深度学习
参考
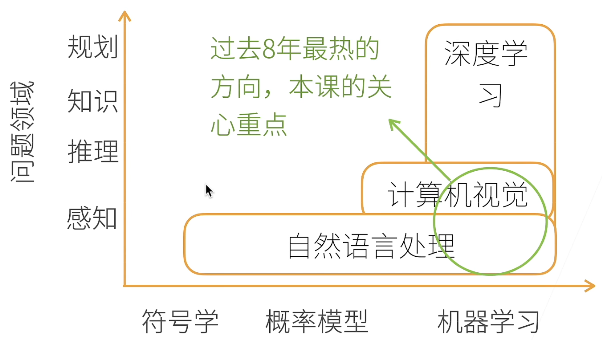
深度学习介绍

人工智能:通过软件和硬件来「模拟」和「模仿」智能人类行为的研究
机器学习:计算机识别数据模式并根据数据模式采取行动
深度学习:机器学习的子领域,是人工神经网络的另一个名字。深度学习网络模仿人类大脑感知与组织的方式,根据数据输入做出决策
环境配置
1.安装CUDA
2.安装anaconda或miniconda
3.安装GPU版Pytorch
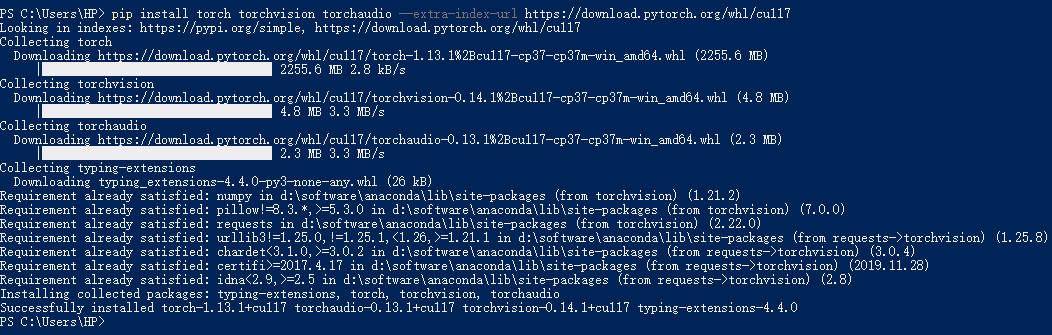
4.安装d2l和Jupyter
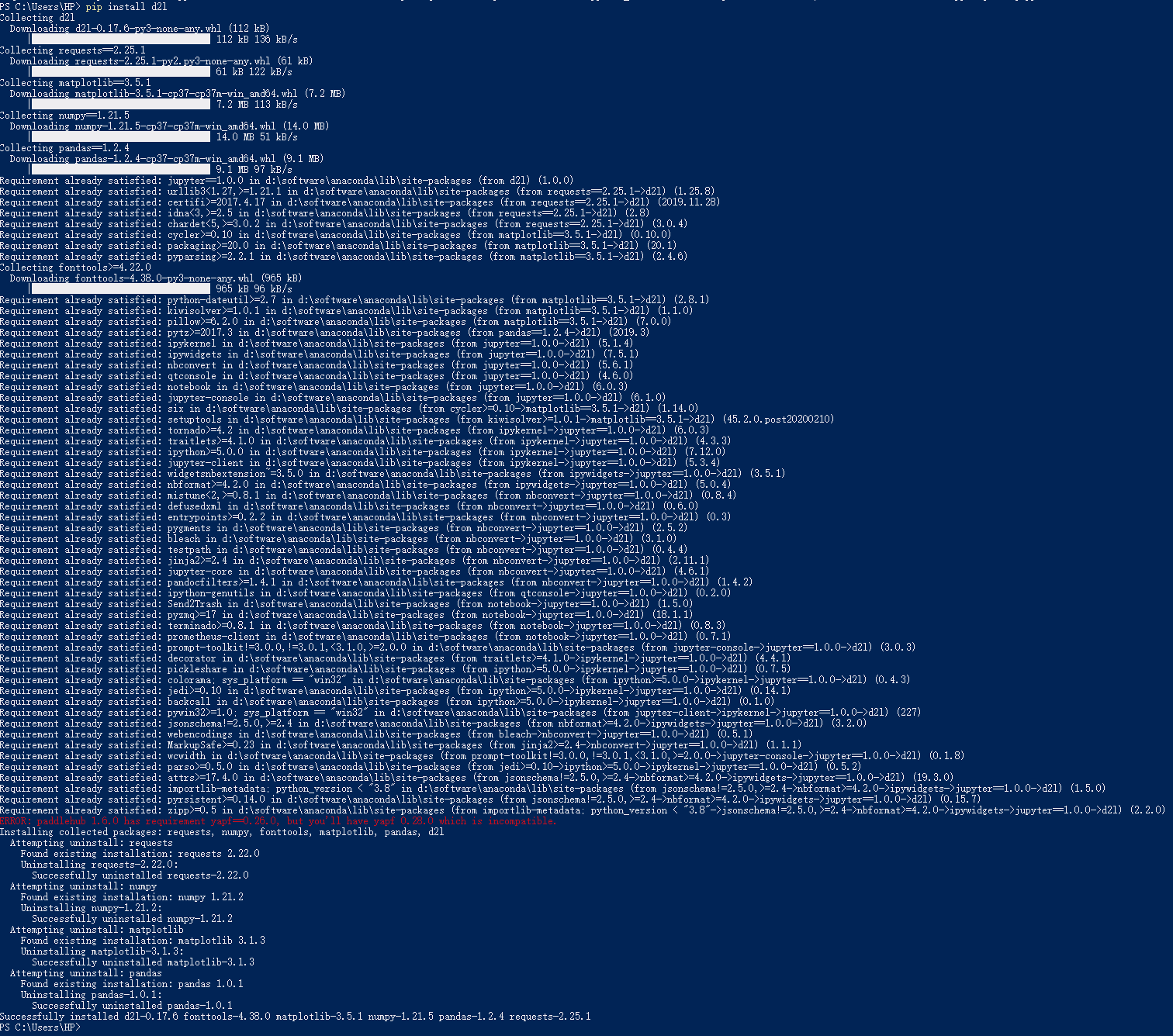
注: 第3步中如果安装anaconda,则Jupyter会附加安装
问题
- 控制台输入
python跳转至 Microsoft Store
解决方法:Windows设置 --> 应用 --> 应用和功能 --> 应用执行别名 --> 关闭应用安装程序(python.exe, python3.exe)
线性代数
数据类型
标量->向量->矩阵->张量
标量
- 标量由只有一个元素的张量表示,例如
