问题收集
1.Future 线程的保护性暂停
一个线程等待另一个线程的执行结果
2.volatile在DCL(单例模式)中应用,代码重排序,双重锁定
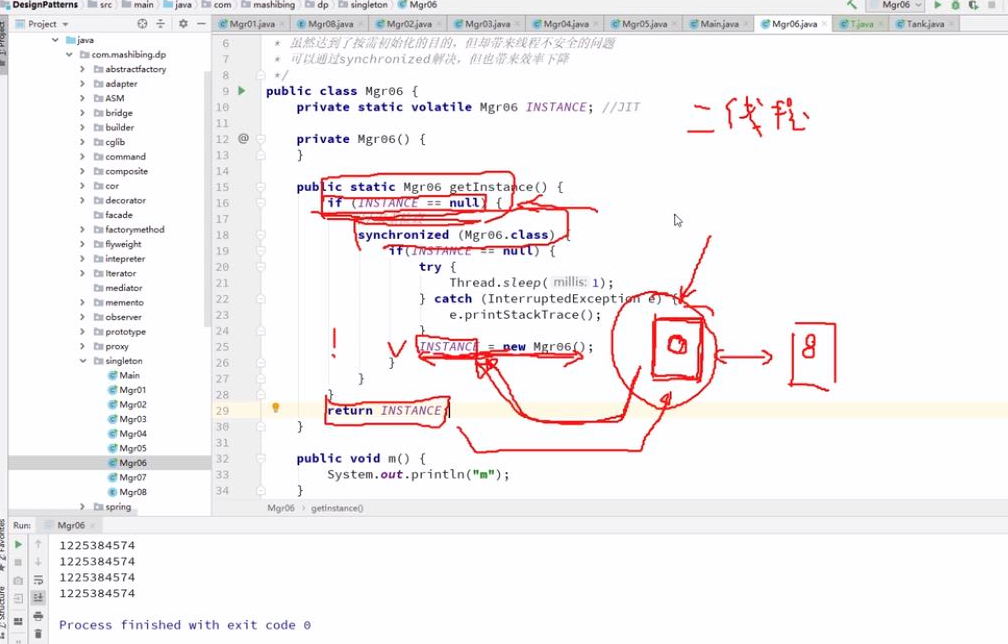
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
// 如果为空则new一个
if (instance == null) { //这个判断是为了提高性能,synchronized性能低
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
第一个线程执行到new Singleton(),实例化对象不是一个原子性操作,如果重排序以后,先赋值new对象到instance,然后再初始化。当赋值完以后,instance还是为null,第二个线程就可以进入同步代码块了。
在这个场景中,如果不用 volatile 修饰 instance 变量,那么可能会导致出现以下情况:
- 由于重排序使得第一个线程先将未初始化的
Singleton对象赋值给instance,然后再执行初始化 - 另一个线程在获取单例对象时,
instance已经不为null,所以可以直接获取到并进行后续操作,然而此时instance还未初始化。
很明显加了 volatile 后禁止了特定的重排序,使得程序能够正常执行。
3.为什么列表遍历元素过程中不能删除元素
fail-fast 快速失败机制
modCount 是AbstractList的一个字段,用来表示这个容器实例被修改的次数,如果容器中的元素有增加、移除等操作的都会修改这个值。
expectedModCount 是一个字段,在很多类的很多方法内都会有。在创建的时候,会将modCount 赋值给expectedModCount,
每当迭代器使用hashNext()/next()遍历下一个元素之,就会检测modCount变量是否为expectedModCount值,是就遍历,反之抛出Concurrent Modification Exception 异常。
这个异常只是用于建议性的检测并发修改的bug。
如果没有这种机制,多线程随意新增删除,那么列表中的数据就会混乱,但是注意,修改是没有问题的。
当大家遍历那些非线程安全的数据结构时,尽量使用迭代器。
符合 Fail-Fast 机制的集合类包括:
Map: HashMap LinkedHashMap TreeMap HashTable
Set: HashSet LinkedHashSet TreeSet
List: ArrayList LinkedList Vector
上述HashTable,Vector两个类虽然是线程安全的,但是也有快速失败机制(单线程也可以边遍历边删除|新增)
fail-safe 安全失败机制
采用安全失败机制的集合,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历的。
因为时对原集合的拷贝进行遍历,所以在遍历过程中对原集合的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
虽然fail-safe不会抛出异常,但存在以下缺点:
- 复制时需要额外的空间和时间上的开销。
- 不能保证遍历的是最新内容。
java.util.concurrent包下的容器集合都是安全失败,可以在多线程下并发使用,并发修改。
聊聊 ConcurrentModificationException
4.一致性哈希
老式hash取模算法:下线一个服务器或者上线一个新的服务器,那么原来的映射将全部失效,需要rehash,一段时间之内不可用,且每次扩缩容都会出现这个问题。
一致性哈希,有效地解决分布式存储结构下普通余数Hash算法带来的伸缩性差的问题,可以保证在动态增加和删除节点的情况下尽量有多的请求命中原来的机器节点。
哈希环
一致性Hash算法将整个Hash值组织成一个虚拟的圆环,整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^ 32-1,也就是说0点左侧的第一个点代表2^ 32-1, 0和2^ 32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
数据倾斜与虚拟节点机制
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题
一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node 1#1”、“Node 1#2”、“Node 1#3”、“Node 2#1”、“Node 2#2”、“Node 2#3”的哈希值,于是形成六个虚拟节点:
Redis和一致性哈希
Redis 集群没有使用一致性hash, 而是引入了哈希槽slots的概念。
redis集群时3.0版本才出现的,出现的比较晚,在集群模式出现之前,很多公司都做了自己的redis集群了。这些自研的redis集群的实现方式有多种,比如在redis的jedis客户端jar包就是实现了一致性hash算法(客户端模式),或者在redis集群前面加上一层前置代理如Twemproxy也实现了hash一致性算法(代理模式)。
Redis哈希槽
一个 Redis Cluster包含16384(0~16383)个哈希槽,存储在Redis Cluster中的所有键都会被映射到这些slot中,
集群中的每个键都属于这16384个哈希槽中的一个,集群使用公式slot=CRC16(key)/16384来计算key属于哪个槽,其中CRC16(key)语句用于计算key的CRC16 校验和。
按照槽来进行分片,通过为每个节点指派不同数量的槽,可以控制不同节点负责的数据量和请求数.
