Kubernetes 网络架构及相关网卡
前言
因为 Kubernetes 的网络可以使用第三方网络插件,所以给我们提供了多样化的网络解决方案,让我们可以根据自身情况选择自己需要的网络方案。
CNM & CNI 阵营:
-
容器网络发展到现在,形成了两大阵营,就是 Docker 的 CNM 和 Google、CoreOS、Kuberenetes 主导的 CNI。首先明确一点,CNM 和 CNI 并不是网络实现,他们是网络规范和网络体系,从研发的角度他们就是一堆接口,你底层是用 Flannel 也好、用 Calico 也好,他们并不关心,CNM 和 CNI 关心的是网络管理的问题。
-
CNM (Docker LibnetworkContainer Network Model)
-
CNI(Container Network Interface)
Kubernetes 网络设计模型:
- 在 Kubernetes 网络中存在两种 IP(Pod IP 和 Service Cluster IP),Pod IP 地址是实际存在于某个网卡(可以是虚拟设备)上的,Service Cluster IP 它是一个虚拟 IP,是由 kube-proxy 使用 Iptables 规则重新定向到其本地端口,再均衡到后端 Pod 的。
基本原则:
- 每个 Pod 都拥有一个独立的 IP 地址(IPper Pod),而且假定所有的 pod 都在一个可以直接连通的、扁平的网络空间中。
设计原因:
- 用户不需要额外考虑如何建立 Pod 之间的连接,也不需要考虑将容器端口映射到主机端口等问题。
网络要求:
- 所有的容器都可以在不用 NAT 的方式下同别的容器通讯;所有节点都可在不用 NAT 的方式下同所有容器通讯;容器的地址和别人看到的地址是同一个地址。
K8S 网络主要解决以下网络通信问题:
-
同一 pod 下容器与容器的通信;
-
同一节点下不同的 pod 之间的容器间通信;
-
不同节点下容器之间的通信;
-
集群外部与内部组件的通信;
-
pod 与 service 之间的通信;
1、容器间通信:
同一个 Pod 的容器共享同一个网络命名空间,它们之间的访问可以用
localhost 地址 + 容器端口就可以访问。
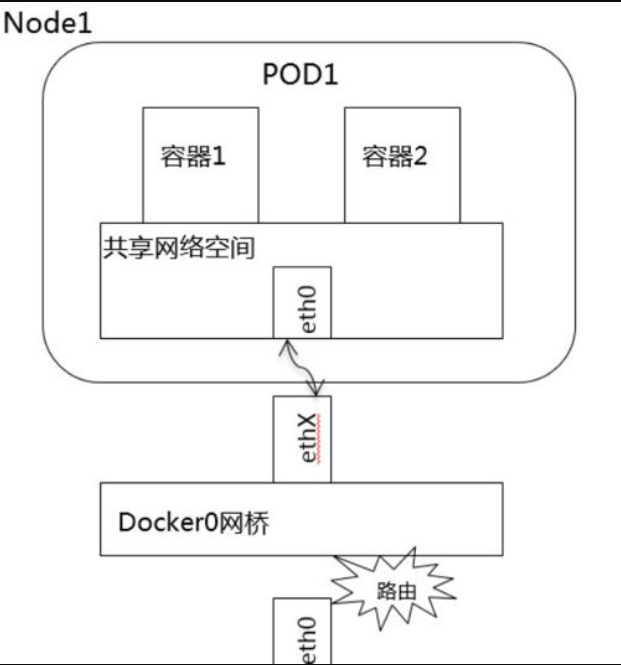
2、同一 Node 中 Pod 间通信:
同一 Node 中 Pod 的默认路由都是 docker0 的地址,由于它们关联在同一个 docker0(cni0)网桥上,地址网段相同,所有它们之间应当是能直接通信的。

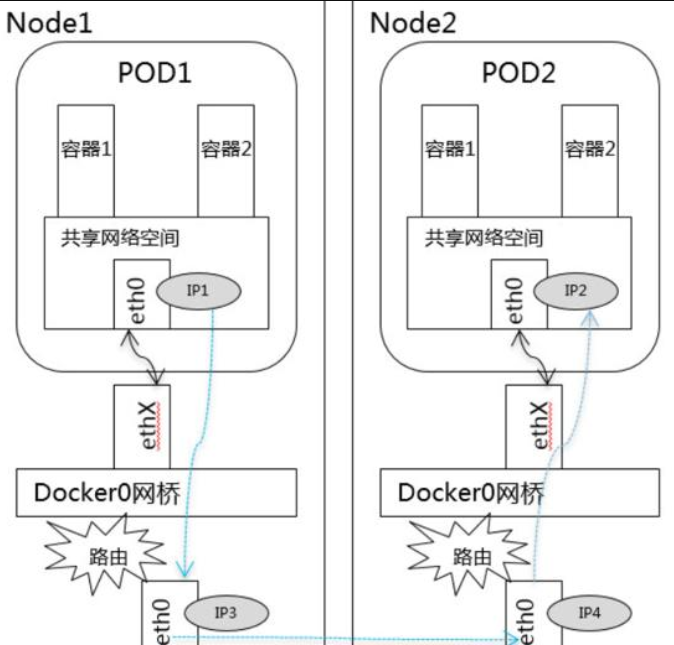
3、不同 Node 中 Pod 间通信:
不同 Node 中 Pod 间通信要满足 2 个条件:
*Pod 的 IP 不能冲突*; 将 Pod 的 IP 和所在的 Node 的 IP 关联起来,通过这个关联让 Pod 可以互相访问。所以就要用到 flannel 或者 calico 的网络解决方案。
对于此场景,情况现对比较复杂一些,这就需要解决 Pod 间的通信问题。在 Kubernetes 通过 flannel、calico 等网络插件解决 Pod 间的通信问题。以 flannel 为例说明在 Kubernetes 中网络模型,flannel 是 kubernetes 默认提供网络插件。Flannel 是由 CoreOs 团队开发社交的网络工具,CoreOS 团队采用 L3 Overlay 模式设计 flannel, 规定宿主机下各个 Pod 属于同一个子网,不同宿主机下的 Pod 属于不同的子网。
查看宿主机网卡
1 packet dropped by kernel
[root@node12 /]# ifconfig
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.3.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::1c39:e0ff:fefd:bc01 prefixlen 64 scopeid 0x20<link>
ether 1e:39:e0:fd:bc:01 txqueuelen 1000 (Ethernet)
