Python
python介绍
跨平台,面向对象,解释型语言
编译相关
- pyc文件: .pyc 是一种二进制文件,是由 .py 文件经过编译后,生成一种byte code文件。 .py 文件变成 .pyc 文件后,加载的速度有所提高,而且 .pyc 是一种跨平台的字节码,是由python的虚拟机来执行的,这个类似于JAVA或者.NET的虚拟机的概念。 .pyc 的内容是跟python的版本相关的,不同版本编译后的 .pyc 文件是不同的,2.5编译的 .pyc 文件对于2.4版本的python是无法执行的。可用于隐藏Python源代码和提高运行速度
- pyw文件: Python源文件,常用于图形界面程序文件
- pyo文件: .pyo 是优化编译后的字节码文件 python -O 源文件 即可将源程序编译为 .pyo 文件。
- pyd文件: 由其他语言编写并编译的二进制文件, 常用于实现接口插件或Python动态链接库
# 编译成pyc文件
# ------------------------------------------------------
python -m py_compile $filename # 其中,$filename是要编译的python源码文件名
2. 编译成pyo文件
# -------------------------------------------------------
python -O -m py_compile $filename
# 或者
python -OO -m py_compile $filename
# 其中, + -O选项表示优化产生的字节码,优化程度由PYTHONOPTIMIZE(environment)的值来决定。 + -OO选项表示在-O优化的基础上移除所有的doc-strings(文档文本)。

对于模块文件,第一次被导入时将被编译成字节码的形式,并在以后再次导入时优先使用“.pyc”文件,以提高模块的加载和运行速度
对于非模块文件,直接执行时并不生成“.pyc”文件,可以选择手动编译
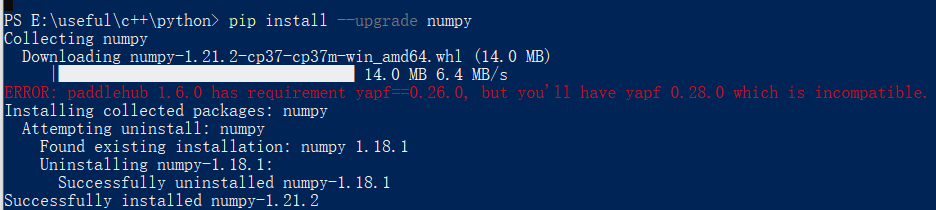
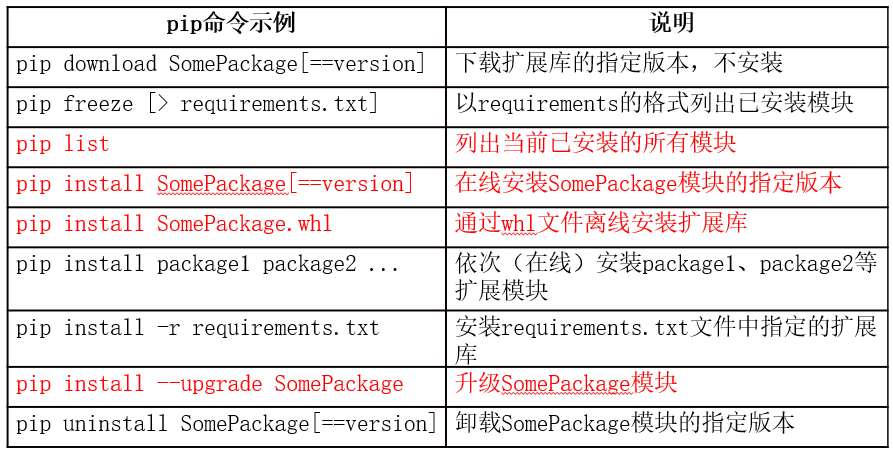
pip命令
对象
- python中一切都是对象
- 内置对象可直接使用,数字,字符串,列表
- 非内置对象需要导入模块
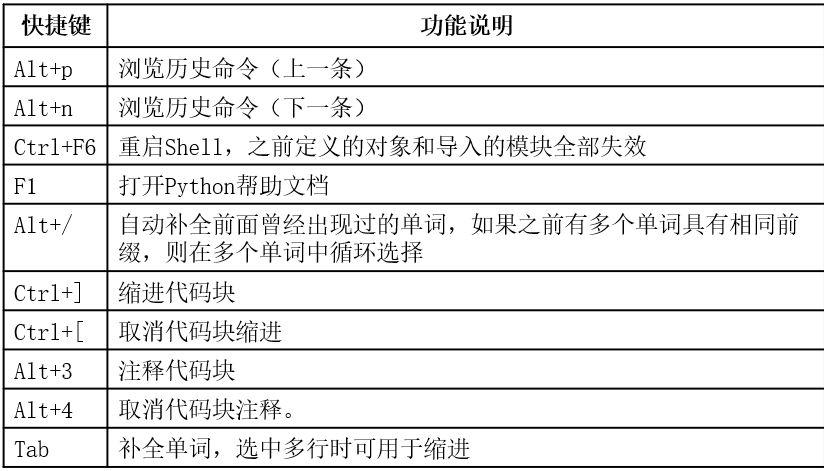
IDLE交互模式
- 在 IDLE 交互模式中浏览上一条语句的快捷键是
ALT + P - IDLE下一条
Alt + n - 在 IDLE 交互模式中,复合语句(例如
for循环等需要按两次回车)
强弱类型&动态静态
- 强类型:某一个变量被定义类型,如果不经强制转换,那么它永远是该数据类型
- 弱类型:某一个变量被定义类型,该变量可以根据环境变化自动进行转换,不需要经过现行强制转换
- 动态类型:在运行期间才去做数据类型检查的语言,,即写程序时不需要指明变量类型,到程序运行为变量赋值时变量的类型才得以确认
- 静态类型:数据类型在编译期间检查,也就是说在写程序时要声明所有变量的数据类型
python运算符
算术运算符
| 算术运算符 | 功能 |
|---|---|
| + | 两个数相加,或是字符串连接 |
| - | 两个数相减 |
| * | 两个数相乘,或是返回一个重复若干次的字符串 |
| / | 两个数相除,结果为浮点数(小数) |
| // | 两个数相除,结果为向下取整的整数 |
| % | 取模,返回两个数相除的余数 |
| ** | 幂运算,返回乘方结果 |
python不支持++和--自增自减运算符,起到的作用仅是改变正负
+-2
>> -2
逻辑运算符
| 逻辑运算符 | 功能 |
|---|---|
| and | 布尔“与”运算符,返回两个变量“与”运算的结果 |
| or | 布尔“或”运算符,返回两个变量“或”运算的结果 |
| not | 布尔“非”运算符,返回对变量“非”运算的结果 |
具有惰性求值特点,只计算必须计算的表达式
# 由于是 or 运算,只要有一者为真,那么结果为真,因此到3时就可以确定最终结果了(python认为非0值均为True)
>>> 3 or 5
3
## 由于是and运算,只要一者为假,那么最终结果为假
>>> 0 and 2
0
位运算符
| 位运算符 | 功能 |
|---|---|
| & | 按位“与”运算符:参与运算的两个值,如果两个相应位都为 1,则结果为 1,否则为 0 |
| ^ | 按位“异或”运算符:当两对应的二进制位相异时,结果为 1 |
| ~ | 按位“取反”运算符:对数据的每个二进制位取反,即把 1 变为 0,把 0 变为 1 |
| << | “左移动”运算符:运算数的各二进制位全部左移若干位,由“<<”右边的数指定移动的位数,高位丢弃, 低位补 0 |
| >> | “右移动”运算符:运算数的各二进制位全部右移若干位,由“>>”右边的数指定移动的位数 |
成员运算符
| 成员运算符 | 功能 |
|---|---|
| in | 当在指定的序列中找到值时返回 True,否则返回 False |
| not in | 当在指定的序列中没有找到值时返回 True,否则返回 False |
身份成员运算符
| 身份成员运算符 | 功能 |
|---|---|
| is | 判断两个标识符是否引用自同一个对象,若引用的是同一个对象则返回 True,否则返回 False |
| is not | 判断两个标识符是不是引用自不同对象,若引用的不是同一个对象则返回 True,否则返回 False |
同一个对象:具有相同的id
集合操作符
| 集合操作符 | 功能 |
|---|---|
| S | T | 返回一个新的集合,包括在集合S和T的所有元素 |
| S - T | 返回一个新集合,包括在集合S但不在T中的元素 |
| S & T | 返回一个新集合,包括同时在集合S和T中的元素 |
| S ^ T | 返回一个新集合, 包括集合S和T中不相同元素,等价于 (S | T) - (S & T),和两个数异或的感觉差不多,相同数异或之后就没得了 |
| S <= T 或 S < T | 返回True/False, 判断S和T的子集关系 |
| S >= T 或 S > T | 返回True/False, 判断S和T的包含关系 |
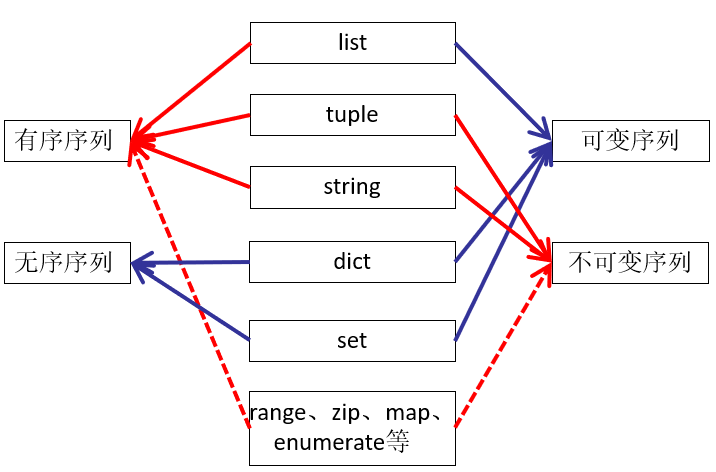
python 6种数据类型
map、filter、enumerate、zip具有的特点:1. 惰性求值 2. 访问过的元素不可再次访问,简单理解就是迭代器已经到了end()的位置
x = [1, 2, 3]
y = filter(lambda x : x + 1, x)
print(list(y))
print(list(y))
结果:
[1, 2, 3]
[]
Number(数字)
复数
>>> c = 3 + 4j
>>> c.real # 实部
3.0
>>> c.imag # 虚部
4.0
在数字中间位置使用单个下划线作为分隔来提高数字的可读性,不影响数字的值,仅是方便读
>>> 1_2_3.4_5
123.45
String(字符串)
