


spark运行
阿里云:
阿里spark作业配置:
https://help.aliyun.com/document_detail/28098.html?spm=a2c4g.11186623.6.650.458d139f8c71x9
资源算法:
https://help.aliyun.com/document_detail/28124.html GG
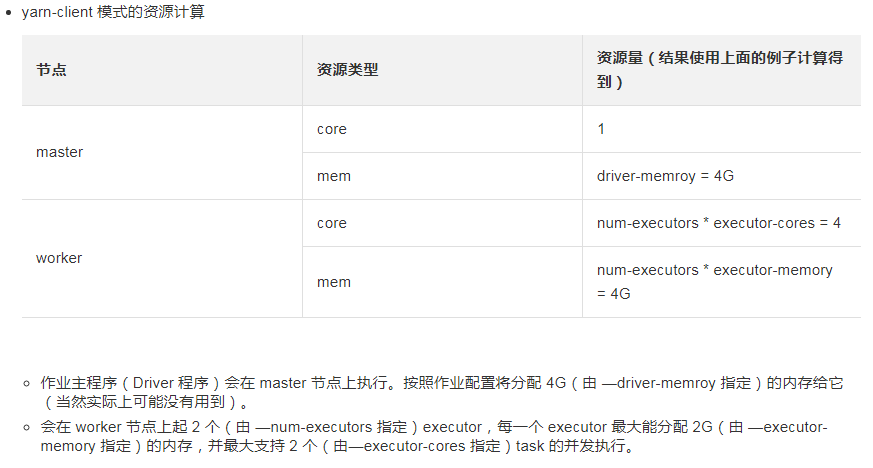
yarn-client:
用到队列的资源就是executor的数量*后面定义的vcore,mem
spark-submit --master yarn-client --driver-memory 7G --executor-memory 5G --executor-cores 1
spark-submit \ --master yarn-client \ --num-executors 100 \ --executor-memory 6G \ --executor-cores 4 \ --driver-memory 8G \ --conf spark.default.parallelism=1000 \ --conf spark.storage.memoryFraction=0.5 \ --conf spark.shuffle.memoryFraction=0.3
#跑py的两种方式
第一种好处是, 输入一个脚本执行一个脚本,便于排错.
1/ pyspark --queue algo_spark --num-executors 15 --executor-cores 5 --executor-memory 10G --driver-memory 10G
第二种好处是, 在yarn可以追踪,可以打开spark的web ui看.
2/ spark-submit --master yarn-client *.py
#默认是false,打开就是开启动态资源调整更好些
yarn.log-aggregation-enable ture


