Mysql
Windows压缩包安装流程
命令概览
// Create the default database and exit. Create a super user with empty password.
mysqld --initialize-insecure
// Install the default service
mysqld --install
// 启动Mysql服务
net start mysql
// 无密码登录Mysql
mysql -uroot
// 修改密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的新密码';
1.准备Mysql文件
- 下载:Mysql官方站点
- 解压上述文件至目录
mysqlxxx
2.添加环境变量
将bin目录(mysqlxxx/bin)配置到环境变量PATH中
3.初始化data目录
mysqld --initialize-insecure
注:执行此命令后,会在
mysqlxxx下生成data文件夹
4.配置文件
在mysqlxxx下新建配置文件my.ini,内容为
[client]
port=3306
[mysql]
default-character-set=utf8
[mysqld]
port = 3306
basedir=mysqlxxx
datadir=mysqlxxx/data
配置文件的读取优先顺序为(可通过mysqld --verbose --help查询得到)
- C:/WINDOWS/my.ini
- C:/WINDOWS/my.cnf
- C:/my.ini
- C:/my.cnf
- mysqlxxx/my.ini
- mysqlxxx/my.cnf
配置文件详解
[client]
| 参数名称 | 说明 |
|---|---|
| port | MySQL 客户端连接服务器端时使用的端口号,默认的端口号为 3306 |
[mysql]
| 参数名称 | 说明 |
|---|---|
| default-character-set | MySQL 客户端默认的字符集 |
[mysqld]
| 参数名称 | 说明 |
|---|---|
| port | 表示 MySQL 服务器的端口号 |
| basedir | 表示 MySQL 的安装路径 |
| datadir | 表示 MySQL 数据文件的存储位置,也是数据表的存放位置 |
| default-character-set | 表示服务器端默认的字符集 |
| default-storage-engine | 创建数据表时,默认使用的存储引擎 |
| sql-mode | 表示 SQL 模式的参数,通过这个参数可以设置检验 SQL 语句的严格程度 |
| max_connections | 表示允许同时访问 MySQL 服务器的最大连接数。其中一个连接是保留的,留给管理员专用的 |
| query_cache_size | 表示查询时的缓存大小,缓存中可以存储以前通过 SELECT 语句查询过的信息,再次查询时就可以直接从缓存中拿出信息,可以改善查询效率 |
| table_open_cache | 表示所有进程打开表的总数 |
| tmp_table_size | 表示内存中每个临时表允许的最大大小 |
| thread_cache_size | 表示缓存的最大线程数 |
| myisam_max_sort_file_size | 表示 MySQL 重建索引时所允许的最大临时文件的大小 |
| myisam_sort_buffer_size | 表示重建索引时的缓存大小 |
| key_buffer_size | 表示关键词的缓存大小 |
| read_buffer_size | 表示 MyISAM 表全表扫描的缓存大小 |
| read_rnd_buffer_size | 表示将排序好的数据存入该缓存中 |
| sort_buffer_size | 表示用于排序的缓存大小 |
注:修改 my.ini 文件中的参数后,必须重新启动 MySQL 服务才会有效
可通过show variables like '%CHAR%';查看mysql编码确定配置文件是否生效
5.安装服务
mysqld --install // Install the default service
mysqld --install service_name // Install an optional service
6.启动服务
6.1命令行启动
net start mysql
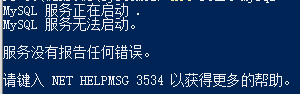
