寒假训练营第二次作业
2019寒假训练营第二次作业
一、学习视频课程:网络空间安全概论
第一章:网络空间安全概述
1.1绪论
我国网络空间安全面临严峻考验
网络空间安全包括人、机、物以及其中产生、处理、传输、存储的各种信息数据的安全
1.2网络框架安全威胁
- 网络空间安全框架
- 设备层威胁:
- 皮下植入RFID芯片,以触摸的形式入侵设备,窃取隐私信息。
- 通过分析计算机辐射电磁波,分析得到隐私数据(设备不联网不代表绝对安全)。
- 伊朗核电站虽然处在信息系统物理隔绝中,仍然遭到病毒袭击。
- 硬件木马:恶意电路,多出现于军事领域(不同与软件木马)
- 系统层威胁
- SQL注入:把SQL命令插入到web表单提交或输入域名或页面请求的查询字符串,以欺骗服务器,引起信息泄露。
- 恶意代码:特洛伊木马、计算机病毒
- 数据层威胁
- 免费WiFi
- 智能设备
- 蓝牙协议漏洞
- 应用层威胁
- 群发短信中内含危险网站,其域名与一些官网很相似。
- 利用充电桩窃取数据
1.3网络空间安全框架
-
网络空间安全包括许多基础维度:
设备安全、网络安全、应用安全、大数据安全、舆情分析、隐私保护、密码学及其应用、网络空间安全实战、网络空间安全治理等。- 网络空间安全框架
- 设备层安全:物理、环境、设备安全
- 系统层安全:网络、计算机、软件、操作系统、数据库安全
- 数据层安全:数据、身份、隐私安全
- 应用层安全:内容、支付、控制、物联网、应用安全
- 网络空间安全框架
-
网络空间安全需求
- 互联网治理问题:信息对抗、舆论安全、网络攻防体系建设
- 移动互联网安全、可信计算、云计算安全、大数据安全、物联网安全、广电网安全
- 特定安全保障:在线社交网络、工业控制安全、支付安全
-
网络空间安全问题
- 网络空间安全模型:基于闭环控制的动态信息安全理论模型(P2DR2)
