寒假作业2/2
| 这个作业属于哪个课程 | <班级的链接> |
|---|---|
| 这个作业要求在哪里 | <作业要求的链接> |
| 这个作业的目标 | 学习Python语法和基础API,自主完成项目,形成语法规范,对于《构建之法》的再思考 |
| 作业正文 | 项目的开发到结束的详细流程和文档,阅读《构建之法》提出问题并思考 |
| 其他参考文献 | 《构建之法》 《腾讯Cplusplus编码规范》 《Python PEP8》 |
目录:
1. 关于《构建之法》的思考和提问

Question One:团队中的人员能力参差不齐,在一个团队中如何安排才能使每个人在团队中发挥出最大作用?
- 《构建之法》P151页
在第四章中讲述了“结对合作”,虽然文中讲述了代码规范,代码复审,两人合作的技巧等......,但是我有一个疑惑点,在团队开发中每个人的代码水平都不尽相同,那么在团队中应该如何较好地协调安排每个人的工作?我查找了一些资料,对于3-5小型的项目由于团队规模较小,能够及时沟通,所以有什么事情能够较好得沟通,但是对于大团队来说,必须要有一系列的说明文档来提供相应的支持,团队通过筛选人员进入公司,并安排有项目经验的人来管理安排人员,但是具体在小型项目中如何安排人员分配依旧没有相应的答案,希望能够给予具体的解答。
Question Two:在项目合作中总是会出现个别人躺赢的情况,不管是团队项目还是结对编程,特别是作业项目,如何处理好这个情况?
- 《构建之法》P151页
尽管文中提及如何结对编程,如何团队开发,但是依然可能出现问题中的这个情况。在网上搜索回答,给出的回答是在组件团队的初期应该能够筛选队友,对于一些不靠谱的队友不予考虑,俗称“混子”,但是根据以往经验,一开始项目时,并没有办法分别是否这个队友靠谱,只有在项目进行到一定的阶段时,才能分辨出来,而在这个时候基于人情考虑,还是没法直接点破将在之提出队伍,在项目开发中,如果出相互这个情况如何解决,恳求给予解答。
Question Three:代码重构和重写的区别是什么?
- 《构建之法》P407页
文中“小飞对照设计文档和代码指南进行自我复审,重构代码。”对于“代码重构”不是很清楚,查找了一些资料,重构代码就是通过调整程序代码,但并不改变程序的功能特征,达到改善软件的质量、性能,使程序的设计模式和架构更趋合理,更容易被理解,提高软件的扩展性和维护性。资料中都在强调重构的好处,重构在“软件系统的过程, 它不会改变代码的外部行为, 同时改善其内部结构。 这是一种严格的清理代码的方法, 它可以最大限度地减少引入错误的可能性。 本质上, 当重构代码时, 是在编写代码之后改进它的设计”。而重写时将代码全部重写。但是具体如何选择重构还是重写我还是不太明白,何时重构何时重写,可以举例说明吗?
Question Four:关于Bug,有些时候bug存在致命性,但我们又无法修复他,只能推倒重做,如何在开发过程中避免这种情况?
- 《构建之法》P61页
文中对bug的定义时影响软件使用效率的缺陷,文中也对如何做出足够好的软件做出了相应的解释,比如做到写文档说明,进行压力测试等等...但是对于一些隐藏的bug人为观察并不容易发现,并且对于一些关键代码,可能出现一些无法修复的bug,到后期无法修复,那应该如何避免这种情况?资料中查找到依旧时列出完整的文档,协调好各个流程,并且考虑周全,但是由于个人原因可能会出现遗漏的情况,那么在具体项目中应该如何考虑,才能尽量不出现这种情况呢?
Question Five:关于PM,在小型开发中是否需要PM?
- 《构建之法》第五章
文中对PM有一个专门的章节进行讲述,但是对于目前来说,接触的都是一些小型的项目,没有接触到大的项目,所做的项目也并不能够发表,在没有专门PM的指导下,做技术的人员通过什么样的方式,才能较为有效地避免后期项目PM的加入并不冲突?并且PM真的不用懂技术吗?查找资料得知,PM可以不用懂技术,但是一定得有所了解,不能说明都不懂,能够从技术转型学习PM是最优选择。既懂得技术又懂得产品的人员更会明白开发人员的难处。小型项目可以没有PM,但是一定得有一个明确的文档,代码规范应该形成,有明白的说明文档。对于理解开发人员的难处确实不懂技术的PM无法体会到开发人员的实现难度,更容易导致争吵(因此建议来几个小姐姐)。具体程序如何快速在生活中PM技能,希望能够给予一定的建议。
2.5附加题
冯·诺伊曼的故事
一次,冯·诺伊曼在晚会上,女主人勇敢地向他提出一个谜题:两列火车在同一轨道上以每小时 30 英里的速度相对而行,且相距 1 英里,这时栖在一列火车前面的一只苍蝇以每小时 60 英里的速度朝着另一列火车飞去。当它飞到另一列火车时,它又迅速地飞回来。它一直这样飞过去飞回来,直到两列火车不可避免地发生碰撞。问这只苍蝇共飞了多少英里?
几乎在女主人刚解释完问题的同时,冯·诺伊曼就答道:“1 英里。”
“太让我惊讶了,你这么快就算出来了。” 她说道。“大多数数学家都没能看出这里面的技巧,而是用无穷级数去计算,这花费了他们很长时间。”
“什么技巧?我也是用无穷级数算的。” 冯·诺伊曼回答道。
事实上,这个笑话 (严格讲应该叫轶事) 见于 Norman Macrae 所作的冯·诺伊曼传记 John von Neumann
Norman Macrae
作者最后写道:“值得一提的是,后来当别人拿这件事开他玩笑时,Johnny 说,‘其实当时他们给我的数字可没这么简单’”。
2.WordCount编程
1.Github项目地址
2.PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20min | 25min |
| • Estimate | • 估计这个任务需要多少时间 | 20min | 25min |
| Development | • 开发 | 9h20min | 10h30min |
| • Analysis | • 需求分析 (包括学习新技术) | 3h | 4h |