数据分布算法:hash+ 一致性 hash + redis cluster 的 hash slot
5.spring-boot项目pom文件添加的依赖的bean是如何注册到spring容器中
@ComponentScan注解只能扫描spring-boot项目包内的bean并注册到spring容器
@EnableAutoConfiguration注解来注册项目包外的bean
META-INF/spring.factories文件,则是用来记录项目包外需要注册的bean类名。
6.使用@AutoConfigureBefore、After、Order调整Spring Boot自动配置顺序无效
@AutoConfigureBefore、@AutoConfigureAfter、@AutoConfigureOrder三大注解控制自动配置执行顺序
上述注解必须在业务系统的引用的项目中,使用META-INF/spring.factories注册的bean上,使用注解才有效
不能在自己的业务系统内调用上述的三个注解,因为SpringBoot会使用@ComponentScan扫描业务系统路径下的配置
自动配置先执行,spring.factories配置后执行,请尽量不要让自动配置类既被扫描到了,又放在spring.factories配置了,否则后者会覆盖前者,很容易造成莫名其妙的错误
使用@AutoConfigureBefore、After、Order调整Spring Boot自动配置顺序
7.Mysql为什么不推荐使用uuid或者雪花id作为主键
自增长主键
自增的主键的值是顺序的,所以Innodb把每一条记录都存储在一条记录的后面。当达到页面的最大填充因子时候(innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的修改)
- 数据按照顺序方式新增插入,主键页就会近乎被顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
- 新插入的行一定会在原有的最大数据行下一行,
mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗 - 少了页分裂和碎片的产生
缺点:
- 别人一旦爬取你的数据库,就可以根据数据库的自增
id获取到你的业务增长信息,很容易分析出你的经营情况 - 对于高并发的负载,
innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争 Auto_Incremen锁机制会造成自增锁的抢夺,有一定的性能损失
非自增长主键
因为uuid数据毫无规律,无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置分配新的空间。这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
-
写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,
innodb在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机IO -
因为写入是乱序的,
innodb不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据 -
由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片
在把随机值(uuid和雪花id)载入到聚簇索引(innodb默认的索引类型)以后,有时候会需要做一次OPTIMEIZE TABLE来重建表并优化页的填充,这将又需要一定的时间消耗。
深入分析mysql为什么不推荐使用uuid或者雪花id作为主键
8.@Configuration与@Component
@Configuration标注在类上,相当于把该类作为spring的xml配置文件中的<beans>,作用为:配置spring容器(应用上下文),所以@Configuration标注的类都是用来注册Bean实例
注册Bean实例,除了上述方式以外,还可以用@Component、@Controller、@Service、@Ripository等注解注册bean,当然需要配置@ComponentScan注解进行自动扫描
Spring整理系列(11)——@Configuration注解、@Bean注解以及配置自动扫描、bean作用域
9.布尔类型变量为什么不建议使用isXXX
平常使用到boolean以及Boolean类型的数据,前者是基本数据类型,后者是包装类
- 对于非
boolean类型的参数,getter和setter方法命名的规范是以get和set开头 - 对于
boolean类型的参数,setter方法是以set开头,但是getter方法命名的规范是以is开头 - 包装类自动生成的
getter和setter方法的名称都是getXXX()和setXXX()
- 其实
javaBeans规范中对这些均有相应的规定,基本数据类型的属性,其getter和setter方法是getXXX()和setXXX,但是对于基本数据中布尔类型的数据,又有一套规定,其getter和setter方法是isXXX()和setXXX。但是包装类型都是以get开头 - 这种方式在某些时候是可以正常运行的,但是在一些
rpc框架里面,当反向解析读取到isSuccess()方法的时候,rpc框架会“以为”其对应的属性值是success,而实际上其对应的属性值是isSuccess,导致属性值获取不到,从而抛出异常。
1、boolean类型的属性值不建议设置为is开头,否则会引起rpc框架的序列化异常。
2、如果强行将IDE自动生成的isSuccess()方法修改成getSuccess(),也能获取到Success属性值,若两者并存,则之后通过getSuccess()方法获取Success属性值。
为什么阿里巴巴不建议 boolean 类型变量用 isXXX?
10.为什么不能使用catch(Throwable e)
因为这样会捕捉到Throwable的子类Error,Error是一种严重的问题,这种错误是不可以恢复的,应用程序不应该捕捉它。
Error:一般为底层的不可恢复的类;Exception:分为未检查异常(RuntimeException)和已检查异常(非RuntimeException)。
未检查异常是因为程序员没有进行必需要的检查,因为疏忽和错误而引起的错误。几个经典RunTimeException如下:
1.java.lang.NullPointerException;
2.java.lang.ArithmaticException;
3.java.lang.ArrayIndexoutofBoundsException
Runtime Exception:
在定义方法时不需要声明会抛出runtime exception; 在调用这个方法时不需要捕获这个runtime exception;runtime exception是从java.lang.RuntimeException或java.lang.Error类衍生出来的。 例如:nullpointexception,IndexOutOfBoundsException就属于runtime exceptionException:
定义方法时必须声明所有可能会抛出的exception; 在调用这个方法时,必须捕获它的checked exception,不然就得把它的exception传递下去;exception是从java.lang.Exception类衍生出来的。例如:IOException,SQLException就属于Exception
11.JAVA中,GC ROOT的对象有哪些
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中
JNI(即一般说的Native方法)引用的对象。
12.CMS垃圾收集流程
-
初始标记(init-mark):仅扫描与根节点直接关联的对象并标记,这个阶段必须STW, 由于跟节点数量有限,所以这个过程非常短暂。 -
并发标记(concurrent-marking):与用户线程并发标记。这个阶段在初始标记的基础上继续向下追溯标记。在并发标记阶段,用户线程和标记线程并发执行,所以用户不会感受到停顿。**遍历第一个阶段(
Init Mark)标记出来的存活对象,继续递归遍历老年代,并标记可直接或间接到达的所有老年代存活对象在这个阶段,发生变化的对象标记为Dity** -
并发预清理(concurrent-precleaning):与用户线程并发进行。在并发标记阶段一些对象的引用已经发生了变化,precleaning会发现这些引用关系的改变,并将存活的对象标记。举个例子:如果线程A有一个指向对象X的引用,并将该引用传递给了线程B,CMS需要记录下线程B持有了对象X,即使线程A已经不存在了。precleaning是为了减少下一阶段“重新标记”的工作量,因为remark阶段会STW。将会重新扫描前一个阶段标记的Dirty对象,并标记被Dirty对象直接或间接引用的对象
-
重新标记(remark):remark阶段会STW。如果应用正在并发运行且在不断地改变对象引用,CMS则不能准确地确定某个对象是否存活。所以CMS会在remark阶段STW,从而获取所有引用关系的改变。 -
并发清理(concurrent-sweeping):清理垃圾对象,这个阶段GC线程和用户线程并发执行。 -
并发重置(concurrent-reset):重置CMS收集器的数据结构,做好下一次执行GC任务的准备工作。
13.hashmap设置长度为1w,请问可以新增10001值吗
可以,因为hashmap扩容,都为2的n次方,所以容量肯定大于1w
14.volatile 可见性,有序性实现方式
volatile也保证变量的读取和写入操作都是原子操作,注意这里提到的原子性只是针对变量的读取和写入,并不包括对变量的复杂操作,比如i++就无法使用volatile来确保这个操作是原子操作。
可见性实现方式:
对一个变量加了volatile关键字修饰之后,只要一个线程修改了这个变量的值,立马强制刷回主内存。
接着强制过期其他线程的本地工作内存中的缓存,最后其他线程读取变量值的时候,强制重新从主内存来加载最新的值!
这样就保证,任何一个线程修改了变量值,其他线程立马就可以看见了!这就是所谓的volatile保证了可见性的工作原理!