1、反斜杠可以用来转义,使用r意思是将那些特殊的转义字符看为普通字符,例如'\n'代表换行,但是r'\n'仅代表两个字符,一个'',一个'n',当我们希望字符串中的''仅是一个''字符而非转义符号时,一种方法是'\',另一种就是字符串前面加上'r'
2、字符串可以用+运算符连接在一起,用*运算符重复。
3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
4、Python中的字符串不能改变,因此切片不支持字符串修改
常用转义字符
| 转义字符 | 含义 | 转义字符 | 含义 |
|---|---|---|---|
| \b | 退格,把光标移动到前一列位置 | \ | 一个斜线\ |
| \f | 换页符 | \’ | 单引号’ |
| \n | 换行符 | \” | 双引号” |
| \r | 回车 | \ooo | 3位八进制数对应的字符 |
| \t | 水平制表符 | \xhh | 2位十六进制数对应的字符 |
| \v | 垂直制表符 | \uhhhh | 4位十六进制数表示的Unicode字符 |
List(列表)[]
1、List写在方括号之间,元素用逗号隔开。
2、和字符串一样,list可以被索引和切片。
3、List可以使用+操作符进行拼接。
4、List中的元素是可以改变的。
5、列表支持双向索引(最后一个元素索引值为-1)
6、一个列表中的数据类型可以各不相同
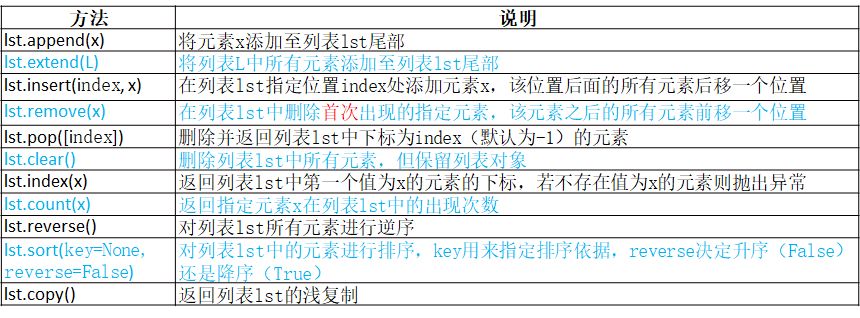
remove(x):If the element doesn’t exist, it throws ValueError: list.remove(x): x not in list exception.
+在进行列表拼接时,并非把一个列表中的元素加入到另一个列表中,而是重新开辟一个列表,将两部分列表中的元素复制过去,较为耗时
append()和extend()都是原地操作,前者是增加一个元素,后者可以将可迭代对象逐个放入
+=类似extend(),是原地操作,但是+并不是原地操作
x = [1, 2, 3]
print(x, id(x))
x += [4]
print(x, id(x))
x = x + [5]
print(x, id(x))
结果:
[1, 2, 3] 2918749822344
[1, 2, 3, 4] 2918749822344
[1, 2, 3, 4, 5] 2918749822216
insert()虽然会移动元素,但是仍是原地操作
x = [1, 2, 3]
print(x, id(x))
x.insert(1, 2)
print(x, id(x))
结果:
[1, 2, 3] 2785177427336
[1, 2, 2, 3] 2785177427336
乘法增加列表元素对象,对原列表内容的重复,且复制出来的不是值,而是引用,修改任何一个其它的也会改变
>>> x = [[1]]
>>> x *= 3
>>> x
[[1], [1], [1]]
>>> x[0][0] = 2
>>> x
[[2], [2], [2]]
列表推导式得到的重复内容,仅是值,而非引用,改变其中一个,其它的并不会改变
>>> x = [[] for i in range(3)]
>>> x[0].append(1)
>>> x
[[1], [], []]
Tuple(元组)()
1、与字符串一样,元组的元素不能修改。
2、元组也可以被索引和切片,方法一样。
3、注意构造包含 0 或 1 个元素的元组的特殊语法规则。tup1 = () # 空元组 tup2 = (20,) # 一个元素,需要在元素后添加逗号4、元组也可以使用+操作符进行拼接。
5.元组支持双向索引(最后一个元素索引值为-1)
连续赋值可以得到一个元组
>>> x = 3, 4
>>> x
(3, 4)
del 不能删除元组中单个元素,但是可以直接删除整个元组
元组虽然为不可变序列,但是其中确可以放入可变序列。并且其中的可变序列还可以进行修改。但放入可变序列的元组就不能再放进set或者作为dist的键了
元组其实就是一种特殊的列表,什么都可以放,只是不能修改
>>> a = [1, 2]
>>> b = (1, a)
>>> b
(1, [1, 2])
Set(集合){}
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是
集合中只能保存不可变序列,例如字符串,元组,原因与Why Lists Can't Be Dictionary Keys类似
当两个集合中存储的数据相同时,两个集合相等
注:
- 是两个集合相等,不是两个对象相同,是两个对象,但是它们的内容相等
- 集合是无序容器,所以判断是否相等时不考虑数据顺序,仅考虑含有的数字是不是一样的
集合的大小关系 <=> 包含关系
x = {1, 2, 3}
y = {1, 2, 5}
z = {1, 2, 3, 4, 5}
print(x < y) # x不是y的真子集
print(y < z) # y是z的真子集
print(x < z) # x是z的真子集
结果:
False
True
True
无法删除集合中指定位置的元素,只能删除特定值的元素
del不能删除集合中的元素,但是可以删除整个集合
| 函数 | 描述 |
|---|---|
| remove | 使用 remove 方法删除元素时,如果元素不存在集合中,那么程序会报错。 |
| discard | 使用 discard 方法删除元素时,如果元素不存在集合中,那么程序不会报错。 |
| pop | 使用 pop 方法删除集合中的元素时,会自动删除集合中的第一个元素,并返回被删除的元素,如果集合为空,程序报错。 |
Dictionary(字典){}
1、字典是一种映射类型,它的元素是键值对。
2、字典的关键字必须为不可变类型,且不能重复,即数字,字符串,元组
3、创建空字典使用
sorted()直接对字典排序,实际是对字典的键进行排序,因为字典属于无序容器,顺序对它来说并没有意义
Why Lists Can't Be Dictionary Keys
如果需要一个可以记住元素插入顺序的字典,可以使用 collections.OrderedDict
输出字典,默认输出键
x = {
"name":"ghy",
"age": 20,
"sex":"male"
}
for i in x:
print(i)
结果:
name
age
sex
| 序号 | 函数 | 描述 |
|---|---|---|
| 1 | radiansdict.clear() | 删除字典内所有元素 |
| 2 | radiansdict.copy() | 返回一个字典的浅复制 |
| 3 | radiansdict.fromkeys(seq) | 创建一个新字典,以序列seq中元素做字典的键,None为所有键对应的初始值 |
| 4 | radiansdict.get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| 5 | key in dict | 如果键在字典dict里返回true,否则返回false |
| 6 | radiansdict.items() | 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | radiansdict.keys() | 以列表返回一个字典所有的键 |
