find a new file shows up in the .git/objects
Let us comb the logical relationship of blob、tree and commit.
A blob can save the content of file, but it can't save the filename and catalog relationship. So git introdces the tree, it can save the filename and catalog relationship. But tree can't save other information such as commitor and commit time and we can't understand the meaning of hash value (such who did what), so git introduces the commit, bases on the tree and add other useful information.
Secondly, let us see the concept of object in git.
// a object in git may be a blob(file), tree(directory) or commit(or snapshot, a state at a certain moment)
type object = blob | tree | commit
// git maintenances a big dictionary, which uses a string as a key to index an object
objects = map<string, object>
// how does git store an objectdef store(object):
id = sha1(object)
objects[id] = object// how does git load an objectdef load(id):
return objects[id]
Although commit have some useful information, which can help people understand these commits, but we can only find a commit by its long and meaningless hash value string now. So git introduces the reference, it contains two parts of file. The first one is the .git/HEAD and the second one is the .git/refs/xxx. Simply speaking, reference is just a short and meaningful string and it refer to a commit. People can use this string to find a commit.
The so-called branch is a synonym for a reference. The difficulty is that top level of operation for branch is different from bottom level of operation. If you don't want to confuse the understand, please remember that a reference is just a pointer, it uses a short string to simplify the long hash value string, although at top level, we always say commit current changes at this branch, a branch (reference) is not a real way.
If you have feeled puzzle about the relationship between different branches, a good way to comb them is that you can ignore the existed branches, what you are facing is only the current working directory. Actually, when we say that create a new branch and git commit at one branch, it means we create a new reference and a commit, then make the reference point to this commit and keep the original reference unchanged.
Thirdly, let us see the concept of reference in git.
// git uses a long and meaningless string to index an object, which is difficult for human to memorise.
// So it introduces a new concept, reference. A reference is a simple and custom string, which can substitude the hash string.
references = map<string, string>
defupdate_reference(name, id):
references[name] = iddefread_reference(name):
return references[name]
defload_reference(name_or_id):
if name_or_id in references:
return load(references[name_or_id])
else:
return load(name_or_id)
To insure current working stage, git introduces a HEAD, which can point to a reference (branch) or a commit. When the HEAD doesn't point to a reference, it is called 'detached HEAD' state.
When you use top level command git checkout, you will edit the HEAD, the .git/HEAD file. When you use top level command git branch, you will edit the branch/reference, the .git/refs/heads file.
staging area
暂存区目前比较难理解,尤其是其内容的变化不知道是如何进行的,以及tree该如何理解
Staging area is a middle state between current state and snapshot/commit.
If you have created many modifications, and you only want to use some of them to create a snapshot. Now, using current state to create a new snapshot/commit directly is inconvenient,
Every staging area is a tree, it is like a directory, which concludes some files and/or some directories.
Tree is also a object in git, so there is a hash string of tree in .git/objects. If you use the command git cat-file -p to get the value of a tree object, you will find its content is some files and/or some directories.
Movement
HEAD movement
Using relative reference
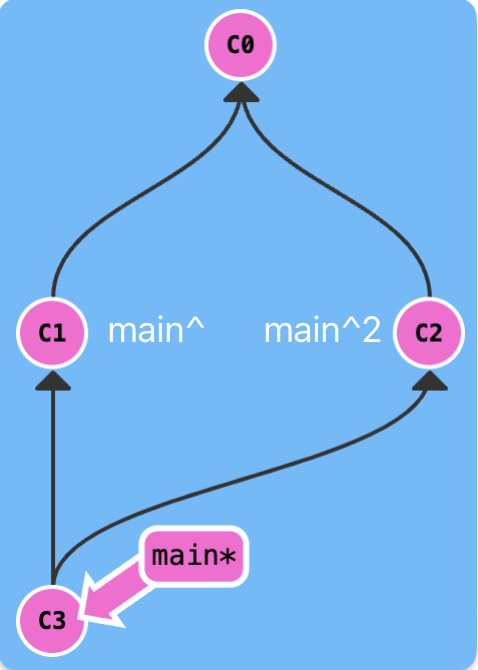
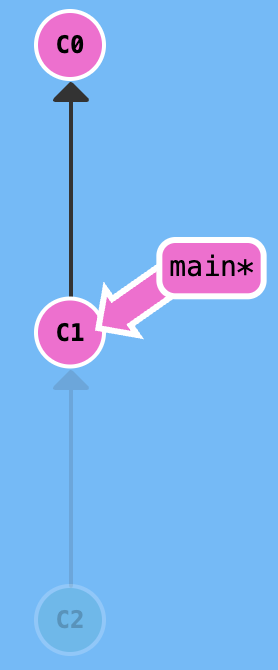
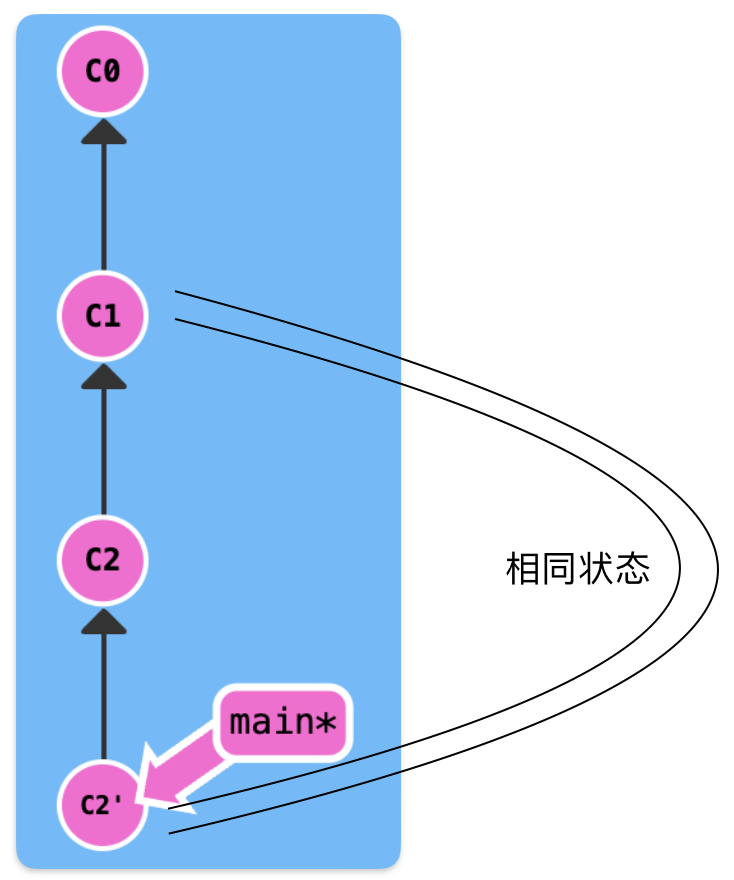
You can use ^ operator to move to a previous state, such as main^ and HEAD^. And you can use multiple operators to move to multiple previous states.
