Zookeeper 问题收集
Zookeeper 问题收集
ZK 明明有了有序的指令队列,为什么还要用 zxid来辅助排序?
没理解这题目
ZAB 协议要求保证事务的顺序,因此必须将每一个事务按照 ZXID 进行先后排序然后处理
ZNode文件系统
不同于Linux,分为文件夹和文件,znode文件系统中只有znode节点(既可以存数据,也可以当作为文件夹)。
但是每个节点都必须要有一个唯一的绝对路径,每个节点都可以存储数据(根节点除外,可以存但是不建议存数据),每隔节点下都可以挂载子节点
虽然说zookeeper每个节点都存储了一份完整数据,但是不能存储大量的数据。所以znode只适合存储非常小量数据,不能超过1M,最好小于1K。
znode的分类:
- 按照生命周期可以分为:
- 短暂(ephemeral)(断开连接自己删除)
- 持久(persistent)(断开连接不删除,默认情况)
- 按照是否自带序列编号可以分为:
- SEQUENTIAL(带自增序列编号,由父节点维护)
- 非SEQUENTIAL(不带自增序列编号,默认情况)
| 节点类型 | 详解 |
|---|---|
| PERSISTENT | 持久化 znode 节点,一旦创建这个 znode 节点,存储的数据不会 主动消失,除非是客户端主动 delete |
| PERSISTENT_SEQUENTIAL | 自动增加自增顺序编号的 znode 节点,比如 ClientA 去 zookeeper service 上建立一个 znode 名字叫做 /zk/conf,指定 了这种类型的节点后zk会创建 /zk/conf0000000000,ClientB 再 去创建就是创建 /zk/conf0000000001,ClientC 是创建 /zk/conf0000000002,以后任意 Client 来创建这个 znode 都会 得到一个比当前 zookeeper 命名空间最大 znod e编号 +1 的 znode,也就说任意一个 Client 去创建 znode 都是保证得到的 znode 编号是递增的,而且是唯一的 znode 节点 |
| EPHEMERAL | 临时 znode 节点,Client 连接到 zk service 的时候会建立一个 session,之后用这个 zk 连接实例在该 session 期间创建该类型的 znode,一旦 Client 关闭了 zookeeper 的连接,服务器就会清除 session,然后这个 session 建立的 znode 节点都会从命名空间消 失。总结就是,这个类型的 znode 的生命周期是和 Client 建立的 连接一样的。比如 ClientA 创建了一个 EPHEMERAL 的 /zk/conf 的 znode 节点,一旦 ClientA 的 zookeeper 连接关闭,这个 znode 节点就会消失。整个zookeeper service命名空间里就会删 除这个znode节点 |
| EPHEMERAL_SEQUENTIA | 临时自动编号节点 znode 节点编号会自动增加 但是会随session 消失而消失 |
注意点:
1、创建 znode 时设置顺序标识,znode 名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
2、在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
3、EPHEMERAL 类型的节点不能有子节点,所以只能是叶子结点
4、客户端可以在 znode 上设置监听器
Zookeeper分布式锁
通常我们会把 ZooKeeper 上的节点(ZNode)看做一把锁,通过 create临时节点的方式来实现,当多个客户端都去创建一把锁的时候,那么只有成功创建了那个客户端才能拥有这把锁.