| 8 | radiansdict.setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | radiansdict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| 10 | radiansdict.values() | 以列表返回字典中的所有值 |
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
有序序列:列表,字符串,元组
无序序列:字典,集合
python类型转换
| 函数 | 描述 |
|---|---|
| int(x, base = 10) | 将x转换为一个整数(1.若 x 为纯数字,则不能有 base 参数,否则报错;其作用为对入参 x 取整;2.若 x 为 str,则 base 可略可有,base 存在时,视 x 为 base 类型数字,并将其转换为 10 进制数字 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数,或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值(ASCII码) |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
print语句
print(*objects, sep=' ', end='\n', file=sys.stdout)
objects --表示输出的对象。输出多个对象时,需要用 , (逗号)分隔
sep -- 指定输出对象之间的间隔符
end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符
file -- 要写入的文件对象
格式化输出:
>>> print("the length of (%s) is %d" %('runoob',len('runoob')))
the length of (runoob) is 6
内存管理机制
Python 采用的是基于值的自动内存管理方式,相同的值在内存中只有一份
这个问题比较复杂,因为运行结果要分为在交互模式下和在程序中两种情况,上面的说法也没错,但是说的非常笼统
首先,Python启动时,会对[-5, 256]区间的整数进行缓存
交互模式下
- 浮点数的id不同,不过连续赋值有点奇怪
>>> x = 3.4
>>> y = 3.4
>>> id(x) == id(y)
False
>>> x, y = 3.4, 3.4
>>> id(x) == id(y)
True
- 列表内部,缓存区以内相同数的id相等,在缓存区间以外,相同大整数的id相等,小数(例如负数)的id不等
>>> x = [30000, 30000]
>>> id(x[0]) == id(x[1])
True
>>> x = [-111, -11]
>>> x = [-111, -111]
>>> id(x[0]) == id(x[1])
False
- 不同列表之间,缓存区以内相同数值id相等, 在缓存区间以外相同数值的id不等
>>> x = [300, 300]
>>> y = [300, 300]
>>> id(x[0]) == id(y[0])
False
- 相同列表,相同短字符串的id相等,相同长字符串的id不等
>>> x = ['abc', 'abc']
>>> id(x[0]) == id(x[1])
True
>>> x = ['abc' * 50, 'abc' * 50]
>>> id(x[0]) == id(x[1])
False
程序中
- 浮点数的id相等
x = 3.4
y = 3.4
print(id(x) == id(y))
True
x, y = 3.4, 3.4
print(id(x) == id(y))
True
- 列表内部执行结果与交互模式相同
- 不同列表之间,缓存区以外相同大整数id相等,小数(例如负数)id不等
x = [300, 300]
y = [300, 300]
print(id(x[0]) == id(y[0]))
True
x = [-111, -111]
y = [-111, -111]
print(id(x[0]) == id(y[0]))
False
- 字符串同交互模式
这句话并不严密
对象存储的是值的内存地址或者引用,为对象修改值时,并不是真的直接修改变量的值,而是使变量指向新的值
库
python标准库
| 名称 | 作用 |
|---|---|
| datetime | 为日期和时间处理同时提供了简单和复杂的方法 |
| zlib | 直接支持通用的数据打包和压缩格式:zlib,gzip,bz2,zipfile,以及 tarfile |
| random | 提供了生成随机数的工具 |
| math | 为浮点运算提供了对底层C函数库的访问 |
| sys | 工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于 sys 模块的 argv 变量 |
| glob | 提供了一个函数用于从目录通配符搜索中生成文件列表 |
| os | 提供了不少与操作系统相关联的函数 |
无论时标准库还是第三方库使用时都需要import
但是在使用标准库中那68个内置函数时是不需要导入库的
注释
- 单行注释 :
# - 多行注释:三个单引号
'''或者三个双引号"""
注:这并不代表着三个单引号或双引号中的内容就是注释,它们也可用来定义字符串(单行字符串或多行字符串)
python关键字
id不是关键字,可以作为变量名,但不建议
python变量名是区分大小写的
| 关键字 | 描述 |
|---|---|
| and | 逻辑运算符。 |
| as | 创建别名。 |
| assert | 用于调试。 |
| break | 跳出循环。 |
| class | 定义类。 |
| continue | 继续循环的下一个迭代。 |
| def | 定义函数。 |
| del | 删除对象。 |
| elif | 在条件语句中使用,等同于 else if。 |
| else | 用于条件语句。 |
| except | 处理异常,发生异常时如何执行。 |
| False | 布尔值,比较运算的结果。 |
| finally | 处理异常,无论是否存在异常,都将执行一段代码。 |
| for | 创建 for 循环。 |
| from | 导入模块的特定部分。 |
| global | 声明全局变量。 |
| if | 写一个条件语句。 |
| import | 导入模块。 |
| in | 检查列表、元组等集合中是否存在某个值。 |
| is | 测试两个变量是否相等。 |
| lambda | 创建匿名函数。 |
| None | 表示 null 值。 |
| nonlocal | 声明非局部变量。 |
| not | 逻辑运算符。 |
| or | 逻辑运算符。 |
| pass | null 语句,一条什么都不做的语句。 |
| raise | 产生异常。 |
| return | 退出函数并返回值。 |
