EMR问题
参考:
https://dbaplus.cn/news-11-1983-1.html
解题思路:
查看服务状态, 运行测试用例,查看报错信息和服务日志.
/mnt/disk1/log/xxx
搜索网上资料和官网,无果提交阿里后台。
1/连接参数

hive.server2.thrift.min.worker.threads 5
hive.server2.thrift.max.worker.threads 2000
在emr中hive-hiveserver2-site中自定义添加
2/ hive.driver.parallel.compilation参数默认为false,导致HS2只允许同时一个Query编译, 有操作元数据比较多的查询编译读取元数据会比较慢,全局锁会卡住所有其他查询。 需要设置为true,打开允许多个Query同时编译。

hive-site:
hive.driver.parallel.compilation 这个参数可以设置为true
hive&hue优化
1、hue配置文件,修改max_number_of_sessions值大小,修改为10
[beeswax]
max_number_of_sessions=10
2、hue
hue的server_conn_timeout调大点
hive:
1、自定义hive配置中,增加这个属性:
hive.server2.parallel.ops.in.session=true
2、hive
将hiveserver2和mestatore的堆大小调大一些
3/ 字符集问题见mysql
4/ 队列问题见emr fair-scheduler
5/ main error unable to locate appender "FA" for logger config "root"
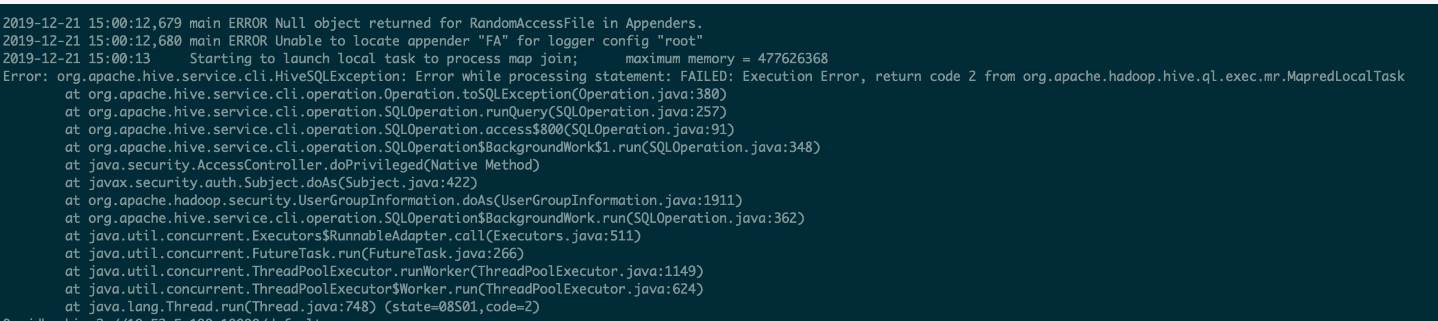
localtask内存不够报错 然后自动重试,hive.auto.convert.join,maplocal 跟这个参数有关系 看看是不是可以关闭这个参数
https://www.jianshu.com/p/80ce4f8a4397?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
6/ 轮询
1. 在EMR Gateway集群的节点如何手动启动HiveServer2
a. 登录gateway节点
b. 切换到hadoop用户, su - hadoop
c. 手动执行启动HS的命令
HADOOP_OPTS=HIVE_SERVER2_OPTS HADOOP_HEAPSIZE=HIVE_SERVER2_HEAPSIZE hive --service hiveserver2 >/var/log/hive/hiveserver2.out 2>/var/log/hive/hiveserver2.err &
#heap在EMR里调,同步到gateway
7/ 在hive有查询s3,设置不同参数权限:
除了ranger里对airflow的授权外:hdfs根, hive的url , database
在hiveserver2的配置文件中:
key: hive.security.authorization.sqlstd.confwhitelist.append
vlaue:
airflow.ctx.*|mapred.job.name|mapreduce.job.queuename|mapred.job.queue.name|tez.queue.name|mapreduce.job.priority|tez.queue.name|tez.job.queue.name|hive.driver.parallel.compilation|fs.s3a.*|mapred.max.split.size|hive.input.format|hive.mapred.mode
或参考:要设置成这个hive.security.authorization.sqlstd.confwhitelist.append = |mapred.job.*|mapreduce.job.*
8/ 运行时访问不了s3:
EMR hive-site自定义添加:
hive.conf.hidden.list fs.s3.awsAccessKeyId,fs.s3.awsSecretAccessKey
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
hive-site.xml里面 把hive.conf.hidden.list 这个配置重新配一些,将fs.s3a.access.key 和 fs.s3a.secret.key
这两个剔除掉 应该就行了
9/ gateway中jar包手动copy
你把jindofs-sdk.jar复制到/opt/apps/extra-jars目录下吧.