基于ZooKeeper的临时顺序节点 ,ZooKeeper比较适合来实现分布式锁:
- 顺序发号器: ZooKeeper的每一个节点,都是自带顺序生成器:在每个节点下面创建临时节点,新的子节点后面,会添加一个次序编号,这个生成的编号,会在上一次的编号进行 +1 操作
- 有序递增: ZooKeeper节点有序递增,可以保证锁的公平性,我们只需要在一个持久父节点下,创建对应的临时顺序节点,每个线程在尝试占用锁之前,会调用watch,判断自己当前的序号是不是在当前父节点最小,如果是,那么获取锁
- Znode监听: 每个线程在抢占锁之前,会创建属于当前线程的ZNode节点,在释放锁的时候,会删除创建的ZNode,当我们创建的序号不是最小的时候,会等待watch通知,也就是上一个ZNode的状态通知,当前一个ZNode删除的时候,会触发回调机制,告诉下一个ZNode,你可以获取锁开始工作了
- 临时节点自动删除: ZooKeeper还有一个好处,当我们客户端断开连接之后,我们出创建的临时节点会进行自动删除操作,所以我们在使用分布式锁的时候,一般都是会去创建临时节点,这样可以避免因为网络异常等原因,造成的死锁。
- 羊群效应: ZooKeeper节点的顺序访问性,后面监听前面的方式,可以有效的避免 羊群效应,什么是羊群效应:当某一个节点挂掉了,所有的节点都要去监听,然后做出回应,这样会给服务器带来比较大压力,如果有了临时顺序节点,当一个节点挂掉了,只有它后面的那一个节点才做出反应。
Zookeeper CP
Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)
Zookeeper遵循的是CP原则,也就是选择了一致性,牺牲了可用性。具体体现在:
当Leader挂掉的时候,集群会马上重选Leader。但这个选举时长在30-120秒之间,在这期间Follower都是Looking状态,是不能提供服务的,相当于集群整个就瘫痪了,所以不满足可用性。
那么为什么Zookeeper的选举如此耗时呢?因为Zookeeper要保证各个节点中数据的一致性,它会做两类数据同步:初始化同步与更新同步。
Leader选举出来以后,Follower需要将Leader的数据同步到自己的缓存之中,这就是初始化同步。
另外,如果Leader的数据被修改,也有单点写问题,写性能不高,Leader会给Follower发广播通知,然后各个Follower会主动去同步Leader更新的数据,这个就是更新同步。在这两个同步的过程中,Zookeeper为了保持数据一致性,如果发现有超过半数的Follower同步时间超时,它会再次进行同步,而这个过程中,集群是不可用的。
以上说的就是Zookeeper的致命问题,可用性低,因为它采取的是CP原则。相较之下,SpringCloud的Eureka在分布式系统中的作用类似于Zookeeper,不过其采用的是AP原则,即牺牲一致性,换取可用性。
ZK的Watcher机制
监听工作原理:ZooKeeper 的 Watcher 机制主要包括客户端线程、客户端 WatcherManager、 Zookeeper 服务器三部分。客户端在向 ZooKeeper 服务器注册的同时,会将 Watcher 对象存储在客户端的 WatcherManager 当中。当 ZooKeeper 服务器触发 Watcher 事件后,会向客户端发送通知,客户端线程从 WatcherManager 中取出对应的 Watcher 对象来执行回调逻辑。
