hadoop2集群环境搭建
在查询了很多资料以后,发现国内外没有一篇关于hadoop2集群环境搭建的详细步骤的文章。
所以,我想把我知道的分享给大家,方便大家交流。
以下是本文的大纲:
1. 在windows7 下面安装虚拟机
2.在虚拟机上面安装linux操作系统
3.启动Linux操作系统
4.修改hostname
4.1.在node1上面修改hostname
4.2.在node2上面修改hostname
4.3.在node3上面修改hostname
4.4.在node4上面修改hostname
4.5.重启4台机器,hostname会永久生效
5.安装JDK
6.免密码登录
7.Linux域名解析配置
8.Windows域名解析配置
9.节点分布方案
10.zookeeper的解压缩和安装
11.Hadoop压缩包安装
11.1.修改hadoop-evn.sh
11.2.修改hdfs-site.xml
11.3.修改core-site.xml
11.4.配置datanode
12.在node2, node3, node4上安装hadoop
13.启动JournalNodes
14.在第一个namenode(node1)上面进行格式化操作并启动namenode
15.拷贝拷贝元数据文件到第二个namenode
16.格式化zookeeper
17.停止所有服务
18.配置mapreduce
19.启动所有服务
20.测试是否成功
21.上传文件测试
若有不正之处,还请多多谅解,并希望批评指正。
请尊重作者劳动成果,转发请标明blog地址
https://www.cnblogs.com/hongten/p/hongten_hadoop.html
正所谓磨刀不费砍材功,下面的工具大家可以先下载备用。
环境及工具:
Windows 7 (64位)下面的虚拟机(64位):VMware-workstation-full-14.0.0-6661328.exe
Linux操作系统:CentOS-6.5-x86_64-bin-DVD1.iso
Xshell:Xshell-6.0.0101p.exe
WinSCP:从windows上面上传文件到Linux
zookeeper:zookeeper-3.4.6.tar.gz
hadoop:hadoop-2.5.1_x64.tar.gz
链接:https://pan.baidu.com/s/1hvdbGUh488Gl1EF2v44BIw
提取码:ncdd
在做好准备工作后,我们就可以来手动搭建hadoop集群
1. 在windows7 下面安装虚拟机
安装说明已经激活码请点击上面虚拟机链接。
*注:上述链接提供的安装包仅支持Windows 7及以上操作系统的64位版,已经不支持32位版的操作系统!
激活码:FF31K-AHZD1-H8ETZ-8WWEZ-WUUVA
2.在虚拟机上面安装linux操作系统
这里我把RedHat,Ubuntu,CentOS都安装过了,最后感觉CentOS好用一点(个人觉得,哈哈哈)
CentOS-6.5-x86_64-bin-DVD1.iso After the installation is complete, please run "yum update" in order to update your system.
安装好Linux后,需要运行 'yum update' 命令。这里是需要花一点时间的,(我花了大概十多分钟的样子来执行yum update)。

在虚拟机里面,我安装了4台相同配置的CentOS。
3.启动Linux操作系统
在虚拟机里面启动4台机器。然后都以root账号进行登录。
启动完以后,我们要记录各个node(节点)ip地址(下面是我机器上面的ip地址情况)
//四台Linux的ip地址 192.168.79.133 node1 192.168.79.134 node2 192.168.79.135 node3 192.168.79.136 node4
*注:在Linux里面查看ip的命令是ifconfig
//在node4上面的ip地址情况 [root@node4 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:80:01:39 inet addr:192.168.79.136 Bcast:192.168.79.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe80:139/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:201532 errors:0 dropped:0 overruns:0 frame:0 TX packets:27023 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:275203684 (262.4 MiB) TX bytes:4283436 (4.0 MiB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:18 errors:0 dropped:0 overruns:0 frame:0 TX packets:18 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1064 (1.0 KiB) TX bytes:1064 (1.0 KiB) You have new mail in /var/spool/mail/root
4.修改hostname
刚开始的时候,我们在4台机器上看到的都是如下的hostname
[root@localhost ~]
我们现在要把他们修改为
[root@node1 ~] [root@node2 ~] [root@node3 ~] [root@node4 ~]
我们为什么要修改hostname呢?