- 总线加锁(此方法性能较低,现在已经不会再使用)。
- MESI协议: 这是
Intel提出的,MESI协议也是相当复杂,在这里我就简单的说下:当一个CPU修改了Cache中的数据,会通知其他缓存了这个数据的CPU,其他CPU会把Cache中这份数据的Cache Line置为无效,要读取数据的话,直接去内存中获取,不会再从Cache中获取了。
有序性实现方式:
代码在运行的时候,执行顺序可能并不是严格从上到下执行的,会进行指令重排。
根据CPU流水线作业,一般来说简单的操作会先执行,复杂的操作后执行。
指令重排会有两个规则:
- as-if-seria:不管怎么重排序,单线程的执行结果不能发生改变。正是由于这个特性,在单线程中,程序员一般无需理会重排序带来的问题。
- happens-before,如果A
happens-beforeB,那么Java内存模型将向程序员保证——A操作的结果将对B可见,且A的执行顺序排在B之前。
JMM其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。JMM这么做的原因是:程序员对于这两个操作是否真的被重排序并不关心,程序员关心的是程序执行时的语义不能被改变(即执行结果不能被改变)。因此,happens-before关系本质上和as-if-serial语义是一回事。
实现方式,内存屏障
内存屏障主要有两个作用:
- 阻止屏障两侧的指令重排序;
- 强制把写缓冲区与高速缓存的脏数据等写回主内存,让缓存中相应的数据失效。
内存屏障可以分为两种:
- Load Barrier:读屏障,在指令前插入 Load Barrier,可以让高速缓存中的数据失效,强制从主内存中加载数据;
- Store Barrier:写屏障,在指令后插入 Store Barrier,可以将写入缓存中的最新数据更新写入到主内存中,令其他线程可见;
volatile 读前插读屏障,写后加写屏障,避免 CPU 重排导致的问题,实现多线程之间数据的可见性。将两种内存屏障进行两两组合,可以完成数据同步操作,也是 volatile 关键字的关键。
15.JMM Java内存模型什么作用
Java内存模型就是为了解决多线程对共享数据的读写一致性问题
16.JDK动态代理为什么继承接口,不使用继承类
因为Jdk动态代理生成的代理类,必须继承Proxy类并实现我们自定义的接口,而Java类继承是单继承,所以只能继承接口
jdk动态代理与cglib代理的区别
JDK动态代理:
利用拦截器(拦截器必须实现InvocationHanlder加上反射机制生成一个实现代理接口的匿名类,
在调用具体方法前调用InvokeHandler来处理。
CGLiB动态代理:
利用ASM开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。(不能对final,static,private方法进行代理)
Spring怎么选择jdk动态代理,cglib代理
Bean实现接口就使用jdk动态代理,没有实现接口就使用cglib代理,当然也可以设置为强制使用cglib代理
jdk动态代理,cglib代理效率怎么样
jdk动态代理在不同jdk版本中不断优化,cglib代理没跟进
在jdk8上,不管少数使用,还是批量使用,都是jdk动态代理性能高
在jdk8前,在批量使用的时候,cglib代理效率高些,少数使用是,还是jdk动态代理效率高。
17.Spring事务Transactional,事务失效场景
Spring事务Transactional和动态代理(三)-事务失效的场景
一口气说出 6种 @Transactional 注解失效场景
-
底层数据库不支持事务
-
注解在非
public方法上- 注解使用
AOP,AOP的两种代理方式,jdk动态代理方式,通过接口生成代理类,接口方法是public的,所以方法一定是public的,cglib代理通过生成子类的方式,复写方法,也要非final的public方法
- 注解使用
-
同一个类的方法内调用
- 这是由于
Spring AOP代理造成的,因为只有当事务方法被当前类以外的代码调用时,才会由Spring生成的代理对象来管理。
- 这是由于
-
rollbackFor设置错误- 触发事务回滚的异常类型,默认为
unchecked(RuntimeException)异常或Error异常,如果事务执行过程中发生了IOException,那么可能造成只有部分数据提交。
- 触发事务回滚的异常类型,默认为
-
propagation传播隔离级别设置错误PROPAGATION_SUPPORTS,PROPAGATION_NOT_SUPPORTED,PROPAGATION_NEVER这三种方式事务失效
-
异常被捕获且未抛出
-
两事务AB,A内部调用B,B发生异常,A内部进行捕获并不抛出,此时会发生异常
UnexpectedRollbackException:Transaction rolled back because it has been marked as rollback-onlyAB嵌套事务,B内发生异常,B识别是要回滚,但是事务最后执行了提交,不是回滚,
rollback-only用来标记内层事务出现异常,外层为rollback如果希望B发生异常不影响A,可以设置B的隔离为PROPAGATION_NESTED
-
18.为什么阿里巴巴Java开发手册明确禁止使用Executors来创建线程池
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式规避资源耗尽的风险。
Executors 返回的线程池对象的弊端如下:
FixedThreadPool 和 SingleThreadPool : 允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
CachedThreadPool 和 ScheduledThreadPool : 允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
除了Executors.newWorkStealingPool方法之外,其他的方法都有OOM的风险
19.为什么HashMap的加载因子为0.75
加载因子太大,hash冲突机率就比较大,容易造成数组中其中一条链表较长,太小,浪费空间
设置为0.75,与泊松分布式有关,具体百度
20.HashMap多线程操作导致死循环
jdk1.8之前并发下rehash是头插法,会造成元素直接形成一个循环链表,但是1.8后修改为了尾插法,但还是建议多线程下不使用HashMap,建议使用ConcurrentHashMap
什么条件转换为红黑树
当链表长度大于等于8并且数组长度大于64时,才会转换为红黑树
链表小于等于6树还原转为链表,大于等于8转为树
为什么优先使用链表,实在不行才转换为红黑树?
