Mock测试,结合Fiddler轻松搞定不同场景
在平时测试过程中,总会遇到一些比较难构造的场景。比如不同平台间的同步,异常场景的构造。遇到难构造的场景时,就可以引用Mock来进行单元测试。简言之:mock测试就是在测试过程中,对于某些不容易构造或者不容易获取的对象,用一个虚拟的对象来创建以便测试的测试方法。
Mock场景
1.对象信息难构建
mock对象就是真实对象在调试期间的代替品。在测试时使用Mock,可以自由方便的构建配置接口对象的信息参数;在测试过程中,需要第三方接口返回特定的数据以符合特定的测试场景,这种情况往往需要跨条线的沟通协调测试数据,成本高,效率低;利用Mock可以自定义返回测试结果,支持手动构造依赖接口的返回值。
2.依赖的接口尚未开发完成
在系统交互双方定义好接口之后,我们可以提前进行开发和测试,并不依赖上游系统的开发。
3.异常场景(连接异常、超时异常等)
大体量级别的公司,系统错综复杂,依赖性极强。使用Mock技术,相当于在开发、测试过程中降级了对外部服务接口的依赖,可以不受限制的提前进行我们的工作。
4.自动化测试
在自动化测试概念和发展要求下,自动化测试的规模也逐渐增大到一定程度;
大型业务系统下测试接口多,测试用例也日益增多,依赖环境的稳定就成为了自动化测试执行的关键所在;
自动化测试过程中,经常会因为依赖的第三方环境不稳定,导致测试执行失败,长期以往的出现问题,导致测试人员对自动化的稳定运行失去维护的信心;
利用Mock技术,在测试过程中,只关注被测业务逻辑,mock掉依赖不相关的系统,这种情况下自动化测试运行失败,就一定是被测系统本身的业务逻辑问题,而不是第三方系统、数据的问题。
Mock步骤
近期在测试同步场景时,涉及到两个平台间的数据同步。为了测试不同场景,总不能让上游把接口给弄坏吧?所以就想到了,使用Fiddler来进行接口返回状态的Mock。
使用Fiddler来进行Mock,就是将请求的接口拦截,然后修改接口的返回值,使得接口返回对应异常场景下的报错,前端依据后端数据来展示对应提示信息。
Fiddler拦截
在Mock之前,需要先学习下Fiddler拦截操作,详细可参见博文:利用Fiddler拦截接口请求并篡改数据,使用起来很简单。
在Fiddler中,配置成接口请求前拦截,我们来看效果,如下所示:
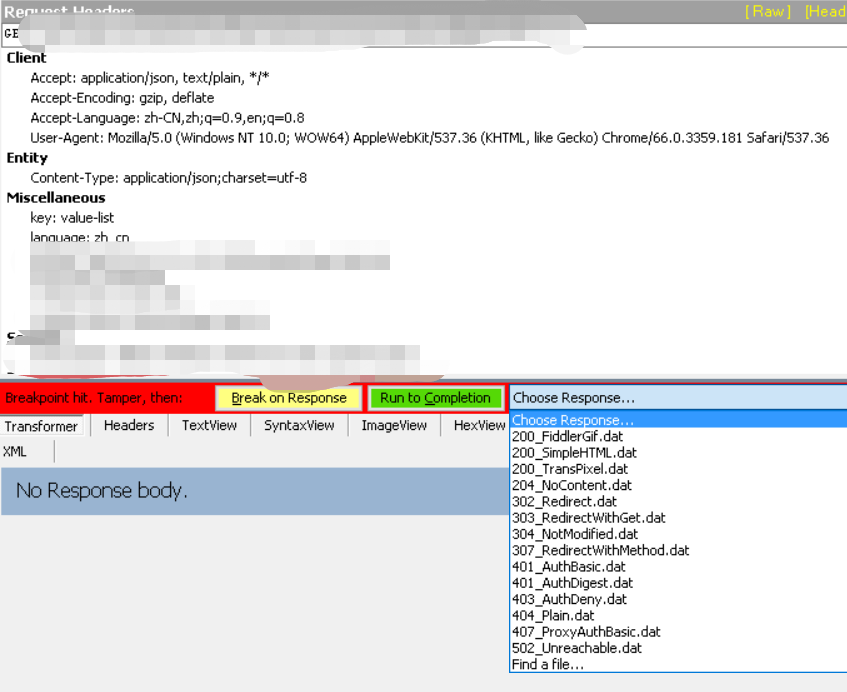
选择Response
数据被拦截后,可以选择Response,如图上所示,这些状态码,是Fiddler工具自带的,不防试试看?
选择Response为401,并点击Run to Completion后,查看数据。
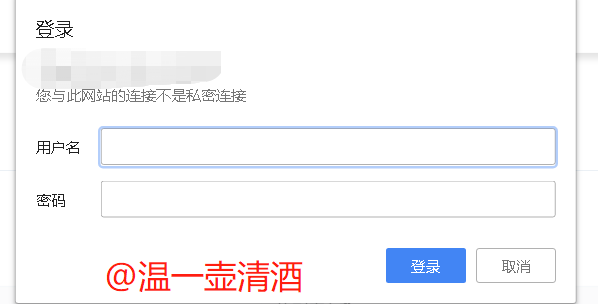
接口状态码为401,如下:

我们再来看页面数据,弹出了登录验证框,如下:
上述这些状态码是自带的,那我们如何模拟自己想要的数据呢?很简单,我们找到这些状态码的存放路径,比如:C:\Users\XX\AppData\Local\Programs\Fiddler\ResponseTemplates,复制一份数据,并修改成自己需要的返回值,即可。
Mock实践
我们熟悉了基本的操作步骤,那么就来实践一番,毕竟是实践出真知嘛,讲太多的理论都是纸上谈兵。
模拟响应码500
先将拦截方式设置为请求前拦截,在之后的例子中就不重复了,默认为请求前。
再将模拟的状态码及Response数据修改如下所示:

HTTP/1.1 500 X-Content-Type-Options: nosniff X-XSS-Protection: 1; mode=block Cache-Control: no-cache, no-store, max-age=0, must-revalidate Pragma: no-cache Expires: 0 Server: fiddler Content-Type: application/json;charset=UTF-8 Vary: Accept-Encoding Date: Fri, 27 Mar 2020 14:36:51 GMT Content-Length: 112 {"message":"请求接口过快","errorCode":"9960","exceptionCategory":"BIZ_ERR","exceptionType":"BizException"}
在对应页面中操作接口请求,此时,Fiddler中已经拦截了请求,我们选择已修改后的状态码文件,并“放行”接口,如下所示:

我们从上图可知,接口的响应码已为500,接口返回的Json数据信息就是界面将要展示的数据,我们来看刚才操作的界面,报错信息展示如下:
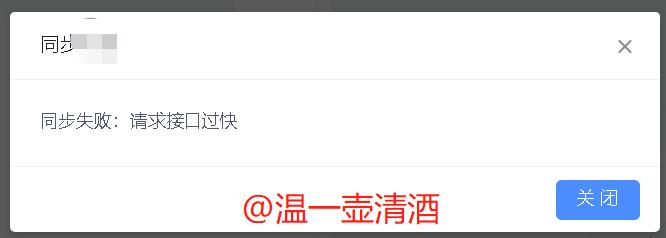
如上一个过程,就模拟了一个请求速度过快的场景。可能有人会疑问,这在界面上操作,重复调用不就可以了嘛?何必需要Mock呢?这个呢,就是前后端的都有校验的缘故了,前端的校验是,当后端没有返回值时,随便你怎么操作,不会再次请求接口。万一哪天前端的校验坏了呢?所以还是要Mock测试下,小心为上。
模拟响应码400
从模拟状态码500的过程来看,是不是很简单,接口继续来看下状态码为400的情况,还是需要先将模拟数据修改,如下:
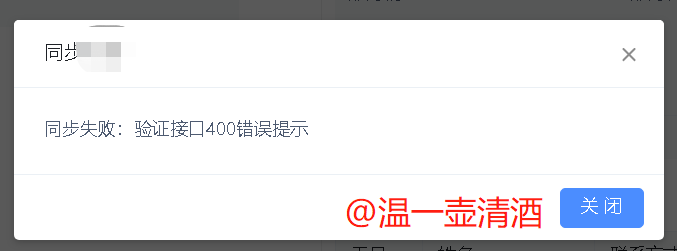
HTTP/1.1 400 X-Content-Type-Options: nosniff X-XSS-Protection: 1; mode=block Cache-Control: no-cache, no-store, max-age=0, must-revalidate Pragma: no-cache Expires: 0 Server: fiddler Content-Type: application/json;charset=UTF-8 Vary: Accept-Encoding Date: Fri, 27 Mar 2020 14:36:51 GMT Content-Length: 121 {"message":"验证接口400错误提示","errorCode":"9960","exceptionCategory":"BIZ_ERR","exceptionType":"BizException"}
请求接口并拦截,选择修改后的响应数据,如下:
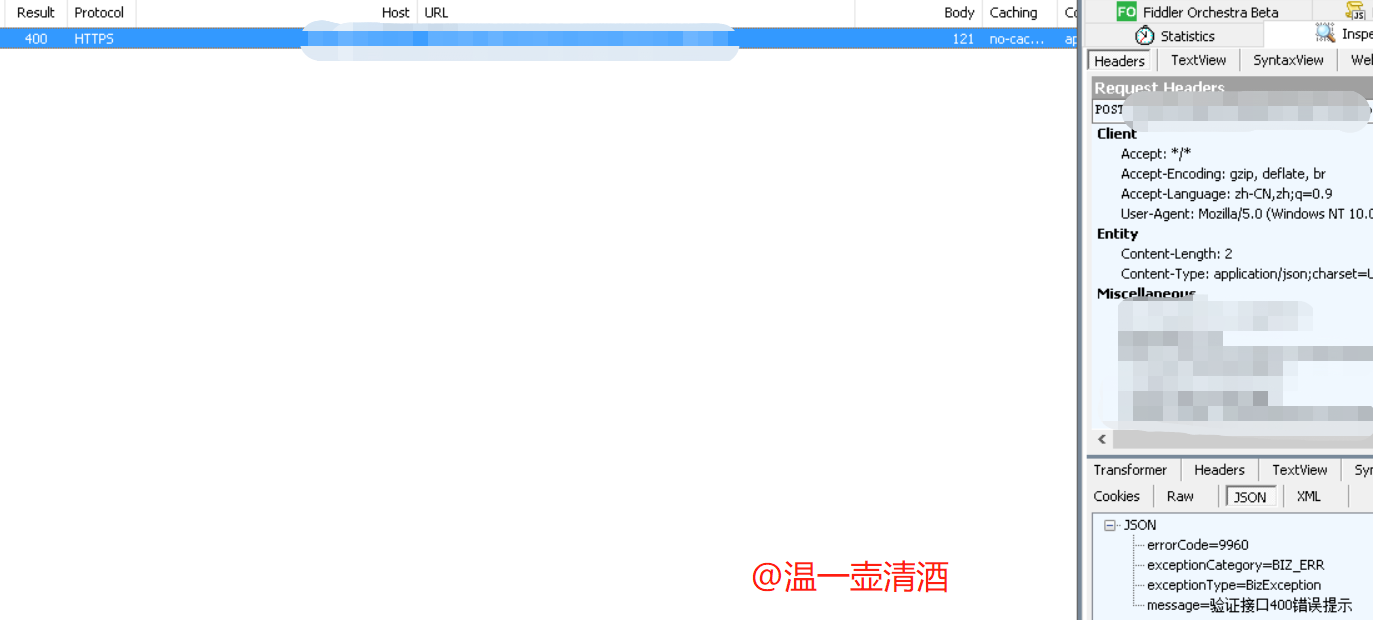
查看页面中的前端提示,验证数据,如下所示:
模拟响应码502
我们同理,重复上述操作,模拟个系统异常,修改如下:
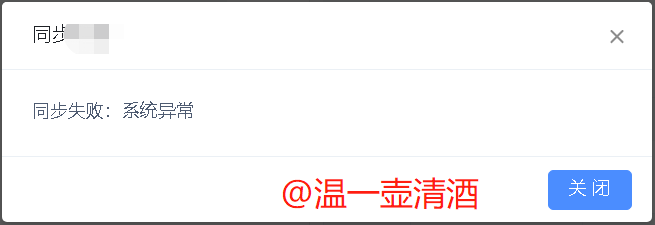
HTTP/1.1 502 X-Content-Type-Options: nosniff X-XSS-Protection: 1; mode=block Cache-Control: no-cache, no-store, max-age=0, must-revalidate Pragma: no-cache Expires: 0 Server: fiddler Content-Type: application/json;charset=UTF-8 Vary: Accept-Encoding Date: Fri, 27 Mar 2020 14:36:51 GMT Content-Length: 106 {"message":"系统异常","errorCode":"9960","exceptionCategory":"BIZ_ERR","exceptionType":"BizException"}
选择响应数据,并放行接口:

查看界面的展示信息,如下:
模拟响应码200
接口响应为200时,接口也有可能返回错误信息,这次我测试的这个接口就是如此。先修改接口200下会报错误的信息,如下:
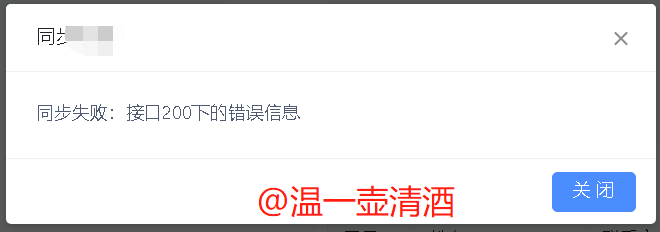
HTTP/1.1 200 X-Content-Type-Options: nosniff X-XSS-Protection: 1; mode=block Cache-Control: no-cache, no-store, max-age=0, must-revalidate Pragma: no-cache Expires: 0 Server: fiddler Content-Type: application/json;charset=UTF-8 Vary: Accept-Encoding Date: Fri, 27 Mar 2020 14:36:51 GMT Content-Length: 56 {"errMsg":"接口200下的错误信息","errorCode":"1"}
还是如出一辙,拦截修改响应数据后放行接口,如下所示:

在界面查看报错数据,如下:
AutoResponder自动响应
AutoResponder可以把本来服务器响应的内容,使用本地内容来响应。理解下来,就相当于,访问百度页面首页,本该展示搜索框。但经过自动响应配置,就可以替换成自己本地的内容。
AutoResponder界面
界面如下所示,我们先来了解下:
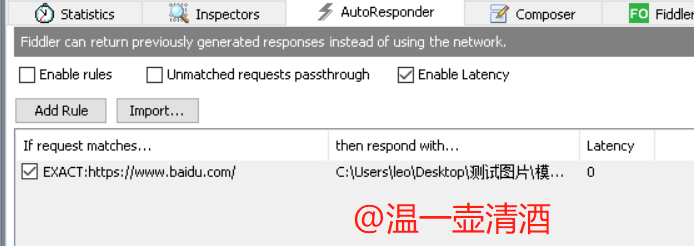
我们从上图界面,一一来了解下对应的功能配置点:
1.Enable rules(激活规则):勾选此选项,自动响应才会激活;
2.Unmatched requests passthrough(跳过非匹配请求):如果不勾选此选项,那么抓包的时候,会返回如下信息:
[Fiddler] The Fiddler AutoResponder is enabled, but this request did not match any of the listed rules. Because the "Unmatched requests passthrough" option on the AutoResponder tab is not enabled, this HTTP/404 response has been generated.
提示理解下来的意思是:fiddler的自动响应激活了,但是请求没匹配到任何列表中的规则。而且因为跳过非匹配请求选项没有激活,所以产生了http/404返回结果。
3.Enable latency(激活延迟):勾选了这个选项,在规则里面就可以设置是立即返回响应,还是隔多少毫秒返回响应;
4.Add rule(加入规则):点击此按钮则会在规则框里插入一个新的规则;
5.import(导入):支持导入之前捕获的saz文件;
6.规则框:
规则框有三个列,下面解释每个列的意思:
if requests matches---这里显示的是匹配的条件;
then response with---这里显示的是如果匹配条件,返回的文件;
latency---这里显示的是延迟时间(毫秒),只有勾选了Enable latecy才会展示出来。

7.rule editor(规则编辑):第一行是设置匹配条件,点开下拉,会看到很多fidder自带的条件;第二行是设置返回,点开下拉,会看到很多fidder自带的返回;
8.test(测试):这个就是用来测试匹配条件的,第一行,url pattern设置匹配公式,第二行test url设置测试的网址。点击savechages,则会将条件替换为rule editor的第一行;
9.Match only once(只匹配一次):勾选此选项,那么自动响应就只会响应一次;
10.Save(保存):按钮可以在更改了规则之后,更新规则。
规则配置
规则进行配置时,是支持正则匹配的,如上例子,就是使用的完全匹配方式,我们来详细看下正则匹配。
1.前缀为“EXACT:” 表示完全匹配(大小写敏感):只有match=rules时,才匹配;
2.无前缀表示基本搜索,表示搜索到字符串就匹配:只要match中包含了rules的字符串,即可;
3.前缀为“NOT:”表示发现就不匹配:与无前缀的基本搜索同理,只是发现了就不匹配,其他默认匹配;
4.前缀为“REGEX:”表示使用正则表达式匹配:
.+ 匹配一个或多个字符,如regex:.+jpg 包含有jpg字符串且以jpg字符串结尾的,即可匹配
.* 匹配0个或多个字符,如regex:.+.jpg.*包含有.jpg字符串即可匹配
^ 匹配字符串开始位置
$ 匹配字符串结束位置,如regex:.+.(jpg|gif|bmp)$包含以jpg或gif或bmp字符串结尾的,即可匹配
如regex:(?insx).+.(jpg|gif|bmp)$ 包含以jpg或gif或bmp字符串结尾的,不区分大小写,且是单行的,即可匹配
5.前缀为“REGEX:(?insx)”表示匹配方式其中:
i表示不区分大小写;
n表示指定的唯一有效的捕获是显式命名或编号的形式;
s表示单行模式;
x表示空格说明的。
实践操作
我们来实践操作一番,在fiddler上启用已配置好的规则,然后访问百度页面,此时,返回的不是百度的首页了,而是规则中配置的图片了,如下所示:

还可以替换成网页内容,将我的博客页面另存为html文件,修改规则内容,返回的数据设置为保存的html文件,我们再次来访问百度页面,展示的是如下页面:

以上就是今天分享的Mock内容了,通过拦截请求的方式,是Mock接口的响应码及响应内容;配置自动响应,是直接修改了响应的整个页面内容,两者还是有所区别。每天总结一点,不积跬步无以至千里。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架