
小白scrapy爬虫简单例子之爬取农业银行分支结构信息
*.准备工作:爬取的网站地址:http://www.abchina.com/cn/AboutABC/nonghzx/fzjg/jnbranch_org/
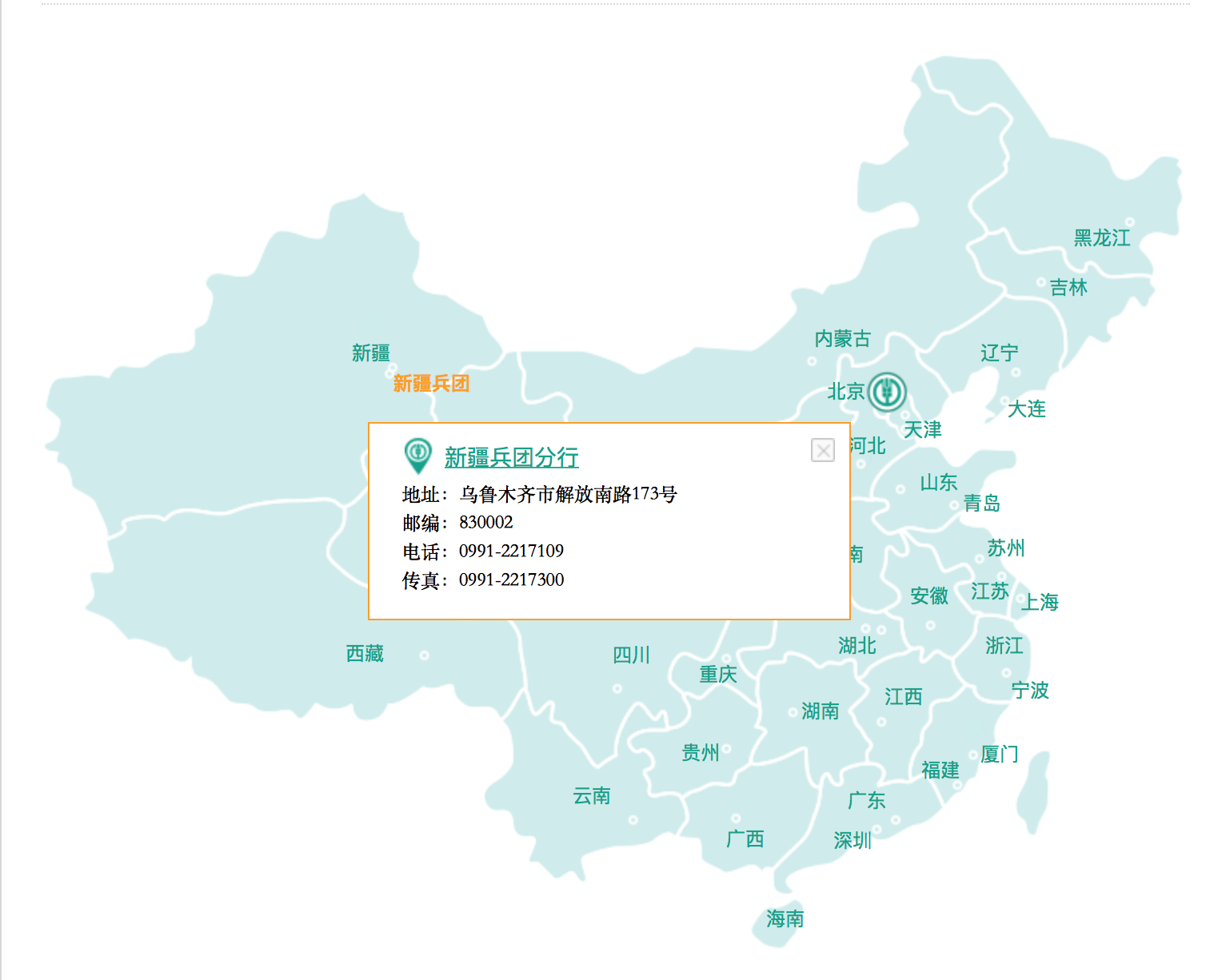
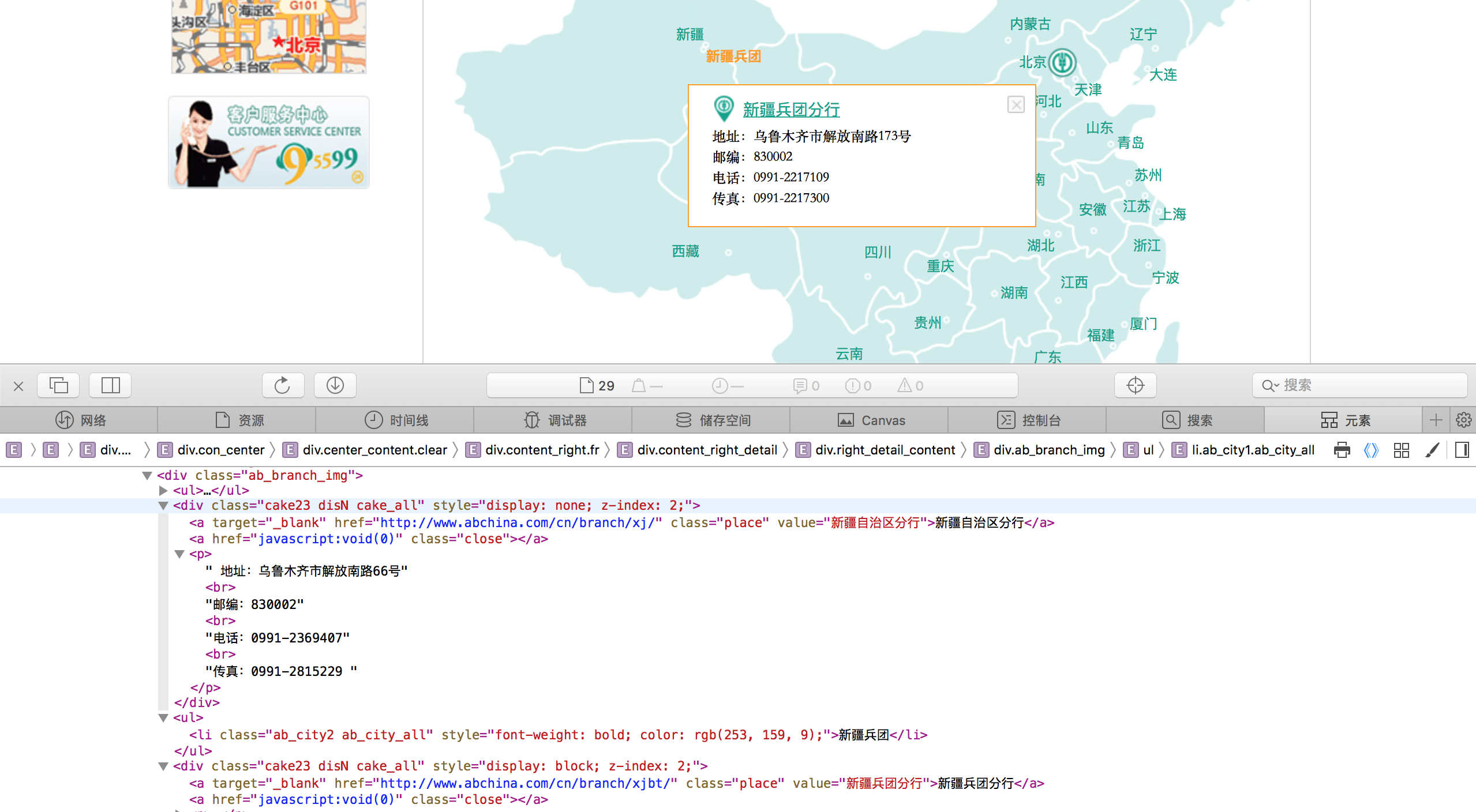
爬取的内容:下图中每个省份(或者城市)对应的弹框里的支行信息
1.打开终端,进入到要存放scrapy项目的文件夹下,并创建一个scrapy项目:

2.自动创建的目录结构(各个文件及文件夹的作用可参考其他博客内容):
