
数仓技术体系设计
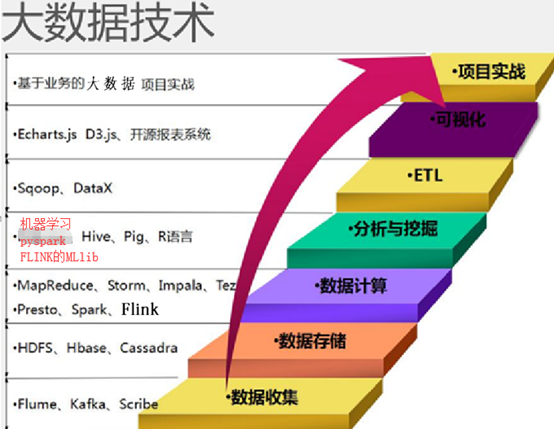
考虑问题 :
实效性高
业务灵活、多变
数据源多样性
1、关系性数据库 ,结构化数据。
2、nosql
3. 日志,行为日志(非结构化,即埋点)
4、系统日志
数据质量参差不齐
应用场景复杂
针对各种问题和场景,在做技术选型和低层技术架构的时候需要考虑:
梳理业务和响应的应用场景
需要处理的数据源的种类、类型、数据量。如关系型还是nosql,行为日志格式的规范,数据量大小
对实效性要求: T+1还是H
对灵活性要求
对性能要求
对成本的要求: 本身就是高投入,采购和维护成本。适合公司当前阶段的架构
一个合理的架构的关键是能够在以下方面取得平衡:
1、满足需求
2、技术可持续性:比如考虑当前数仓人员的技能技术栈
3、稳定性
4、可扩展性
5、成本
6、灵活性:微服务化,快速迭代敏捷性开发,第一版一个demo,满足基本的功能点,下一版再考虑高并发,加什么功能,优化。
实际项目,分解:
采集:
-数据源
1、关系型数据库: sqoop、datax、binglog采集
或像银行,orcle直接导成flat文件
2、日志:
业务日志:
如只要求t+1的,用flume或直接scp过去
如实时的,可以用flume, logstash或filebeat. 可以写到hdfs或ES
如果应用服务器本身资源就少,还要考虑flume agent和logstash占的资源都比较高,filebeat占得少
-数据量
#所需技术岗位:
岗位分类:
1/ 大数据平台:
不过度关注业务、数据内容本身,重点是集群的稳定性、性能、易用性,技术上会涉及底层源码,比如Hadoop、spark、hbase等,大数据底层框架的维护角色---神秘但重要的底层建设者
2/ 大数据生态开发、工程性开发、应用相关开发:(工程性开发),主要是使用大数据平台,
要求: 熟悉某一种语言,精通某一种大数据框架.做特定的场景:如推荐系统....
实时计算
反作弊
调度系统的开发
hive开发
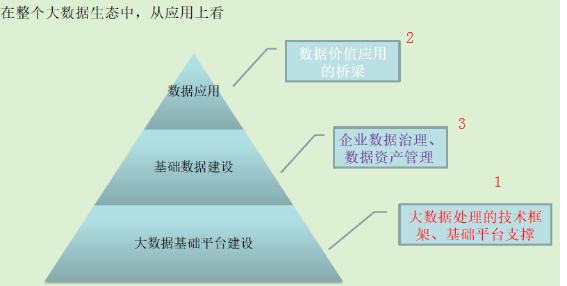
大数据岗位:
etl工程师
数仓工程师:
离线数仓+实时数仓
hadoop工程师:
hadoop,hive,hbase,zookeeper,sqoop,flume,azkaban,spark\flink
spark工程师:
java,scala,python
flink工程师
机器学习
3/ 数据仓库、数据内容建设、开发(包括架构,建模)
“大数据”真正的建设者,负责企业整体的数据资产建设和管理,负责数据治理体系,构建高质量、一致性、规范化的数据平台,关注企业整体业务情况和数据内容本身,对数据、业务有较高的敏感性,是所谓人工智能、自动驾驶等一切数据应用的底层基础数据建设者
4/ bi: 大数据产品经理,数据分析师 (数据可视化)