链表取一个数需要遍历链表,复杂度为O(N),而红黑树为O(logN)
因为树节点的大小是链表节点大小的两倍(TreeNodes占用空间是普通Nodes的两倍),所以只有在容器中包含足够的节点保证使用才用它,显然尽管转为树使得查找的速度更快,但是在节点数比较小的时候,此时对于红黑树来说内存上的劣势会超过查找等操作的优势,自然使用链表更加好,但是在节点数比较多的时候,综合考虑,红黑树比链表要好。
为什么Map桶中的个数超过8才转换为红黑树
理想情况下随机hashCode算法下所有bin中节点的分布频率会遵循泊松分布,一个bin中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件。所以,之所以选择8,而是根据概率统计决定的。
21.限流算法
漏桶算法:固定容量的漏桶,按固定速率流出(流入超出桶容量就溢出,桶容量为空就不流出)
令牌桶算法:固定容量令牌的桶,可以控制速率往桶里添加令牌(桶满时,新加的令牌被丢弃或拒绝,桶中令牌不足,数据就被丢弃或进缓存区)
两种算法对比:漏桶算法流出速率是固定的,但是令牌桶算法可以通过控制令牌发放速率来控制数据处理速度
Guava提供了限流工具类RateLimiter,该类基于令牌桶算法来完成限流,非常易于使用。
22.破坏单例的方式
-
反序列化:一个单例对象,序列化后反序列化,得到的是另外一个对象
-
解决办法:让单例类实现
readResolve()方法public final class MySingleton implements Serializable { private MySingleton() { } private static final MySingleton INSTANCE = new MySingleton(); public static MySingleton getInstance() { return INSTANCE; } private Object readResolve() throws ObjectStreamException { return INSTANCE; } }
-
-
反射:
- 解决办法:
- 在私有的构造函数中加判断,校验是否已经创建单例,存在就抛出异常
- 使用枚举,枚举没有构造器而反射需要使用构造器来创建实例对象
- 解决办法:
23.Java SPI机制
SPI(Service Provider Interface)就是一种系统解耦的机制,SPI通过“基于接口编程”+“配置文件”来完成系统组件的动态加载,实现依赖解耦。
项目启动,会在加载依赖jar的META-INF文件夹下具体接口的全名的文件,内部就是接口的具体实现类。
这样可以实现热插拔,想换功能直接换jar包即可
SpringBoot中利用SPI实现了自动化配置,其实自动化配置就是将装配控制权,要装配哪些内容放到了Jar包的spring.factories文件中了。
24.ConcurrentHashMap在1.7,1.8区别
ConcurrentHashMap在1.7中使用Segment,而Segment 继承自 ReentrantLock
在1.8中,元素的节点上采用 CAS + synchronized 操作来保证并发的安全性
面试必问之 ConcurrentHashMap 线程安全的具体实现方式
25.写饥饿以及StampedLock
比如在读线程非常多,写线程很少的情况下,很容易导致写线程饥饿
ReentrantReadWriteLock中读锁是一种共享锁,允许多个线程同时获取锁,写锁是一种独占锁,同一时刻只允许一个线程获取。
在读多写少的情况下,使用默认的非公平读写锁,线程想要获取到写锁变得极为困难,因为当前可能一直存在读锁,同步队列中的第一个节点一直会是共享节点,这样就无法获取到写锁。
StampedLock内存实现是基于CLH锁,提供了三种模式来控制读写操作:写锁 writeLock、悲观读锁 readLock、乐观读 Optimistic reading。
核心思想在于,在读的时候如果发生了写,应该通过重试的方式来获取新的值,而不应该阻塞写操作。
Java并发(8)- 读写锁中的性能之王:StampedLock
26.nginx挂掉以后,怎么继续访问服务
27.阿里SLB负载均衡 nginx与ribbon区别
负载均衡(Server Load Balancer,简称SLB)是对多台云服务器进行流量分发的负载均衡服务。
28.ArrayList扩容机制
jdk1.5 : (oldCapacity*3)/2+1
jdk1.7: oldCapacity + (oldCapacity >> 1)
29.kafka与rabbitmq区别
rabbitmq作为交易数据作为数据传输管道,主要的取舍因素则是是否存在丢数据的可能;rabbitmq在金融场景中经常使用,具有较高的严谨性,数据丢失的可能性更小,同事具备更高的实时性;kafka优势主要体现在吞吐量上,虽然可以通过策略实现数据不丢失,但从严谨性角度来讲,大不如rabbitmq;而且由于kafka保证每条消息最少送达一次,有较小的概率会出现数据重复发送的情况;
1.应用场景方面
RabbitMQ:用于实时的,对可靠性要求较高的消息传递上。
kafka:用于处于活跃的流式数据,大数据量的数据处理上。
30.使用枚举写单例
public enum EnumSingleton {
INSTANCE;
}
创建枚举默认就是线程安全的,所以不需要担心double checked locking,而且还能防止反序列化导致重新创建新的对象。
31.GC触发条件
Minor GC触发条件:当Eden区满时,触发Minor GC。
Full GC触发条件:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法去空间不足
32.Spring IOC
IOC指的就是控制反转,在Spring中就是对象实例不再由调用者创建,而是由Spring容器创建,Spring容器会负责控制对象之间的关系,控制权转移到了Spring容器中,控制权发生了反转,即控制反转。
Spring IOC提供了两种IOC容器,分别是BeanFactory和ApplicationContext。
BeanFactory是基础的IOC容器,是一个接口,提供了完整的IOC服务,BeanFactory是一个管理Bean的工厂,他主要负责初始化各种bean,并调用它们的生命周期方法。
ApplicationContext是继承BeanFactory的接口,也被称为应用上下文,不仅提供了BeanFactory的所有功能,还添加了对国际化、资源访问、事件传播等方面的支持。
BeanFactory与FactoryBean区别
BeanFactory是个Factory,也就是IOC容器或对象⼯⼚,它负责生产和管理bean的一个工厂。在Spring中,BeanFactory是IOC容器的核心接口,它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。BeanFactory只是个接口,并不是IOC容器的具体实现,但是Spring容器给出了很多种实现,如 DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,其中XmlBeanFactory就是常用的一个,该实现将以XML方式描述组成应用的对象及对象间的依赖关系。ApplicationContext接口,它由BeanFactory接口派生而来,ApplicationContext包含BeanFactory的所有功能,通常建议比BeanFactory优先
FactoryBean是个Bean。一般情况下,Spring通过反射机制利用<bean>的class属性指定实现类实例化Bean,在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,则需要在<bean>中提供大量的配置信息。配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。Spring为此提供了一个org.springframework.bean.factory.FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。
33.为什么压缩指针超过32G会失效?
首先在64位机器下,指针地址大小是8个字节,且对象按照8字节对齐存储。
32位机器指针大小是4个字节,能寻址空间大小是 2^32字节 = 4G 。
64位JVM在开启指针压缩后,一个4字节压缩指针能寻址的空间从1字节变成了8字节(8字节对齐) ,所以能寻址的总内存大小就是2^32 * 8 = 32G。
34.String有长度限制吗?是多少?