因为我们要在下面的配置文件里面添加这些节点名称,如node1,node2,node3, node4.
那么我们应该怎样做呢?下面给出了方法。
4.1.在node1上面修改hostname
--http://www.cnblogs.com/kerrycode/p/3595724.html(深入理解Linux修改hostname) --在node1上面运行 vi /etc/sysconfig/network --设置hostname=node1 :qw --再运行 sysctl kernel.hostname=node1
4.2.在node2上面修改hostname
--http://www.cnblogs.com/kerrycode/p/3595724.html(深入理解Linux修改hostname) --在node2上面运行 vi /etc/sysconfig/network --设置hostname=node2 :qw --再运行 sysctl kernel.hostname=node2
4.3.在node3上面修改hostname
--http://www.cnblogs.com/kerrycode/p/3595724.html(深入理解Linux修改hostname) --在node3上面运行 vi /etc/sysconfig/network --设置hostname=node3 :qw --再运行 sysctl kernel.hostname=node3
4.4.在node4上面修改hostname
--http://www.cnblogs.com/kerrycode/p/3595724.html(深入理解Linux修改hostname) --在node4上面运行 vi /etc/sysconfig/network --设置hostname=node4 :qw --再运行 sysctl kernel.hostname=node4
4.5.重启4台机器,hostname会永久生效
*注:在Linux里面查看ip情况,看看是否有变化。如果有变化,则调整相应的ip所对应的节点。
--我虚拟机里面的ip情况 192.168.79.133 node1 192.168.79.134 node2 192.168.79.135 node3 192.168.79.136 node4
5.安装JDK
把我们下载好的jdk-7u67-linux-x64.rpm通过WinSCP上传到4台机器的根目录上。
--在node1, node2, node3, node4上面安装jdk --install JDK -- http://blog.51cto.com/vvxyz/1642258(LInux安装jdk的三种方法) --解压安装 rpm -ivh your-package.rpm --修改环境变量 vi /etc/profile JAVA_HOME=/usr/java/jdk1.7.0_67 JRE_HOME=/usr/java/jdk1.7.0_67/jre CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JRE_HOME CLASS_PATH PATH :wq --使配置有效 source /etc/profile
*注:在4个节点上都要安装JDK。
6.免密码登录
--免密码登录 --分别在node1, node2, node3, node4,上面运行 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys --在node1上面运行,拷贝node1的公钥到node2,node3,node4上面的根目录里面去 scp id_rsa.pub root@node2:~ scp id_rsa.pub root@node3:~ scp id_rsa.pub root@node4:~ --分别进入node2, node3, node4运行,把node1的公钥追加到~/.ssh/authorized_keys文件里面 cat ~/id_rsa.pub >> ~/.ssh/authorized_keys --测试 --在node1上面运行下面命令,应该都能够免密码登录,即成功。
ssh node1 ssh node2 ssh node3 ssh node4
*注:我在这里遇到很多坑,最后还是搞定了。
7.Linux域名解析配置
--修改域名解析conf hosts --在node1上面运行下面命令 vi /etc/hosts --根据自己机器上面的ip进行配置 192.168.79.134 node1 192.168.79.135 node2 192.168.79.133 node3 192.168.79.136 node4 :wq --copy hosts file to node2, node3, node4 scp /etc/hosts root@node2:/etc/ scp /etc/hosts root@node3:/etc/ scp /etc/hosts root@node4:/etc/
8.Windows域名解析配置
--windows 域名解析 --打开C:/WINDOWS/system32/drivers/etc/hosts文件 --把下面的信息复制到文件最后尾 -- 根据自己机器ip进行配置 192.168.79.134 node1 192.168.79.135 node2 192.168.79.133 node3 192.168.79.136 node4
为什么要做这个呢?