第四章:网络安全技术
4.1防火墙(firewall)概述
- 防火墙是网络安全防御系统,根据安全规则,对相应的网络数据流进行监视和控制。
- 网络防火墙
外部网络(不可信任网络)和本地网络(可信任网络)之间的所有数据流都需要经过网络防火墙的处理,拦截异常数据流。 - 主机防火墙
- 防火墙的作用
- 安全域划分与安全域策略部署:将安全需求相同的接口或IP地址划分到相同的域,实现策略的分层管理,将网络划分为:不可信区域,可信区域,DMZ区域
- 根据访问控制列表实现访问控制
- 防止内部信息外泄:屏蔽泄露内部细节服务的信息,将内部网络结构隐藏起来。
- 审计功能:审查网络连接记录、历史记录、故障记录
- 部署网络地址转换:缓解地址短缺问题,隐藏地址网络信息。
- 防火墙的局限性
- 无法防范来自网络内部的恶意攻击
- 无法防范不经过防火墙的攻击
- 防火墙会带来传输的延迟、通信瓶颈和单点失效等问题
- 防火墙无法阻止对服务器合法开发的端口
- 防火墙本身存在漏洞而遭到攻击
- 防火墙不能处理病毒和木马攻击
- 限制了存在安全缺陷的网络服务,影响了用户使用服务的便利性
- 网络防火墙
4.2防火墙关键技术
- 数据包过滤技术:检查网络中每个通过对数据包,根据访问控制列表的通行规则,决定对一个数据包的放行、丢弃。
- 在防火墙中检查数据包基本信息:IP地址、数据包协议类型、端口号、进出的网络接口,与预期的访问控制列表进行对比。
- 优点:对用户透明、通过路由器实现、处理速度快
- 缺点:规则表的制定复杂、核查简单、以单个数据包为处理单位
- 应用层代理技术:作用在应用层,用来提供应用层服务的控制,在内部网络向外部网络申请服务时起到中间转接作用
- 优点:不允许外部主机直接访问内部主机,将内外完全隔离,比较安全;可以提供多种用户认证方案;可以分析数据包内部的应用命令;可以提供详细的审计记录
