WordCount小组作业
一、基础功能
GitHub:https://github.com/SuperScholar-Z/WordCountOptimized
PSP:
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
20 |
20 |
|
· Estimate |
· 估计这个任务需要多少时间 |
20 |
20 |
|
Development |
开发 |
360 |
370 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
30 |
30 |
|
· Design Spec |
· 生成设计文档 |
30 |
30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
20 |
20 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 |
30 |
|
· Design |
· 具体设计 |
20 |
20 |
|
· Coding |
· 具体编码 |
80 |
60 |
|
· Code Review |
· 代码复审 |
30 |
40 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
120 |
140 |
|
Reporting |
报告 |
100 |
140 |
|
· Test Report |
· 测试报告 |
60 |
100 |
|
· Size Measurement |
· 计算工作量 |
10 |
10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
30 |
|
|
合计 |
480 |
530 |
接口及模块设计:
主要负责模块为单词分割模块。由WordSplit类中的split()函数所实现,功能是将输入的字符串拆分成若干单词存入动态数组。
1 public static void split(String line, ArrayList<String> wordST) 2 { 3 char[] Line = line.toCharArray(); 4 String temp; 5 int p = 0; 6 while(p<line.length()) 7 { 8 if((Line[p]>= 'a'&&Line[p]<='z')||(Line[p]>= 'A'&&Line[p]<='Z')) 9 { 10 int a = p;//记录字符串开始的索引 11 while((Line[p]>= 'a'&&Line[p]<='z')||(Line[p]>= 'A'&&Line[p]<='Z')||Line[p] == '-')//截取单词的循环 12 { 13 if(Line[p] == '-') 14 { 15 if(p+1==line.length())//如果'-'是最后一个字符,跳出循环 16 break; 17 if(!