


Note3 :《集体智慧编程》用户相似度计算
欧几里德距离评价:

以经过人们一致评价的物品为坐标轴,然后将参与评价的人绘制到图上,并考察他们彼此之间的距离远近。计算出每一轴向上的差值,求平方之后再相加,最后对总和取平方根。
# -*- coding: UTF-8 -*- #一个涉及影评者及其对几部影片评分情况的字典 critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5, 'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5, 'The Night Listener': 3.0}, 'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5, 'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0, 'You, Me and Dupree': 3.5}, 'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0, 'Superman Returns': 3.5, 'The Night Listener': 4.0}, 'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0, 'The Night Listener': 4.5, 'Superman Returns': 4.0, 'You, Me and Dupree': 2.5}, 'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0, 'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0, 'You, Me and Dupree': 2.0}, 'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0, 'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5}, 'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}} from math import sqrt #返回一个有关person1与person2的基于距离的相似度评价 def sim_distance (prefs,person1,person2): #得到shared_items的列表 si={} for item in prefs[person1]: for item in prefs[person2]: si[item]=1 #如果两者没有共同之处,则返回0 if len(si)==0: return 0 #计算所有差值的平方和 sum_of_squares=sum([ pow(prefs[person1][item]-prefs[person2][item],2) for item in prefs[person1] if item in prefs[person2]]) return 1/(1+sqrt(sum_of_squares)) print(sim_distance(critics,'Lisa Rose','Gene Seymour'))
皮尔逊相关度评价:

Mick Lasalle为《Superman》评了3分,而Gene Seyour则评了5分,所以该影片被定位中图中的(3,5)处。在图中还可以看到一条直线。
皮尔逊相关系数是判断两组数据与某一直线拟合程度的一种度量。
通常情况下:
相关系数0.8-1.0为极强相关
0.6-0.8为强相关
0.4-0.6为中等程度相关
0.2-0.4为弱相关
0.0-0.2为极弱相关或无相关
最佳拟合线:尽可能地靠近图上的所有坐标点。
修正“夸大分值”情况。
皮尔逊积差系数:
数学特征:
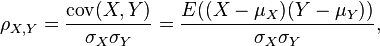
因为μX = E(X),σX2 = E(X2) − E2(X),同样地,对于Y,可以写成

当两个变量的标准差都不为零,相关系数才有定义。从柯西—施瓦茨不等式可知,相关系数不超过1. 当两个变量的线性关系增强时,相关系数趋于1或-1。当一个变量增加而另一变量也增加时,相关系数大于0。当一个变量的增加而另一变量减少时,相关系数小 于0。当两个变量独立时,相关系数为0.但反之并不成立。 这是因为相关系数仅仅反映了两个变量之间是否线性相关。比如说,X是区间[-1,1]上的一个均匀分布的随机变量。Y = X2. 那么Y是完全由X确定。因此Y 和X是不独立的。但是相关系数为0。或者说他们是不相关的。当Y 和X服从联合正态分布时,其相互独立和不相关是等价的。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一: 
公式二: 
公式三: 
公式四: 
以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
利用公式一代码:
# -*- coding: UTF-8 -*- #一个涉及影评者及其对几部影片评分情况的字典 critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5, 'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5, 'The Night Listener': 3.0}, 'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5, 'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0, 'You, Me and Dupree': 3.5}, 'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0, 'Superman Returns': 3.5, 'The Night Listener': 4.0}, 'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0, 'The Night Listener': 4.5, 'Superman Returns': 4.0, 'You, Me and Dupree': 2.5}, 'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0, 'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0, 'You, Me and Dupree': 2.0}, 'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0, 'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5}, 'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}} from math import sqrt #返回p1和p2的皮尔逊相关系数 def sim_pearson(prefs,p1,p2): #得到双方都曾评价过的物品列表 si={} for item in prefs[p1]: if item in prefs[p2]: si[item]=1 #得到列表元素的个数 n=len(si) #如果两人没有共同之处,则返回0 if n==0: return 0 #对所有偏好求和 sum1=sum([prefs[p1][it] for it in si]) sum2=sum([prefs[p2][it] for it in si]) #求平方和 sum1Sq=sum([pow(prefs[p1][it],2) for it in si]) sum2Sq=sum([pow(prefs[p2][it],2) for it in si]) #求乘积之和 pSum=sum([prefs[p1][it]*prefs[p2][it] for it in si]) #计算皮尔逊评价值 num=pSum/n-(sum1*sum2)/(n*n) den=sqrt((sum1Sq/n-pow(sum1,2)/(n*n))*(sum2Sq/n-pow(sum2,2)/(n*n))) if den==0: return 0 r=num/den return r print(sim_pearson(critics,'Lisa Rose','Gene Seymour'))

