
impala
参考:
架构原理:
https://www.cnblogs.com/Rainbow-G/articles/4282444.html
使用:
https://www.w3cschool.cn/impala/impala_architecture.html
官网:
https://impala.apache.org/
http://impala.apache.org/docs/build/html/topics/ GG
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具(实时SQL查询引擎Impala),Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。
Impala通过使用标准组件(如HDFS,HBase,Metastore,YARN和Sentry)将传统分析数据库的SQL支持和多用户性能与Apache Hadoop的可扩展性和灵活性相结合。
1/ 使用Impala,与其他SQL引擎(如Hive)相比,用户可以使用SQL查询以更快的方式与HDFS或HBase进行通信。
2/ Impala可以读取Hadoop使用的几乎所有文件格式,如Parquet,Avro,RCFile。
通过把存储(hdfs,kudu..)的文件读要内存里运行. 所以具有实时计算的特点: 1/ 实时,快. 2/ 大批量支持并没那么好.
Impala主要由Impalad, State Store和CLI组成。
Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。
在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
Impala State Store: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
与Hive的关系
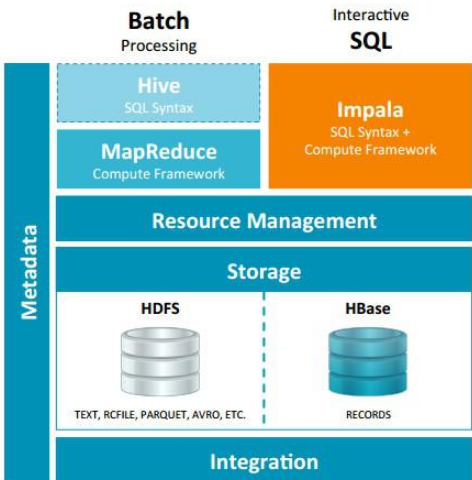
Impala与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如图 2所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
impala的使用:
Impala shell(命令提示符)
Hue (用户界面)
ODBC和JDBC(第三方库)
1、 impala-shell:
[root@emr-header-1 ~]# impala-shell
Starting Impala Shell without Kerberos authentication
Connected to emr-header-1.cluster-635:21000
Server version: impalad version 2.12.0-cdh5.16.1 RELEASE (build 4a3775ef6781301af81b23bca45a9faeca5e761d)
***********************************************************************************
Welcome to the Impala shell.
(Impala Shell v2.12.0-cdh5.16.1 (4a3775e) built on Tue Dec 4 08:37:43 CST 2018)
To see live updates on a query's progress, run 'set LIVE_SUMMARY=1;'.
***********************************************************************************
[emr-header-1.cluster-635:21000] > help;
测试脚本:
select
id,
concat(name,'[',CAST(id as string),']') as city_label
from oride_db.data_city_conf
where dt >= from_unixtime(unix_timestamp(days_sub(current_timestamp(),1)), 'yyyy-MM-dd') and
id < 999000
order by id
union select 0 as id, 'All[0]' as city_label
2、通过jdbc
https://www.cnblogs.com/xinfang520/p/9354466.html
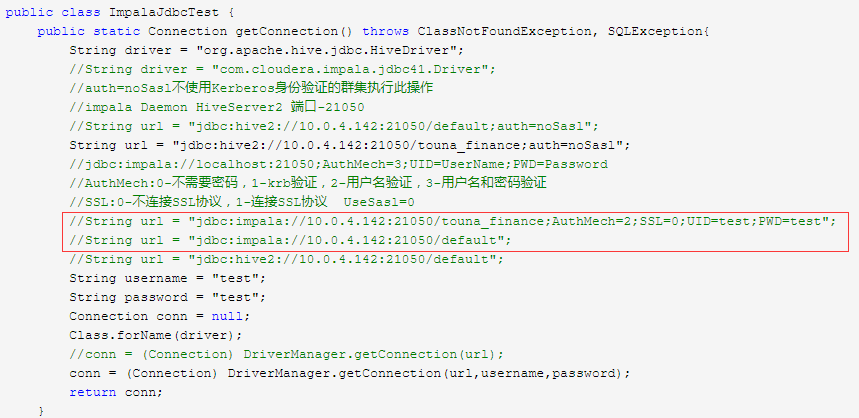
默认是21050,emr做了个负载均衡,连header的21050就可以了,它会分发给其它两个节点的21050


