机器学习
Python科学计算生态系统和库
- NumPy(Numerical Python):Python科学计算的基础包
- pandas:提供了快速便捷处理结构化数据的大量数据结构和函数
- matplotlib:绘制图表和其它二维数据可视化的Python库
- SciPy:专门解决科学计算中各种标准问题域的包的集合
- scikit-learn:通用机器学习工具包
- statsmodels:统计分析包
scikit-learn子模块
- 分类:SVM、近邻、随机森林、逻辑回归等等。
- 回归:Lasso、岭回归等等。
- 聚类:k-均值、谱聚类等等。
- 降维:PCA、特征选择、矩阵分解等等。
- 选型:网格搜索、交叉验证、度量。
- 预处理:特征提取、标准化。
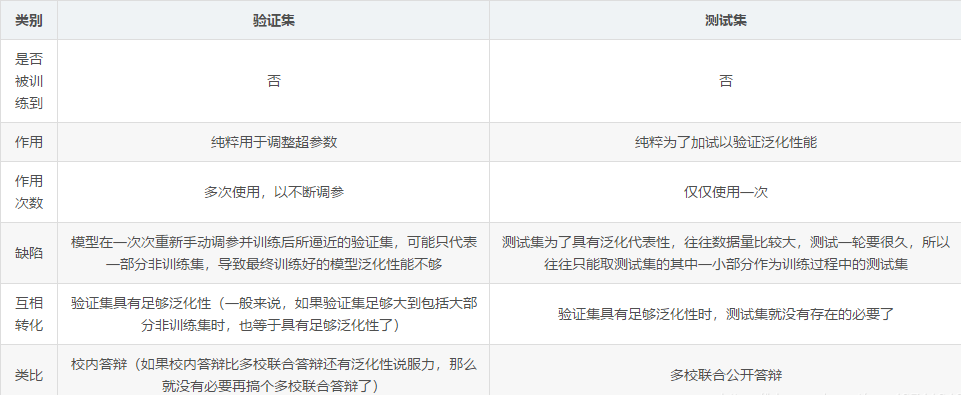
训练集和数据集关系
半监督学习
reference
分类回归问题
决策树
1.如何区分决策树分裂和决策树回归
在决策树回归中,我们仍然使用决策树来划分数据,但叶子节点的含义发生了变化。在决策树分类中,叶子节点对应着某个类别标签,而在决策树回归中,叶子节点对应着某个数值。
具体来说,每个叶子节点都表示一个数据子集的平均值或中位数,而不是一个具体的类别标签。在测试阶段,我们沿着决策树向下遍历,找到测试数据点所属的叶子节点,然后将该叶子节点对应的数值作为预测结果。
在决策树回归中,我们可以使用不同的策略来确定分裂节点,以处理连续型变量。一种常见的策略是使用最小二乘法来确定最佳分裂点。在这种方法中,我们选择一些候选分裂点,然后在每个候选分裂点上计算数据子集的方差和。我们选择方差和最小的分裂点作为最佳分裂点。
因此,与决策树分类相比,决策树回归需要修改叶子节点的含义,并使用不同的策略来处理连续型变量,以适应回归问题的特点。
2.分类问题是根据什么策略来确定分裂节点的
在决策树分类中,通常使用信息增益(information gain)或基尼不纯度(Gini impurity)来确定分裂节点。
信息增益是指在选择某个特征进行分裂时,信息熵的减少量,即父节点的信息熵减去子节点的信息熵之和。信息熵可以用来度量数据集的不确定性,当某个特征的信息增益较大时,说明使用该特征来划分数据可以显著地减少数据的不确定性,因此是一个好的分裂点。
基尼不纯度是指随机选取一个样本,它被分错的概率。因此,基尼不纯度越小,说明使用该特征来划分数据可以更好地区分不同类别的数据。
在实践中,信息增益和基尼不纯度通常是等效的,因此可以根据具体的数据和问题选择其中的一种作为分裂节点的判断标准。
3.回归问题是根据什么策略确定分裂节点的
在决策树回归中,通常使用平方误差(mean squared error,MSE)或平均绝对误差(mean absolute error,MAE)来确定分裂节点。
平方误差是指预测值与实际值之间差值的平方,即
MSE = 1/n * Σ(y - y_hat)^2
其中,n表示样本数量,y表示实际值,y_hat表示预测值。当某个特征的平方误差较小时,说明使用该特征来划分数据可以更好地拟合数据。
平均绝对误差是指预测值与实际值之间差值的绝对值的平均值,即
MAE = 1/n * Σ|y - y_hat|
当某个特征的平均绝对误差较小时,说明使用该特征来划分数据可以更好地拟合数据。
类似地,在实践中,平方误差和平均绝对误差通常是等效的,因此可以根据具体的数据和问题选择其中的一种作为分裂节点的判断标准。
reference


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理