To simplify the operation of multiple states movement, you can use ~ operator. For example, HEAD~2 and HEAD^^ are equivalent.
^ + <number> isn't similar with ~ + <number>, its usage is shown in the following figure.
Branch/Commit movement
Merge branches
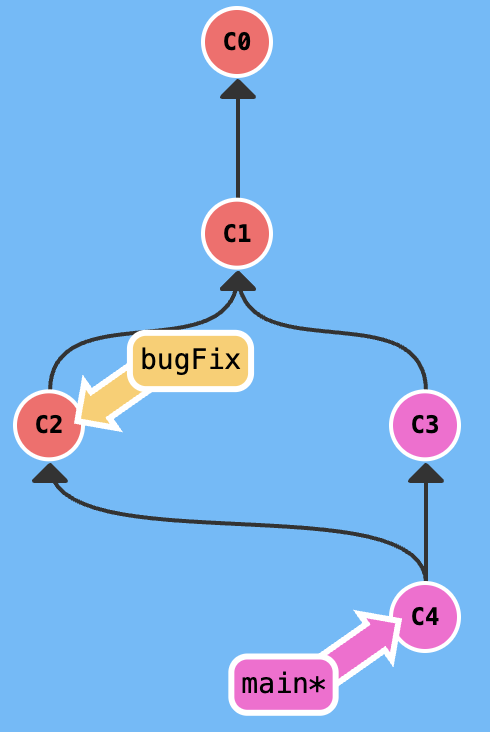
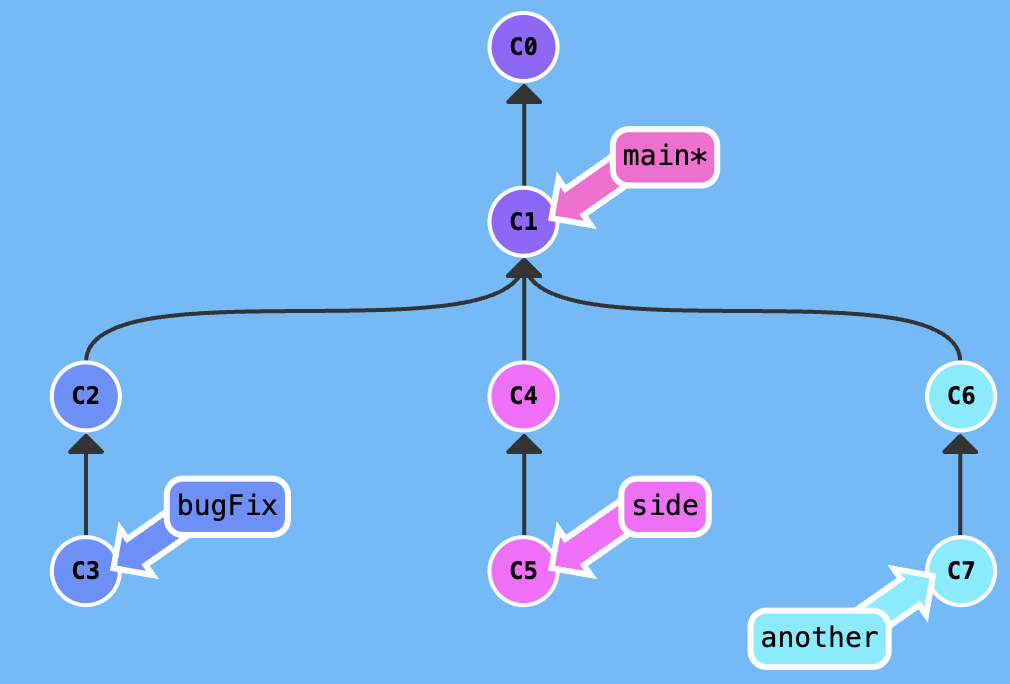
The begining state is shown in the following figure:
git merge xxx
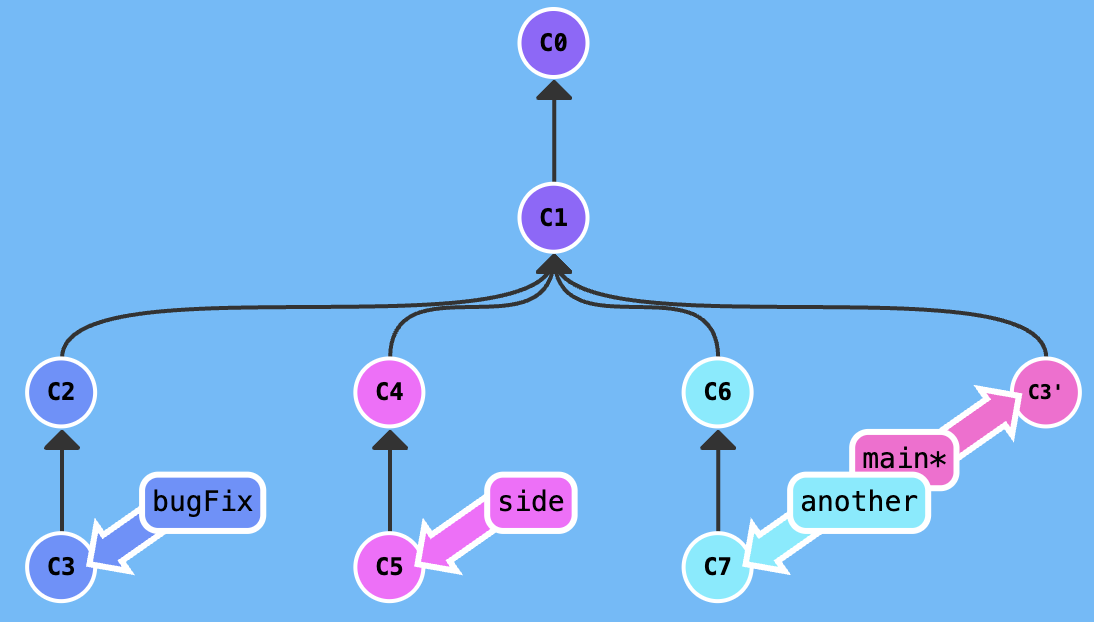
Assuming current branch is main, you want merge bugFix branch into main, you can excute git merge bugFix, the result is shown in the following figure.