3.创建爬虫
bank_branch:爬虫名字
abchina.com:爬取网站的域名
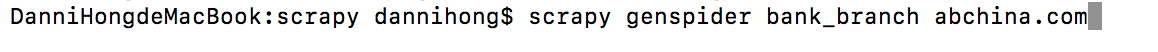
存放在spiders文件夹下
4.查看网页源码,找到要爬取信息所在的位置
5.利用xpath取出我们所需要的地址、邮编、电话等信息(关于xpath的知识可以百度看一下):
可以通过'scrapy shell http://www.abchina.com/cn/AboutABC/nonghzx/fzjg/jnbranch_org/' 命令在终端里调试出满足自己要求的表达式
(这里要注意的是有的网址需要在setting.py里设置USER_AGENT值之后才可以访问,不然会报‘4xx’的错误)


6.将上面的逻辑代码写入自己创建的bank_branch.py爬虫文件里
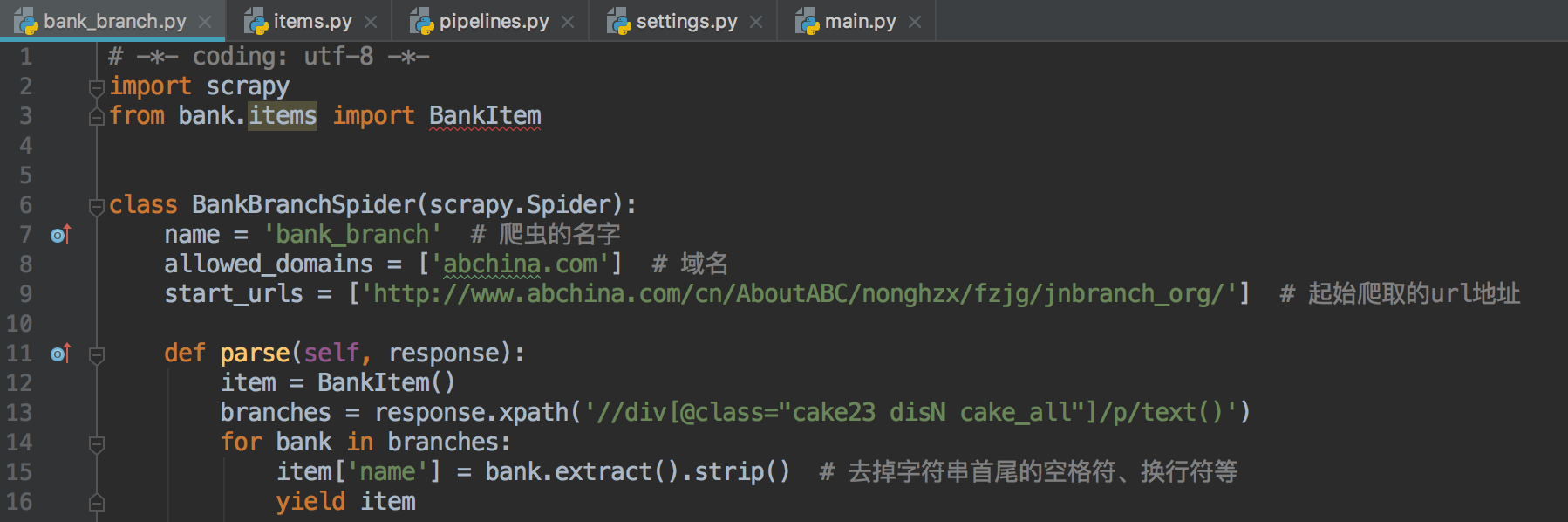
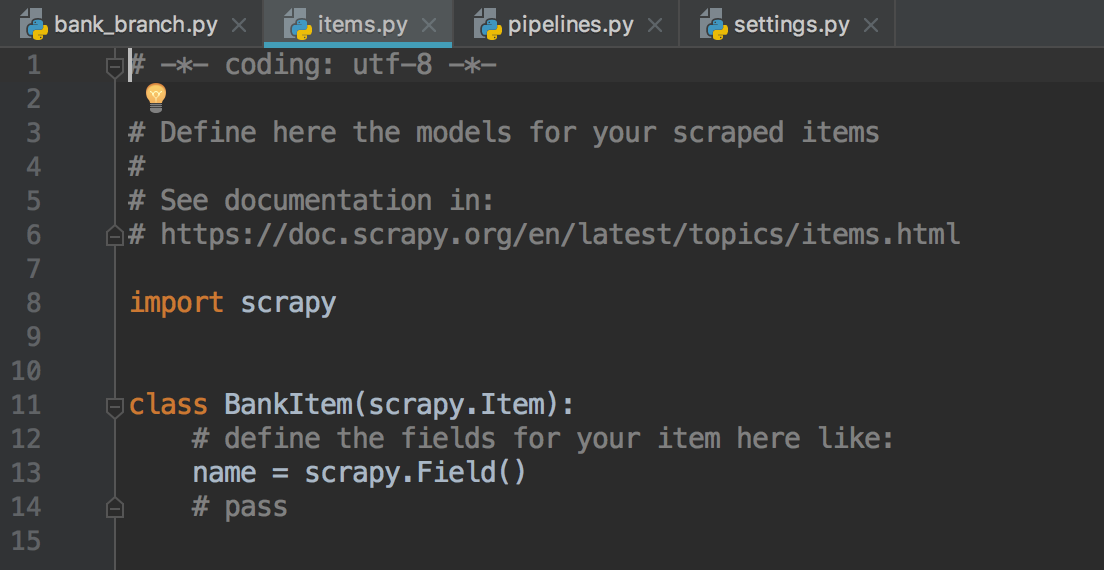
7.bank_branch.py脚本里的item对象来自来自于items.py文件(items.py文件设置数据存储模板)(name为item的一个字段)
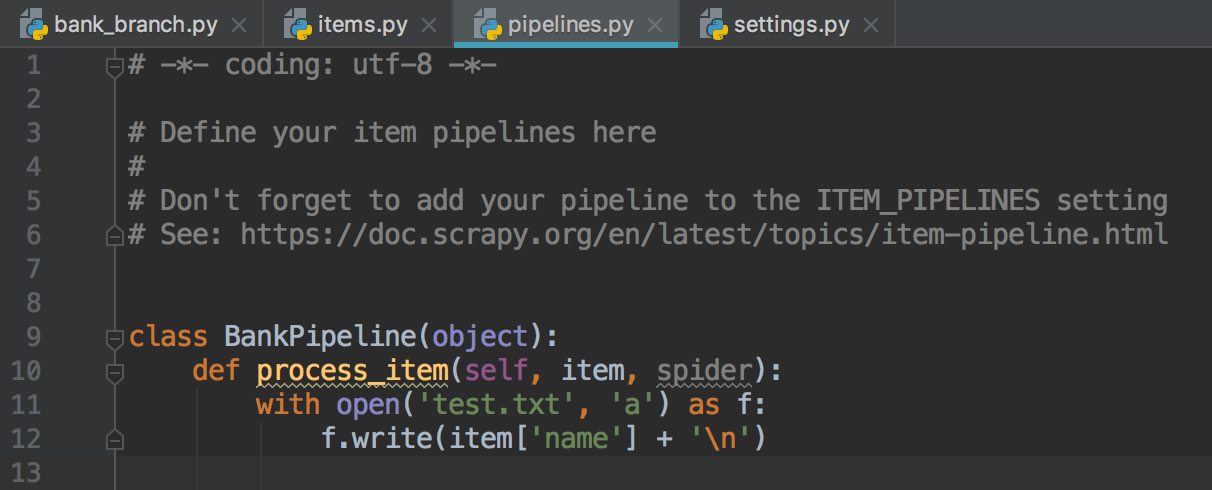