首先字符串的内容是由一个字符数组 char[] 来存储的,由于数组的长度及索引是整数,且String类中返回字符串长度的方法length() 的返回值也是int ,所以通过查看java源码中的类Integer我们可以看到Integer的最大范围是2^31 -1,由于数组是从0开始的,所以数组的最大长度可以使【0~2^31】通过计算是大概4GB。
但是通过翻阅java虚拟机手册对class文件格式的定义以及常量池中对String类型的结构体定义我们可以知道对于索引定义了u2,就是无符号占2个字节,2个字节可以表示的最大范围是2^16 -1 = 65535。
其实是65535,但是由于JVM需要1个字节表示结束指令,所以这个范围就为65534了。超出这个范围在编译时期是会报错的,但是运行时拼接或者赋值的话范围是在整形的最大范围。
35.虚拟机栈 栈帧
虚拟机栈
与程序计数器⼀样,Java虚拟机栈也是线程私有的,它的⽣命周期和线程相同,描述的是 Java 方法执行的内存模型,每次方法调用的数据都是通过栈传递的。
Java 虚拟机栈会出现两种异常:StackOverFlowError 和 OutOfMemoryError。
- StackOverFlowError: 若
Java虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前Java虚拟机栈的最大深度的时候,就抛出StackOverFlowError异常。 - OutOfMemoryError: 若
Java虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出OutOfMemoryError异常。
栈描述的是Java方法执行的内存模型;执行一个方法时会产生一个栈帧,随后将其保存到栈(后进先出)的顶部,方法执行完毕后会自动将此方法对应的栈帧自顶部移除(即:出栈),当前方法的栈帧必然在当前线程对应的栈的顶部。
栈中保存的是一个又一个栈帧。
栈帧
一个栈帧对应一个未运行完的函数;当某一个函数被调用一次时,就会产生一个栈帧(记录着该函数的相关信息),并入栈;当该函数运行完毕之后,其对应的栈帧会出栈。
函数的一次调用就会产生一个对应的栈帧,而不是一个函数本身对应一个栈帧;如:递归调用就会产生无数个栈帧。
从栈的结构可知:如果栈帧数量过多(n多次调用方法)或某个(些)栈帧过大会导致栈溢出引发SOE(Stack Overflow Error)。
如果允许虚拟机栈动态扩展,那么当内存不足时,会导致
OOM(OutOfMemoryError)。
栈帧中主要包含的数据有:
- 局部变量表(
Local Variable Table) - 操作数栈(
Operand Stack) - 返回地址(
Return Adderss) - 动态链接(
Dynamic Linking): - 指向运行时常量池的引用:
36.方法区与永久代
《Java虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。 方法区和永久代的关系很像Java中接口和类的关系,类实现了接口,而永久代就是HotSpot虚拟机对虚拟机规范中方法区的⼀种实现方式。 也就是说,永久代是HotSpot的概念,方法区是Java虚拟机规范中的定义,是⼀种规范,而永久代是一种实现,⼀个是标准⼀个是实现,其他的虚拟机实现并没有永久代这一说法。
JDK 1.8 的时候,方法区(HotSpot的永久代)被彻底移除了(JDK1.7就已经开始了),取而代之是元空间,元空间使用的是直接内存。
37.GC过程中,那些过程是STW的
目前所有的年轻代的回收都是要STW的
老年代的化,CMS中的初始标记,重新标记为STW的,G1的话,
Serial:单线程STW,复制算法
ParNew:多线程并行STW,复制算法
Parallel Scavange:多线程并行STW,吞吐量优先,复制算法
G1:多线程并发,可以精确控制STW时间,整理算法
38.RabbitMQ如果保证消息不丢失
发送方确认模式
设置为发送确认模式,消息被投递到目标队列以后,会发送ack给producer,如果mq内部错误导致消息丢失,就会发送一个nack(notacknowledged,未确认)消息给生产者。发送确认模式是异步的,producer在等待确认的同时,可以继续发送消息,当确认消息到达生产者,生产者的回调方法就会被触发调用。
接受方确认机制 :rabbitmq判断与consumer的连接是否中断
- 如果
consumer返回ack给mq的过程中,连接断开,mq认为consumer没有收到,会重新发送,这时会有重新消费的隐患 - 如果
consumer消费了消息,但是没有返回ack,并且连接没有断开,那么mq认为consumer繁忙,也不会重新发送。
39.RabbitMQ如何保证消息不被重复消费
在消息生产时,MQ 内部针对每条生产者发送的消息生成一个 inner-msg-id,作为去重的依据(消息投递失败并重传),避免重复的消息进入队列;在消息消费时,要求消息体中必须要有一个 bizId(对于同一业务全局唯一,如支付 ID、订单 ID、帖子 ID 等)作为去重的依据,避免同一条消息被重复消费。
40.零拷贝
- mmap + write
- sendfile
41.FutureTask获取线程池返回值原理
FutureTask继承RunnableFuture接口,RunnableFuture接口继承Runnable,Future接口
FutureTask初始化,使用Callable初始化
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
使用Runnable初始化:
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
FutureTask通过Callable,Runnable创建new Thread()创建线程,通过start()方法启动线程- 执行
FutureTask中的run()方法 run方法调用Callable中的call方法,拿到返回值set到FutureTask的outcome成员变量中(Runnable通过RunnableAdapter转换为Callable)FutureTask通过get方法获取outcome对象值,从而成功拿到线程执行返回值
42.preHandle,postHandle和afterCompletion
-
preHandle:Controller方法处理前 若返回false,则中断执行,注意:不会进入afterCompletion -
postHandle:Controller处理完成,DispatcherServlet进行视图渲染前 -
afterCompletion:DispatcherServlet进行视图的渲染之后
应用场景:日志记录,权限检查,性能监控,通用行为
43.SpringBoot项目启动流程
- ①
Spring Boot在启动时会去依赖的Starter包中寻找resources/META-INF/spring.factories文件,然后根据文件中配置的Jar包去扫描项目所依赖的Jar包。 - ② 根据
spring.factories配置加载AutoConfigure类 - ③ 根据
@Conditional注解的条件,进行自动配置并将Bean注入Spring Context
总结一下,其实就是 Spring Boot 在启动的时候,按照约定去读取 Spring Boot Starter 的配置信息,再根据配置信息对资源进行初始化,并注入到 Spring 容器中。这样 Spring Boot 启动完毕后,就已经准备好了一切资源,使用过程中直接注入对应 Bean 资源即可。
44.Spring Boot 的自动配置是如何实现的
Spring Boot 项目的启动注解是:@SpringBootApplication,其实它就是由下面三个注解组成的:
- @
Configuration @ComponentScan@EnableAutoConfiguration
其中 @EnableAutoConfiguration 是实现自动配置的入口,该注解又通过 @Import 注解导入了AutoConfigurationImportSelector,在该类中加载 META-INF/spring.factories 的配置信息。然后筛选出以 EnableAutoConfiguration 为 key 的数据,加载到 IOC 容器中,实现自动配置功能!
45.Bean的生命周期
字节跳动面试题:“请你描述下 Spring Bean 的生命周期?”
- Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化
- Bean实例化后对将Bean的引入和值注入到Bean的属性中
- 如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
- 如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
- 如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来
- 如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
- 如果Bean 实现了InitializingBean接口,Spring将调用他们的afterPropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用
- 如果Bean 实现了BeanPostProcessor接口,Spring就将调用他们的postProcessAfterInitialization()方法。
- 此时,Bean已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
- 如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
46.Autowired是如何实现自动装配的
Spring框架你敢写精通,面试官就敢问@Autowired注解的实现原理
死磕Spring之IoC篇 - @Autowired 等注解的实现原理
47.简单说一下TCC
T(Try)锁资源:锁定某个资源,设置一个预备类的状态,冻结部分数据。
- 比如,订单的支付状态,先把状态修改为"支付中(PAYING)"。
- 比如,本来库存数量是 100 ,现在卖出了 2 个,不要直接扣减这个库存。在一个单独的冻结库存的字段,比如 prepare _ remove _ stock 字段,设置一个 2。也就是说,有 2 个库存是给冻结了。
- 积分服务的也是同理,别直接给用户增加会员积分。你可以先在积分表里的一个预增加积分字段加入积分。
- 比如:用户积分原本是 1190 ,现在要增加 10 个积分,别直接 1190 + 10 = 1200 个积分啊!你可以保持积分为 1190 不变,在一个预增加字段里,比如说 prepare _ add _ credit 字段,设置一个 10 ,表示有 10 个积分准备增加。
C(Confirm):在各个服务里引入了一个 TCC 分布式事务的框架,事务管理器可以感知到各个服务的 Try 操作是否都成功了。假如都成功了, TCC 分布式事务框架会控制进入 TCC 下一个阶段,第一个 C 阶段,也就是 Confirm 阶段。此时,需要把 Try 阶段锁住的资源进行处理。
- 比如,把订单的状态设置为“已支付(Payed)”。
- 比如,扣除掉相应的库存。
- 比如,增加用户积分。
C(Cancel):在 Try 阶段,假如某个服务执行出错,比如积分服务执行出错了,那么服务内的 TCC 事务框架是可以感知到的,然后它会决定对整个 TCC 分布式事务进行回滚。
TCC 分布式事务框架只要感知到了任何一个服务的 Try 逻辑失败了,就会跟各个服务内的 TCC 分布式事务框架进行通信,然后调用各个服务的 Cancel 逻辑。也就是说,会执行各个服务的第二个 C 阶段, Cancel 阶段。
- 比如,订单的支付状态,先把状态修改为" closed "状态。
- 比如,冻结库存的字段, prepare _ remove _ stock 字段,将冻结的库存 2 清零。
- 比如,预增加积分的字段, prepare _ add _ credit 字段,将准备增加的积分 10 清零。
48.线程池核心线程可以被回收吗 allowCoreThreadTimeOut
当设置ThreadPoolExecutor类中的私有变量allowCoreThreadTimeOut(true)时,线程池中corePoolSize线程空闲时间达到keepAliveTime也将关闭
allowCoreThreadTimeOut为true
该值为true,则线程池数量最后销毁到0个。allowCoreThreadTimeOut为false
销毁机制:超过核心线程数时,而且(超过最大值或者timeout过),就会销毁。
49.zookeeper临时节点可以有子节点吗
不可以
zk作为注册中心原理
- 是个分布式文件系统,每个znode可以存储数据
- 通过
心跳机制可以检测挂掉的机器并将挂掉机器的ip和服务对应关系从列表中删除 - 选举机制提高容错容灾能力
50.Thread.yeid方法,线程状态变化
yield 即 "谦让",也是 Thread 类的方法。它让掉当前线程 CPU 的时间片,使正在运行中的线程重新变成就绪状态,并重新竞争 CPU 的调度权。它可能会获取到,也有可能被其他线程获取到。
51.Spring Cloud Gateway跟注册中心交互流程
52.Hystrix流程与原理,降级与熔断的区别
Hystrix主要用来服务降级,熔断,隔离,监控,防止雪崩的技术
Hystrix 为每个依赖项维护一个小线程池(或信号量);如果它们达到设定值(触发隔离),则发往该依赖项的请求将立即被拒绝,执行失败回退逻辑(Fallback),而不是排队。
当Service A调用Service B,失败多次达到一定阀值,Service A不会再去调Service B,而会去执行本地的降级方法!
服务熔断
服务熔断:当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
//滑动窗口的大小,默认为20
circuitBreaker.requestVolumeThreshold
//过多长时间,熔断器再次检测是否开启,默认为5000,即5s钟
circuitBreaker.sleepWindowInMilliseconds
//错误率,默认50%
circuitBreaker.errorThresholdPercentage
每当20个请求中,有50%失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。直到5s钟之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。
服务降级
从整个系统的负荷情况出发和考虑的,对某些负荷会比较高的情况,为了预防某些功能(业务场景)出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的fallback(退路)错误处理信息。这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性。
- 当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
- 当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
服务降级有很多种降级方式!如开关降级、限流降级、熔断降级!
服务熔断属于降级方式的一种!
熔断降级区别
熔断是针对单个服务的
降级是针对整个系统的,宏观上的
Hystrix能解决如下问题:
- 请求超时降级,线程资源不足降级,降级之后可以返回自定义数据
- 线程池隔离降级,分布式服务可以针对不同的服务使用不同的线程池,从而互不影响
- 自动触发降级与恢复
- 实现请求缓存和请求合并
53.比线程池更好的方案
使用协程
Quasar 提供了高性能轻量级的线程,可以用在 Java 和 Kotlin 编程语言中。
Quasar 最主要的贡献就是提供了轻量级线程的实现 —— fiber。Fiber 的功能和使用类似 Thread, API 接口也类似,所以使用起来没有违和感,但是它们不是被操作系统管理的,它们是由一个或者多个 ForkJoinPool 调度。一个空闲的 fiber 只占用 400 字节内存,切换的时候占用更少的 CPU,你的应用中可以有上百万的 fiber,显然Thread 做不到这一点。
54.Nacos与eureka对比
eureka闭源了- 官网上
nacos注册实例数大于eureka nacos使用raft协议,nacos集群一致性要远大于eureka集群
nacos config使用长连接更新配置,一旦配置有变动后,通知provider的过程非常的迅速。
nacos热加载配置数据
Nacos采用的是Pull模式(Kafka也是如此),并且采用了一种长轮询机制。客户端采用长轮询的方式定时的发起Pull请求,去检查服务端配置信息是否发生了变更,如果发生了变更,那么客户端会根据变更的数据获得最新的配置。
长轮询:客户端发起轮询请求后,服务端如果有配置发生变更,就直接返回。
55.线程池底层逻辑流程
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
workerCount,生效的线程数。基本可以理解为存活的线程,但某个时候有暂时性的差异。runState,线程池的运行状态。
ctl(int32位)的低29位代表workerCount,所以最大线程数为(2^29)-1。另外高3位表示runState。