10/ spark运行报权限错:

暂时把/etc/ecm/spark-conf/hive-site.xml这个文件里面,
hive.security.authorization.enabled
hive.security.authorization.manager
hive.conf.restricted.list 这三个删掉
重启spar服务
11/ 建json表的问题
http://www.voidcn.com/article/p-dewklslz-bhu.html
#select * from oride_dw_ods.ods_binlog_base_data_order_hi limit 10; #测试有没有json包
1/ 把jar包放入$HIVE_HOME/lib/目录下
cp json-serde-1.3.8-jar-with-dependencies.jar /usr/lib/hive-current/lib/
2/ 在hive cli中执行 hive>add jar jar包的存放路径
hive->
add jar /usr/lib/hive-current/lib/json-serde-1.3.8-jar-with-dependencies.jar;
3/ 向Hadoop中导入json jar包:直接把jar包放在$HADOOP_HOME/share/hadoop/mapreduce/下即可,注意:一定要放到这个目录中。
cp json-serde-1.3.8-jar-with-dependencies.jar /usr/lib/hadoop-current/share/hadoop/mapreduce/
spark:
cp json-serde-1.3.8-jar-with-dependencies.jar /opt/apps/ecm/service/spark/2.4.3-1.3.0/package/spark-2.4.3-1.3.0-bin-hadoop2.8/jars
12/ 查agent和存储服务
service ecm-agent restart
service ecm-agent status
ps -ef |grep b2-
13/ 开发反映hive任务结束时间和系统时间不一致
hive -e 'select current_timestamp()' ; date