tensor(5)
向量
- 向量可以被视为标量值组成的列表,例如
tensor([0, 1, 2, 3]) - 向量通常记为粗体、小写的符号(例如x, y, z)
- 向量的长度/向量中元素数量通常称为向量的维度
矩阵
- 矩阵是向量从一阶推广到二阶的结果,在代码中表示为具有两个轴的张量,例如
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
- 通常用粗体、大写字母来表示(例如X,Y,Z)
张量
- 描述具有任意数量轴的𝑛维数组的通用方法,并未要求一定要3阶。例如,向量是一阶张量,矩阵是二阶张量。
- 张量的维度表示张量具有的轴数。 在这个意义上,张量的某个轴的维数就是这个轴的长度
注意维度一概念对于向量和张量的不同解释
“乘法”
- Hadamard积,对应元素相乘,
A * B - 向量点积,相同位置的按元素乘积的和,
torch.dot(x, y) - 矩阵-向量乘法,
torch.mv(A, x) - 矩阵-矩阵乘法,
torch.mm(A, B)
注意区分 Hadamard积 和 矩阵乘法
降维
如何理解指定张量沿哪一个轴来通过
tensor.sum()方法求和降低维度这一功能的实际表现
在第一次看到这个方法时,令人费解的是axis这一参数该如何理解。
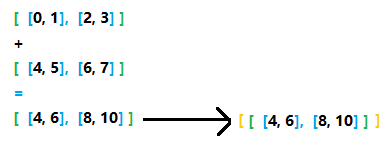
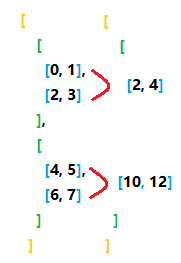
为了方便论述,取一个三维的张量
X = torch.arange(8).reshape(2, 2, 2)
> [
[
[0, 1],
[2, 3]
],
[
[4, 5],
[6, 7]
]
]

单轴降维
如果把一对括号括起来的部分看为一个集合,集合内元素个数就是所谓的各个维度对应的数值,上图中橙色的2表示最外层的括号内部有2个元素,绿色和蓝色的含义与此相同,所以说当axis指定0时,意思就是看外层的黄色括号,把内部的两个元素进行求和,此时如果keepdims = False也就意味着要将最外层的这一维度去掉,即下图所示

如果keepdims = True,那么将保留最外层的这一维度,即下图所示
当axis指定1时,意思就是看中间的绿色括号,把内部的2个元素进行求和,当keepdims = False时,即下图所示,

如果keepdims = True,那么将保留中间层的这一维度,即下图所示