注:此命令需要以管理员身份执行cmd或powershell
若提示以下错误信息,可执行命令
mysqld --console查找问题并解决
6.2通过服务
Windows+R打开运行- 输入
services.msc - 找到Mysql(或自定义名称),启动服务
7.登录Mysql并修改密码
// 无密码登录Mysql
mysql -uroot
// 修改密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的新密码';
Windows压缩包卸载流程
命令概览
// 停止mysql服务
net stop mysql
// Remove the default service from the service list
mysqld --remove
1.停止服务
1.1命令行停止
net stop mysql
注:此命令需要以管理员身份执行cmd或powershell
1.2通过服务
Windows+R打开运行- 输入
services.msc - 找到Mysql(或自定义名称),停止服务
2.卸载服务
mysqld --remove // Remove the default service from the service list
mysqld --remove service_name // Remove the service_name from the service list
3.删除环境变量
4.删除Mysql文件
Linux-docker-mysql部署流程
以数据持久化的方式运行,将配置文件和数据挂载在宿主机中,一方面对配置信息的修改无需进入容器,另一方面确保容器重启后数据依然存在
- 创建临时容器,将配置文件复制到宿主机
1. docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql
2. mkdir -p /root/docker/mysql/conf && mkdir -p /root/docker/mysql/data
3. docker cp mysql:/etc/my.cnf /root/docker/mysql/conf
- 创建新容器
docker run --name mysql \
-p hostport:3306 -e MYSQL_ROOT_PASSWORD=xxxx \
--mount type=bind,src=/root/docker/mysql/conf/my.cnf,dst=/etc/my.cnf \
--mount type=bind,src=/root/docker/mysql/data,dst=/var/lib/mysql \
--restart=on-failure:3 \
-d mysql
- 宿主机进入mysql命令行
docker exec -it mysql bash
权限管理
初始密码
在使用docker时,通过-e MYSQL_ROOT_PASSWORD=password似乎可以跳过无密码登录mysql之后修改密码的过程
参考
设置远程访问权限
当mysql安装完成之后,默认设置”localhost”具有全部权限。所以大部分服务器端脚本程序可以很方便的联接到本地服务器的数据库,但远程连接会被拦截,直到授予足够的用户权限。例如,在远程连接mysql时,新建数据库提示1044-Access denied for user 'root'@'%' to database '数据库名称'
根据mysql文档,root指登录用户,%的含义为:The host name part of the account, if omitted, defaults to '%'.
由下图mysql数据库->user表可以看出,root用户对应两个host-%和localhost,%对应远程连接,localhost对应本地连接,分别具有一定的权限

大部分博客给出的解决方案是使用命令GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION修改以root用户进行远程连接时的权限。但是会出现报错ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'IDENTIFIED BY '123' WITH GRANT OPTION' at line 1
理解这个问题,需要了解一下CREATE USER、ALTER USER 和 GRANT这3者之间的关系。CREATE USER用于创建一个用户,ALTER USER用于修改用户的非特权属性,GRANT用于修改用户的特权属性。
