
Zookeeper简介
zookeeper实际上是yahoo开发的,用于分布式中一致性处理的开源框架,保证在分布式环境下数据的最终一致性,这个就是zookeeper能解决的问题
应用场景:分布式通知/协调、负载均衡、配置中心、分布式锁、分布式队列等:(著名的hadoop、kafka、dubbo 都是基于zookeeper而构建)
-
数据发布订阅。即注册中心,见上面dubbo用法。主要通过对节点管理做到发布以及事件监听做到订阅。
-
负载均衡。见上面kafka用法。
-
命名服务。zookeeper的节点结构天然支持命名服务,即把信息集中存储,并以树状管理,方便统一查阅。
-
分布式协调通知。协调通知实际上与发布订阅类似,由于引入的第三方的zookeeper,实际上对很多种协调通知做了解耦。
-
集群管理与master选举。可以轻易得知集群机器存活状况(节点 特性2),从而轻松管理集群;也可以做出master争抢(节点 特性1)。
-
分布式锁。(节点 特性1)
-
分布式队列。(节点 特性3)
-
分布式的并发等待。类似于多线程的join问题,主任务的执行依赖于其他子任务全部执行完毕,在单机多线程里可以用join,但是分布式环境下如何实现呢。利用zookeeper,可以创建一个主任务节点,旗下子任务一旦执行完毕,则在主任务节点下挂一个子任务节点,等节点数量足够,则认为主任务可以开始执行。
类似Linux文件系统的节点模型:
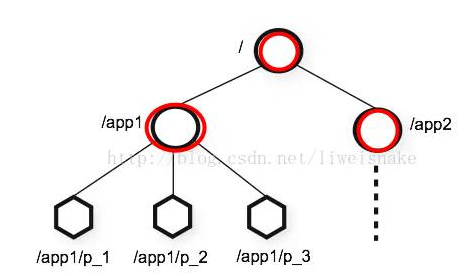
znode类型分为:
持久:创建之后一直存在,除非有删除操作,创建节点的客户端会话失效也不影响此节点。
持久顺序:跟持久一样,就是父节点在创建下一级子节点的时候,记录每个子节点创建的先后顺序,会给每个子节点名加上一个数字后缀。
临时:创建客户端会话失效(注意是会话失效,不是连接断了),节点也就没了。不能建子节点。
临时顺序:不用解释了吧。
znode特性:
-
同一时刻多台机器创建同一个节点,只有一个会争抢成功。利用这个特性可以做分布式锁。
-
临时节点的生命周期与会话一致,会话关闭则临时节点删除。这个特性经常用来做心跳,动态监控,负载等动作。
-
顺序节点保证节点名全局唯一。这个特性可以用来生成分布式环境下的全局自增长id。
chubby是google的,完全实现paxos算法,不开源。zookeeper是chubby的开源实现,使用zab协议,paxos算法的变种:
Paxos算法& Zookeeper使用协议
Paxos算法是分布式选举算法,Zookeeper使用的 ZAB协议(Zookeeper原子广播),二者有相同的地方,比如都有一个Leader,用来协调N个Follower的运行;Leader要等待超半数的Follower做出正确反馈之后才进行提案;二者都有一个值来代表Leader的周期。
不同的地方在于:
ZAB用来构建高可用的分布式数据主备系统(Zookeeper),Paxos是用来构建分布式一致性状态机系统。
Paxos算法、ZAB协议要想讲清楚可不是一时半会的事儿,自1990年莱斯利·兰伯特提出Paxos算法以来,因为晦涩难懂并没有受到重视。后续几年,兰伯特通过好几篇论文对其进行更进一步地解释,也直到06年谷歌发表了三篇论文,选择Paxos作为chubby cell的一致性算法,Paxos才真正流行起来。
对于普通开发者来说,尤其是学习使用Zookeeper的开发者明确一点就好:分布式Zookeeper选举Leader服务器的算法与Paxos有很深的关系。
ZK选举过程
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法使用ZAB协议:
① 选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
② 选举线程首先向所有Server发起一次询问(包括自己);
③ 选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
④ 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
⑤ 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数最好是奇数2n+1,且存活的Server的数目不得少于n+1
zookeeper提供的原语服务:
-
创建节点
-
删除节点
-
更新节点
-
获取节点信息
-
权限控制
-
事件监听
节点的watch监听通知:
官方声明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
为什么不是永久的,举个例子,如果服务端变动频繁,而监听的客户端很多情况下,每次变动都要通知到所有的客户端,这太消耗性能了。
一般是客户端执行getData(“/节点A”,true),如果节点A发生了变更或删除,客户端会得到它的watch事件,但是在之后节点A又发生了变更,而客户端又没有设置watch事件,就不再给客户端发送。
在实际应用中,很多情况下,我们的客户端不需要知道服务端的每一次变动,我只要最新的数据即可。
一个客户端修改了某个节点的数据,其它客户端能够马上获取到这个最新数据吗
ZooKeeper不能确保任何客户端能够获取(即Read Request)到一样的数据,除非客户端自己要求:方法是客户端在获取数据之前调用org.apache.zookeeper.AsyncCallback.VoidCallback, java.lang.Object) sync.
通常情况下(这里所说的通常情况满足:1. 对获取的数据是否是最新版本不敏感,2. 一个客户端修改了数据,其它客户端是否需要立即能够获取最新),可以不关心这点。
在其它情况下,最清晰的场景是这样:ZK客户端A对 /my_test 的内容从 v1->v2, 但是ZK客户端B对 /my_test 的内容获取,依然得到的是 v1. 请注意,这个是实际存在的现象,当然延时很短。解决的方法是客户端B先调用 sync(), 再调用 getData().
常用命令:ls get set create delete等
部署模式:单机模式、伪集群模式、集群模式。
集群规则为2N+1台(主要是为了选举算法),N>0,即3台,即:集群需要一半以上的机器可用,所以,3台挂掉1台还能工作,挂掉2台不能。
集群角色:leader、foller、observer。
zookeeper是如何保证事务的顺序一致性的:
zookeeper采用了递增的事务Id来标识,所有的proposal都在被提出的时候加上了zxid,zxid实际上是一个64位的数字,高32位是epoch用来标识leader是否发生改变,如果有新的leader产生出来,epoch会自增,低32位用来递增计数。当新产生proposal的时候,会依据数据库的两阶段(http://blog.itpub.net/15498/viewspace-2140089/)过程,首先会向其他的server发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行 。
最终一致性:
假设卖家更新成功之后买家立马就能看到卖家的更新,则称为强一致性;
如果卖家更新成功后买家不能看到卖家更新的内容,则称为弱一致性;
而卖家更新成功后,买家经过一段时间最终能看到卖家的更新,则称为最终一致性。
zookeeper在dubbo中的应用:

0 服务容器负责启动,加载,运行服务提供者。
1. 服务提供者(生产者)在启动时,向注册中心注册自己提供的服务。
2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
https://www.toutiao.com/i6482598983712637453/
https://blog.csdn.net/chizizhixin/article/details/81867106
https://blog.csdn.net/zhangxiaoyang0/article/details/79166676