多轴降维
核心问题是:当指定axis=(0,1)时,1是原张量的第1维度还是先对原张量的第0维度进行降维后的新张量的第1维度
验证方法很简单,只需要对比原张量按照axis=(0, 1)进行降维的结果和先对原张量的第0维进行降维,再分别对新张量的第0维和第1维降维的结果
// 原张量 X = torch.arange(8).reshape(2, 2, 2)
[
[
[0, 1],
[2, 3]
],
[
[4, 5],
[6, 7]
]
]
// 对第0维和第1维进行求和降维 X.sum(axis = (0, 1), keepdims = False)
[12, 16]
// 对第0维进行求和降维
[
[ 4, 6],
[ 8, 10]
]
// 对上方结果对第0维(原张量的第1维)进行求和降维
[12, 16]
// 对上方结果对第1维(原张量的第2维)进行求和降维
[10, 18]
结论:从上方结果可以看出,当指定axis = (0, 1)时,0和1是针对原张量而言的,如果一定要分开来说,就是先对原张量第0维进行降维,再对降维结果的第0维(原张量的第1维)进行降维
矩阵计算-向量求导
国内外关于凹凸函数的定义略有不同,同济大学高等数学教材对函数的凹凸性定义为函数的下方图是凹集或凸集,国外的凹凸性是指函数的上方图是凹集或凸集
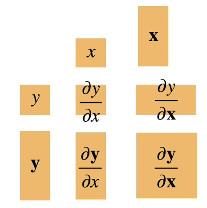
标量对向量求导
求导方法
对于多元函数
对, , 的偏导分别为
标量对向量求导的本质就是标量中的每个部分分别对向量中的每个元素逐个求偏导,并将结果写成向量、矩阵的形式
示例
根据沐神的讲解,标量y表示为一个等高线,而标量y对向量X求导后的结果在代入某一点时表示一个梯度,是和等高线在该点是正交的,梯度指向值变化最大的方向
其他示例如下图所示
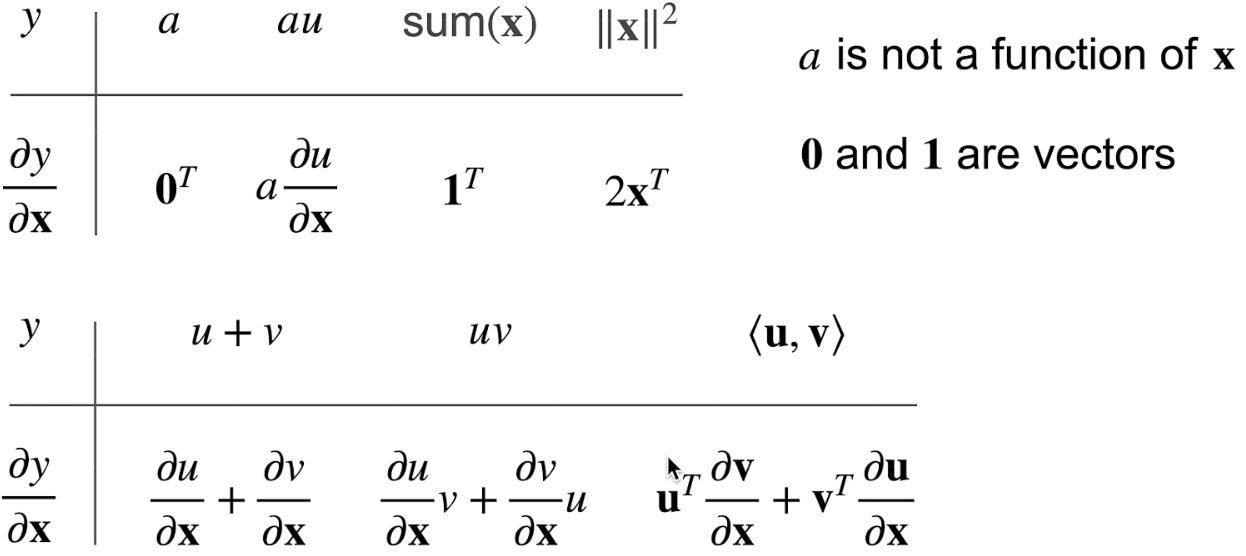
向量对标量求导
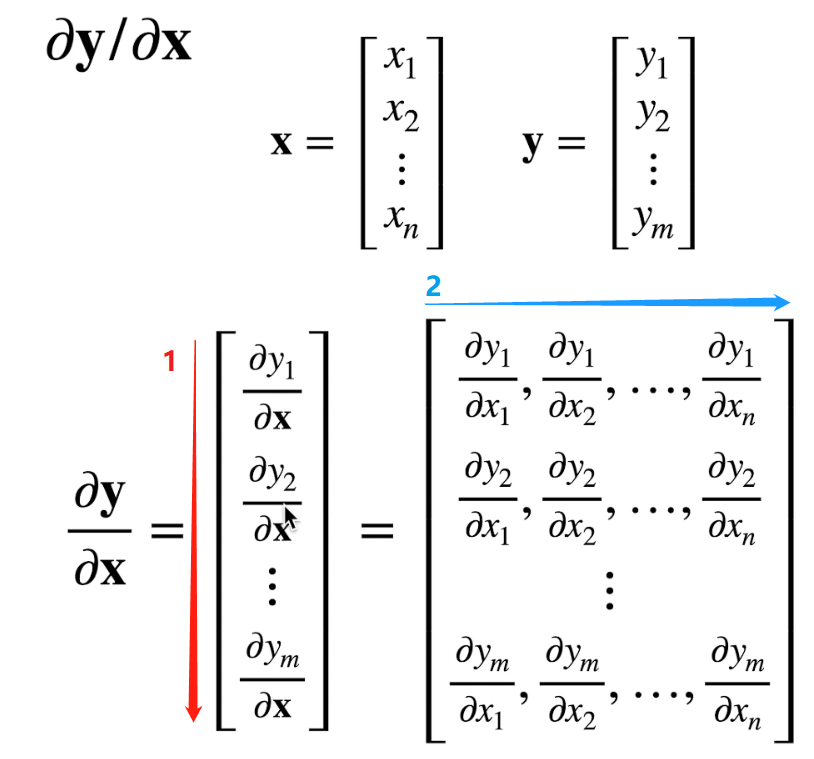
向量对向量求导
根据下图求导时的展开规则,求导后矩阵行数同的行数,列数同的行数
计算图
- 将代码分解为操作子
- 将求导计算表示为一个无环图
自动求导是基于链式法则,但有2种计算模式:1.正向累积 2.反向累积(反向传递)
正向是求复合函数的值,反向是计算偏导数和梯度
线性回归模型
为了便于描述,规定场景为房价预测,即根据房屋面积和房龄预测房屋价格