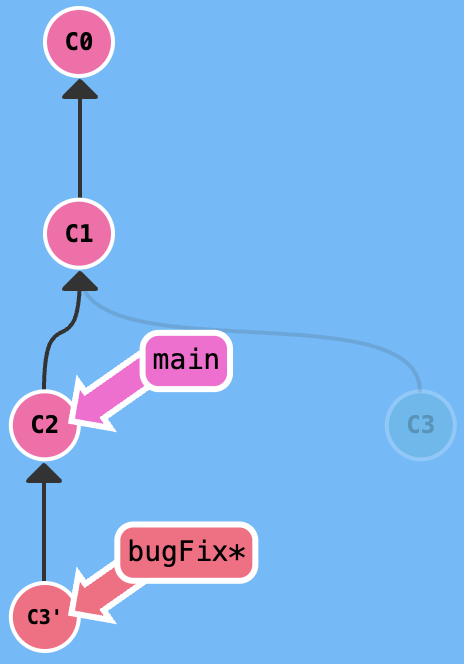
git rebase xxx
Assuming current branch is bugFix, you want merge bugFix branch and main and you want keep just one record line of commit, you can excute git rebase main, the result is shown in the following figure.
git rebase xxx means moving current branch to the xxx branch, git rebase yyy xxx means moving xxx branch to the yyy branch
An important and easily overlooked point is that excute an rebase command to a commit doesn't mean just move this commit to the target commit, it will find the lowest common ancestor between source branch and target branch, move the source commits below the LCA to the target branch (below the latest commit) following the original index.
If the work of using command git rebase to adjust the branch is too complex, you can use the interactive version of rebase. Just add a extra parameter -i (interactive).
Revoke changes
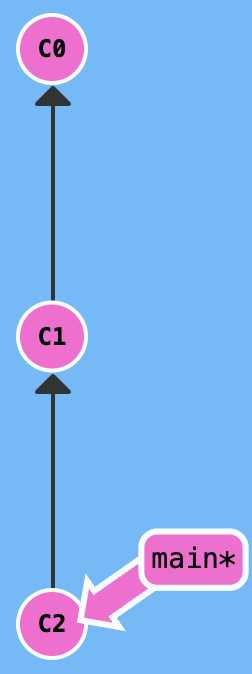
The begining state is shown in the following figure:
git reset xxx
After you excute the command git reset HEAD^, the main back to the previous commit.