((Line[p+1]>= 'a'&&Line[p+1]<='z')||(Line[p+1]>= 'A'&&Line[p+1]<='Z')))//如果'-'后面不是字母,跳出循环 18 break; 19 } 20 p++; 21 if(p==line.length()) 22 break; 23 } 24 temp = line.substring(a,p);//截取这个单词 25 wordST.add(temp.toLowerCase()); 26 } 27 else 28 p++; 29 } 30 }
主要设计思路是,将字符串转换为字符数组。外围循环扫描整个数组。读到字母时,进入单词分割的循环。循环主要将由此字母开头的这个单词截取出来。进入循环时,标记此时字母的下标,之后通过循环找到这个单词的结尾。若检测到’-’的字符,则判断这个字符的下一个是不是字母,如果是字母,则表示’-’是单词的一部分,继续循环;如果不是字母,则表示此单词已经结尾,跳出循环,截取该单词。
该模块主要包含在单词计数模块中,被该模块所调用。
public void Count() throws IOException //统计单词数 { String line; //读取的一行文本 while ((line = input.readLine()) != null) { //单词分割 ArrayList<String> wordST = new ArrayList<String>(); WordSplit.split(line, wordST); //单词分割 if(wordST == null) continue; for(String m_strWord : wordST) //提取出分割的单词 { Word m_word = new Word(m_strWord); //逐个单词读入 int indexOfWord = wordArr.indexOf(m_word); //单词在容器中的位置 if (m_word.getStrWord().length() == 0) //跳过空字符串 continue; if (indexOfWord == -1) //单词第一次出现则放进容器 wordArr.add(m_word); else //单词重复出现则计数器+1 wordArr.get(indexOfWord).incNum(); } } WordSort.sort(wordArr); //排序 }