四要素
Model
Parameters
Cost Function
Objective
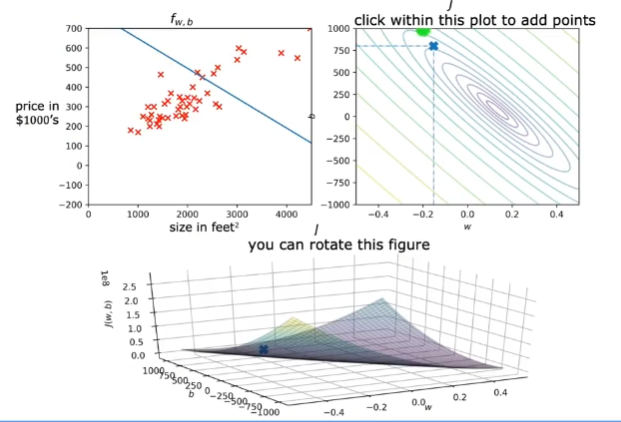
左上是model的图像,剩余两个都是代价函数,对于下方图像,很多垂直于j轴方向的平面与代价函数图像相交后会形成很多线,这些线汇聚在一起就是右上的图像
目标就是最小化代价函数
模型
在房价预测问题中,model为
采用线代代数的表示方式,对于一个样本而言,将权重置于向量中,即。将特征置于向量中,即。因此根据向量乘法可得model为
多个样本与单一样本的区别在于特征值由一组变为多组,即多个,将他们以行向量的形式置于一个大的矩阵,可得,它的每一行是一个样本,此时model为
代价函数
直观理解就是模型值和实际值的差距
梯度下降
起初一个令人疑惑的问题是梯度下降使用的等高线是哪里来的,
在线性回归模型中,model的图像是一个三维空间,当指定x和y值时,对应一个高度,该高度值为model的值,这一图像就像是一座山,如下图所示
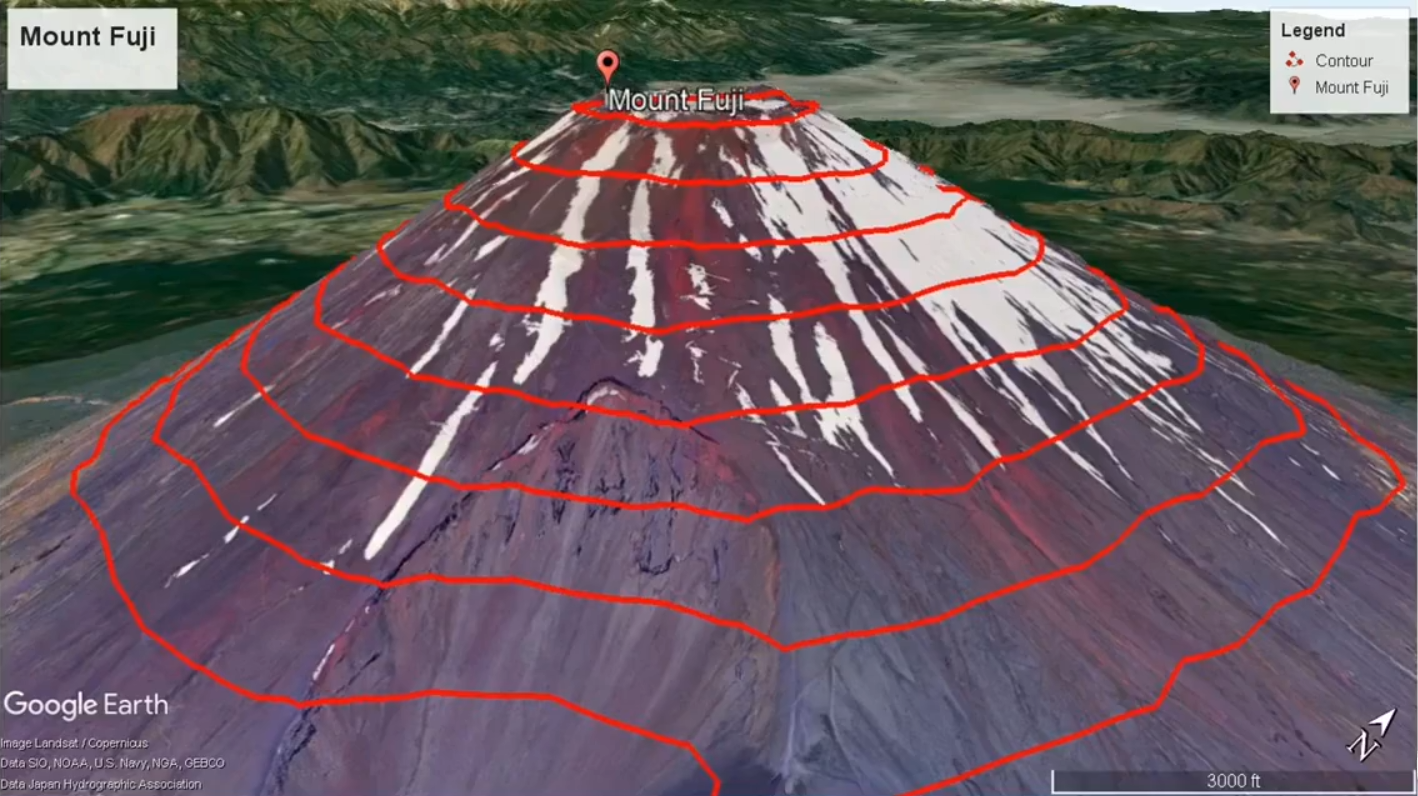
换个视角来看,就变为了等高线图,在三维图中寻找局部最优解的过程对应着等高线图中梯度下降的过程