| True | 布尔值,比较运算的结果。 |
| try | 编写 try...except 语句。 |
| while | 创建 while 循环。 |
| with | 用于简化异常处理。 |
| yield | 结束函数,返回生成器。 |
del
- 删除整个列表
del list - 删除列表中某个元素
del list[0]
切片
浅复制是指复制出的为原内容的引用,存储在同一内存区域,copy()是指对列表中的每一个元素执行浅拷贝,例如列表中嵌套列表,copy出的新列表中的嵌套列表为原来的拷贝
深复制是指复制出的为原内容的拷贝,存储在不同内存区域,deepcopy()是指对列表中的每一个元素执行深拷贝
切片返回的为浅复制,因此可以通过切片直接修改原有序列中那些容器,改变切片中的数值原有容器对应数值并不会改变
但是切片得到和原列表并不是一个对象,两者的id并不相等
>>> x = [1, [2, 3]]
>>> y = x[:]
>>> id(x)
2491381320136
>>> id(y)
2491381319048
>>> x
[1, [2, 3]]
>>> y
[1, [2, 3]]
>>> y[0] = 4
>>> x
[1, [2, 3]]
>>> y
[4, [2, 3]]
>>> y[1][0] = 5
>>> x
[1, [5, 3]]
>>> y
[4, [5, 3]]
但是直接赋值得到的和原列表是一个对象,修改其中一个中的任何元素,另一个对应元素也会改变(相当于一个引用)
>>> x = [1, [2, 3]]
>>> y = x
>>> id(x)
2491381319240
>>> id(y)
2491381319240
>>> y[0] = 2
>>> x
[2, [2, 3]]
>>> y
[2, [2, 3]]
切片非常神奇的地方在于,切片的结果和原对象不是同一个对象,但是却可以直接采用切片对原对象进行修改
x = [1,2,1,1,2]
print(x, id(x));
print(x[:], id(x[:]))
x[len(x):] = [3]
print(x)
结果:
[1, 2, 1, 1, 2] 2168963063176
[1, 2, 1, 1, 2] 2168963063048
[1, 2, 1, 1, 2, 3]
+=
python对[-5, 256]内的数字在内存中进行了缓存,所以当多个对象(例如下面的x和y)都等于范围内一个数字时,实际代表的对象就只是一个
>>> x = 3
>>> id(x)
1382786208
>>> id(3)
1382786208
>>> x += 3
>>> id(x)
1382786304
>>> id(6)
1382786304
序列解包
解包:把容器内的元素一个个抽离出来的过程
根据以上结果,可以推断`*a`的结果是将原列表中的两个子列表单独抽离出来在定义函数时,某个参数名字前面带有2个*符号表示可变长度参数,可以接收任意多个关键参数并将其存放于一个字典之中
排序
x.sort():原地排序,默认升序,```reverse = True````表示降序
sorted():非原地排序,返回排序后的列表,默认升序
reversed():对列表元素逆序排列返回迭代对象,通过list()可生成列表
def size(x):
return x + 5
x = [3, 4, 1, 2]
y = sorted(x, key = lambda x : x, reverse = False)
print(y)
y = sorted(x, key = size, reverse = True)
print(y)
random模块中常用方法
| 方法名 | 功能描述 |
|---|---|
| randint(1,10) | 产生 1 到 10 的一个整数型随机数 |
| random() | 产生 0 到 1 之间的随机浮点数 |
| uniform(1.1,5.4) | 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数 |
| choice('tomorrow') | 从序列中随机选取一个元素 |
| randrange(1,100,2) | 生成从1到100的间隔为2的随机整数 |
| sample([1, 2, 3, 4, 5], 3) | 从列表[1, 2, 3, 4, 5]中随机选择3个元素,如果要生成的个数大于列表中元素数量会报错 |
| random.shuffle(['A', 'B', 'C', 'D', 'E']) | 打乱列表['A', 'B', 'C', 'D', 'E']顺序 |
列表推导式和生成器推导式
列表推导式使用[]生成, 生成器推导式使用()生成
列表推导式的返回值是一个列表,生成器推导式的返回值是一个生成器对象,只能一次遍历
生成器推导式使用()生成,用一个生成一个,在我们不对它进行操作之前,它什么都不会做
x 如果是生成器推导式生成的,list(x)一次使得迭代器遍历结束,因此后一次list(x)的结果就为空了
准确的的理解是,生成器推导式并不会把结果计算出来放入到内存中,而是用一个生成一个,因此只能遍历一次
>>> x = (3 for i in range(3))
>>> x
<generator object <genexpr> at 0x0000025F8A7B3A40>
>>> list(x)
[3, 3, 3]
>>> list(x)
[]
g = (i for i in range(3))
print(g.__next__()) # 0
print(next(g)) # 1
结果:
0
1
while和for循环的else
只要循环不是由break结束的,就会执行else中的语句
while xxx:
xxx
else:
xxx
for xxx:
xxx
else:
xxx
条件表达式
在条件表达式中不允许使用赋值运算符“=”,会提示语法错误
>>> if a = 3:
SyntaxError: invalid syntax
global关键字
内部函数有引用外部函数的同名变量或者全局变量,并且对这个变量有修改时,Python 会认为它是一个局部变量,如果函数中并没有 x 的定义,则会报错local variable 'xxx' referenced before assignment
pass语句
pass 不做任何事情,一般用做占位语句
函数
如果函数中没有 return 语句,则默认返回空值 None
python内置函数
内置函数不需要导入对应模块即可使用
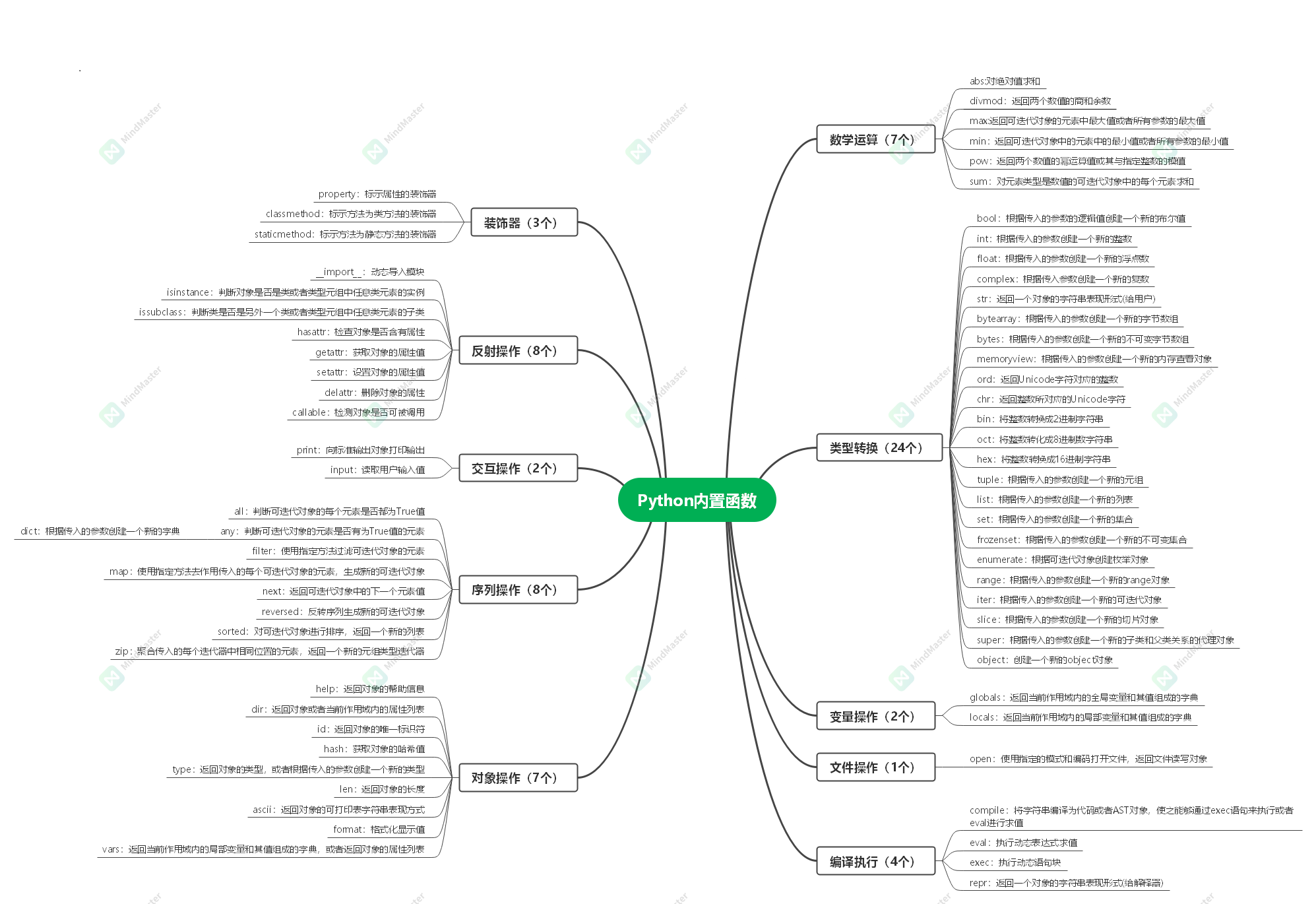
callable()
callable() 函数用于检查一个对象是否是可调用的
对于函数、方法、lambda 函式、 类以及实现了 call 方法的类实例, 它都返回 True
isinstance()
判断一个对象是否是一个已知的类型
isinstance() 与 type() 区别:
- type() 不会认为子类是一种父类类型,不考虑继承关系。
- isinstance() 会认为子类是一种父类类型,考虑继承关系。
map()
map() 函数会根据提供的函数对指定序列做映射
map(function, iterable, ...)