在MySQL 5.7之前,GRANT不仅可以修改特权属性,同时也可以起到创建用户和修改非特权属性的作用,也就是GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION此命令的用法
在MySQL 5.7之后,上述用法就被弃用了
use of GRANT to create accounts or define nonprivilege characteristics is deprecated in MySQL 5.7[1]
三个命令的用法示例就变为[2]:
CREATE USER 'jeffrey'@'localhost' IDENTIFIED BY 'password';
ALTER USER 'jeffrey'@'localhost' WITH MAX_QUERIES_PER_HOUR 90;
GRANT ALL ON db1.* TO 'jeffrey'@'localhost';
因此只需要执行以下命令,赋予以root用户远程连接全部特权并进行刷新
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';
FLUSH PRIVILEGES;
注:若修改后无效,尝试重启mysql服务
总结:该问题的核心就是mysql数据库-user表中root@'%'用户的权限,如果没有这个用户,可以手动创建该用户;如果有该用户但没有权限,可以修改其权限
参考
撤销权限
参考
- [1] REVOKE Statement
Mysql索引理解
创建语句:
CREATE INDEX idx_name ON students(name);
索引:是一本书籍的重要组成部分,它把书中的重要名词名称罗列出来,并给出它们相应的页码,方便读者快速查找该名词的定义和含义 --Wikipedia
书籍目录表现出的效果就是,我们可以利用其快速定位到整本书的其中一部分,抽象一点描述就是快速定位到大数据集中的一个小的子集
mysql中的索引预期目标是与此相同的,我们对一些列建立索引,预期目标就是能够根据这一列对应的属性快速缩小查找范围,从而提高查找速度
然后这种“快速定位到大数据集中的一个小的子集”只是逻辑上面的说法,我们要将其实现,就需要考虑物理存储的问题
此问题属于查找范畴,所以不妨回忆一下数据结构中的内容,在查找一章节中,着重讲述了树形结构
以二叉搜索树为例,通过将结点设定为一些条件,每次都可以快速地将待查找数据集分为两部分,这实现的效果似乎与索引的预期效果相一致
为了后续描述的方便,假设目前存在一张学生表,存在id、name、age字段
上述提到将结点设定为一些条件,不妨考虑一下如果我们将条件设定为age是什么效果。我们将得到一颗根据age进行划分的二叉搜索树,或许就像下面这样
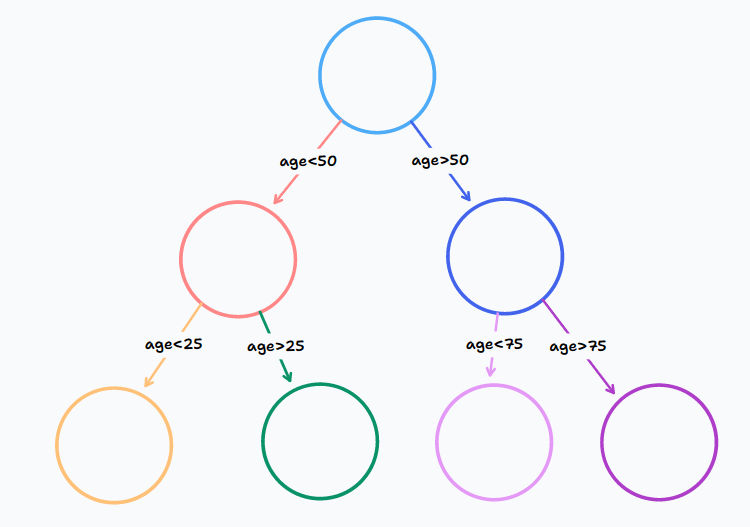
根据这颗二叉搜索树,我们就可以根据age进行快速定位查找
因为age此时就像目录一样,我们可以根据age对整个数据集进行快速的划分,从而快速完成查找工作,age此时就像目录一样,所以说这就相当于对age字段添加了索引
也就是说到目前为止,我们理解了mysql所说的索引可以加快查找过程是怎么一回事,其本质就是利用了修改结点分裂条件后的树形查找。不过需要注意的是,上面我们为了讲解的方便,使用的是二叉搜索树,而mysql实际运用的是B+Tree,不过这对于索引的含义并没有什么影响,因为B+Tree也只是特殊的多叉搜索树。mysql对某个字段建立索引,实际上就是以这个字段为分裂条件创建了一颗新的B+Tree,对多个字段创建索引就会创建出多个B+Tree。需要注意多个字段联合字段,多个字段中每个字段都是独立的,而联合字段相当于一个大的独立字段。
理解了以上内容后,关于“聚簇索引无需手动创建”这一规则就不难理解了,在没有创建任何索引时,所有数据仍然需要按照B+Tree进行存储,此时的分裂条件就会自动设定为主键、第一个unique字段或者当二者都不存在时,mysql会自行创建字段充当分裂条件。所以无形之中就为它们创建了索引。也就说当表中存在主键但又没有创建其他索引时,按照主键进行查询的速度理论上是要快于根据其他字段进行查询的速度。
Reference(以下内容来自chatgpt)
当在多个字段上创建索引时,MySQL 会分别为每个索引创建一棵 B+Tree。例如,如果你同时在name和age字段上创建了索引,那么 MySQL 会分别创建一颗以name为键值的 B+Tree 和一颗以age为键值的 B+Tree。每个 B+Tree 都包含了相应字段的键值和指向数据行的指针。在查询时,MySQL 会根据查询条件和查询语句中的