runState状态:
RUNNING:接收新任务,处理队列任务。SHUTDOWN:不接收新任务,但处理队列任务。STOP:不接收新任务,也不处理队列任务,并且中断所有处理中的任务。TIDYING:所有任务都被终结,有效线程为0。会触发terminated()方法。TERMINATED:当terminated()方法执行结束。
当调用了shutdown(),状态会从RUNNING变成SHUTDOWN,不再接收新任务,此时会处理完队列里面的任务。
如果调用的是shutdownNow(),状态会直接变成STOP。
当线程或者队列都是空的时候,状态就会变成TIDYING。
当terminated()执行完的时候,就会变成TERMINATED。
主要步骤:
线程池调用execute提交任务—>创建Worker(设置属性thead、firstTask)—>worker.thread.start()—>实际上调用的是worker.run()—>线程池的runWorker(worker)—>worker.firstTask.run();
Worker这个工作线程,实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务;firstTask用它来保存传入的第一个任务,这个任务可以有也可以为null。如果这个值是非空的,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况;如果这个值是null,那么就需要创建一个线程去执行任务列表(workQueue)中的任务,也就是非核心线程的创建。
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。线程池使用一张Hash表去持有线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期。这个时候重要的就是如何判断线程是否在运行。
Worker是通过继承AQS,使用AQS来实现独占锁这个功能。没有使用可重入锁ReentrantLock,而是使用AQS,为的就是实现不可重入的特性去反应线程现在的执行状态。
lock方法一旦获取了独占锁,表示当前线程正在执行任务中。- 如果正在执行任务,则不应该中断线程。
- 如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。
- 线程池在执行
shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则通过worker的unlock可以安全回收。
【Java线程池04】ThreadPoolExecutor的addWorker方法
56.@Async失效场景
- 异步方法使用
static修饰 - 异步类没有使用
@Component注解(或其他注解)导致spring无法扫描到异步类 - 异步方法不能与被调用的异步方法在同一个类中
- 类中需要使用
@Autowired或@Resource等注解自动注入,不能自己手动new对象 - 如果使用
SpringBoot框架必须在启动类中增加@EnableAsync注解
57.整个系统的可用性
- 多节点,
k8s灾备 - 网关限流
hystrix熔断降级
58.oom排查
-XX:+HeapDumpOnOutOfMemoryError 参数可以在发生 OOM 时自动进行 dump;
jmap 命令可以手动 dump;
使用MAT进行分析
59.GlobalFilter,GatewayFilter,WebFilter区别
webFilter是spring-web中的过滤器,其他两个是网关中自带的。
webFilter比网关中过滤器先执行。
GatewayFilter,GlobalFilter 优先级越低,越先执行。
GlobalFilter作用于全局路由上,GatewayFilter是更细粒度的过滤器,作用于指定的路由中。
60.rabbitmq,生产者发送消息到mq,mq没有ack就宕机
生产者没有收到mq的应答,超过一定时间就会重发
如果mq发送消息给消费者,但是消费者还没处理就宕机,这个时候mq等待一段时间以后没有收到应答,就会重发给消费者,消费者要防止重复消费。
61.cpu100%问题排查
-
top命令找pid, -
根据
ps -mq pid -o THREAD,tid,time,查找tid -
tid转换成16进制 -
jstackpiddump当前进程堆栈状态 -
根据
tid的16进制在dump文件内部进行查找相关文本日志信息
62.zookeeper选举成功怎么通知其他节点的
估计时广播,其他节点读更新自己的状态。
63.zookeeper注册发现原理
-
Znode数据模型 -
Watcher机制
服务注册发现流程
- 服务提供者启动向
zookeeper注册服务信息,即在zookeeper服务器创建服务节点,并在节点存储服务相关的数据(服务提供者ip,端口等) - 服务消费者启动时,向
zookeeper获取注册的服务信息并设置watch,并将注册的服务信息缓存本地。 - 但服务提供者宕机或不提供服务,
zookeeper对应服务节点就会被删除,触发了消费者在对应节点设置了watch,zookeeper会异步向服务所有相关的消费者发出节点删除的通知,服务消费者收到就更新服务列表缓存。
64.方法区溢出,虚拟机栈溢出排查
出现 StackOverflowError 异常时,会有明确错误堆栈可供分析,相对而言比较容易定位到问题所在。
如果是建立过多线程导致的 OutOfMemoryError,在不能减少线程数量或者更换 64 位虚拟机的情况下,就只能通过减少最大堆和减少栈容量来换取更多的线程,通过 “减少内存” 的手段来解决内存溢出。
-Xss 每个线程堆栈的大小。一般情况下256K是足够了。影响此进程中并发线程数大小等。
65.G1垃圾回收器停顿时间
G1的STW(stop the world)可控,可以使用-XX:MaxGCPauseMillis设置默认200ms
G1 分为年轻代和老年代,但它的年轻代和老年代比例,并不是那么“固定”,为了达到 MaxGCPauseMillis 所规定的效果,G1 会自动调整两者之间的比例。
200ms,这个数值是一个软目标,也就是说JVM会尽一切能力满足这个暂停要求,但是不能保证每次暂停一定在这个要求之内。根据测试发现,如果我们将这个值设定成50毫秒或者更低的话,JVM为了达到这个要求会将年轻代内存空间设定的非常小,从而导致youngGC的频率大大增高。所以我们并不设定这个参数.
如果你强行使用 -Xmn 或者 -XX:NewRatio 去设定它们的比例的话,我们给 G1 设定的这个目标将会失效.
66.Rabbitmq解决消息堆积
- 排查消费者消费性能瓶颈
- 新增多个消费者
- 新增消费者多线程处理
- 新增消息队列,将消息按顺序转移到一个新的队列,让消费者消费新队列中消息
- 修改
rabbitmq两个参数来增大消息的并发数:concurrentConsumers:对每个listener在初始化的时候设置并发消费者个数prefetchCount:批量获取消息条数。
67.rabbitmq消息丢失
消息在生产者丢失
rabbitmq发送发设置为异步确认模式.
可以实现ConfirmCallback接口,消息发送到exchange后触发回调。
消息在mq中丢失
持久化exchage,queue,message
消息在消费者丢失
比较重要的消息,可以设置手动ack
默认情况下消息消费者是自动 ack (确认)消息的,如果要手动 ack(确认)则需要修改确认模式为 manual
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual
channel.basicAck(tag,false);
需要注意的 basicAck 方法需要传递两个参数
- deliveryTag(唯一标识 ID):当一个消费者向
RabbitMQ注册后,会建立起一个Channel,RabbitMQ会用basic.deliver方法向消费者推送消息,这个方法携带了一个delivery tag, 它代表了 RabbitMQ 向该 Channel 投递的这条消息的唯一标识 ID,是一个单调递增的正整数,delivery tag的范围仅限于Channel - multiple:为了减少网络流量,手动确认可以被批处理,当该参数为 true 时,则可以一次性确认 delivery_tag 小于等于传入值的所有消息
68.线程池队列长度可否设置为0
SynchronousQueue是一种特殊的队列,长度为0,元素插入就要取走,元素取走之前插入操作不会结束。
一般的LinkedBlockingQueue队列长度不能设置为0
69.事务隔离
PROPAGATION_REQUIRED:如果当前没有事务,就新建一个事务,如果已经存在一个事务,就加入到这个事务中。这是最常见的选择。PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行。PROPAGATION_MANDATORY:使用当前的事务,如果当前没有事务,就抛出异常。PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起。PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