可迭代对象iterable中的每一个元素调用 function 函数,对iterable进行映射,返回映射结果map的迭代器
filter()
filter(function, iterable)
filter() 函数会把iterable中那些使function()返回值为True的元素留下,返回filter迭代器
map() 和 filter()区别:
a = [1, 2]
b = filter(lambda x : x > 1, a)
print(list(b))
>>> [2]
c = map(lambda x : x > 1, a)
print(list(c))
>>> [False, True]
zip()
将可迭代的对象作为参数,将对象中对应位置的元素按照下标打包成一个个元组,返回一个zip迭代器,通过list()等转化为其它容器
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = zip(a, b)
>>> list(c)
[(1, 4), (2, 5), (3, 6)]
# 不是对应位置的结果
a = [1, 2, 3]
b = ['a', 'b']
c = zip(a, b)
print(list(c))
结果:[(1, 'a'), (2, 'b')]
enumerate()
enumerate(iterable, start=0)
Parameters:
Iterable: any object that supports iteration
Start: the index value from which the counter is
to be started, by default it is 0
>>> s = "abc"
>>> o = enumerate(s, 2)
>>> o
<enumerate object at 0x0000024411E5A240>
>>> list(o)
[(2, 'a'), (3, 'b'), (4, 'c')]
eval()
函数功能更:执行一个字符串表达式,并返回表达式的值
>>> eval('2 + 2')
4
join()
用于将序列中的元素以指定的字符连接生成一个新的字符串
>>> str = '-'
>>> seq = ['a', 'b', 'c']
>>> str.join(seq)
'a-b-c'
len()
python 3.x 在统计字符串长度时,无论是数字,英文字母还是汉字,计数均按照一个字符处理
reduce()
该函数不是内置函数
代码实现出处
Geeksforgeeks讲解
# reduce()代码实现
def reduce(function, iterable, initializer=None):
it = iter(iterable)
if initializer is None:
value = next(it) # 返回第一个值,详细说明查一下next(),使用一次next,迭代器本身会自增
else:
value = initializer
for element in it:
value = function(value, element)
return value
# 当缺省initializer时,next(it)会使迭代器会后移一位,因此for循环时会从第2个元素开始
# python code to demonstrate working of reduce()
# importing functools for reduce()
import functools
# initializing list
lis = [1, 3, 5, 6, 2, ]
# using reduce to compute sum of list
print("The sum of the list elements is : ", end="")
print(functools.reduce(lambda a, b: a+b, lis))
# using reduce to compute maximum element from list
print("The maximum element of the list is : ", end="")
print(functools.reduce(lambda a, b: a if a > b else b, lis))
input()
input()函数的返回结果都是字符串,需要将其转换为相应的类型再处理
all() 和 any()
all()函数检查序列对象中是否所有元素均等价于True
any()函数检查序列对象中是否存在元素等价于True
x = [1, 1, 0]
print(all(x))
print(any(x))
结果:
False
True
sum()
sum(iterable, start)
求和,如果计算的不是数值,需要指定start。这并不难理解,数值类型不指定可以认定为0,其他类型很难说
globals() 和 locals()
globals():返回当前作用域内所有全局变量和值的字典
locals():返回当前作用域内所有局部变量和值的字典
字符串
ASCII码:1个字节
GB2312、GBK和CP936:2个字节表示中文
UTF-8:3个字节表示常见汉字
Python 3.x默认使用UTF-8编码,数字、英文字母,汉字,在统计字符串长度时都按一个字符对待和处理
x = "高"
y = 'a'
print(len(x), len(y))
结果:
1 1
字符串使用r意思是将那些特殊的转义字符看为普通字符,例如'\n'代表换行,但是r'\n'仅代表两个字符,一个'',一个'n',当我们希望字符串中的''仅是一个''字符而非转义符号时,一种方法是'\',另一种就是字符串前面加上'r'
>>> s = '\n'
>>> print(s)
>>> s = r'\n'
>>> print(s)
\n
string中定义的相关常量
whitespace = ' \t\n\r\v\f'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_letters = ascii_lowercase + ascii_uppercase
digits = '0123456789'
hexdigits = digits + 'abcdef' + 'ABCDEF'
octdigits = '01234567'
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""
printable = digits + ascii_letters + punctuation + whitespace
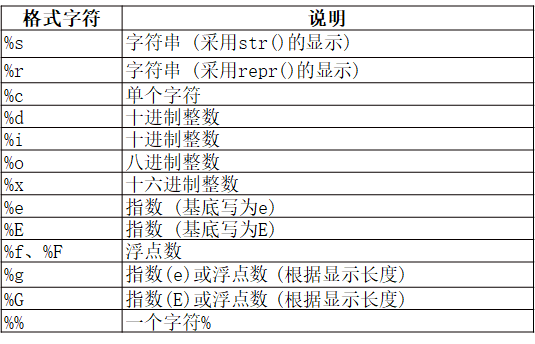
字符串格式化
- %操作符:
>>> str = '0x7f'
>>> print('I am %s'%str)
I am 0x7f
- format()方法
>>> print("I am {}".format("0x7f"))
I am 0x7f
>>> print("{} {} {}".format("I", "am", "0x7F"))
I am 0x7F
>>> print("{2} {1} {0}".format('c', 'b', 'a'))
a b c
# 与使用%操作符等价的format格式,例如%s <=> {参数位置:s},同样可以进行宽度,精度控制
>>> print("I am {0:s}".format("0x7F"))
I am 0x7F
# 使用‘#’可以添加上不同进制数前面的标志
>>> print('{0:d}, {0:b}, {0:x}, {0:o}'.format(65))
65, 1000001, 41, 101
>>> print('{0:#d}, {0:#b}, {0:#x}, {0:#o}'.format(65))
65, 0b1000001, 0x41, 0o101
# 控制精度
>>> print("{0:.2f}".format(11.12345))
11.12
- f-strings方式
weight = 8
height = 8
print(f"weight:{weight}, height:{height}, weight*height:{weight*height}")
结果:
weight:8, height:8, weight*height:64
find() 和 rfind()
str.find(str, beg=0, end=len(string))
- str:待查询字符串
- beg:规定开始位置下标
- end: 规定结束位置下标的后一位(即左闭右开区间)
find()返回待查询字符串作为子串在当前字符串中第一次出现的位置,如果没有匹配项则返回 -1
rfind()返回待查询字符串作为子串在当前字符串中最后一次出现的位置,如果没有匹配项则返回 -1
>>> n = 6
>>> x = bin(n)
>>> x
'0b110'
>>> x.rfind('1')
3
>>> str = "abc"
>>> str.find('b', 0, 1)
-1
>>> str.find('b', 0, 2)
1
startswith()
检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False
str.startswith(str, beg=0,end=len(string))
- str:待查询字符串
- beg:规定开始位置下标
- end: 规定结束位置下标的后一位(即左闭右开区间)
>>> 'abc'.startswith('a', 1)
False
>>> 'abc'.startswith('a', 0)
True
>>> 'abcd'.startswith('bc', 1, 2)
False
>>> 'abcd'.startswith('bc', 1, 3)
True
index() 和 rindex()
index():返回一个字符串在另一个字符串中作为子串第一次出现的位置,不存在则抛出异常
rindex():返回一个字符串在另一个字符串中作为子串最后一次出现的位置,不存在则抛出异常
>>> str = "abb,a,s"
>>> str.index('a')
0
>>> str.rindex('a')
4
count()
返回一个字符串作为子串在当前字符串中出现的次数
split()
str.split(str="", num=string.count(str)).
