分布式系统一致性算法Raft
Raft 算法也是一种少数服从多数的算法,在任何时候一个服务器可以扮演以下角色之一:
Leader:负责 Client 交互 和 log 复制,同一时刻系统中最多存在一个
Follower:被动响应请求 RPC,从不主动发起请求 RPC
Candidate : 由Follower 向Leader转换的中间状态
在选举Leader的过程中,是有时间限制的,raft 将时间分为一个个 Term,可以认为是“逻辑时间”:
每个 Term中至多存在1个 Leader
某些 Term由于不止一个得到的票数一样,就会选举失败,不存在Leader。则会出现 Split Vote ,再由候选者发出邀票
每个 Server 本地维护 currentTerm
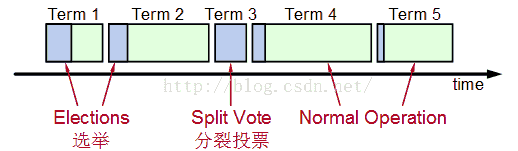
选举过程:
自增 CurrentTerm,由Follower 转换为 Candidate,设置 votedFor 为自身,并行发起 RequestVote RPC,不断重试,直至满足下列条件之一为止:
获得超过半数的Server的投票,转换为 Leader,广播 HeatBeat
接收到 合法 Leader 的 AppendEnties RPC,转换为Follower
选举超时,没有 Server选举成功,自增 currentTerm ,重新选举
当Candidate 在等待投票结果的过程中,可能会接收到来自其他Leader的 AppendEntries RPC ,如果该 Leader 的 Term 不小于本地的 Current Term,则认可该Leader身份的合法性,主动降级为Follower,反之,则维持 candida 身份继续等待投票结果
Candidate 既没有选举成功,也没有收到其他 Leader 的 RPC (多个节点同时发起选举,最终每个 Candidate都将超时),为了减少冲突,采取随机退让策略,每个 Candidate 重启选举定时器
日志更新问题:
如果在日志复制过程中,发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwers了,那么Leader只能正常更新它能访问的那些Follower服务器,
而大多数的服务器Follower因为没有了Leader,他们重新选举一个候选者作为Leader,然后这个Leader作为代表于外界打交道,如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers,
如果这时网络故障修复了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新。
流程:
Client 发送command 命令给 Leader
Leader追加日志项,等待 commit 更新本地状态机,最终响应 Client
若 Client超时,则不断重试,直到收到响应为止(重发 command,可能被执行多次,在被执行但是由于网络通信问题未收到响应)
解决办法:Client 赋予每个 Command唯一标识,Leader在接收 command 之前首先检查本地log
https://www.cnblogs.com/mindwind/p/5231986.html
http://blog.csdn.net/followmyinclinations/article/details/52870418
https://www.cnblogs.com/linbingdong/p/6442673.html
https://www.jianshu.com/p/096ae57d1fe0
http://blog.csdn.net/cszhouwei/article/details/38374603

 浙公网安备 33010602011771号
浙公网安备 33010602011771号