What need we notice is that the c2 changes don't disappear, these changes just don't add to staging area.
git revert xxx
If we are editing a remote branch which need to be shared with other people, we need to use this command.
After we excute the command git revert HEAD
The difference between the two commands is that the latter command create a new commit, which can be push to the remote, so that other people can see the change.
Move the specify commit
git cherry-pick commit...
In software development, the term cherry-pick is used to describe the action of choosing specific commits from one branch and applying them to current branch. It is derived from the analogy of a tree with branches that have many cherries (commits).
The begining state is shown in the following figure
Now we are in the main branch, after we excute the command git cherry-pick bugFix, the bugFix branch will be applied into current main branch. The result is shown in the following figure.
If you select multiple commits when you use this command, it will pick the commit one by one, its role is similar with git rebose -i
Realistic scenarios
select a specific historical commit to commit
The scenario is that you just want to select the bugFix branch to merge with main and to commit.
You can switch to the main branch, then use the git cherry-pick bugFix to select the bugFix branch. The result is shown in the following figure.
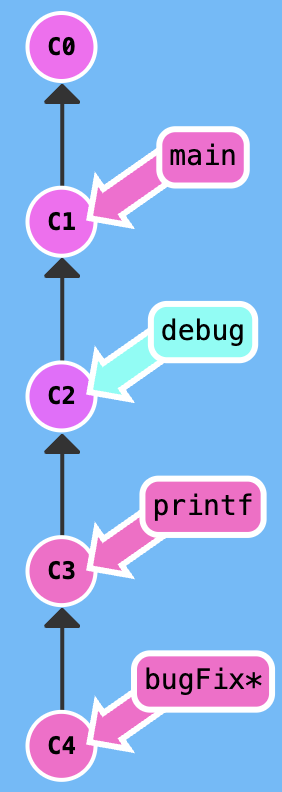
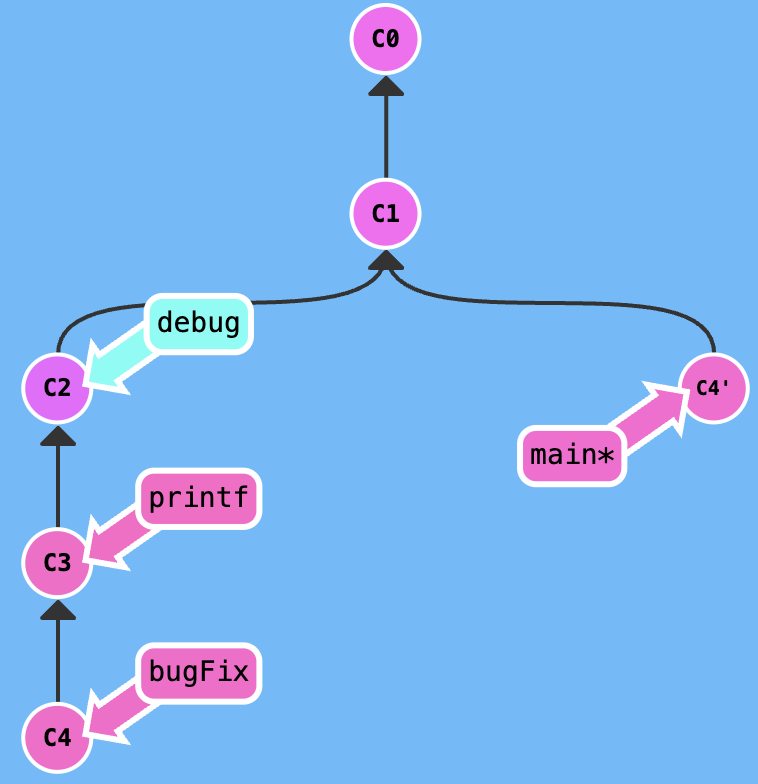
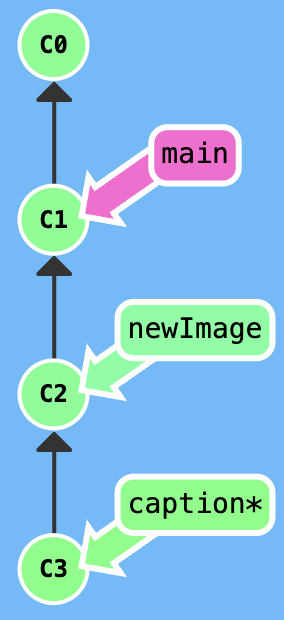
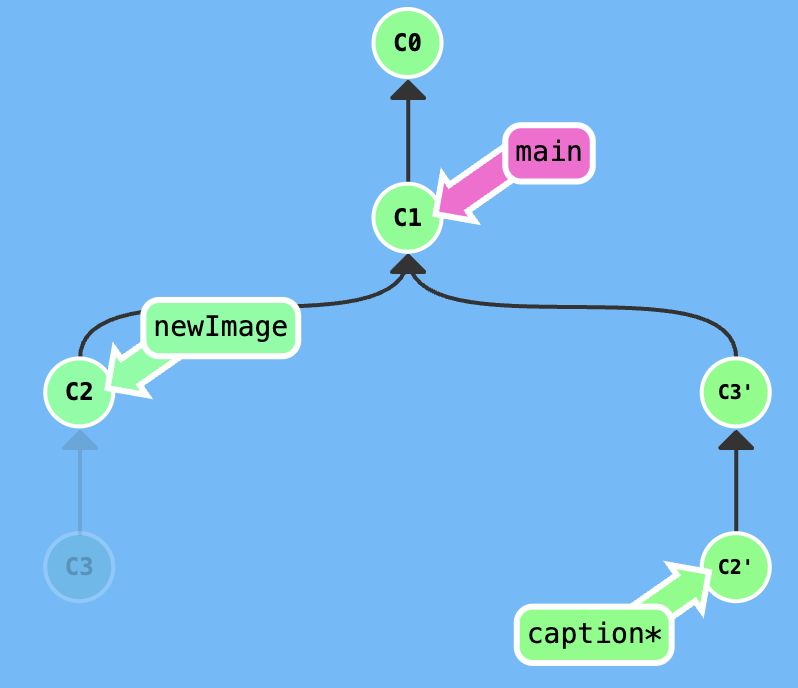
edit the previous commit
Note: I still don't know the way of datas change, when we use the git rebase -i to edit many commit.
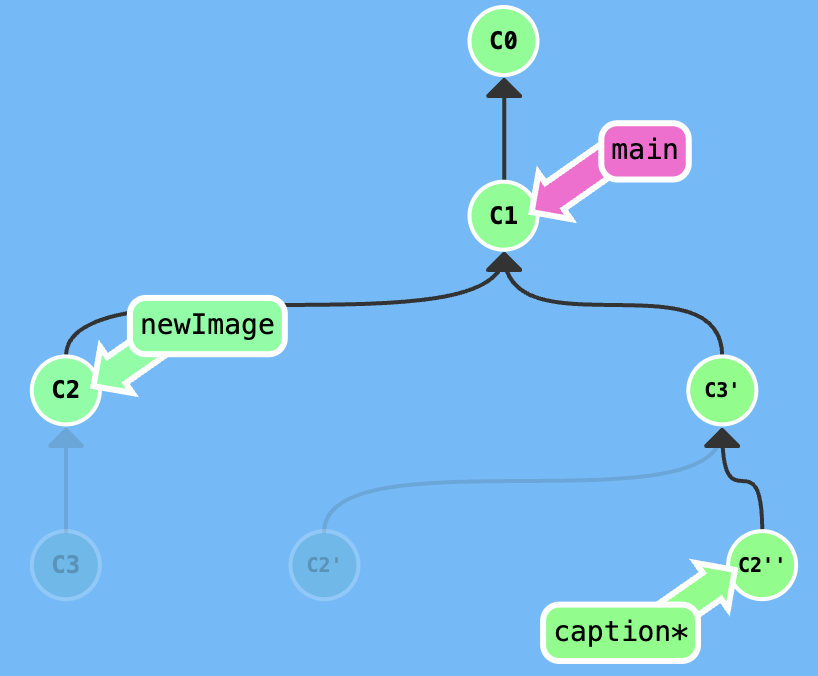
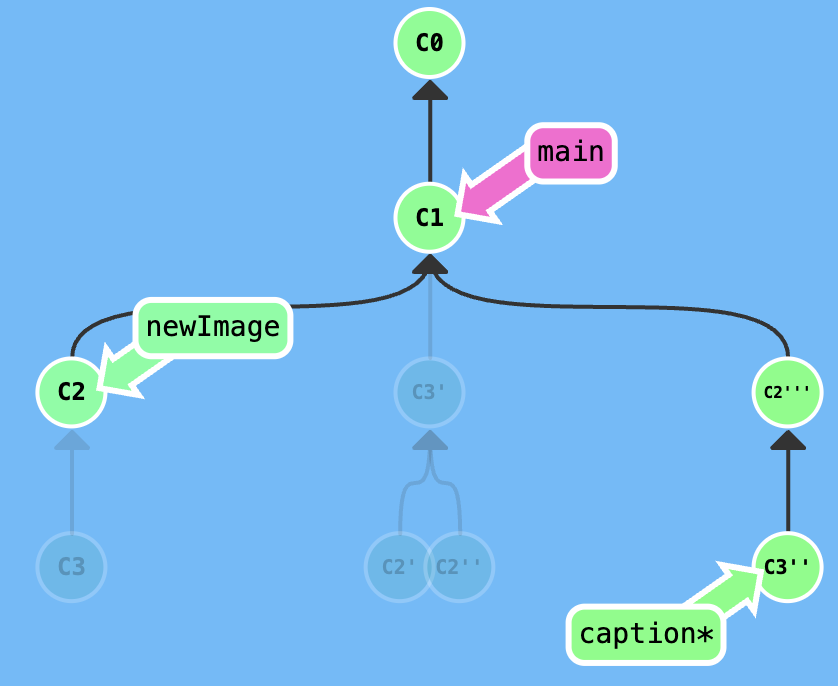
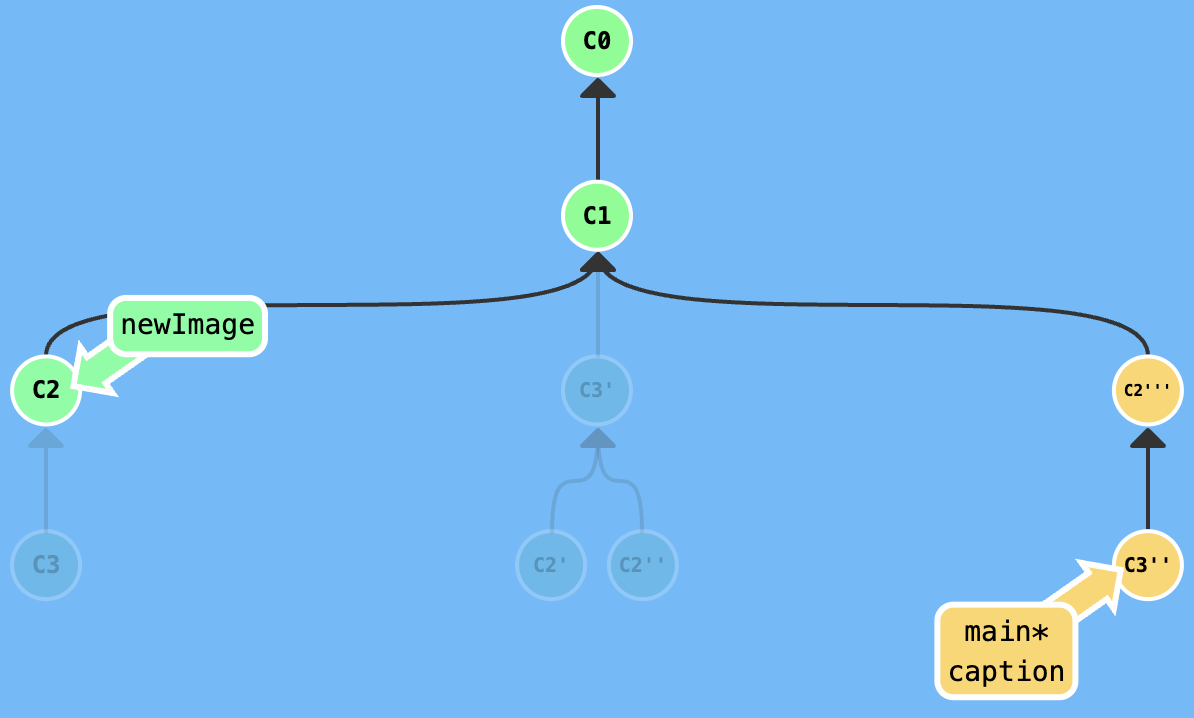
Your task is that edit the newImage commit.
Firstly, excute git rebase -i HEAD~2, adjust the index of rebasing, get a result that is shown in the following figure.
Secondly, edit in the newImage branch, then excute git commit --amend.
Thirdly, excute git rebase -i HEAD~2, adjust the index of rebasing.
