写了个学习正则的小工具
背景:感觉自己正则学的不是很好,所以想再学习下,于是就去翻各大框架里的正则,想看看他们是怎么使用正则的,但是一个一个看源代码太长又太麻烦了,所以就想把框架里的所有正则都匹配出来,然后再来集中学习。
这里推荐一个学习正则网站:https://regexr.com/
先看看整个流程:
下面简单讲讲怎么匹配正则的正则:
let re = /([a-zA-Z_]+\s*=\s*)?\/(?=[^*>/])[^\s[/\\]*(?:(?:\\.|\[(?:\\.|[^\]\\]*)*\])[^[\\/]*)*?\/[gimuy]*(?=([ ,;]+))/ig;
我们先看前面部分:
([a-zA-Z_]+\s*=\s*)?\/(?=[^*>/])[^\s[/\\]*
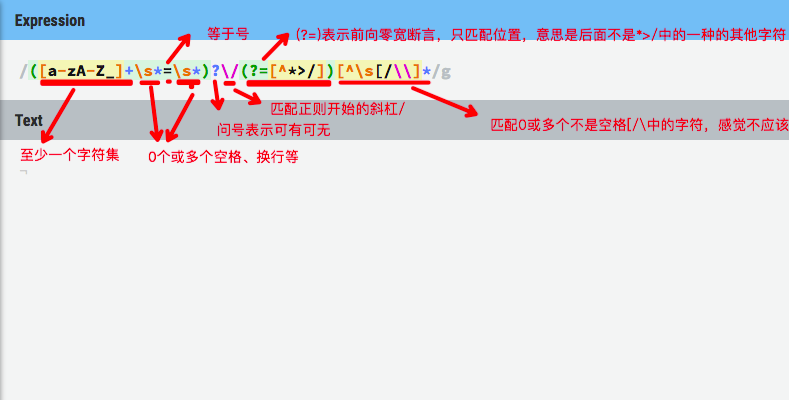
再看后面的:
(?:(?:\\.|\[(?:\\.|[^\]\\]*)*\])[^[\\/]*)*?\/[gimuy]*(?=([ ,;]+))
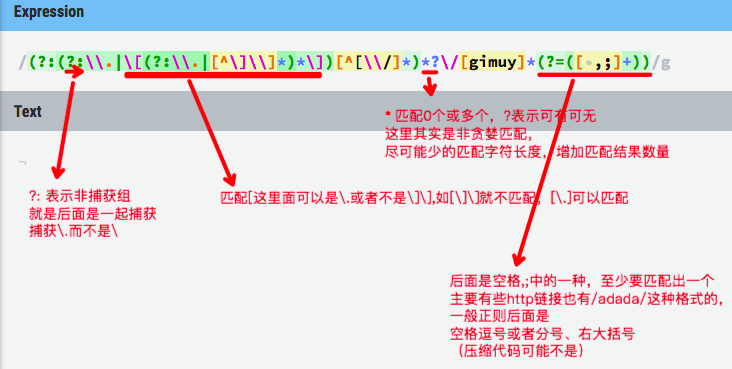
这就是核心,其他的不用多说,希望能帮到大家学习。

