关于Nagle算法和粘包问题
关于Nagle算法和粘包问题
1.Nagle算法
TCP/IP协议中,无论发送多少数据,总是要在数据前面加上协议头,同时,对方接收到数据,也需要发送ACK表示确认。为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块,提高网络的利用率。
Nagle算法的基本定义是 任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则:
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
Nagle算法只允许一个未被ACK的包存在于网络,它并不管包的大小,因此它事实上就是一个扩展的停止等待协议,只不过它是基于包停-等的,而不是基于字节停-等的。Nagle算法完全由TCP协议的ACK机制决定,这会带来一些问题,比如如果对端ACK回复很快的话,Nagle事实上不会拼接太多的数据包,虽然避免了网络拥塞,网络总体的利用率依然很低,所以Nagle算法一般和延迟确认机制一起使用。但是网上也有说法说,同时使用Nagle和延迟确认在一些情况下可能会导致相互等待到超时的情况。
考虑关闭Nagle的情况
-
对端不向本端发送数据,并且对延时比较敏感的操作;这种操作没法捎带ack;
-
写-写-读操作;对于此种情况,优先使用其他方式,而不是关闭Nagle算法:
--使用writev,而不是两次调用write,单个writev调用会使tcp输出一次而不是两次,只产生一个tcp分节,这是首选方法;
--把两次写操作的数据复制到单个缓冲区,然后对缓冲区调用一次write;
--关闭Nagle算法,调用write两次;有损于网络,通常不考虑;
2.延迟确认机制(delay ack)
ACK机制
在TCP协议种,接收方成功收到数据后,会回复一个ACK数据包,用于表示已经收到了ACK确认号以前的所有数据。如果发送方在一定时间内没有收到接受方的ACK确认包,就会重新发送数据包。ACK机制和序列号,消息重传机制一起保证了TCP协议的可靠性。
当接受方收到数据包时,可能因为下面的一些原因,不会立即返回ACK确认:
-
收到的数据包的序列号前还有未收到的数据。
-
ACK的值在到达最大时,会重新从零开始。
-
为了降低流量,而引入的延迟确认机制。
ACK延迟确认机制
接收方在收到数据后,并不会立即回复ACK,而是延迟一定时间。一般ACK延迟发送的时间为200ms,但这个200ms并非收到数据后需要延迟的时间。系统有一个固定的定时器每隔200ms会来检查是否需要发送ACK包。这样做有两个目的。
1、这样做的目的是ACK是可以合并的,也就是指如果连续收到两个TCP包,并不一定需要ACK两次,只要回复最终的ACK就可以了,可以降低网络流量。
2、如果接收方有数据要发送,那么就会在发送数据的TCP数据包里,带上ACK信息。这样做,可以避免大量的ACK以一个单独的TCP包发送,减少了网络流量。
ACK延迟确认和Nagle算法混用可能出现的问题
比较典型的场合就是写-写-读,即通过多个写小片数据向对端发送单个逻辑的操作,两次写数据长度小于MSS,当第一次写数据到达对端后,对端延迟ack,不发送ack,而本端因为要发送的数据长度小于MSS,所以nagle算法起作用,数据并不会立即发送,而是等待对端发送的第一次数据确认ack;这样的情况下,需要等待对端超时发送ack,然后本段才能发送第二次写的数据,从而造成延迟;
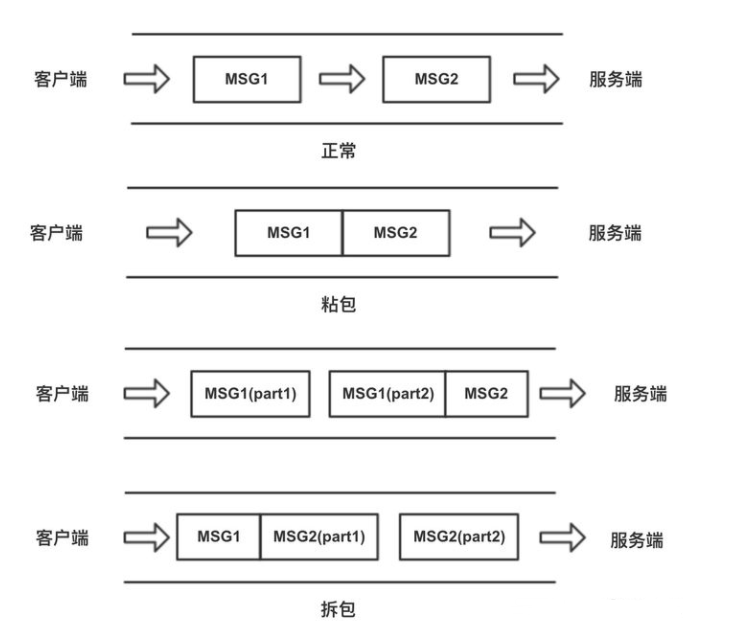
3.粘包问题
什么是粘包
因为TCP是面向字节流的协议,没有消息保护边界,同时在TCP的首部没有表示数据长度的字段。一方发送的多个数据包,可能会被合并成一个大的数据包进行传输,这就是粘包。粘包情况有两种,一种是粘在一起的包都是完整的数据包,另一种情况是粘在一起的包有不完整的包。
与粘包对应的还有一个概率:分包是指在出现粘包的时候我们的接收方要进行分包处理。(在长连接中都会出现) 数据包的边界发生错位,导致读出错误的数据分包,进而曲解原始数据含义。
粘包的成因
-
发送方原因
TCP默认使用上面提到的Nagle协议,即会将小数据包合成大数据包一起发送出去。
-
接收方原因
接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象。这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据。
粘包的解决方法
粘包问题的本质就是无法区分数据包的边界,只要解决了这个问题,也就解决了粘包问题。
1、发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便知道每一个数据包的实际长度了。
2、发送端将每个数据包封装为固定长度(不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
3、可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号