RX packets 215461844 bytes 49255741900 (45.8 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 210219198 bytes 99380196541 (92.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
ether 02:42:3a:fe:ce:d7 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 18.16.200.142 netmask 255.255.255.0 broadcast 18.16.200.255
inet6 fe80::4e56:dbf1:fdb1:bbd9 prefixlen 64 scopeid 0x20<link>
ether 52:54:00:fb:f2:44 txqueuelen 1000 (Ethernet)
RX packets 271704820 bytes 128411272052 (119.5 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 234410728 bytes 75423059029 (70.2 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.3.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::8087:1ff:fe29:ed7c prefixlen 64 scopeid 0x20<link>
ether 82:87:01:29:ed:7c txqueuelen 0 (Ethernet)
RX packets 52059332 bytes 8640899916 (8.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 38918760 bytes 6548881752 (6.0 GiB)
TX errors 0 dropped 20 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 23487 bytes 1343648 (1.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 23487 bytes 1343648 (1.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth0b52cfb8: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet6 fe80::bca4:22ff:fea7:349 prefixlen 64 scopeid 0x20<link>
ether be:a4:22:a7:03:49 txqueuelen 0 (Ethernet)
RX packets 5345585 bytes 2672632806 (2.4 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5451377 bytes 3371977575 (3.1 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth3867ca45: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet6 fe80::7035:a5ff:fecd:e4d0 prefixlen 64 scopeid 0x20<link>
ether 72:35:a5:cd:e4:d0 txqueuelen 0 (Ethernet)
RX packets 4210336 bytes 3083434674 (2.8 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4364899 bytes 5908811645 (5.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0网卡
Docker 安装时会自动在 host 上创建三个网络:none,host,和bridge;详细说明可参考其它文档。
我们可用 docker network ls 命令查看:
[root@node12 /]# docker network ls