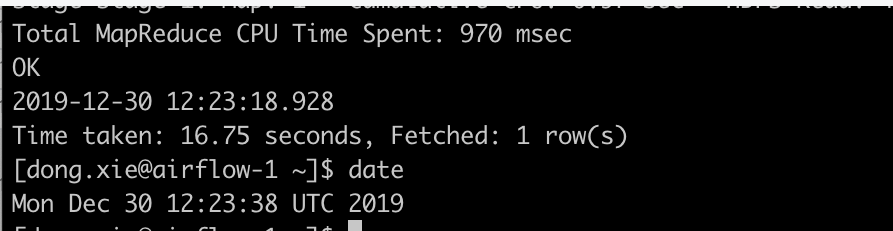
ive任务运行需要一段时间(比如30秒),current_timestamp不一定是hive任务结束的时间,可能是中间的某个时间点(开始时间)。所以current_timestamp和任务结束之间有差距。这应该是hive的实现问题
14/ #这个如果为true,一些join操作将不被允许.
hiveserver2-site.xml
hive.strict.checks.cartesian.product=false
hive.mapred.mode=nonstrict
#这个如果为true,一些join操作将不被允许.
FAILED: SemanticException Cartesian products are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.cartesian.product to false and that hive.mapred.mode is not set to 'strict' to proceed. Note that if you may get errors or incorrect results if you make a mistake while using some of the unsafe features.
15/ 没有写hiveserver2.log的权限
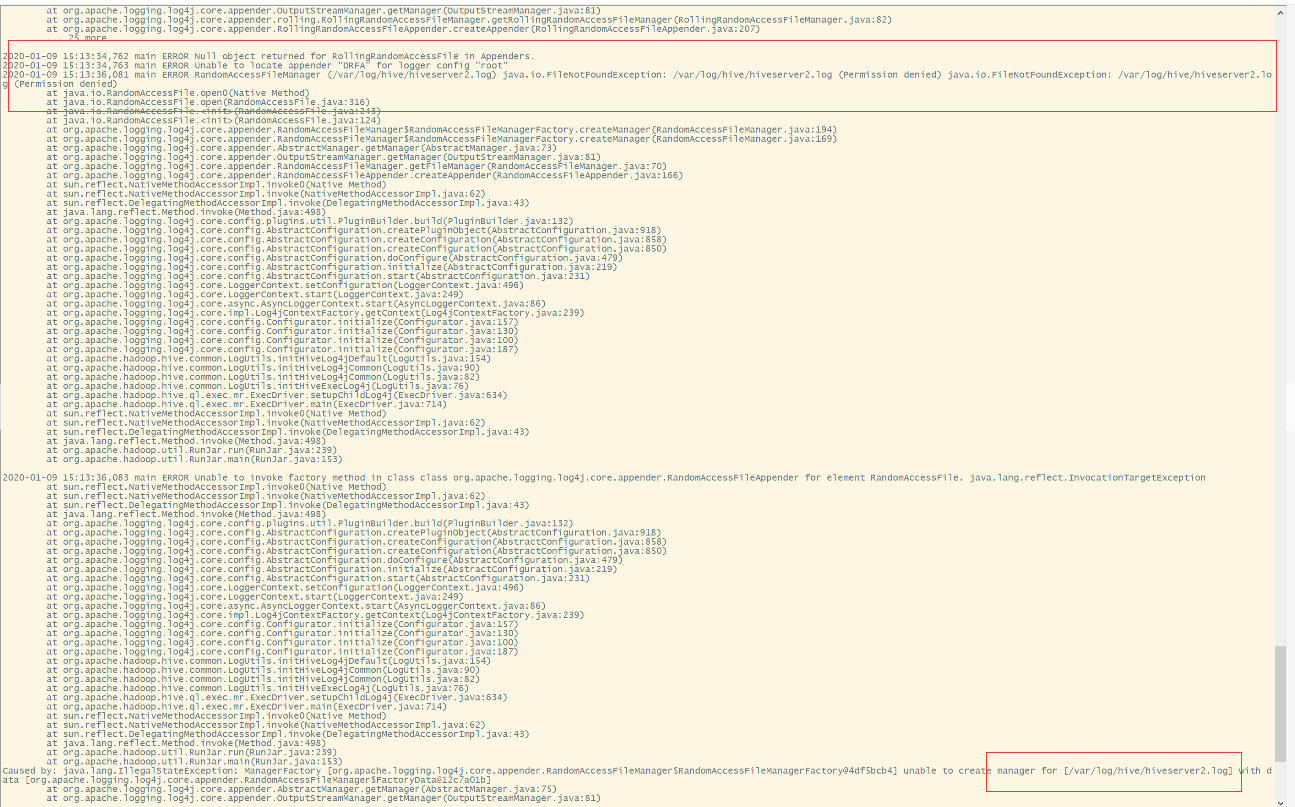
#在gateway的机器上手动起的hiveserver2, 因为首次用root起, 后来用hadoop起,导致/mnt/disk1/log/hive没有权限,
chown -R hadoop /mnt/disk1/log/hive
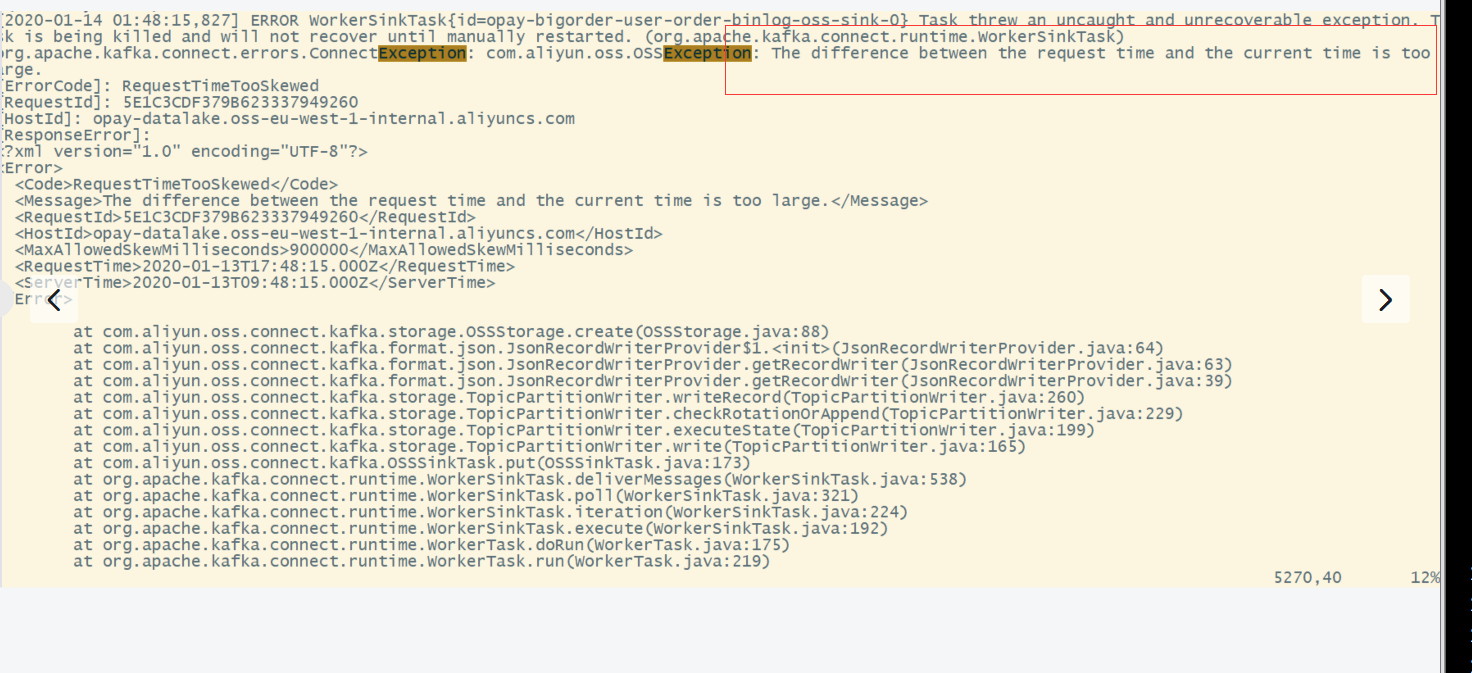
16/ 时区问题
需改新机器的时区, 和集群/kafka时区一致
17/ 老gateway上需要手动启动:
gateway上手动hbase:
#从生产集群copy
/etc/ecm/hbase-conf
/usr/lib/hbase-current
/etc/profile.d/hbase.sh
source /etc/profile