将读入的文件拆分成每一行,调用split函数,将每一行的字符拆分成若干单词存入动态数组以供之后进行单词计数。
测试设计过程:
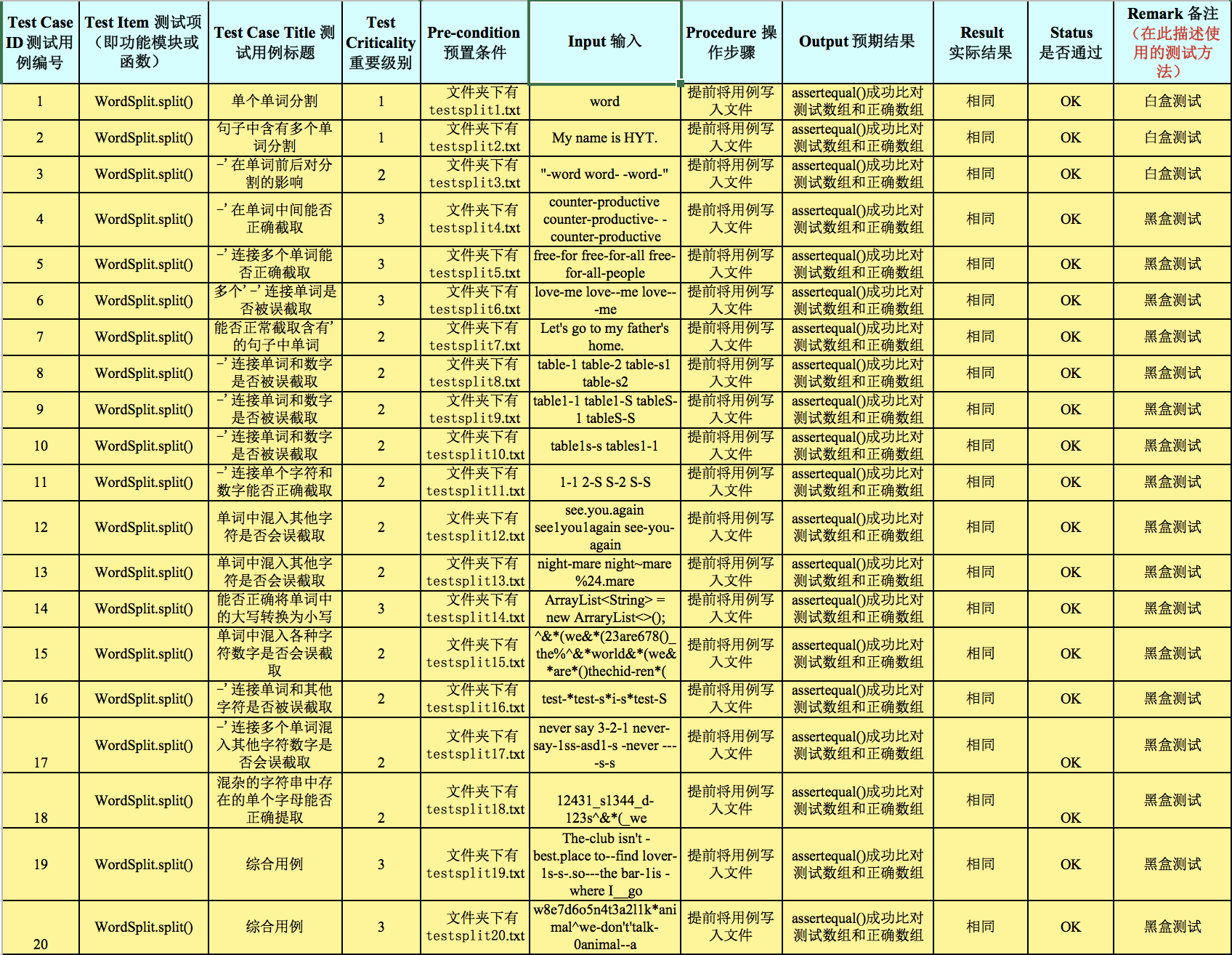
本次测试用例的设计采用了白盒测试和黑盒测试的思想。由于本模块功能较为简单,程序分支和复杂度不高,因此前三个用例就能完全覆盖模块的每一个分支和语句,因此前三个用例主要偏重于白盒测试。后面的用例主要处理各种不同的情况下能否正确将单词进行分割,主要偏重于测试结果,属于黑盒测试内容。每个测试用例针对性较强,单词数不多且考虑到了各种情况,包括各种边界与极端情况,能够满足测试的效率和要求。具体每个用例的偏重可参考用例设计表。
测试脚本示例:
@Test public void testSplit2() throws IOException{ readline("testsplit2.txt"); WordSplit.split(line, wordtest); wordtrue.add("my"); wordtrue.add("name"); wordtrue.add("is"); wordtrue.add("hyt"); assertEquals(wordtrue, wordtest); }
每个测试函数的示例如上,将split()函数分割的单词存入wordtest数组和手工输入存入的wordtrue数组的正确答案进行比对。
单元测试运行和评价:
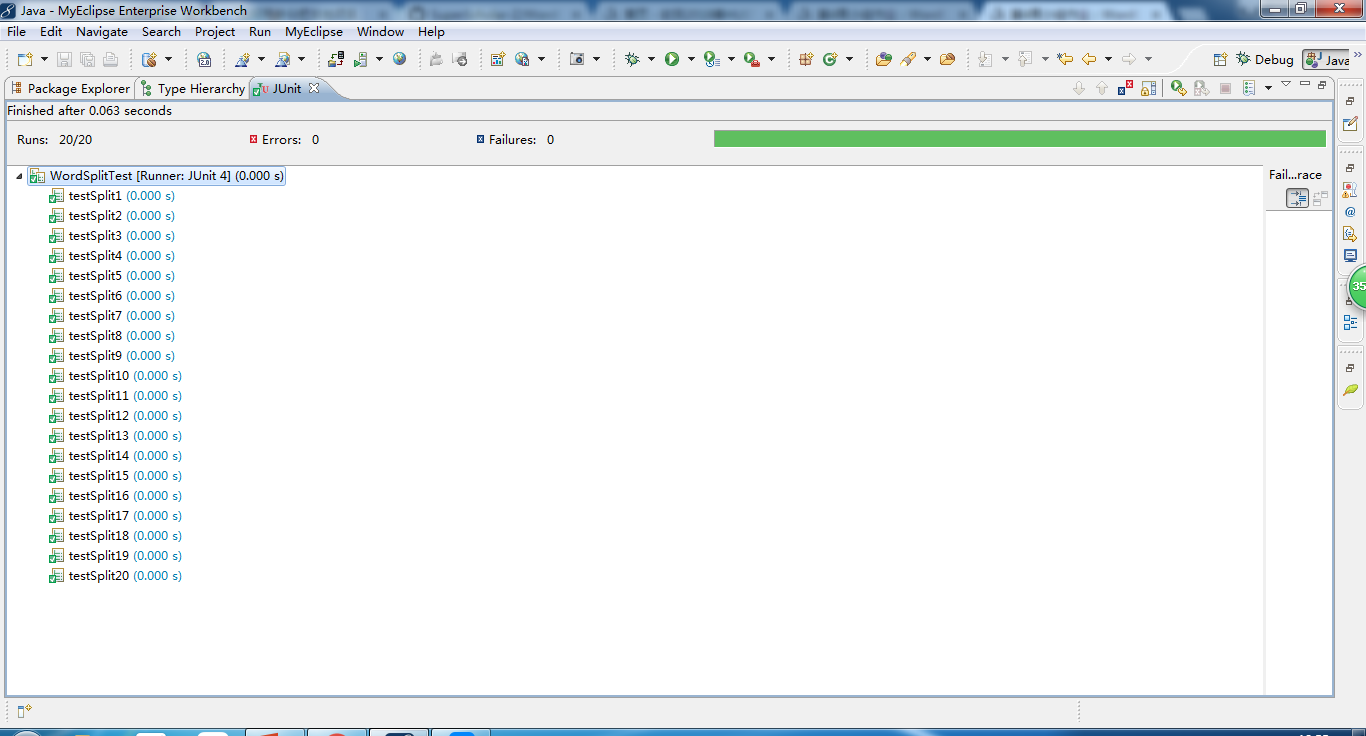
如图所示,对单词分割模块编写了测试脚本并进行了单元测试,20个测试用例通过。
单元测试覆盖了模块的所有分支和语句,且对各种情况(包括边界和极端情况)进行测试了,确保功能的准确无误,满足用户的需求,且单元测试效率较高。
二、扩展功能
开发规范分析:
邹欣老师对代码规范和代码复审的讨论:http://www.cnblogs.com/xinz/archive/2011/11/20/2255971.html
下面选取其中两个规范进行分析
1.断行与空白的{ }行:
if ( condition) { DoSomething(); } else { DoSomethingElse(); }
2.命名:
“匈牙利命名法”。例如:
fFileExist,表明是一个bool值,表示文件是否存在;
szPath,表明是一个以0结束的字符串,表示一个路径。
这是一种非常好的命名方式,值得我们学习,可以方便自己及其他人更容易的理解代码。
