


redis详解
https://www.cnblogs.com/wyy123/p/6078593.html
⑤⑥⑦⑧⑨⑩
1.redis是一个可基于内存也可持久化的非关系型数据库,以key-value的形式存储数据。默认端口号是6379
2.key-value的讲解:
一.value支持5中数据类型:字符串strings,字符串列表lists,字符串集合sets,有序集合sorted sets,哈希hashes
①Strings类型:即最基本的字符串,存储字符串类型
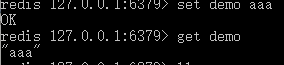

遇到数字类型的字符串,可以自动转换成数字,并且可以自增自减
由于INCR等指令本身就具有原子操作的特性,所以我们完全可以利用redis的INCR、INCRBY、DECR、DECRBY等指令来实现原子计数的效果,假如,在某种场景下有3个客户端同时读取了mynum的值(值为2),然后对其同时进行了加1的操作,那么,最后mynum的值一定是5。不少网站都利用redis的这个特性来实现业务上的统计计数需求。
②lists数据类型:
其底层实现是链表形式,增删数据比较快,查询数据比较慢。提供了lpush(从左侧插入),rpush(从右侧插入)和lrange(范围查询)的方法
lists的应用相当广泛,随便举几个例子:
1.我们可以利用lists来实现一个消息队列,而且可以确保先后顺序,不必像MySQL那样还需要通过ORDER BY来进行排序。
2.利用LRANGE还可以很方便的实现分页的功能。
3.在博客系统中,每片博文的评论也可以存入一个单独的list中。
二.key的长度也不要过长,否则影响查询效率.key就是一个名字的作用,可以随便取名,有意义即可
③sets和zsets:无序集合和有序集合.和java类似,通过一个变量名来操作一堆数据,相当于存在了集合里
④哈希:即存的是一个对象 hmset 对象名 属性名 值 属性名 值 ......
3.redis单线程机制:客户端发送的命令,到达服务端执行,多个客户端发送的命令到达服务端后,不会立即执行,而是存入一个队列中,一条一条执行,所以redis不会出现并发的问题。
4.redis持久化:
两种方式:rdb和aof
持久化:将redis中存的数据写入磁盘,当redis重新启动时,再从磁盘读到redis中去,
rdb:定时的将redis中的数据写入磁盘,是一种快照式的持久化方式。生成rdb文件它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
aof:
英文是Append Only File,即只允许追加不允许改写的文件。
如前面介绍的,AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍,就这么简单。
这种持久化的打开方式是在配置文件redis.conf中将appendonly设置成yes即可。aof默认每秒钟就追加一次写操作
持久化详解:https://www.cnblogs.com/anjijiji/p/6164615.html
5.redis集群部署:
6.本地虚拟机linux系统,redis装在/usr/local/redis下,在linux中启动redis分为前台启动和后台启动,
前台启动:
如上图,为前台启动,无法部署集群
后台启动:
l 修改redis.conf配置文件,daemonize yes 以后端模式启动。
启动命令:
./bin/redis-server ./redis.conf
7.redis通用操作:
keys 通配符
*代表0到多个任意字符
?代表1个任意字符
del key1 key2 …删除键值对
exists key:判断该key是否存在,1代表存在,0代表不存在
type key:获取指定key的类型。该命令将以字符串的格式返回。 返回的字符串为string、list、set、hash和zset,如果key不存在返回none。
expire key 秒:设置过期时间,单位:秒。
注意:如果某个key过期,这个key就会被redis删除
ttl key:获取该key所剩的超时时间,如果没有设置超时,返回-1。如果返回-2表示超时不存在。
Redis数据库固定好的,一共有16个数据库。0~15
默认使用的是0号数据库。
select 数据库号码
如何把某个键值对移植到另外一个数据库中呢?
move key数据库号码
例如:用户模块0号
订单模块 1号
合同模块 2号