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。分割num次生成num+1个子串。默认为 -1, 即分隔所有。
当不指定分隔符时,采取默认的空白字符(上方提到的),切分结果中的空字符会被自动删除
指定分隔符时,空字符不会被删除
partition()
根据指定的分隔符将字符串进行分割,返回一个3元的元组
- 如果分割符在待分割字符串中,那么第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串
- 如果分隔符不在待分割字符串中,那么第一个为原字符串,第二个和第三个为空字符串
str = 'abc'
>>> str.partition('a')
('', 'a', 'bc')
>>> str.partition('b')
('a', 'b', 'c')
>>> str.partition('c')
('ab', 'c', '')
>>> str.partition('d')
('abc', '', '')
upper(), lower(), swapcase()
upper(): 小写字母转大写字母
lower(): 大写字母转小写字母
swapcase(): 将大小写字母进行颠倒,小写->大写,大写->小写
>>> str = "i AM 0x7f"
>>> str.swapcase()
'I am 0X7F'
ljust() 和 rjust()
ljust(): 返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串
rjust():返回一个原字符串右对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串
>>> str = '!abc'
>>> str.ljust(6, '*')
'!abc**'
>>> str.rjust(6, '*')
'**!abc'
maketrans() 和 translate()
maketrans(): 创建字符映射的转换表。第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。两个字符串的长度必须相同,为一一对应的关系
translate(): 根据maketrans()生成的转换表,将字符串中的响应字符进行转换
# 这里如果不通过字符串调用maketrans,就需要导入相应模块,哪个字符串调用都无所谓
>>> table = ''.maketrans('abcw', 'xyzc')
>>> 'Hellow world'.translate(table)
'Helloc corld'
replace()
string.replace(old, new, count)
不要求全字匹配,子串即可
strip(), lstrip() 和 rstrip()
3种方法提供的字符串可以是一个字符,或者多个字符,匹配时不是按照整个字符串匹配的,而是一个个匹配的
strip():移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。方法只能删除开头或是结尾的字符,不能删除中间部分的字符
>>> 'aaasdfaaas'.strip("as")
'df'
lstrip(): 截掉字符串左边的空格或指定字符
>>> 'aaasdfaaas'.lstrip('as')
'dfaaas'
rstrip(): 删除 string 字符串末尾的指定字符(默认为空格)
>>> 'aaasdfaaas'.rstrip("as")
'aaasdf'
isalnum(), isalpha() 和 isdigit()
isalnum(): 检测字符串是否由字母和数字组成
返回值:
- True:如果所有的字符均是字母或数字
- False:如果一个或多个字符不是字母和数字
isalpha(): 检测字符串是否只由字母组成
isdigit(): 检测字符串是否只由数字组成
encode() 和 decode()
默认均为utf-8编码
编码:str.encode(encoding='UTF-8',errors='strict')
解码:str.decode(encoding='UTF-8',errors='strict')
compress() 和 decompress()
zlib.compress(): 字符串压缩
zlib.decompress(): 字符串解压缩
正则表达式re
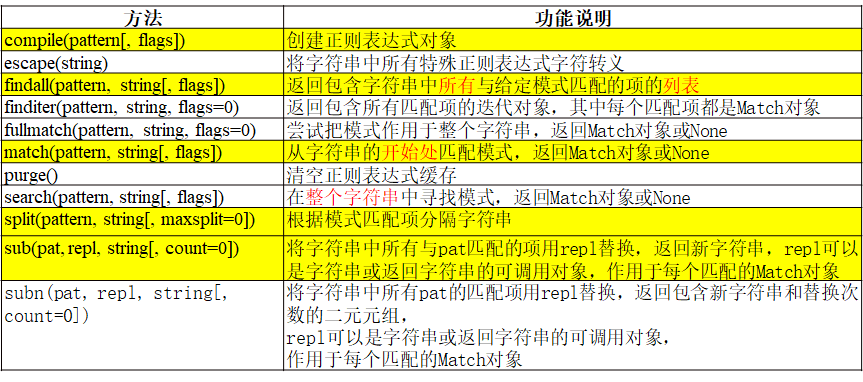
re.match()
从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
re.match(pattern, string, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
| 匹配成功re.match方法返回一个匹配的对象,否则返回None |
# 在起始位置匹配
>>> print(re.match('www', 'www.runoob.com').span())
(0, 3)
# 不在起始位置匹配
>>> print(re.match('com', 'www.runoob.com'))
None
re.search()
扫描整个字符串并返回第一个成功的匹配,未找到则返回None
re.search(pattern, string, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
# 在起始位置匹配
>>> print(re.search('www', 'www.runoob.com').span())
(0, 3)
# 不在起始位置匹配
print(re.search('com', 'www.runoob.com').span())
(11, 14)
re.findall() 与 re.search()的差异
>>> re.search(r'\w*?(?P<f>\b\w+\b)\s+(?P=f)\w*?', 'Beautiful is is better than ugly.').group(0)
'is is'
>>> re.search(r'\w*?(?P<f>\b\w+\b)\s+(?P=f)\w*?', 'Beautiful is is better than ugly.').group(1)
'is'
>>> re.findall(r'\w*?(?P<f>\b\w+\b)\s+(?P=f)\w*?', 'Beautiful is is better than ugly.')