因为下面我们会在浏览器里面输入http:node1:50070进行测试,就会用到这个配置了。
9.节点分布方案

*注:打钩的表示在该节点上有相对应的服务。
10.zookeeper的解压缩和安装
--解压zookeeper压缩包并安装 tar -zxvf zookeeper-3.4.6.tar.gz --创建zookeeper的软链 ln -sf /root/zookeeper-3.4.6 /home/zk --配置zookeeper cd /home/zk/conf/ --把下面的zoo_sample.cfg文件重新命名 cp zoo_sample.cfg zoo.cfg --修改zoo.cfg配置文件 vi zoo.cfg --设置zookeeper的文件存放目录 --找到dataDir=/tmp/zookeeper,并设置为下面值 dataDir=/opt/zookeeper --设置zookeeper集群 server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888 :wq --创建/opt/zookeeper目录 mkdir /opt/zookeeper --进入/opt/zookeeper目录 cd /opt/zookeeper --创建一个文件myid vi myid --输入1 1 :wq --以此类推,在node2,node3,值分别是2, 3 --拷贝zookeeper目录到node2, node3的/opt/目录下面 cd .. scp -r zookeeper/ root@node2:/opt/ scp -r zookeeper/ root@node3:/opt/ --分别进入到node2, node3里面,修改/opt/zookeeper/myid,值分别是2, 3 --作为以上配置,把node1里面的zookeeper拷贝到node2, node3上面。 scp -r zookeeper-3.4.6 root@node2:~/ scp -r zookeeper-3.4.6 root@node3:~/ --分别进入到node2, node3里面,创建软链 ln -sf /root/zookeeper-3.4.6/ /home/zk --配置zookeeper环境变量 cd /home/zk/bin --修改/etc/profile文件,把zookeeper的bin目录路径添加进去 vi /etc/profile PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:/home/zk/bin --让配置文件生效 source /etc/profile --分别进入到node2, node3里面,修改/etc/profile文件,把zookeeper的bin目录路径添加进去 --作为环境变量配置,就可以启动zookeeper了。 --分别在node1, node2, node3上面启动zookeeper zkServer.sh start --测试是否启动成功 jps --观察是否有QuorumPeerMain进程
注:这里一定要让Zookeeper启动着。
11.Hadoop压缩包安装
--解压Hadoop压缩包安装 --在node1上面安装 tar -zxvf hadoop-2.5.1_x64.tar.gz --解压完,创建一个软链到home目录下面 ln -sf /root/hadoop-2.5.1 /home/hadoop-2.5 --进入hadoop中进行文件配置 cd /home/hadoop-2.5/etc/hadoop/
11.1.修改hadoop-evn.sh
--1.修改hadoop-evn.sh --修改JAVA_HOME配置 vi hadoop-env.sh --The java implementation to use. 根据上面JDK的配置信息 export JAVA_HOME=/usr/java/jdk1.7.0_67
:wq
11.2.修改hdfs-site.xml
--2.修改hdfs-site.xml vi hdfs-site.xml --2.1.配置dfs.nameservices - the logical name for this new nameservice --服务名称 <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> --2.2.配置namenode节点名称。这里的名称是namenode的名称,不是主机名(hostname)。 <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> --2.3.配置RPC协议和端口 --有多少namenode,就需要配置多少次。 <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> --2.4.配置HTTP协议和主机 --这里也是针对上面的namenode --有多少namenode,就需要配置多少次。 <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2:50070</value> </property> --2.5.配置dfs.namenode.shared.edits.dir --the URI which identifies the group of JNs(JournalNodes) where the NameNodes will write/read edits <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node2:8485;node3:8485;node4:8485/mycluster</value> </property> --2.6.配置客户端使用的一个类,固定配置 --作用:客户端使用该类去找到active namenode <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> --2.7.配置sshfence --这里配置的私钥路径,是根据上面免密登录设置的路径 --ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> --2.8.配置JournalNodes的工作目录 <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/jn/data</value> </property> -------- --以上基本配置完成 --下面进行自动切换配置 --2.9.配置自动切换 --自动切换配置好了以后,可以允许手动切换 <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> :wq