整个Watcher注册与通知过程如图所示。
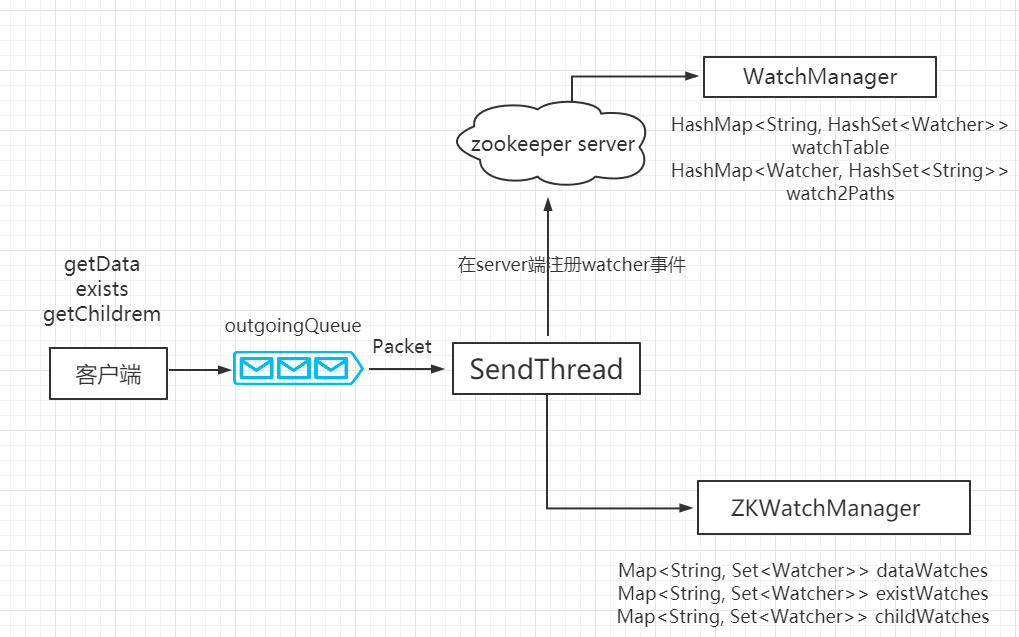
Zookeeper的Watcher机制主要包括客户端线程、客户端WatcherManager、Zookeeper服务器器三部 分。
客户端注册 watcher 有三种方式,调用客户端 API 可以分别通过 getData、exists、getChildren 实现。
Watcher事件类型(EventType)
EventType是数据节点(znode)发生变化时对应的通知类型。EventType变化时KeeperState永远处于SyncConnected通知状态下;当KeeperState发生变化时,EventType永远为None。其路径为org.apache.zookeeper.Watcher.Event.EventType,是一个枚举类,枚举属性如下;
| 枚举属性 | 说明 |
|---|---|
| None (-1) | 无 |
| NodeCreated (1) | Watcher监听的数据节点被创建时 |
| NodeDeleted (2) | Watcher监听的数据节点被删除时 |
| NodeDataChanged (3) | Watcher监听的数据节点内容发生变更时(无论内容数据是否变化) |
| NodeChildrenChanged (4) | Watcher监听的数据节点的子节点列表发生变更时 |
客户端接收到的相关事件通知中只包含状态及类型等信息,不包括节点变化前后的具体内容,变化前的数据需业务自身存储,变化后的数据需调用get等方法重新获取。
Watcher注册及通知流程
客户端Watcher管理器:ZKWatchManager数据结构
//ZKWatchManager维护了三个map,key代表数据节点的绝对路径,value代表注册在当前节点上的watcher集合
//代表节点上内容数据、状态信息变更相关监听
private final Map<String, Set<Watcher>> dataWatches =
new HashMap<String, Set<Watcher>>();
//代表节点变更相关监听
private final Map<String, Set<Watcher>> existWatches =
new HashMap<String, Set<Watcher>>();
//代表节点子列表变更相关监听
private final Map<String, Set<Watcher>> childWatches =
new HashMap<String, Set<Watcher>>();
服务端Watcher管理器:WatchManager数据结构
//WatchManager维护了两个map
//说明:WatchManager中的Watcher对象不是客户端用户定义的Watcher,
// 而是服务端中实现了Watcher接口的ServerCnxn抽象类,
// 该抽象类代表了一个客户端与服务端的连接