交叉代码评审:
评审对象:17124(胡天池)
代码:
public void Count() throws IOException //统计单词数 { String line; //读取的一行文本 while ((line = input.readLine()) != null) { //单词分割 ArrayList<String> wordST = new ArrayList<String>(); WordSplit.split(line, wordST); //单词分割 if(wordST == null) continue; for(String m_strWord : wordST) //提取出分割的单词 { Word m_word = new Word(m_strWord); //逐个单词读入 int indexOfWord = wordArr.indexOf(m_word); //单词在容器中的位置 if (m_word.getStrWord().length() == 0) //跳过空字符串 continue; if (indexOfWord == -1) //单词第一次出现则放进容器 wordArr.add(m_word); else //单词重复出现则计数器+1 wordArr.get(indexOfWord).incNum(); } } WordSort.sort(wordArr); //排序 }
根据邹欣老师提出的意见,我们可以看到这份代码的风格规范是很好的。
从命名来看,例如 “indexOfWord”,非常清晰的了解变量的含义。
从下划线的使用来看,代码恰当的使用了下划线,例如变量名“m_strWord”,下划线用来分隔变量名字中的作用域标注和变量的语义。
从分行和断行与空白的{ }行来看,代码完全符合邹欣老师所提的规范。
美中不足的是,注释的编写如果可以的话,应该尽量只用ASCII字符,不要用中文或其他特殊字符,它们会极大地影响程序的可移植性。
静态测试:
测试工具:FindBugs
下载地址:http://plugins.jetbrains.com/files/3847/29582/FindBugs-IDEA-1.0.1.zip?updateId=29582&pluginId=3847&uuid=d795e0ae-00bd-4334-82c3-95d6d34bb64e&code=IU&build=162.2032.8
测试代码:

测试截图:
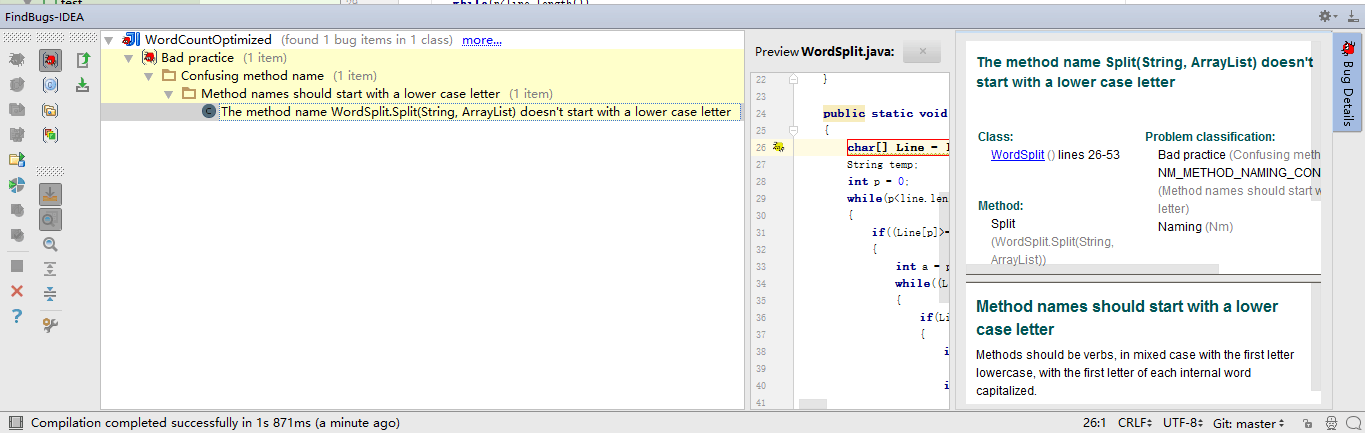
反应出的问题是:函数名的首字母是大写,这是一种不好的方式。
修改方案:将函数名修改为小写。