8.pipelines.py为管道文件,决定数据输出流向的部分:是保存到数据库还是文本文件。
9.在settings.py里设置配置参数。设置USER_AGENT,ITEM_PIPELINES的参数值。
10.运行
方式一:在终端里输入命令:scrapy crawl bank_branch (bank_branch是bank_branch.py里声明的爬虫名字)
方式二:新建main.py脚本,执行main.py脚本
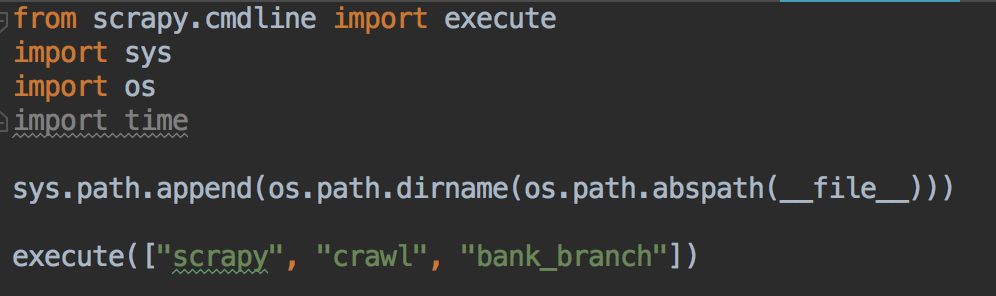
11.执行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号