
OO第四次博客作业
OO第四次博客作业
本单元三次作业的架构设计
第一次作业
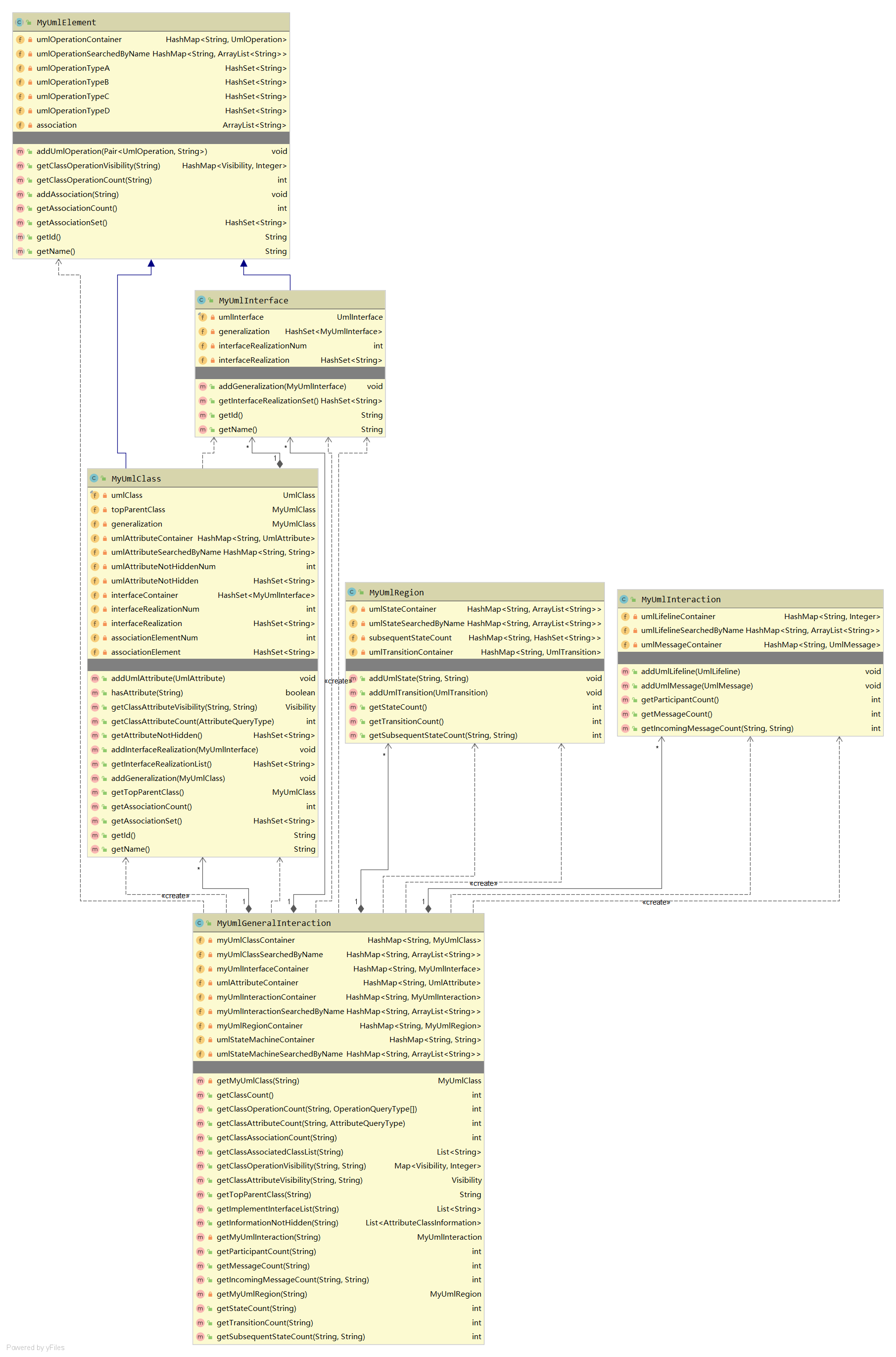
第一次作业的目标是实现一个UML类图的解析器,难点在于对UML类图的理解和代码架构的设计,代码的具体实现较为简单。我自己设计了父类MyUmlElement和表示类和接口的两个子类MyUmlClass和MyUmlInterface,MyUmlElement的作用是保存类和接口共有的属性、方法和关联关系,MyUmlClass存储继承的父类和实现的接口,并实现了解析器对类图进行查询的功能,MyUmlInterface中保存了继承的父类列表。
在初始化MyUmlInteraction类时对类图进行了构建,在按照element.getElementType()进行分类的存储后,先遍历UmlAttribute、UmlParameter和UmlOperation存储到相应类或者接口中,再遍历UmlAssociation、UmlInterfaceRealization和UmlGeneralization在类和类、类和接口、接口和接口之间建立关系。对于MyUmlClass,在MyUmlInteraction用了两个HashMap容器进行存储,一个以id为key,MyUmlClass为value,满足属性、方法、关联关系、继承关系和接口实现关系通过parentId找寻类的要求,另一个容器以name作为key,存储同名类id的ArrayList作为value,满足使用名字对类图进行查询的功能,并增加了私有方法getMyUmlClass,以name作为参数,MyUmlClass作为返回值,并抛出类不存在或存在多个重名类异常,使代码更加简洁。
private MyUmlClass getMyUmlClass(String s)
throws ClassNotFoundException, ClassDuplicatedException {
if (!myUmlClassSearchedByName.containsKey(s)) {
throw new ClassNotFoundException(s);
} else if (myUmlClassSearchedByName.get(s).size() > 1) {
throw new ClassDuplicatedException(s);
} else {
return myUmlClassContainer.get(myUmlClassSearchedByName.get(s).get(0));
}
}
从第一次作业开始,考虑到第三单元CTLE的教训,着重在性能上进行了考虑,在所有需要查询的地方都采用了缓存的方法,以getInterfaceRealizationList()方法为例,声明存储类所有实现接口的容器时并不进行初始化,每次查询时发现已经初始化则直接返回,否则进行初始化并递归查询。
private HashSet<String> interfaceRealization = null;
public HashSet<String> getInterfaceRealizationList() {
if (interfaceRealization == null) {
interfaceRealization = new HashSet<>();
if (hasParent()) {
interfaceRealization.addAll(generalization.getInterfaceRealizationList());
}
for (MyUmlInterface myUmlInterface : interfaceContainer) {
interfaceRealization.add(myUmlInterface.getId());
interfaceRealization.addAll(myUmlInterface.getInterfaceRealizationList());
}
}
return interfaceRealization;
}
第二次作业
第二次作业在第一次作业的基础上拓展了对顺序图和状态图的查询功能,对于上一次作业的代码未进行修改,新增了MyUmlInteraction和MyUmlRegion两个类,前者存储顺序图的所有生命线,所有消息,以及每个生命线的传入消息有几个,后者存储状态图中包括InitialState和FinalState在内的所有状态,所有状态迁移以及每个状态直接后继状态的id。
第三次作业
第三次作业我对原有代码进行了较大程度的改动,主要有以下几点:
1、删去了MyUmlElement类,将其功能分散到两个子类MyUmlClass和MyUmlInterface中,这是因为接口并不需要对方法和关联关系进行存储,也只需要记录有无可见性不为public的属性,不需要像类一样将属性、方法和关联关系全部存储下来。
2、将关联关系的存储方式进行了改变,前两次作业存储的是关联对端的id,第三次作业因为要将UmlAttribute和UmlAssociationEnd统一起来进行检查,所以修改为存储关联对端的UmlAssociationEnd。
3、修改了类存储实现接口和接口存储父类的容器类型,从HashSet改为ArrayList,因为模型有效性检查需要对接口重复继承和类重复实现接口进行查询。

对于新增加的模型有效性检查部分,比较有难度的是检查循环继承的R002,我采用的算法是对每一个点进行深度优先搜索dfs,找寻是否有从自身到自身的环存在,如果存在,则环上的每一个点都不需要再进行查询,减少了时间开销。
class TravelDfs {
private String startingPoint;
private HashSet<String> path = new HashSet<>();
private HashSet<String> visited = new HashSet<>();
private boolean dfs(MyUmlClass v) {
visited.add(v.getId());
path.add(v.getId());
if (v.hasParent()) {
if (v.getParentClass().getId().equals(startingPoint)) {
return true;
} else if (!visited.contains(v.getParentClass().getId())) {
if (dfs(v.getParentClass())) {
return true;
}
}
}
path.remove(v.getId());
return false;
}
private boolean dfs(MyUmlInterface v) {
visited.add(v.getId());
path.add(v.getId());
for (MyUmlInterface myUmlInterface : v.getParentInterface()) {
if (myUmlInterface.getId().equals(startingPoint)) {
return true;
} else if (!visited.contains(myUmlInterface.getId())) {
if (dfs(myUmlInterface)) {
return true;
}
}
}
path.remove(v.getId());
return false;
}
public HashSet<String> getPath(String v) {
startingPoint = v;
if (myUmlClassContainer.containsKey(v)) {
dfs(myUmlClassContainer.get(v));
} else if (myUmlInterfaceContainer.containsKey(v)) {
dfs(myUmlInterfaceContainer.get(v));
}
return path;
}
}
public void checkForUml002() throws UmlRule002Exception {
HashSet<UmlClassOrInterface> ret = new HashSet<>();
HashSet<String> hashSet = new HashSet<>();
hashSet.addAll(myUmlClassContainer.keySet());
hashSet.addAll(myUmlInterfaceContainer.keySet());
while (!hashSet.isEmpty()) {
String string = hashSet.iterator().next();
hashSet.remove(string);
for (String id : new TravelDfs().getPath(string)) {
hashSet.remove(id);
if (umlClassContainer.containsKey(id)) {
ret.add(umlClassContainer.get(id));
} else if (umlInterfaceContainer.containsKey(id)) {