WHERE子句,选择其中一个最适合的索引进行查找。当查询条件包含了多个字段时,MySQL 可能会利用多个索引进行查找,并且在内部将它们合并起来。这个过程叫做“索引合并”(Index Merge)。在索引合并的过程中,MySQL 可以通过对多个索引进行排序、去重和过滤等操作,综合利用多个索引的信息,从而找到最终的查询结果。具体来说,当 MySQL 执行一个包含多个索引的查询语句时,它会将这些索引的键值从各自的 B+Tree 中取出,进行排序和去重,并计算出它们的交集。然后,MySQL 再利用这个交集对数据表进行扫描,从而找到满足查询条件的数据行。
需要注意的是,索引合并的过程可能会带来一定的性能开销,因为它需要对多个索引进行操作,并且需要在内存中缓存大量的数据。因此,在设计索引时,需要根据实际的业务需求和数据特征来选择适合的索引策略,从而提高查询效率。
创建索引的注意事项
-
通用设计原则
1.1 对于经常被查询的列,可以考虑创建索引,以提高查询性能。但是,对于一些不经常被查询的列,创建索引反而会带来额外的维护成本和存储开销。
1.2 避免创建过多的索引。过多的索引会占用大量的存储空间和维护成本,同时也可能会导致查询性能下降。 -
特殊场景设计原则
2.1 对于组合查询,可以考虑创建联合索引。联合索引可以提高查询效率,但需要注意索引的顺序和组合方式。
2.2 对于高并发的系统,需要考虑索引对写操作的影响。索引的增删改操作都会带来额外的维护成本,因此需要根据实际情况进行权衡和选择。
2.3 对于一些字符串类型的列,可以考虑使用前缀索引。前缀索引可以大大减少索引的存储空间,同时也可以提高查询效率。 -
特别注意
3.1 避免在查询中使用函数或表达式。使用函数或表达式可能会导致索引失效,从而影响查询性能。
如何理解这一点?
使用函数或表达式可能导致索引失效是因为数据库系统无法利用索引直接匹配函数或表达式的结果,而需要先计算出函数或表达式的值,然后再进行匹配。这样就需要扫描整个表来匹配结果,而无法利用索引的快速匹配特性,从而导致查询效率下降。
举个例子,如果我们在查询中使用了函数或表达式,如下所示:
SELECT * FROM table WHERE YEAR(date_column) = 2022;
其中,我们使用了 YEAR() 函数来提取日期列的年份信息。由于数据库系统无法直接匹配函数结果,而是需要先计算出每一行的年份值,然后再进行匹配,因此无法利用索引的快速匹配特性。如果我们在日期列上创建了索引,这个索引就会失效,而需要对整个表进行扫描,从而导致查询效率下降。
因此,在设计数据库表结构和查询语句时,需要避免使用函数或表达式,以提高查询性能。如果必须使用函数或表达式,可以考虑将其放在查询条件的右侧,以减少其对索引的影响。例如:
SELECT * FROM table WHERE date_column >= '2022-01-01' AND date_column < '2023-01-01';
在这个查询语句中,我们使用了日期范围来代替 YEAR() 函数,从而可以利用索引进行快速匹配。
但是注意,函数或表达式只是可能使索引失效,在以下两种情况中并不会失效
- 前缀索引:如果我们在一个字符串列上创建了前缀索引,那么我们仍然可以在查询中使用函数或表达式,只要这个函数或表达式不改变列值的前缀部分。例如,我们可以在一个名字列上创建前缀索引,然后在查询中使用 LEFT() 函数来提取名字的前几个字符,仍然可以利用前缀索引进行快速匹配。
- 函数索引:某些数据库系统支持在函数上创建索引,这样就可以利用索引直接匹配函数的结果。例如,MySQL 支持在字符串列上创建 FULLTEXT 索引,然后利用 MATCH() 函数进行全文搜索。这种情况下,函数或表达式不会导致索引失效,而是直接利用索引进行匹配。
时区问题
-
查看时区
show variables like '%zone%'; -
在 MySQL 启动时就指定时区,则应该使用启动参数:
default-time-zone
--方法1:在启动命令中添加
mysqld --default-time-zone='+08:00' &
--方法2:在配置文件中添加
[mysqld]
default-time-zone='+08:00'
- 后期修改时区
--修改全局时区,所有已经创建的、新创建的session都会被修改
set global time_zone='+00:00';
--修改当前session的时区
set session time_zone='+00:00';
Reference
mysql时区


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2021-01-08 简单高精度模板总结