At last, switch to main branch and excute git rebase caption to move the main to the caption.
You can also use the git cherry-pick to solve this problem
Tag
git tag <tag_name> <commit>: create a tag named tag_name at specify commit
Remote warehouse
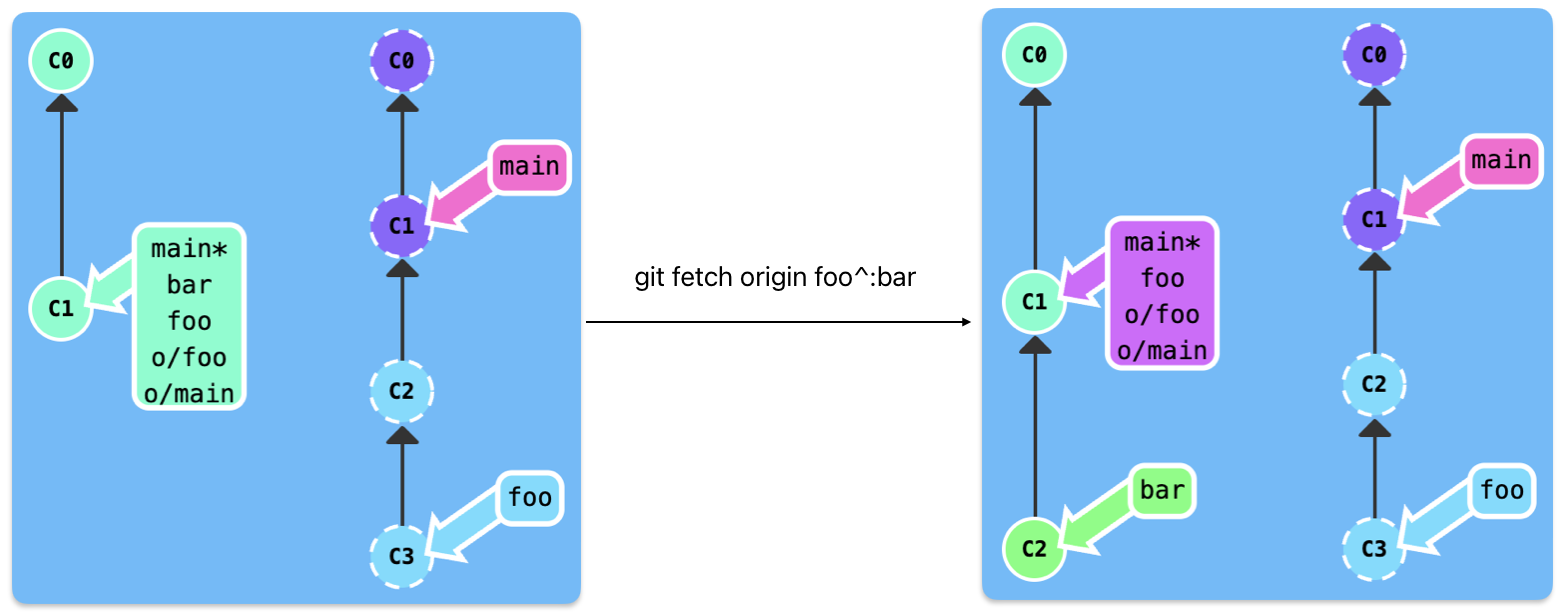
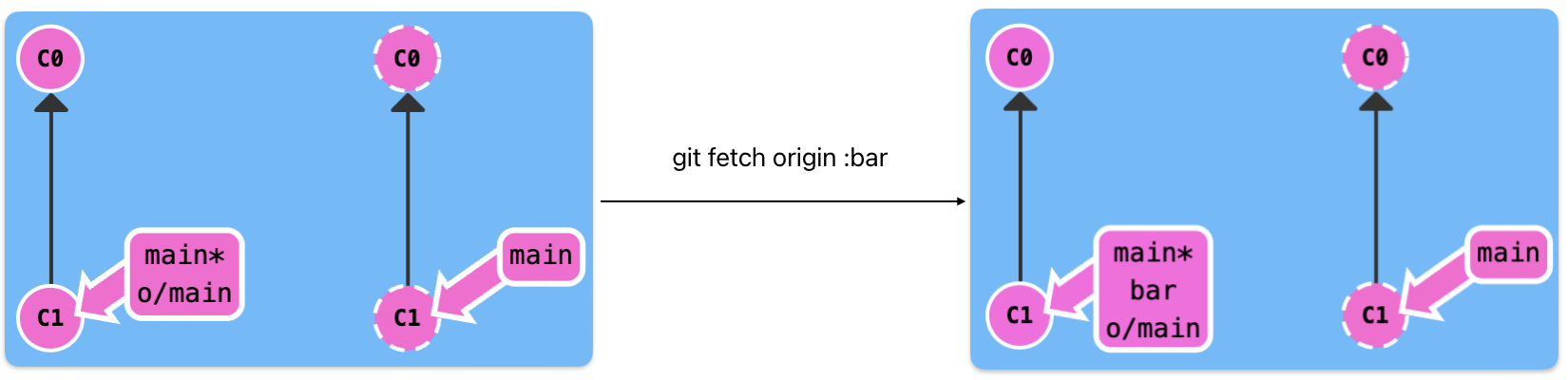
git fetch
download commit records which don't exist in local from remote
update the remote reference
git fetch is equivalent to download data from remote, it doesn't edit the local date such as local reference
Parameters for the git-fetch
参数
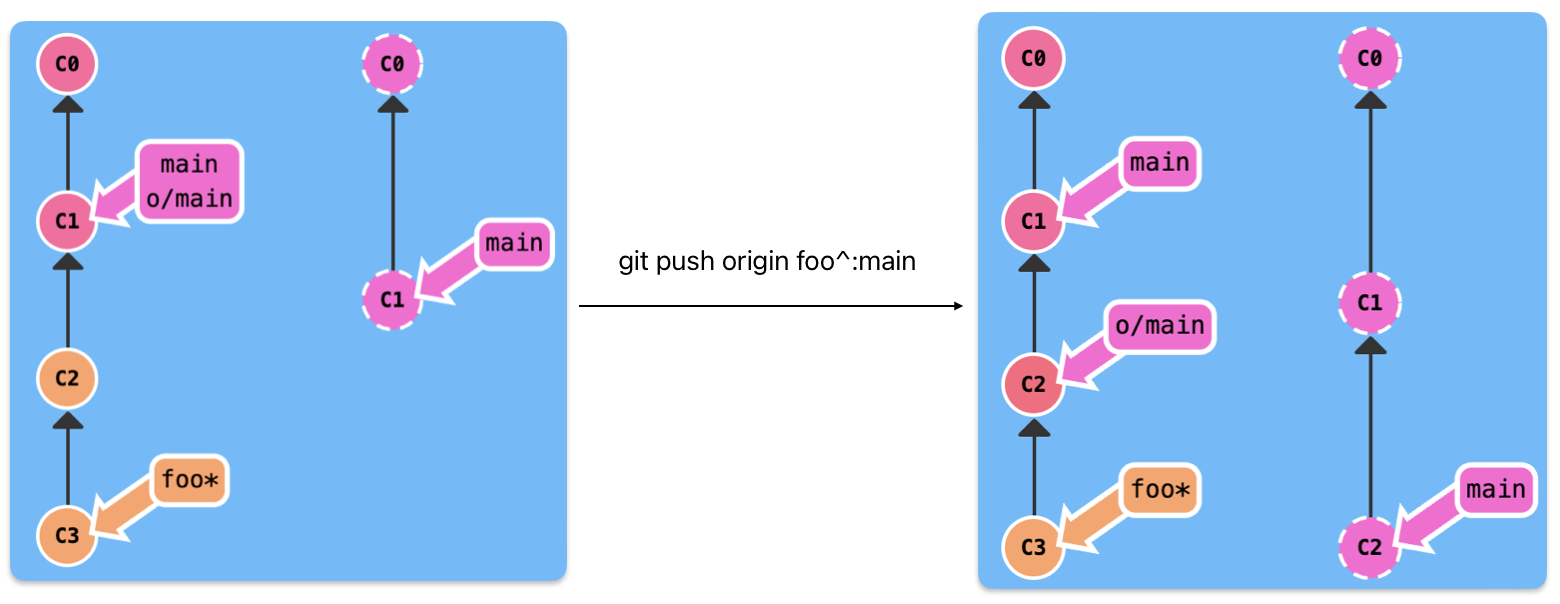
git fetch origin foo: download the data from remote foo branch
:参数
download the remote source branch to the local destination branch, for example
If the source is null, the command will create a new local destination branch
git pull
Because git fetch just download the remote data, we need edit the local data manually. So git pull will complete two works of download remote data and merge the remote and local reference.