| • Design Spec | • 生成设计文档 | 30min | 1h |
| • Design Review | • 设计复审 | 30min | 20min |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 1h | 1h30min |
| • Design | • 具体设计 | 1h | 1h |
| • Coding | • 具体编码 | 1h | 1h |
| • Code Review | • 代码复审 | 20min | 10min |
| • Test | • 测试(自我测试,修改代码,提交修改) | 2h | 1h30min |
| Reporting | 报告 | 2h10min | 2h50min |
| • Test Repor | • 测试报告 | 1h | 1h |
| • Size Measurement | • 计算工作量 | 10min | 20min |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 1h20min | 1h30min |
| 合计 | 12h | 13h45min |
3.解题思路描述
拿到题目后,我首先学习了Python的基础语法,而浏览了一遍题目,明白了题目重点要求IO操作,正则表达式,单元测试。
其中对文件的读写对于IO操作,对单词的搜索对于正则表达式,对结果的测试对于单元测试。
于是我首先重点学习了IO类的相关操作,正则表达式和如何进行单元测试,在了解了这三方面的知识后大体上就能够完成本次作业的内容,在作业完成过程中有时候会遇到一些自身无法解决的问题,我会进行google或百度都能找到答案
4.代码规范制定链接
5.计算模块接口的设计与实现过程
模块接口:
# WordCount接口 由于这次作业的类只有一个就实际代码没有封装了
class IWordCount
# 统计字符数
@abstractmethod
def count_char(filename)
# 统计单词数
@abstractmethod
def count_word(filename)
# 统计行数
@abstractmethod
def count_row(filename)
# 统计最多的10个单词及其词频
@abstractmethod
def count_fword(filename)
总体思路:将文件的每行读出,并进行处理
统计字符数关键代码:使用len函数读取每行字符个数
with open(dir, "r", encoding="utf-8") as f:
for line in f:
count += len(line)
统计单词数关键代码:应用正则表达式^[a-zA-Z]{4}[a-zA-Z0-9]*表示匹配一个以4个字母开头的字符串
with open(dir, "r", encoding="utf-8") as f:
for line in f:
lis = re.split(r"[^a-zA-Z0-9]", line)
new_lis = [x for x in lis if x != ""]
for item in new_lis:
if not re.match(r"^[a-zA-Z]{4}[a-zA-Z0-9]*", item) == None:
count += 1
统计行数关键代码:由于使用每行读取的方法每读取一行如果还有下一行的话那么每行读取的字符串最后一个字符就是\n,我们使用strip('\n')去掉后再使用re.sub('\s',"",new_line)去掉字符串中的空白字符如果最后这个字符串不为空那么则此行不是空行,即计数
with open(dir, "r", encoding="utf-8") as f:
for line in f:
new_line = line.strip('\n')
new_line=re.sub('\s',"",new_line)
if new_line != "":
count += 1
统计最多的10个单词及其词频关键代码:通过字典存储单词,并计数,首先使用正则表达式[^a-zA-Z0-9]对一行的字符串进行分隔,得到一个List字符串数组,而后去掉List数组中的空字符串,把其中的字母转为小写,对于每个符合要求的单词检查是否在字符串数组中,如存在则计数加1,不存在则在字典中添加该单词key,并将value设置为1
最后使用sorted方法对得到字典进行排序,使用lambda表达式表示key,lambda表达式表示先按照valua的负数按照升序排序(即value的正数的降序排列),而后按照key键的升序排列,并取最终结果的前10个数构成字典
dict = {}
with open(dir, "r", encoding="utf-8") as f:
for line in f:
lis = re.split(r"[^a-zA-Z0-9]", line)
new_lis = [x for x in lis if x != ""]
for item in new_lis:
new_item = item.lower()
if not re.match(r"^[a-zA-Z]{4}[a-zA-Z0-9]*", new_item) == None:
if dict.__contains__(new_item):
dict[new_item] += 1
else:
dict[new_item] = 1
#排序
sorted(dict.items(), key=lambda x: (-x[1], x[0]))[:10]
独到之处:使用Python来书写代码能够快速解决许多其他语言需要写多行代码才能解决的事情,使用正则表达式来匹配字符串快速判断出了单词的正确性,使用sorted函数快速进行排序并得到最后要求的结果
6.计算模块接口部分的性能改进
10条数据 0.001s

