
字节对齐
一、什么是字节对齐?
在现代计算机中,内存空间都是按照字节(byte)划分的。从理论上讲对任何类型的变量的访问可以从任何地址开始,但实际情况是,访问特定类型的变量的时候经常在特定的内存地址访问,这就需要各种类型的数据按照一定规则在空间上排列,而不是顺序地一个接一个地排放,这种所谓的规则就是字节对齐。这么长一段话的意思是说:字节对齐可以提升存取效率,也就是用空间换时间。
例如:
struct A
{
char a;
char reserved[3];//使用空间换时间
int b;
};
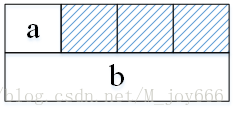
注:其中的reserved成员对于程序并没有意义,只是起到了填补空间达到字节对齐的目的。当然,即使不加这个成员,编译器也会自动为我们补齐,加上它只是起到显式提醒。
二、为什么需要字节对齐?
因为各个硬件平台对存储空间的处理上有很大的不同,一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐.其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。显然在读取效率上下降很多。
三、几个基本概念
1、基本数据类型的自身对齐值
例如,char型数据的自身对齐值为1字节,short类型自身对齐值为2字节,int、float、long类型自身对齐值均为4字节,double类型自身对齐值均为8字节。(32位系统)
2、结构体或类的自身对齐值
其成员中自身对齐值最大的那个值。
3、指定对齐值
通过预编译指令 #pragma pack (value) 来指定的对齐值value。(注:取消自定义对齐值得指令为 #pragma pack ( ))
4、数据成员、结构体和类的有效对齐值
其自身对齐值和指定对齐值中较小的那个值。
四、字节对齐的几个例子浅析
例1:设有如下两个结构体
struct A
{
char a;
short b;
int c;
};
struct B
{
short b;
int c;
char a;
};
那么上面两个结构体的大小是多少呢?
对于结构体A:a是char型数据,占用1字节内存;short型数据,占用2字节内存;int型数据,占用4字节内存。因此,结构体A的自身对齐值为4,sizeof(struct A) =8字节。

对于结构体B:同理也是4字节对齐,但是sizeof(struct B) =12字节。

例2:为结构体指定对齐值
#pragma pack(2) //指定2字节对齐
struct C
{
char a;
int b;
short c;
};
#pragma pack() //取消指定对齐,恢复缺省对齐
对于结构体C:由于其自身对齐值为4字节(int b),而指定对齐值为2字节,因此该结构体的有效对齐值为较小的2字节,那么sizeof(struct C) = 8 字节。

#pragma pack(1) //指定1字节对齐
struct D
{
char a;
int b;
short c;
};
#pragma pack() //取消指定对齐,恢复缺省对齐
对于结构体D:同理可知,由于其自身对齐值为4字节(int b),而指定对齐值为1字节,因此该结构体的有效对齐值为较小的1字节,那么sizeof(struct D) = 7 字节。

在缺省情况下,C编译器为每一个变量或是数据单元按其自然对界条件分配空间。一般地,可以通过下面的方法来改变缺省的对界条件:
使用伪指令#pragma pack (n),C编译器将按照n个字节对齐。
使用伪指令#pragma pack (),取消自定义字节对齐方式。
另外,还有如下的一种方式:
__attribute((aligned (n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。
__attribute__ ((packed)),取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐。
五、总结
由以上分析可知,字节对齐会造成空间上的浪费。 事实上,除了结构体之外,整个程序在给每个变量进行内存分配时都会遵循对齐机制,也都会产生内存空间的浪费。但我们要知道,这种浪费是值得的,因为它换来的是效率的提高。
参考博客:https://blog.csdn.net/M_joy666/article/details/80030024


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端