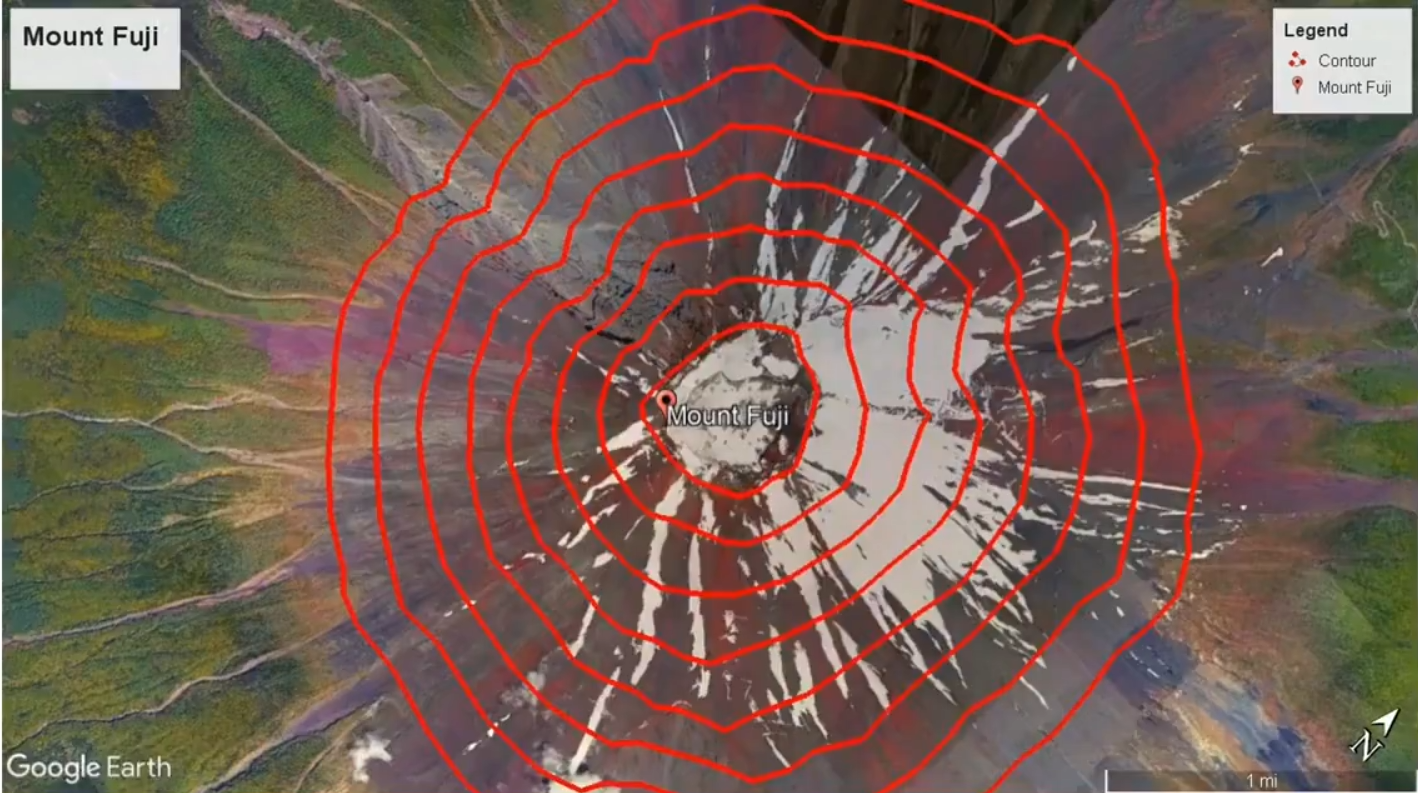
上面说的有问题,我们希望最小化代价函数,因此我们应该是考虑函数j,因此三维图是j,w,b的函数,等高线上相同线上的代价函数j值是相同的,我们寻求的是j的局部最优解
当仅存在一个变量时,梯度下降是按照下面这样理解的
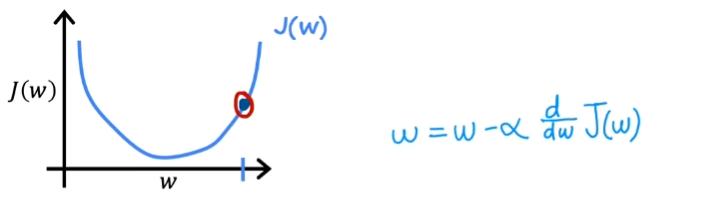
线性回归问题只不过是由上述的单变量w变为了双变量w和b,梯度下降就变为对两个变量分别进行梯度下降,于是线性回归问题的梯度下降就是按照下面这样进行的
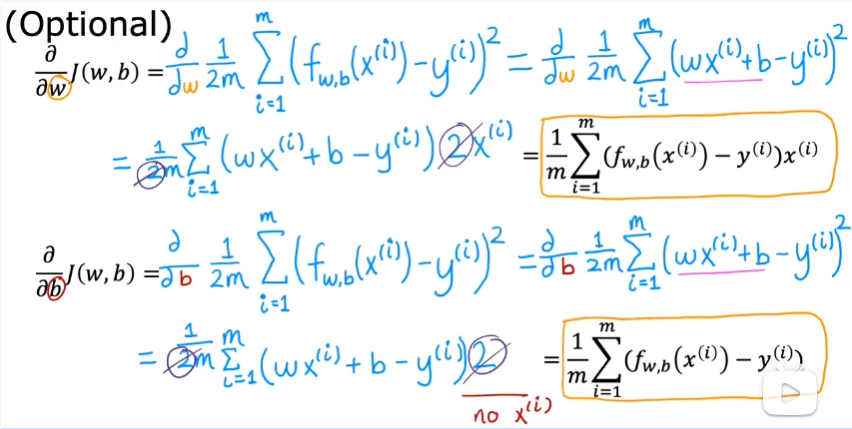
只有凸函数(外国的定义)具有全局最小值,否则w和b的选择不同可能会到达不同的局部最小值,但不一定一定可以到达全局最小值
参考
- [1] 直观理解梯度,以及偏导数、方向导数和法向量
- [2] 导数、方向导数与梯度
- [3] 第七节 方向导数与梯度
- [4] 函数对向量求导通俗理解


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2021-01-09 货仓选址