100条数据 0.002s

1000条数据 0.008s
100条数据 0.002s

10000条数据 0.065s

100000条数据 0.628s

1000000条数据 6.71s

...
数据测试大致呈现线性增长
改进计算模块性能上所花费的时间:1h
思路:通过使用正则表达式能够快速匹配单词,使用内置函数排序能使得按照一定顺序输出,使用按照字典value的负数输出能够使得排序结果降序输出
7.计算模块部分单元测试展示
由于单元测试函数有十多个,一一列举的话篇幅过多,这里仅列举较为重要的几个测试函数
对于统计特殊字符数测试的测试:
#对于特殊的字符进行测试如:/t /r等等
def test_count_char1(self):
"""
统计特殊字符数测试(转义字符)
"""
filename = "test_count_char1.txt"
dir = os.getcwd() + "/" + filename
str="1\r\n2\n3\'\t4\"5\f\a"
with open(dir, "w", encoding="utf-8") as f:
f.write(str)
WordCount.file_read_out(filename, "testout_count_char1")
对于统计单词数测试:
#特殊单词进行测试 如:12file fil等等
def test_count_word2(self):
"""
统计单词数测试(判断是不是单词情况)
"""
filename = "test_count_word2.txt"
dir = os.getcwd() + "/" + filename
with open(dir, "w", encoding="utf-8") as f:
str = "123file;wwww;wWwW,file123;file;fil,\n"
i = 0
while i < 100:
f.write(str)
i += 1
WordCount.file_read_out(filename, "testout_count_word2")
对于统计单词数测试:
#空白字符进行测试如:\r \n \t等等
def test_count_row1(self):
"""
行数测试(有空行包括非空白字符)
"""
str = "whuihu\n\t\n \nwww"
filename = "test_count_row1.txt"
dir = os.getcwd() + "/" + filename
with open(dir, "w", encoding="utf-8") as f:
f.write(str)
WordCount.file_read_out(filename, "testout_count_row1")
对于统计最多的10个单词及其词频测试:
#测试大小写和优先输出
def test_count_fword2(self):
"""
统计最多的10个单词及其词频测试(频率相同的单词,优先输出字典序靠前的单词)
"""
str = ('windows95 windows95 windows98 windows96 '
'windows2000\n')
filename = "test_count_fword2.txt"
dir = os.getcwd() + "/" + filename
with open(dir, "w", encoding="utf-8") as f:
i = 0
while i < 20:
f.write(str)
i += 1
WordCount.file_read_out(filename, "testout_count_fword2")
使用Coverage计算测试覆盖率:
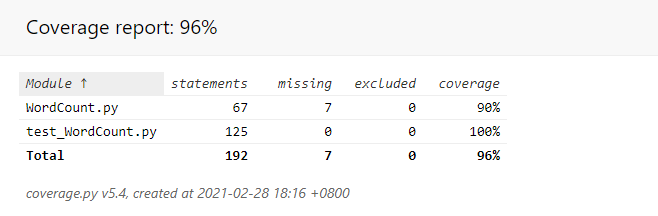
如何优化覆盖率:
由于我采用正则表达式匹配,并未使用判断,所以覆盖率基本是100%,少了的那些覆盖率是因为对于输入文件名的正确性判断和主函数所以暂时无法更好优化,除非将主函数独立出来,就可将覆盖率再提升,但我个人认为这样做意义不大
8.计算模块部分异常处理说明
由于题目要求的是不会有中文输入,所以中文输入可能存在错误,但是在实际统计过程中,因为是正则匹配又会将不是因为字符和数字的删除,所以最后汉字不记录统计,将汉字作为特殊字符看待。
控制台输入参数错误异常

9.心路历程与收获
学习了Python基础语法,相关IO操作,学习了如何进行单元测试和如何生成覆盖率文档,学习了如何使用正则表达式,对Python基本的API调用有了大致的了解,对IO操作进行了熟悉.学会了如何使用Python语法完成一个较为完整的项目

 浙公网安备 33010602011771号
浙公网安备 33010602011771号