- 缺点:
- 对于每一种应用服务都必须为其设计一个代理软件模块来进行安全控制,而每一种网络应用服务的安全问题各不相同,分析困难,因此实现也困难。对于新开发的应用,无法通过相应的应用代理。
- 由于检查整个应用报文内容,存在延迟问题
- 状态检测技术:采用一种基于连接的状态检测机制,将属于同一个连接的所有包作为一个整体的数据流来看待,建立连接状态表,并进行维护通过规则表和状态表的共同配合,动态地决定数据包是否被允许进入防火墙内部网络。应用于网络层、传输层、应用层,跟踪通过防火墙的网络连接和数据包,并使用一组状态检测标准,已确定是否允许或拒绝通信
- 优点:具备较快的处理速度和灵活性;具备理解应用程序状态的能力和高度安全性;减小了伪造数据包通过防火墙的可能性
- 缺点:记录状态信息,会导致网络迟滞;跟踪各类协议,技术较为复杂
- 网络地址转换技术:最初用来解决私有IP地址的上网问题
- 转换方式:
- 多对1映射:多个内部网络地址翻译到一个IP地址,来自内部不同的连接请求可以用不同的端口号来区分(常用于普通家庭)
- 1对1映射:网关将内部网络上的每台计算机映射到NAT的合法地址集中唯一的一个IP地址(常用于Web服务器)
- 多对多映射:将大量的不可路由的内部IP地址转换为少数合法IP地址,可以隐藏内部IP地址分为静态翻译、动态翻译
- 优点:对外隐藏内部网络主机地址;实现网络的负载均衡;缓解互联网IP地址的不足问题
- 个人防火墙技术:安装在本地计算机上的系统安全软件,可以监视传入传出网卡的所有网络通信,使用状态检测技术,保护一台计算机免受攻击
- 优点:增加了保护级别,不需要额外的硬件资源,通常是免费的软件资源
- 缺点个人防火墙自身受到攻击,可能会失效,而将主机暴露在网络上