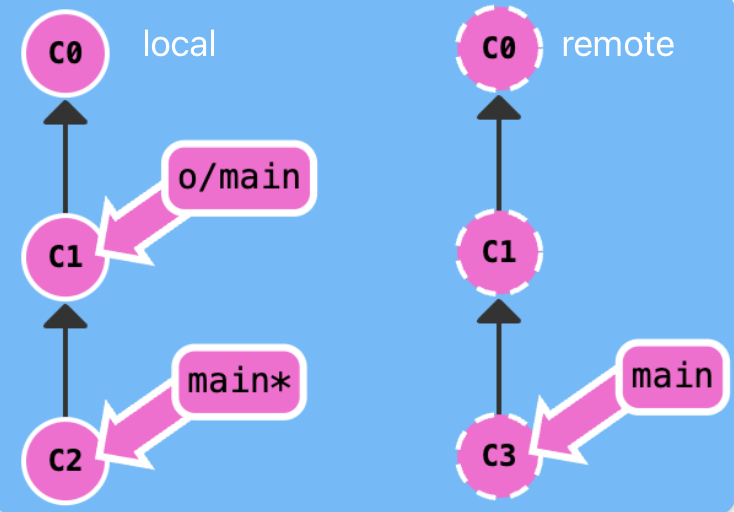
The local and remote structure is shown in the following figure.
After we excute the command git fetch, the remote reference go ahead one step.
Then we excute the command git merge o/main.
If we excute git pull, we can get the same result. All in all, git pull = git fetch + git merge
git push
git pull --rebase = git fetch + git rebase
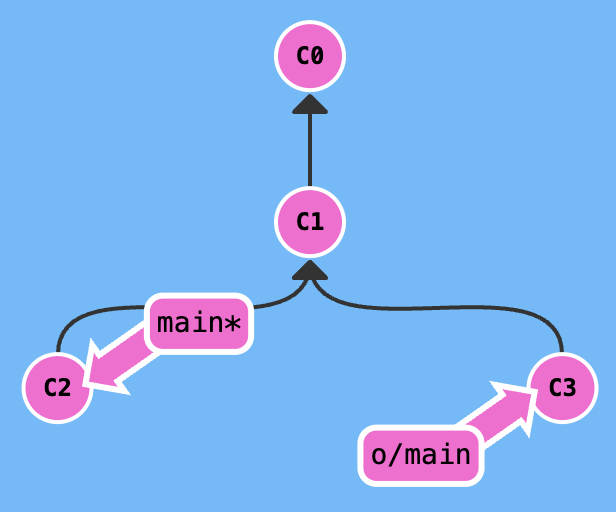
Before push the local commit, maybe we need to handle some special situations.
c3 bases on c1, but remote branch has gone to the c2, so direct git push operation fails.
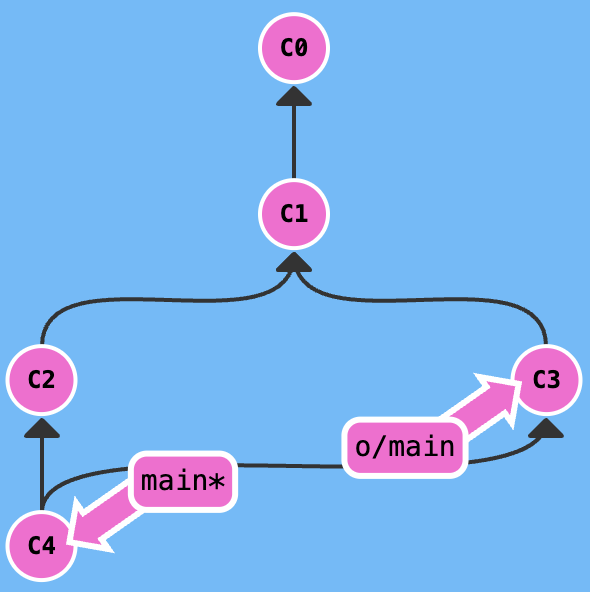
We need git fetch to gain the remote warehouse data, then merge the data, at last push the data to the remote.
And we can also use the git merge to substitute the git rebase
Parameters for the git-push
git push <remote> <place>
After setting up the mapping, you can use origin as the remote directly. Place means the source of data for commit to the remote warehouse.
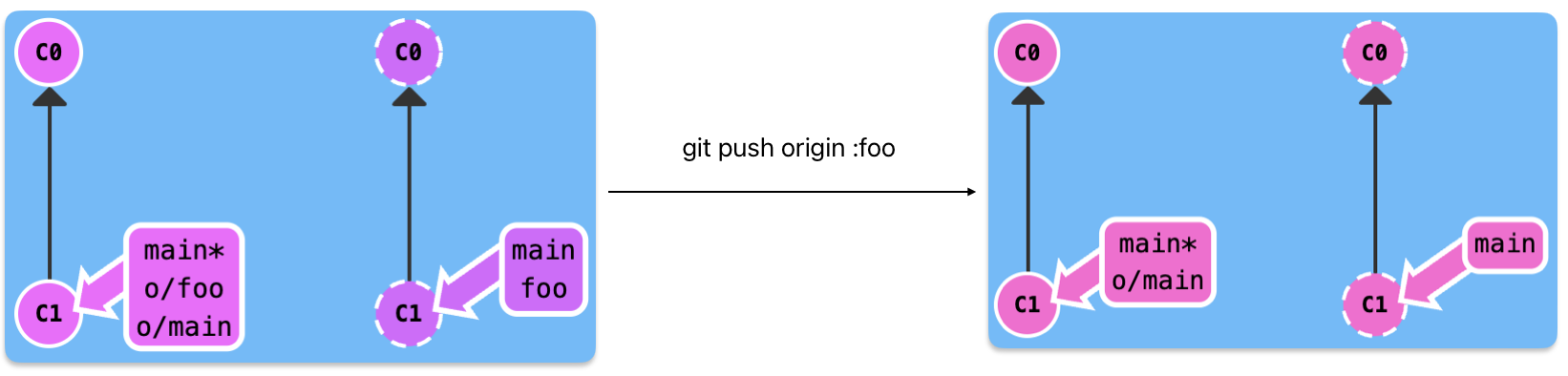
git push origin :
When we set the mapping relationship between source and destination at origin, we can use the command git push origin source directly, but if we don't set it, we need give this information for git.