//key代表数据节点路径,value代表客户端连接的集合,该map作用为:
//通过一个指定znode路径可找到其映射的所有客户端,当znode发生变更时
//可快速通知所有注册了当前Watcher的客户端
private final HashMap<String, HashSet<Watcher>> watchTable =
new HashMap<String, HashSet<Watcher>>();
//key代表一个客户端与服务端的连接,value代表当前客户端监听的所有数据节点路径
//该map作用为:当一个连接彻底断开时,可快速找到当前连接对应的所有
//注册了监听的节点,以便移除当前客户端对节点的Watcher
private final HashMap<Watcher, HashSet<String>> watch2Paths =
new HashMap<Watcher, HashSet<String>>();
Watcher注册流程
//Packet对象构造函数
//参数含义:请求头、响应头、请求体、响应体、Watcher封装的注册体、是否允许只读
Packet(RequestHeader requestHeader, ReplyHeader replyHeader,
Record request, Record response,
WatchRegistration watchRegistration, boolean readOnly) {
this.requestHeader = requestHeader;
this.replyHeader = replyHeader;
this.request = request;
this.response = response;
this.readOnly = readOnly;
this.watchRegistration = watchRegistration;
}

1. 客户端发送的请求中只包含是否需要注册Watcher,不会将Watcher实体发送;
2. Packet构造函数中的参数WatchRegistration是Watcher的封装体,用于服务响应成功后将Watcher保存到ZKWatchManager中;
Watcher通知流程
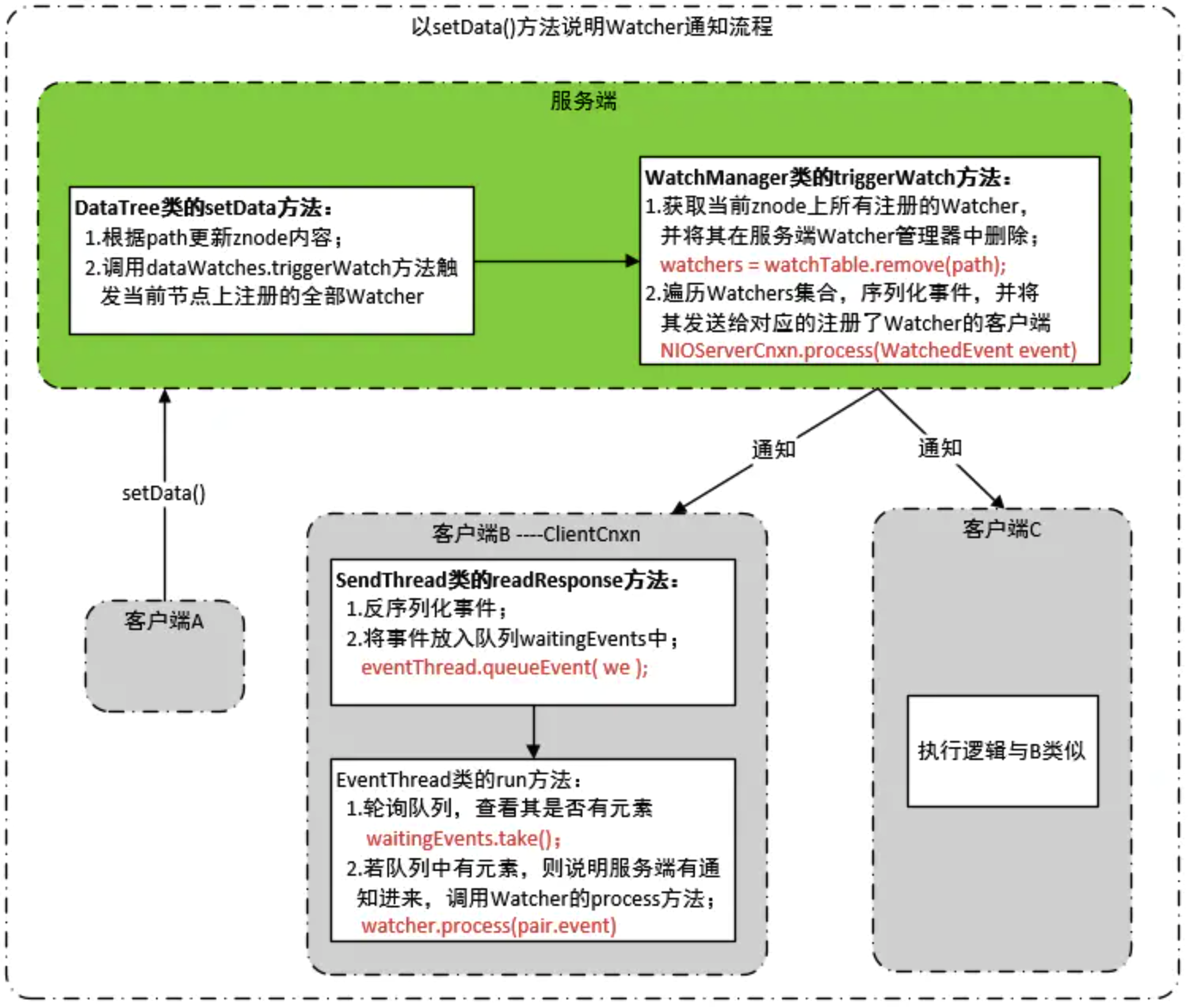
Watch机制特点
- 主动推送 Watch被触发时,由 Zookeeper 服务器主动将更新推送给客户端,而不需要客户端轮询。
- 一次性 数据变化时,Watch 只会被触发一次。如果客户端想得到后续更新的通知,必须要在 Watch 被触发后重新注册一个 Watch。
- 可见性 如果一个客户端在读请求中附带 Watch,Watch 被触发的同时再次读取数据,客户端在得到 Watch 消息之前肯定不可能看到更新后的数据。换句话说,更新通知先于更新结果。
- 顺序性 如果多个更新触发了多个 Watch ,那 Watch 被触发的顺序与更新顺序一致。
参考:
深入浅出Zookeeper(一) Zookeeper架构及FastLeaderElection机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号