NETWORK ID NAME DRIVER SCOPE
0ee6eb650f66 bridge bridge local
30a3e66f751c host host local
2d1ae28eb78b none null local
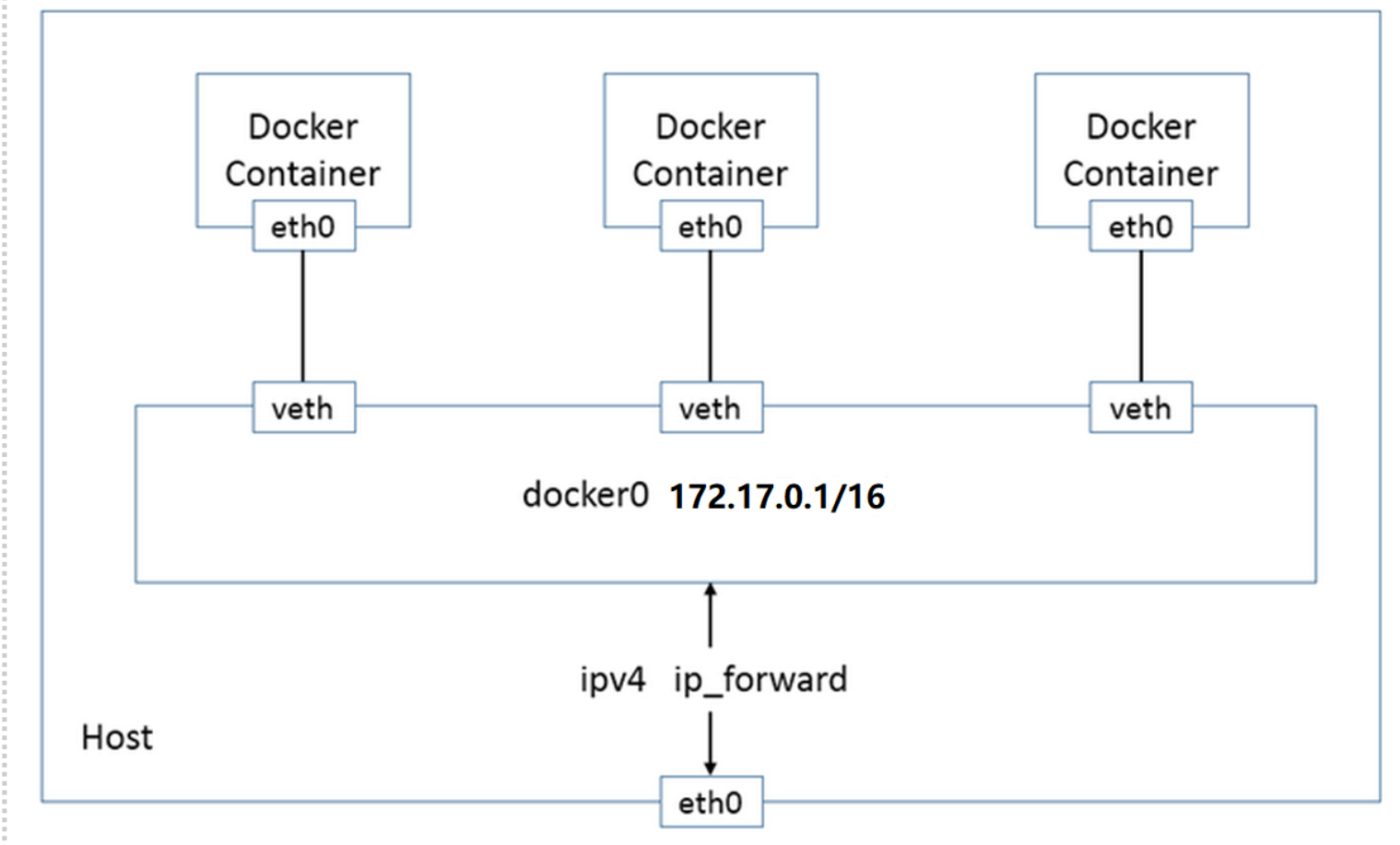
基于DRIVER是bridge的网络都会有一个对应的linux bridge被创建:
在默认环境中,一个名为docker0的linux bridge自动被创建好了,其上有一个 docker0 内部接口,IP地址为172.17.0.1/16(掩码为255.255.0.0)
再用docker network inspect指令查看bridge网络:其Gateway就是网卡/接口docker0的IP地址:172.17.0.1。
[root@node12 /]# docker network inspect bridge
[
{
"Name": "bridge",
"Id": "0ee6eb650f66797ca4dde49db3985a4006affdf69f2e208791e11dd3f977a9ab",
"Created": "2019-12-27T09:25:56.921594934+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
这时就会出现如何识别docker0的虚拟网卡和容器的对应关系,例如,图示中有两个容器和docker0中的两个接口:
安装Linux网桥管理工具bridge-utils
[root@node12 /]# yum install bridge-utils
[root@node12 /]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.3a1d7362b4ee no veth65f9
vethdda6
vetha596
flannel网络
flannel简介
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
在默认的Docker配置中,每个节点上的Docker服务会分别负责所在节点容器的IP分配。这样导致的一个问题是,不同节点上容器可能获得相同的内外IP地址。并使这些容器之间能够之间通过IP地址相互找到,也就是相互ping通。
Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
Flannel实质上是一种“覆盖网络(overlaynetwork)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持udp、vxlan、host-gw、aws-vpc、gce和alloc路由等数据转发方式,默认的节点间数据通信方式是UDP转发。
flannel网络
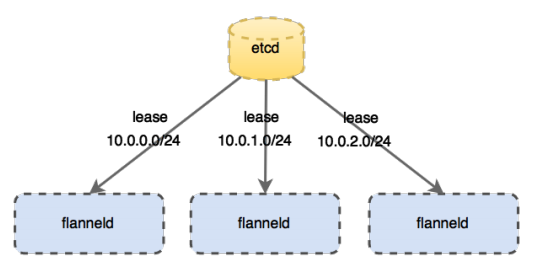
flannel 的 IP 地址是通过 Etcd 管理的,在 k8s 初始化的时候指定 pod 大网的网段 --pod-network-cidr=10.244.0.0/16,flanneld 可以直接通过 Etcd 管理,如果启动的时候指定了 --kube-subnet-mgr,可以直接通过 k8s 的 apiserver 来获得一个小网段的租期,通过 kubectl get -o jsonpath='{.spec.podCIDR}' 可以获取对应节点的 CIDR 表示的网段,flannel 是以节点为单元划分小网段的,每个节点上的 pod 在这个例子当中是划分一个 10.244.x.0/24 的网段,所以总共能分配 255 个节点,每个节点上可以分配 253 个 pod。结构如下图所示,每个节点上都会有一个 flanneld 用于管理自己网段的租期。
可以通过在 host 上 cat /run/flannel/subnet.env 查看同步下来的信息,例如:
[root@node12 /]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.3.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
说明当前节点分配的网段是 10.244.0.1/24。在每个节点上因为已经确定了网段,用 ipam 就可以管理这一范围 ip 地址的分配,所以本身 pod 的 IP 分配和中心 Etcd 没有太多联系。