['is']
search任何时候都将整个正则视为一个分组,group(0),这也是search的默认返回结果,其他括号也都算一个分组可通过group(index)方法来获取对应分组的匹配结果;
findall在没有括号时将整个正则视为一个分组,有括号时只认括号内的分组,仅仅匹配分组里面的内容,然后返回这个组的列表; 如果有多个分组,那就把每一个分组看成一个单位,组合为一个元组,然后返回一个含有多个元组的列表。如果想要在使用findall()时将整个正则表达式视为分组,把小括号仅作为一个整体来匹配,可以采用非捕获分组
re.sub()
re.sub(pattern, repl, string, count=0, flags=0)
替换字符串中的匹配项,如果匹配项没有找到,则不加改变地返回 string
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
>>> re.sub('\d', '1', 'a12345bbbb67c890d0e')
'a11111bbbb11c111d1e'
# 注意默认采用的是贪婪模式,因此会尽可能多的进行匹配,所以连着的数字就被匹配为1个元素了
>>> re.sub('\d+', '1', 'a12345bbbb67c890d0e')
'a1bbbb1c1d1e'
re.compile()
re.compile(pattern, flags=0)
编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
- pattern : 一个字符串形式的正则表达式
- flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I(IGNORECASE) 忽略大小写
- re.L(LOCALE) 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M(MULTILINE) 多行模式
- re.S(DOTALL) 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U(UNICODE) 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X(VERBOSE) 为了增加可读性,忽略空格和 # 后面的注释
>>> pattern = re.compile('\d+')
>>> m = pattern.match('123abc')
>>> m
<_sre.SRE_Match object; span=(0, 3), match='123'>
模块
模块的作用
- 提高代码可维护性
- 提高代码可重用性
重新导入一个模块,使用imp模块的reload函数
在导入模块时,会优先导入相应的pyc文件,如果相应的pyc文件与py文件时间不相符,则导入py文件并重新编译该模块
导入模块时的文件搜索顺序
在 import 导入 module 时,会遵循以下的优先级进行搜索
- 当前文件夹
- sys.path变量指定的文件夹
- 优先导入pyc文件
我们可以通过如下的方式来查看目前的 module 的搜索路径以及某个具体的 module 所在的路径
>>> from sys import path
>>> path
['', '/home/user', '/home/user/miniconda3/lib/python39.zip', '/home/user/miniconda3/lib/python3.9', '/home/user/miniconda3/lib/python3.9/lib-dynload', '/home/user/miniconda3/lib/python3.9/site-packages']
>>> import pip
>>> pip
<module 'pip' from '/home/user/miniconda3/lib/python3.9/site-packages/pip/__init__.py'>
有两种方式修改导入 module 的搜索路径 [1]
- 通过
sys.path.append() - 通过
PYTHONPATHenvironment variable
在使用这两种方式指定搜索路径后,即可直接通过 import 引入指定目录下的 module
代码规范性
检查工具:pep8工具,flake8,pylint
包
包是一个包含__init__.py文件的文件夹
打包工具:py2exe,pyinstaller,cx_Freeze
函数的设计与使用
- 参数传递传的是引用而非值
def add(x):
a = x
print(id(a))
a += 1
print(id(a))
y = 5
print(id(y))
add(y)
结果:
1409066208
1409066208
1409066240
如果实参为序列对象,在函数内部采用序列对象原地操作的方法就可以实现通过形参修改实参了
2. 参数类型:普通参数,默认值参数,关键参数,可变长度参数
- 默认值参数必须出现在函数参数列表的最右端,任何一个默认值参数右边不能有非默认值参数
- 可变长度参数
*parameter用来接收多个位置实参并将其放在元组中
parameter接收多个关键参数**并存放到字典中
def fun1(*x):
print(x)
def fun2(**x):
print(x)
fun1(1, 2, 3)
fun2(a = 1, b = 2, c = 3)
结果:
(1, 2, 3)
{'a': 1, 'b': 2, 'c': 3}
- 对字典进行两次解包后参数传递 <=> 关键参数传递
def fun(a, b):
print(a, b)
dic = {'a':1, 'b':2}
fun(**dic)
fun(a = 1, b = 2)
结果:
1 2
1 2
4.当函数执行结束后,局部变量自动删除
5.nonlocal:闭包作用域变量,nonlocal声明的变量会引用距离最近的非全局作用域的变量,用于内部函数中使用外部函数的局部变量
7. 如何理解yield创建生成器对象
6. 修饰器(decorator,包装器),本质上也是一个函数,只不过这个函数接收其他函数作为参数并对其进行一定的改造之后返回新函数。(函数即对象)
面向对象程序设计
- OOP支持代码复用 和 设计复用
- 基本原则:计算机程序由多个能够起到子程序作用的单元或对象组合而成
- 基本功能:封装,继承,多态,对基类方法的重写
- 类包含:数据成员(用变量表示的对象属性),成员方法(用函数表示的对象行为)
- 类名的首字母一般要大写
- Python 类中属性和方法所在的位置是任意的
- 类的所有实例方法都必须至少有一个名为self的参数,且必须是方法的第一个形参
- 混入机制(mixin):可以动态地为自定义类和对象增加或删除成员
- 实例对象仅可以访问类变量,无法修改,修改实际是在定义新的实例变量; 实例变量和类变量重名时, 实例对象会首选实例变量
class T :
val = 5
t = T()
print(t.val)
t.val = 3
print(t.val)
t2 = T()
T.val = 4
print(t.val)
print(t2.val)
结果:
5
3
3
4
11.如果数据成员为容器类对象,则通过实例修改和通过类修改,所有实例均会发生改变
class T :
val = [0]
t = T()
t2 = T()
print(t.val)
print(t2.val)
t.val[0] = 1
print(t.val)
print(t2.val)
T.val[0] = 2
print(t.val)
print(t2.val)
结果:
[0]
[0]
[1]
[1]
[2]
[2]
12.函数和方法的区别在于方法具有第一个隐式参数self
13.
_xxx:受保护成员,不能用'from module import *'导入;
__xxx__:系统定义的特殊成员;
__xxx:私有成员(>=2个‘_’开头的数据成员),只有类对象自己能访问,子类对象不能直接访问到这个成员,但在对象外部可以通过“对象名._类名__xxx”这样的特殊方式来访问。
14.类中方法:公有方法,私有方法,静态方法(@staticmethod),类方法(@classmethod)
静态方法和类方法只能访问类的成员
15.@property,保护类的封装特性
class T :
def __init__(self, val):
self.__val = val
@property
def getVal(self) :
return self.__val
t = T(5)
print(t.getVal) # @property修饰,不需要加()
结果:5
16.特殊方法
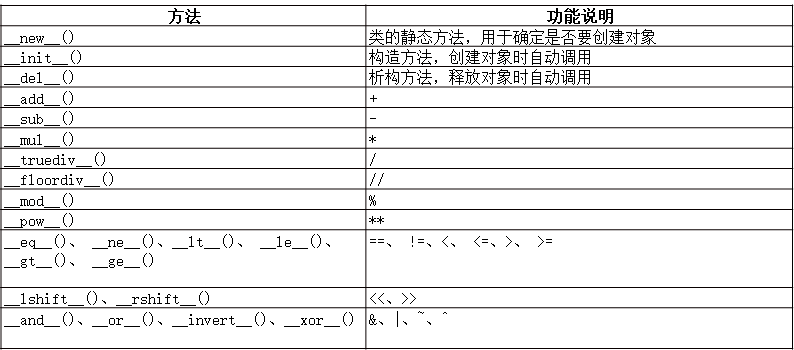
17.