ret.add(umlInterfaceContainer.get(id));
}
}
}
if (!ret.isEmpty()) {
throw new UmlRule002Exception(ret);
}
}
四个单元中架构设计及OO方法理解的演进
第一单元的任务是含简单幂函数和简单正余弦函数的表达式求导,前两次作业除了新建Poly和Term两个类分别表示多项式和项外,类内的方法完全采用的还是面向过程式的编程思想,第三次作业按照老师推荐的层级结构进行了设计,多少有了一点面向对象的味道。
第二单元我仔细对架构进行了设计,而且预测了后两次作业的迭代方向,在第一次作业时就引入了调度器,采用了两次生产者消费者模式,虽然增大了工作量,但是大大减少了后两次作业迭代开发的难度。而且这单元学习了面向对象程序设计的SOLID原则,第一次基于这些设计原则审视自己的代码架构,感觉不足之处还有很多。
第三单元是根据JML规格实现代码,功能完成难度不是很大,主要的难点在于图论算法和时间复杂度的分析上。前两次作业由于完全按照规格进行实现,并没有注重代码架构的设计,最后一次作业因为MyNetwork类过于臃肿,因此新建类对需要实现的功能进行了分派。
第四单元我采用的方式是将给定的元素进行封装,然后在我封装的类中实现具体的功能,在交互接口中只需要调用相应类的方法即可,代码的架构较为简单。
四次作业相比较,前两次作业重在架构,后两次作业重在对功能如何实现的设计上,即使如此,我能明显感到自己对于面向对象的理解有很大的进步,在每一次动手写代码前,都会先对架构进行设计,勾勒出程序的大体轮廓,而且会用SOLID原则审视自己的代码设计,考虑到迭代开发和自动化测试,还会思考程序的可拓展性和鲁棒性等。
四个单元中测试理解与实践的演进
第一单元的三次作业采用的都是自动化测试+手动构造测试数据的方法,通过写python程序和批处理文件,实现了对代码的自动化随机测试,并手动构造了边界数据和特殊数据等进行针对性的测试,感觉效果很好。
第二单元多线程程序的测试难度较大,我是对官方下发的输入接口进行了改写,使得支持按时投递数据,又编写了能够自动化生成随机数据的程序,两者搭配进行使用,但是忽略了对于重复数据和边界数据可能导致CTLE错误的测试。
第三单元我们学习了Junit单元测试工具,这是一个十分强大也十分完善的工具,对于类中每一个方法构造数据进行测试,感觉代码的正确性和鲁棒性都得到了保证。此外还尝试使用了openjml、jmlunitNG等工具,感觉操作非常复杂,而且效果也不是很好。
第四次作业因为是对UML图进行解析,因此测试的方法就是根据需求在starUML中构造测试样例,用课程组下发的命令行工具导出测试数据进行测试,感觉自动化程度很低,但是很有针对性,效果也很好。
课程收获
第一单元我主要的收获是对依靠类和接口进行层级结构设计进行了学习和理解,感觉出了面向对象和面向过程相比的优势,不仅仅提高了代码的可封装性、可拓展性,而且代码更易于理解,适合迭代开发。
第二单元接触了全新的多线程知识,我真的是大开眼界,而且OS课也同时正在进行进程同步方面的学习,感觉照应的很好,学会了同步控制块,锁机制,wait和notify等多线程编程方法,也掌握了生产者消费者模式、Worker Thread模式、观察者模式等并发程序设计模式。
第三单元在作业中我们主要训练的是阅读规格写代码的能力,两次实验训练了根据设计书写规格以及依据规格开展单元化测试的能力,学习这种契约化编程的思想可以将程序的设计与实现分离,提供了更加严谨的程序设计方式。
作为OO终章,第四单元我们学习了强大的统一建模语言UML,作业帮助我们对UML中元素的层级结构进行理解,实验课则学习了UML类图、顺序图和状态图的画法以及模型有效性的检查。
除此以外,一个学期的应用使我更加熟悉java这门强大的面向对象编程语言,还学习了版本控制工具git的使用等,并从老师和助教那里学习到了很多编程经验、代码设计技巧等,感觉自己正在向一个专业的程序员迈进。
课程改进建议
1、感觉应该加大实验课的比重,因为实验课相比于作业来说,形式更加灵活,而且更有针对性,对于理解课堂上的内容和完成作业的帮助都很大。而且希望老师能够给出实验课的答案,可以以文档的方式,也可以在下一周研讨课进行讲解等。
2、感觉第三单元三次作业都是根据规格写代码,重复性很高,难度也不在JML而是图论算法上,感觉可以在第三单元舍弃这种迭代性开发的形式,分别训练根据规格写代码、根据代码补充规格和依照规格进行测试,可能学习的更加全面一点。
3、五一没必要放假了......还是不进烤漆好一点。
线上学习OO课程的体会
感觉对作业的影响不是很大,就是实验课和理论课的效果可能没有学校好,少了很多与老师和同学的交流,最重要的就是一学期也没看见帅气的OO老师们真的遗憾。