如果事务AB,A内部调用B,默认是Required,那么B中事务没生效,使用A的事务,如果是Nested,那么B中的事务会成功A事务的一个子事务,只有等A事务结束以后才提交。
70.SpringBoot自动装配实现原理
启动SpringBoot,其背后默认帮我们配置了很多自动配置类,下面来看SpringBootApplication注解:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
说一下三个注解:
- @
SpringBootConfiguration:Spring Boot的配置类,标注在某个类上,表示这是一个Spring Boot的配置类(等于xml方式下.xml文件)。 - @
EnableAutoConfiguration: 开启自动配置类,SpringBoot的精华所在。 - @
ComponentScan:包扫描,等同于xml下开启并设置包扫描路径。
@EnableAutoConfiguration:告诉SpringBoot开启自动配置功能,这样自动配置才能生效。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(EnableAutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
@AutoConfigurationPackage:自动配置包
@Import: 导入自动配置的组件
@Import:通常用于有时没有把某个类注入到IOC容器中,但在运用的时候需要获取该类对应的bean,此时就需要用到@Import注解。加入IOC容器的方式有很多种,当然@Bean注解也可以,但是@Import注解快速导入的方式更加便捷。
AutoConfigurationImportSelector类中selectImport方法
该方法奠定了SpringBoot自动批量装配的核心功能逻辑。
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return NO_IMPORTS;
}
try {
AutoConfigurationMetadata autoConfigurationMetadata = AutoConfigurationMetadataLoader
.loadMetadata(this.beanClassLoader);
AnnotationAttributes attributes = getAttributes(annotationMetadata);
List<String> configurations = getCandidateConfigurations(annotationMetadata,
attributes);
configurations = removeDuplicates(configurations);
configurations = sort(configurations, autoConfigurationMetadata);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = filter(configurations, autoConfigurationMetadata);
fireAutoConfigurationImportEvents(configurations, exclusions);
return configurations.toArray(new String[configurations.size()]);
}
catch (IOException ex) {
throw new IllegalStateException(ex);
}
}
可以看到getCandidateConfigurations()方法,它其实是去加载 public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories" 外部文件。这个外部文件里面,默认有很多自动配置的类,这些类的定义信息将会被SpringBoot批量的加载到Bean定义Map中等待被创建实例。
总结:
当我们使用@EnableAutoConfiguration注解激活自动装配时,实质对应着很多XXXAutoConfiguration类在执行装配工作,这些XXXAutoConfiguration类是在spring-boot-autoconfigure jar中的META-INF/spring.factories文件中配置好的,@EnableAutoConfiguration通过SpringFactoriesLoader机制创建XXXAutoConfiguration这些bean。XXXAutoConfiguration的bean会依次执行并判断是否需要创建对应的bean注入到Spring容器中。
在每个XXXAutoConfiguration类中,都会利用多种类型的条件注解@ConditionOnXXX对当前的应用环境做判断,如应用程序是否为Web应用、classpath路径上是否包含对应的类、Spring容器中是否已经包含了对应类型的bean。如果判断条件都成立,XXXAutoConfiguration就会认为需要向Spring容器中注入这个bean,否则就忽略。
71.Nacos注册配置中心原理
服务注册发现原理
服务提供者启动时,会通过轮询配置注册中心集群地址进行服务注册,失败就会请求下一个节点,并且与nacos-server建立心跳机制,检测服务状态。
nacos-server中,服务注册信息会保存到一个serviceMap的ConcurrentHashmap中。
Nacos与其他注册中心不同的时,采用了Pull/Push同时运行的方式。
pull:服务消费者启动时,从nacosServer中获取指定服务名称的实例列表,缓存到本地,并且开启一个定时任务,每隔10秒轮询一次服务列表。
push:nacosServer通过检测心跳,心跳超时则推送服务实例消息。通过UDP协议,无需保证连接的安全性,因为还有pull机制。
配置中心原理
配置的动态监听:
Nacos采用的Pull模式,采用了一种长轮询机制。客户端采用长轮询的方式定时发起pull请求,去检查服务器端配置信息是否发生了变更,如果发生了变更,那么客户端会根据变更的数据获取最新的配置。
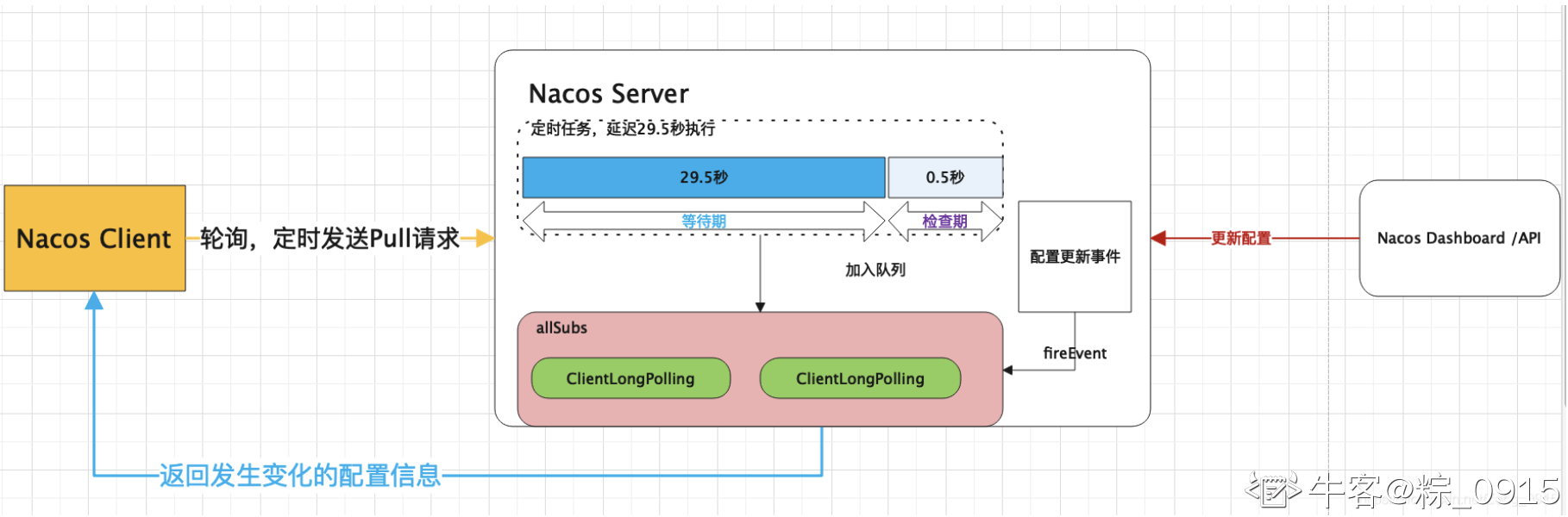 对于流程图解释如下:
对于流程图解释如下:
Nacos服务端收到请求后,会检查配置是否发生了变更,如果没有,那么设置一个定时任务,延期29.5秒执行。同时并且把当前的客户端长轮询连接加入到allSubs队列。 这时候有两种方式触发该连接结果的返回:
- 第一种:等待
29.5秒(长连接保持的时间)后触发自动检查机制,这时候不管配置有无发生变化,都会把结果返回给客户端。 - 第二种:在
29.5秒内的任意一个时刻,通过Nacos控制台或者API的方式对配置进行了修改,那么触发一个事件机制,监听到该事件的任务会遍历allSubs队列,找到发生变更的配置项对应的ClientLongPolling任务,将变更的数据通过该任务中的连接进行返回,即完成了一次推送操作。
配置的加载:
对于配置的加载而言,需要牵扯到SpringBoot的自动装配
Nacos Config的配置加载过程如下:
-
BootstrapApplicationListener监听器监听到环境准备事件,对需要做自动装配的类进行载入。,导入BootstrapImportSelectorConfiguration配置类,该配置类引入BootstrapImportSelector选择器,完成相关的初始化操作。 -
环境准备完成后(所需的相关配置类也初始化完成),执行方法
this.prepareContext()完成上下文信息的准备。 -
this.prepareContext()需要对相关的类进行初始化操作。由于PropertySourceBootstrapConfiguration类实现了ApplicationContextInitializer接口。因此调用其initialize()方法,完成初始化操作。 -
对于
PropertySourceBootstrapConfiguration下的初始化操作,需要实现应用外部化配置可动态加载,而NacosPropertySourceLocator实现了PropertySourceLocator接口,故执行他的locate()方法。 -
最终
NacosPropertySourceLocator的locate()方法完成从Nacos Config Server上加载配置信息。
写到这里,其实目前为止主要讲的是SpringCloud项目从启动到执行方法获取配置的这么一个过程,而对于具体获取远程配置的代码实现并没有深入去讲解。即上文的locate()方法,而该方法还涉及到配置更新时,Nacos如何去做到监听的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号