组内代码分析:
小组的代码总体来说没有很大的问题,大家的代码大部分都符合规范,但是可以更加严格要求自己,做到更好,例如完善自己的算法,注释尽量使用英文等。
三、高级功能
测试程序集:
我们选取了《SteveJobs》拥有大量字符和单词的文本进行测试,能够对程序造成一定的压力。
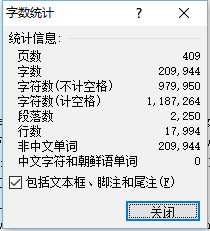
通过以下代码获取程序开始和结束的时间:
long startTime = System.currentTimeMillis(); //获取开始时间 long endTime = System.currentTimeMillis(); //获取结束时间 System.out.println("程序运行时间:" + (endTime - startTime) + "ms"); //输出程序运行时间
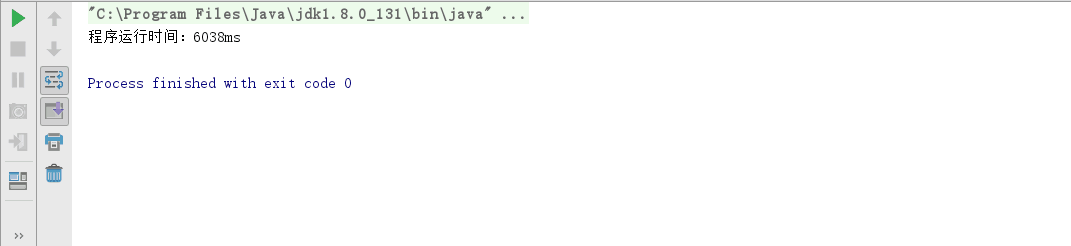
得到如下图所示的运行时间:
同行评审:
小组中每个人分饰不同的角色进行了小组评审,每个人均为作者和讲解员。
其余角色分工如下:
主持人:钟芳郅
评审员:刘弋、胡天池
记录员:黄一桐
经过详细的评审后我们得到结论:程序效率主要受核心功能即单词分割、统计计数、排序影响。
性能分析及性能优化:
经过实际的测试,我们发现影响程序效率的主要因素的确是单词分割、统计计数、排序的核心算法的效率,和同行评审的结论一致。
为提高程序的运行效率我们还拟定了以下方案:
1. 统计计数,由于要在数组中查找该单词是重复出现的单词还是新出现的单词,因此此时使用Map容器会比ArrayList容器更为快捷,因此Map容器基于二叉树,按值查找的效率较快。
2. 排序时使用较高效的算法,如归并排序,可以加快排序的效率。
因此我们修改了代码,将原先存放单词的动态数组换为Map容器。得到新的运行结果:

可以看出,程序的效率得到了非常明显的优化,从原先3000~5000ms的处理时间,到现在300ms左右的处理时间。可以看出,Map容器的查找效率非常高。算法的时间复杂度有非常明显的改善。
作业小结:
软件开发,软件测试和软件质量的关系。这次的实践作业让我更加清晰的认识到了这三者的关系。软件的测试应该是始终贯穿在整个开发过程中的,能够发现程序运行中的各种问题。单元测试帮助发现程序本身的功能是否有问题,静态测试帮助完善代码中不符合编码规范的地方,性能测试督促我们进一步提高程序的效率,能够从多方面考虑,得到效率最高的方式。这些种种都是测试所能完成的,也是提高软件质量的重要途径。
小组贡献分:
0.24

 浙公网安备 33010602011771号
浙公网安备 33010602011771号