容器间跨宿主如何运行
如下图所示,集群范围内的网络地址空间为10.1.0.0/16,Machine A获取的subnet为10.1.15.0/24,且其中的两个容器IP分别为10.1.15.2/24和10.1.15.3/24,两者都在10.1.15.0/24这一子网范围内,对于下方的Machine B同理。

如果上方Machine A中IP地址为10.1.15.2/24的容器要与下方Machine B中IP地址为10.1.16.2/24的容器进行通信,封包是如何进行转发的。从上文可知,每个主机的flanneld会将自己与所获取subnet的关联信息存入etcd中,例如,subnet 10.1.15.0/24所在主机可通过IP 192.168.0.100访问,subnet 10.1.16.0/24可通过IP 192.168.0.200访问。反之,每台主机上的flanneld通过监听etcd,也能够知道其他的subnet与哪些主机相关联。如上图,Machine A上的flanneld通过监听etcd已经知道subnet 10.1.16.0/24所在的主机可以通过Public 192.168.0.200访问,而且熟悉docker桥接模式的同学肯定知道,目的地址为10.1.16.2/24的封包一旦到达Machine B,就能通过cni0网桥转发到相应的pod,从而达到跨宿主机通信的目的。
因此,flanneld只要想办法将封包从Machine A转发到Machine B就OK了,而上文中的backend就是用于完成这一任务。不过,达到这个目的的方法是多种多样的,所以我们也就有了很多种backend. 在这里我们举例介绍的是最简单的一种方式hostgw : 因为Machine A和Machine B处于同一个子网内,它们原本就能直接互相访问。因此最简单的方法是:在Machine A中的容器要访问Machine B的容器时,我们可以将Machine B看成是网关,当有封包的目的地址在subnet 10.1.16.0/24范围内时,就将其直接转发至B即可。而这通过图中那条红色标记的路由就能完成,对于Machine B同理可得。由此,在满足仍有subnet可以分配的条件下,我们可以将上述方法扩展到任意数目位于同一子网内的主机。而任意主机如果想要访问主机X中subnet为S的容器,只要在本主机上添加一条目的地址为R,网关为X的路由即可。
veth网卡
Linux container 中用到一个叫做veth的东西,这是一种新的设备,专门为 container 所建。veth 从名字上来看是 Virtual ETHernet 的缩写,它的作用很简单,就是要把从一个 network namespace 发出的数据包转发到另一个 namespace。veth 设备是成对的,一个是 container 之中,另一个在 container 之外,即在真实机器上能看到的。
VETH设备总是成对出现,送到一端请求发送的数据总是从另一端以请求接受的形式出现。创建并配置正确后,向其一端输入数据,VETH会改变数据的方向并将其送入内核网络子系统,完成数据的注入,而在另一端则能读到此数据。(Namespace,其中往veth设备上任意一端上RX到的数据,都会在另一端上以TX的方式发送出去)veth工作在L2数据链路层,veth-pair设备在转发数据包过程中并不串改数据包内容。
veth设备特点
- veth和其它的网络设备都一样,一端连接的是内核协议栈
- veth设备是成对出现的,另一端两个设备彼此相连
- 一个设备收到协议栈的数据发送请求后,会将数据发送到另一个设备上去
cni0网卡
查看cni0网卡对应的桥接网卡
[root@node12 /]# brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.1e39e0fdbc01 no veth07cd1879
veth0b52cfb8
veth4238d279
veth6389b6d5
veth724d6510
veth78b32a65
veth96aa8f2a
vethad79f5c0
vethb4ae9fae
vethcaba2513
vethd9bb4726


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2017-03-01 数组构建完全二叉树