If the source is null, the command will delete the remote destination branch
Remote tracking
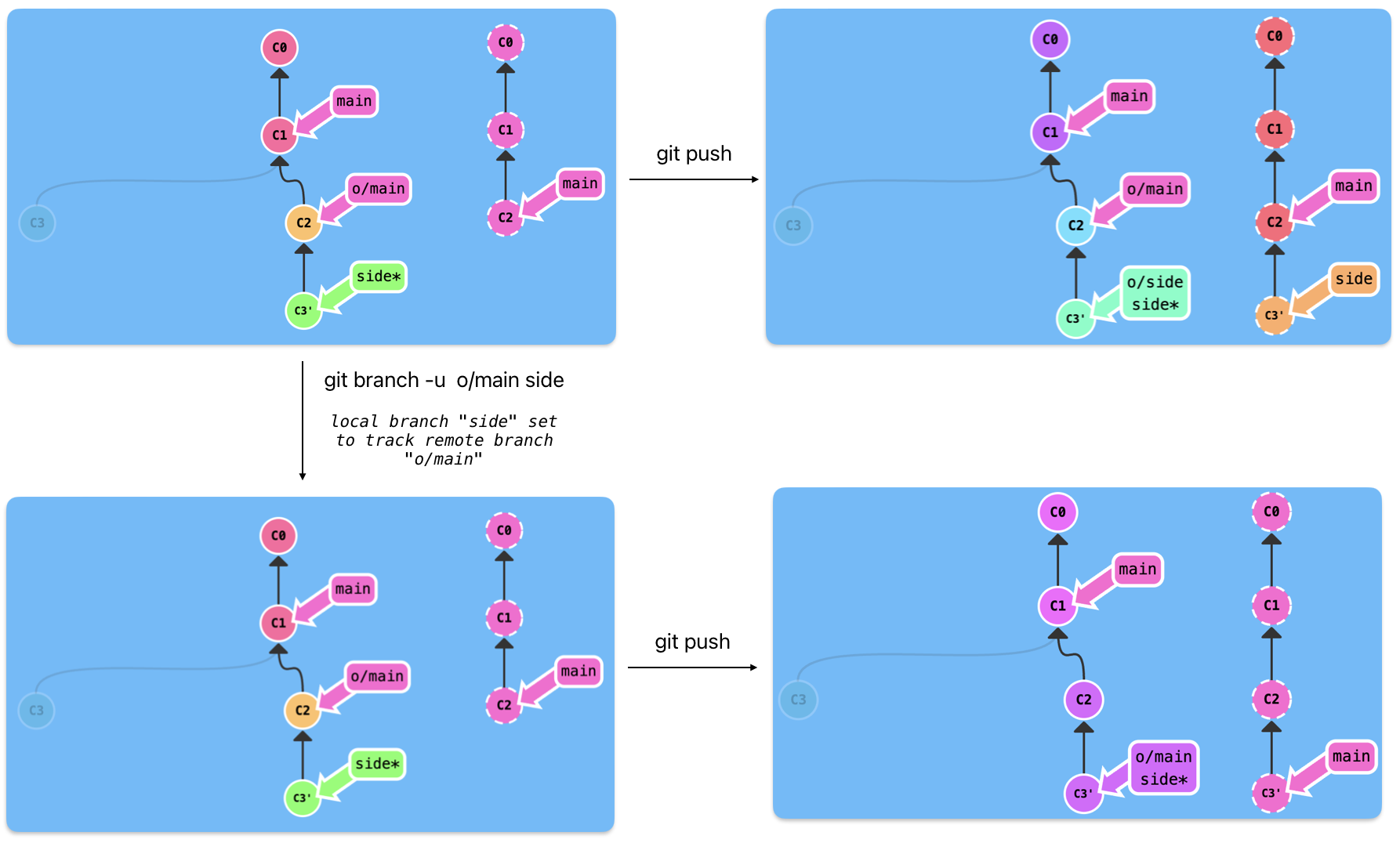
The remote tracking means that you can specify a branch to track a remote branch.
Think about it, why when we commit an main branch, it will commit to the main branch in remote warehouse. The reason is that the local main branch maps to the original main branch.
You can use git branch -u original/main side to set the side branch to track the remote main branch, after it, you can git push directly at side branch. The result of changing the map relationship is shown in the following figure.
—————————————————————————————————
control the ordinary file
// create hash string of object from standord input and file
git hash-object -w --stdin
git hash-object -w test.txt
// get the value of object by hash string:
git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
// judge the type of object:
git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
—————————————————————————————————
control the staging area
// index is a equivalent concept of staging area// select a file and put it into the staging area
git update-index --add test.txt
//what is the meaning of parameter cacheinfo?// Now, in the working area, you just have one file named test.txt, but this file has twe versions because of different file content, such as version 1 and version 2. // The file is version 2 now, but you only want to use version 1 to update index, so you can use the parameter cacheinfo to specify to use version 1.
git update-index --add --cacheinfo 10064483baae61804e65cc73a7201a7252750c76066a30 test.txt
// create an object id for staging area which concludes selected files and directories
git write-tree
—————————————————————————————————
// control the commit object
echo 'first commit' | git commit-tree d8329f
echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
—————————————————————————————————
// control the reference// create a new reference, the object must be a commit
git update-ref refs/heads/main <object id>
// determine which branch now
git symbolic-ref HEAD
// edit the HEAD
git symbolic-ref HEAD refs/haeds/other






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理