下面是完整的配置信息(hdfs-site.xml配置)
<configuration> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node2:8485;node3:8485;node4:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/jn/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
11.3.修改core-site.xml
--修改core-site.xml vi core-site.xml --3.1.配置namenode入口 <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> --3.2.配置ZooKeeper集群 <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> --3.3.修改hadoop的临时目录 <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop2</value> </property> :wq
下面是完整的配置信息(core-site.xml配置)
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop2</value> </property> </configuration>
11.4.配置datanode
cd /home/hadoop-2.5/etc/hadoop/ vi slaves --输入 node2 node3 node4 :wq
*注:以上为hadoop的配置
12.在node2, node3, node4上安装hadnoop
--拷贝hadoop到node2, node3, node4上去 scp hadoop-2.5.1_x64.tar.gz root@node2:~/ scp hadoop-2.5.1_x64.tar.gz root@node3:~/ scp hadoop-2.5.1_x64.tar.gz root@node4:~/ --然后分别进入到node2,node3, node4上面去解压缩文件,分别创建软链 cd ~ tar -zxvf hadoop-2.5.1_x64.tar.gz ln -sf /root/hadoop-2.5.1 /home/hadoop-2.5 --回到node1, 进入到/home/hadoop-2.5/etc/hadoop/目录 cd /home/hadoop-2.5/etc/hadoop/ --把所有配置文件拷贝到node2,node3, node4上面的/home/hadoop-2.5/etc/hadoop/目录下面 --这样做的目的是保证,所有机器上面的配置文件都一样 scp ./* root@node2:/home/hadoop-2.5/etc/hadoop/ scp ./* root@node3:/home/hadoop-2.5/etc/hadoop/ scp ./* root@node4:/home/hadoop-2.5/etc/hadoop/
13.启动JournalNodes
--做完这些后,就可以启动JournalNodes --去到node2, node3, node4 cd /home/hadoop-2.5/sbin/ ./hadoop-daemon.sh start journalnode --检查是否启动成功: jps --检查是否有:JournalNode
14.在第一个namenode(node1)上面进行格式化操作并启动namenode
--在第一个namenode上面进行格式化操作 --进入node1 cd /home/hadoop-2.5/bin
--进入node1,node2,node3,node4关闭防火墙........这一步很关键......
service iptables stop
./hdfs namenode -format --格式化成功后,会在/opt/hadoop2/dfs/name/current/目录下面生成元数据文件 cd /opt/hadoop2/dfs/name/current --需要把元数据文件拷贝到第二个namenode上面去。 --在拷贝之前,需要启动刚刚格式化后的namenode(node1) cd /home/hadoop-2.5/sbin/ ./hadoop-daemon.sh start namenode --查看是否启动成功 jps --检查是否包含:NameNode
15.拷贝拷贝元数据文件到第二个namenode
--然后去到node2上去。要保证第一个(即格式化后的namenode(node1)要先启动--运行着的状态) --执行拷贝元数据文件命令 cd /home/hadoop-2.5/bin/ ./hdfs namenode -bootstrapStandby --检查是否拷贝成功: cd /opt/hadoop2/dfs/name/current/ --查看是否有元数据
ls
16.格式化zookeeper
--格式化zookeeper
cd /home/hadoop-2.5/bin/
./hdfs zkfc -formatZK
注:这里只需要在node1上面进行操作。
17.停止所有服务
--如果都完成,在node1上面 cd /home/hadoop-2.5/sbin/ --停止所有服务 ./stop-dfs.sh
18.配置mapreduce
--配置mapreduce cd /home/hadoop-2.5/etc/hadoop/ --复制/创建mapred-site.xml cp mapred-site.xml.template mapred-site.xml --修改mapred-site.xml vi mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> :wq --修改yarn-site.xml vi yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration> :wq
注:在node1上面修改完后,分发两个xml文件到node2,node3,node4.