多态的定义:基类的同一个方法在不同派生类对象中具有不同的表现和行为
多态的前提条件:1.继承:发生在子类和父类之间 2.重写:子类重写父类方法
简答题
简单解释 Python 基于值的自动内存管理方式
在 Python 中可以为不同变量赋值为相同值,这个值在内存中只有一份,多个变量指向同一个内存地址;
Python 具有自动内存管理功能,会自动跟踪内存中所有的值,对于没有任何变量指向的值,Python 自动将其删除。
Python 运算符&的两种功能
- 数字位运算
- 集合交集运算
Python 中导入模块中的对象的几种方式
- import 模块名 [as 别名]
- from 模块名 import 对象名 [as 别名]
- from 模块名 import *
1与3的区别在于,对于模块内的方法名,1需要以模块名为前导,3则可以直接使用
>>> sqrt(4.0)
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
sqrt(4.0)
NameError: name 'sqrt' is not defined
>>> import math
>>> sqrt(4.0)
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
sqrt(4.0)
NameError: name 'sqrt' is not defined
>>> math.sqrt(4.0)
2.0
>>> from math import *
>>> sqrt(4.0)
2.0
解释 Python 脚本程序的“name”变量及其作用
每个 Python 脚本在运行时都有一个“name”属性。
如果脚本作为模块被导入,则其“name”属性的值被自动设置为模块名;
如果脚本独立运行,则其“name”属性值被自动设置为“main”。
利用“name”属性即可控制 Python 程序的运行方式。
为什么应尽量从列表的尾部进行元素的增加与删除操作
当列表增加或删除元素时,列表对象自动进行内存扩展或收缩,从而保证元素之间没有缝隙,
但这涉及到列表元素的移动,效率较低,应尽量从列表尾部进行元素的增加与删除操作以提高处理速度。
析逻辑运算符“or”的短路求值特性
假设有表达式“表达式 1 or 表达式 2”,
如果表达式 1 的值等价于 True,那么无论表达式 2 的值是什么,整个表达式的值总是等价于 True。
因此,不需要再计算表达式 2 的值。
简单解释 Python 中短字符串驻留机制
对于短字符串,将其赋值给多个不同的对象时,内存中只有一个副本,多个对象共享改副本。
异常和错误有什么区别
异常是指因为程序执行过程中出错而在正常控制流以外采取的行为。
严格来说,语法错误和逻辑错误不属于异常,但有些语法错误往往会导致异常,
例如由于大小写拼写错误而访问不存在的对象,或者试图访问不存在的文件,等等。
使用 pdb 模块进行 Python 程序调试主要有哪几种用法
- 在交互模式下使用 pdb 模块提供的功能可以直接调试语句块、表达式、函数等多种脚本。
- 在程序中嵌入断点 来实现调试功能。在程序中首先导入 pdb 模块,然后使用 pdb.set_trace()在需要的位置设置断点。
如果程序中存在通过该方法调用显式插入的断点,那么在命令提示符环境下执行该程序或双击执行程序时将自动打开 pdb 调试环境,即使该程序当前不处于调试状态。 - 使用命令行调试程序。在命令行提示符下执行“python –m pdb 脚本文件名”,则直接进入调试环境;当调试结束或程序正常结束以后,pdb 将重启该程序。
文件操作
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
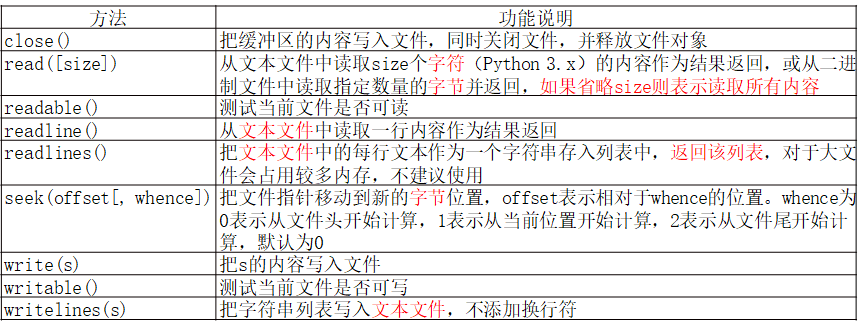
- 文件对象常用方法
2.序列化:把内存中的数据在不丢失其类型信息的情况下转成对象的二进制形式的过程
常用的序列化模块有struct、pickle、marshal和shelve
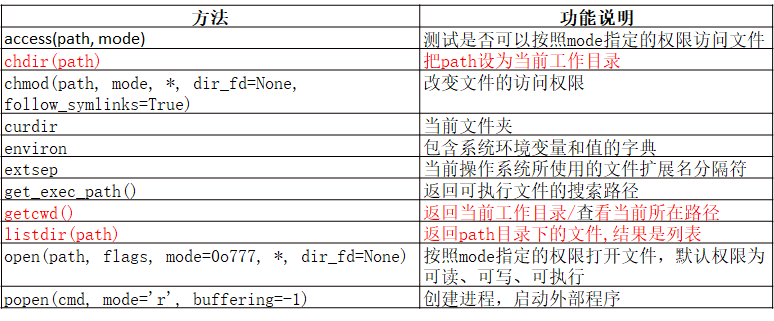
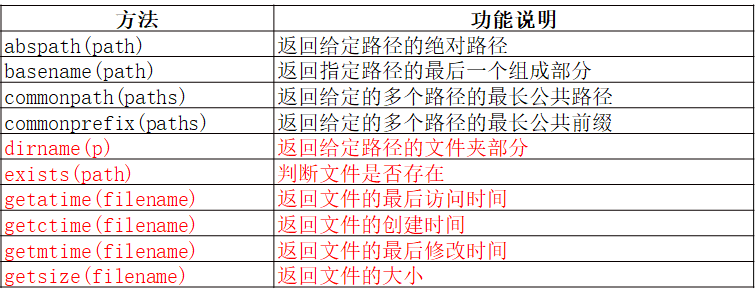
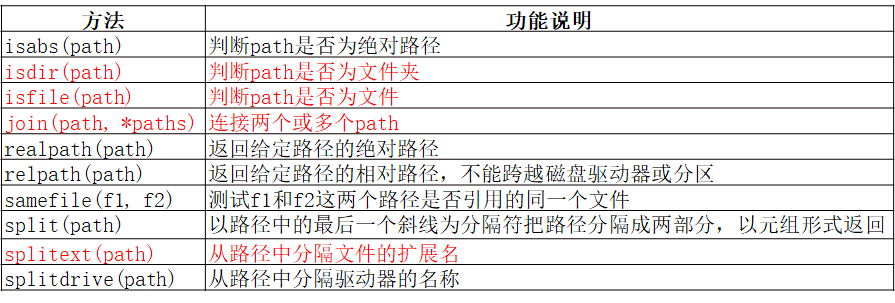
- os模块 和 os.path模块 常用方法
- os模块
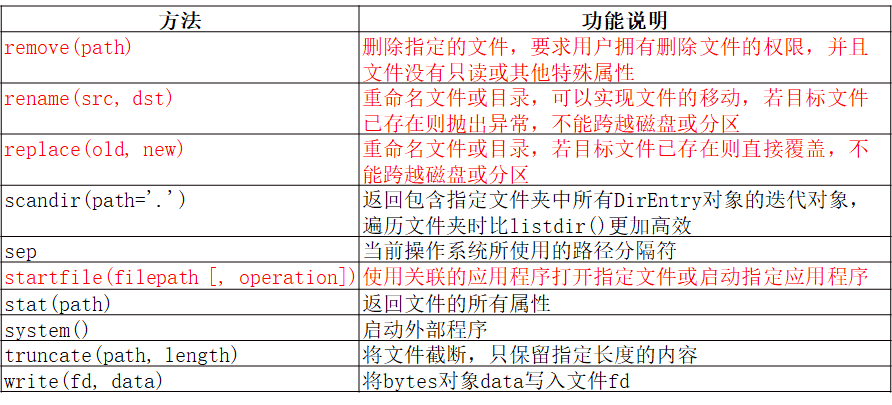
- os.path模块


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理