19.启动所有服务
--然后启动所有服务,在node1上面 cd /home/hadoop-2.5/sbin/ ./start-all.sh
*注:下面是我机器上面的运行结果
[root@node1 sbin]# ./start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [node1 node2] node1: starting namenode, logging to /root/hadoop-2.5.1/logs/hadoop-root-namenode-node1.out node2: starting namenode, logging to /root/hadoop-2.5.1/logs/hadoop-root-namenode-node2.out node3: starting datanode, logging to /root/hadoop-2.5.1/logs/hadoop-root-datanode-node3.out node2: starting datanode, logging to /root/hadoop-2.5.1/logs/hadoop-root-datanode-node2.out node4: starting datanode, logging to /root/hadoop-2.5.1/logs/hadoop-root-datanode-node4.out Starting journal nodes [node2 node3 node4] node2: starting journalnode, logging to /root/hadoop-2.5.1/logs/hadoop-root-journalnode-node2.out node3: starting journalnode, logging to /root/hadoop-2.5.1/logs/hadoop-root-journalnode-node3.out node4: starting journalnode, logging to /root/hadoop-2.5.1/logs/hadoop-root-journalnode-node4.out Starting ZK Failover Controllers on NN hosts [node1 node2] node2: starting zkfc, logging to /root/hadoop-2.5.1/logs/hadoop-root-zkfc-node2.out node1: starting zkfc, logging to /root/hadoop-2.5.1/logs/hadoop-root-zkfc-node1.out starting yarn daemons starting resourcemanager, logging to /root/hadoop-2.5.1/logs/yarn-root-resourcemanager-node1.out node3: starting nodemanager, logging to /root/hadoop-2.5.1/logs/yarn-root-nodemanager-node3.out node4: starting nodemanager, logging to /root/hadoop-2.5.1/logs/yarn-root-nodemanager-node4.out node2: starting nodemanager, logging to /root/hadoop-2.5.1/logs/yarn-root-nodemanager-node2.out
20.测试是否成功
--打开windows上面的浏览器 --输入: http://node1:50070 --输入: http://node2:50070 --可以看到hadoop启动成功
node运行结果(standby):

node2运行结果(active):

21.上传文件测试
--上传文件测试: cd /home/hadoop-2.5/bin/ --创建上传文件目录 ./hdfs dfs -mkdir -p /usr/file --这里上传的文件是jdk-7u67-linux-x64.rpm ./hdfs dfs -put /root/jdk-7u67-linux-x64.rpm /usr/file --在浏览器上面查看是否上传文件成功。

点击Name
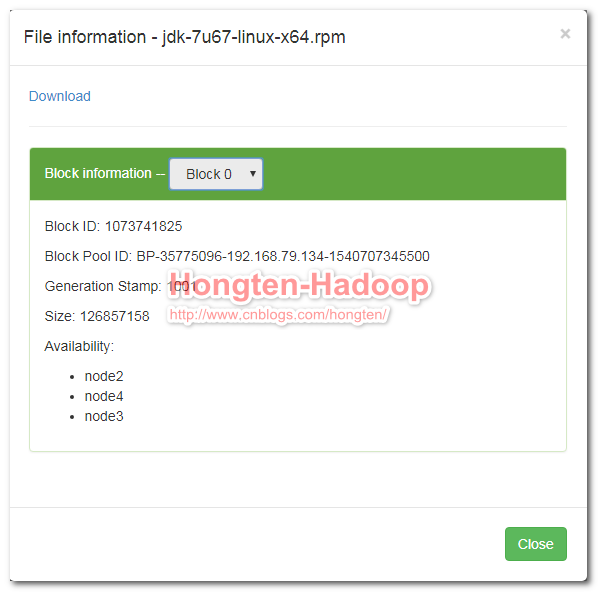
到这里我们的hadoop集群环境成功搭建完成。
========================================================
More reading,and english is important.
I'm Hongten
大哥哥大姐姐,觉得有用打赏点哦!你的支持是我最大的动力。谢谢。
Hongten博客排名在100名以内。粉丝过千。
Hongten出品,必是精品。
E | hongtenzone@foxmail.com B | http://www.cnblogs.com/hongten
========================================================