4.3入侵检测技术IDS:
一种主动的安全防护技术,以旁路方式接入网络,通过实时监测计算机网络和系统,来发现违反安全策略访问的过程。继防火墙之后的第二道防线,在不影响网络性能的前提下,通过实时收集和分析计算机网络或系统的审计信息,来检测是否出现违反安全策略的行为和攻击的痕迹,达到防止攻击和预防攻击的目的。是对防火墙的有益补充,可以在网络系统中快速发现已知或未知的网络攻击行为,扩展了系统管理员的安全管理能力,提高安全系统的完整性。
- 作用和优势
- 能快速检测入侵行为
- 能形成网络入侵的威慑力,防护入侵者的作用
- 收集入侵信息,增强入侵防护系统的防护能力
- 主要功能
- 监控、分析用户和系统的活动
- 发现入侵企图和异常现象
- 审计系统的配置和漏洞
- 评估关键系统和数据文件的完整性
- 对异常活动的统计分析
- 识别攻击的活动模型
- 实时报警与主动响应
- 入侵检测通用模型

- 事件产生器:负责原始数据采集,对数据流、日志文件进行追踪,将原始数据转换为事件,并提供给其他组件。
- 事件分析器:接收事件信息,并采用检测方法进行分析,判断是否入侵行为或者异常现象,将分析结果转换为警告信息。
- 相应单元:根据警告信息做出反应,以阻止入侵。
- 事件数据库:从事件产生器和事件分析器接收数据,存放各种中间或者最终数据。
-分类:
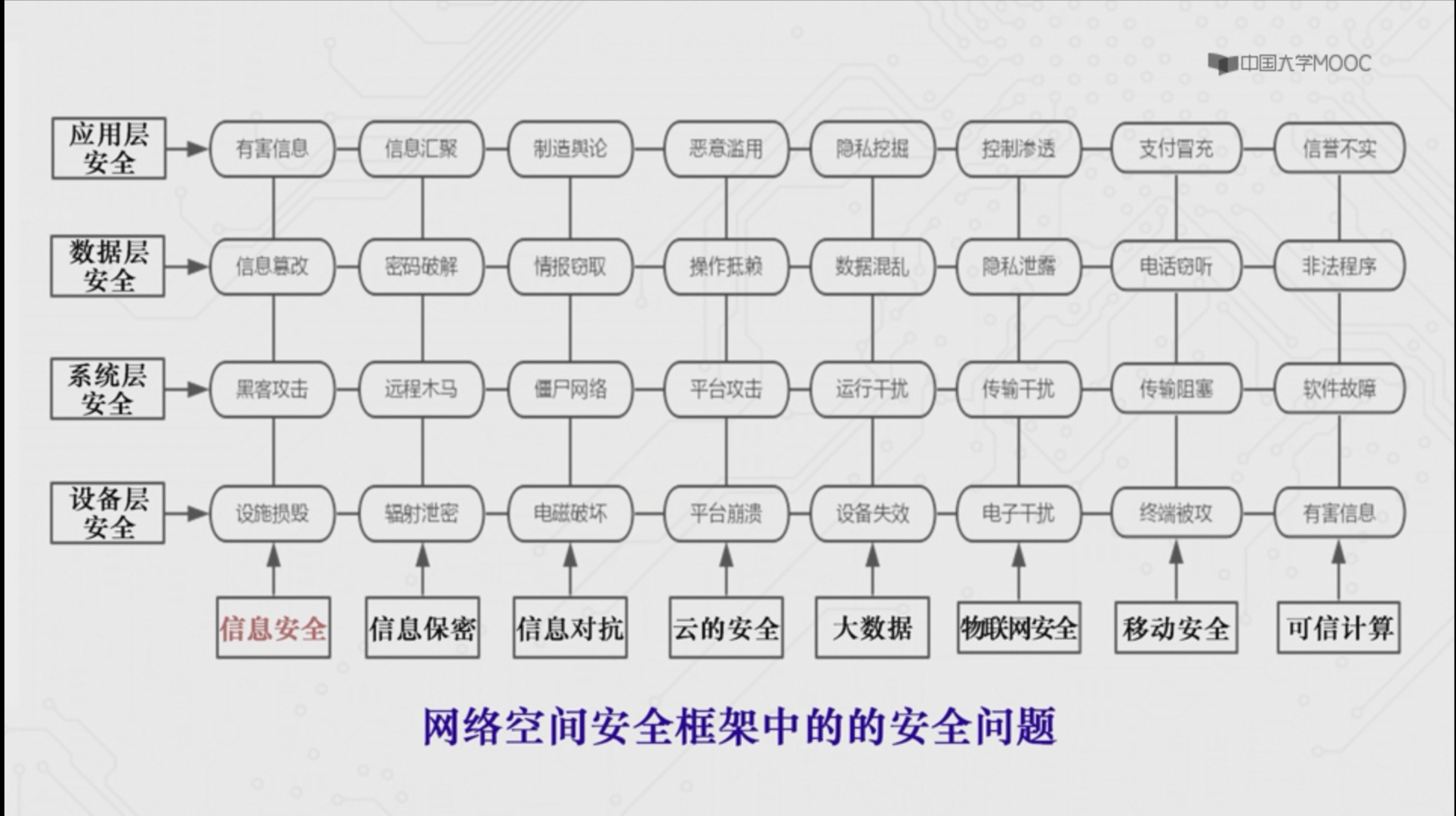
- 基于网络的入侵检测系统
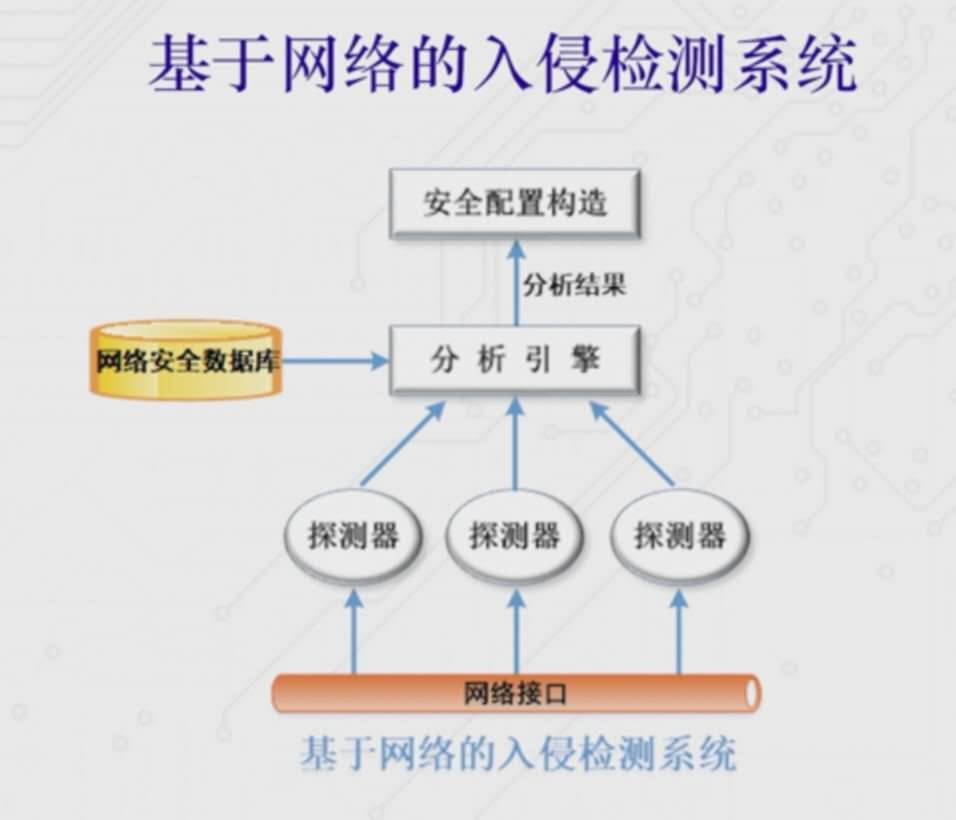
- 基于主机的入侵检测系统
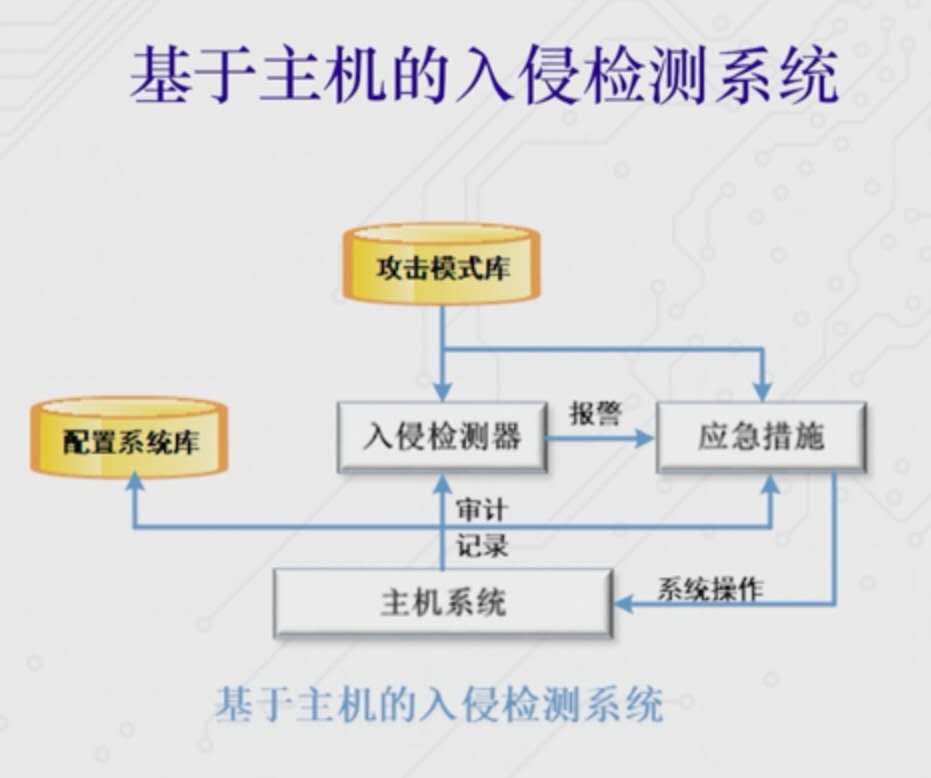
- 分布式入侵检测系统(综合前两个检测系统)
- 入侵检测方法分类
- 特征检测(误用检测),检测已知攻击
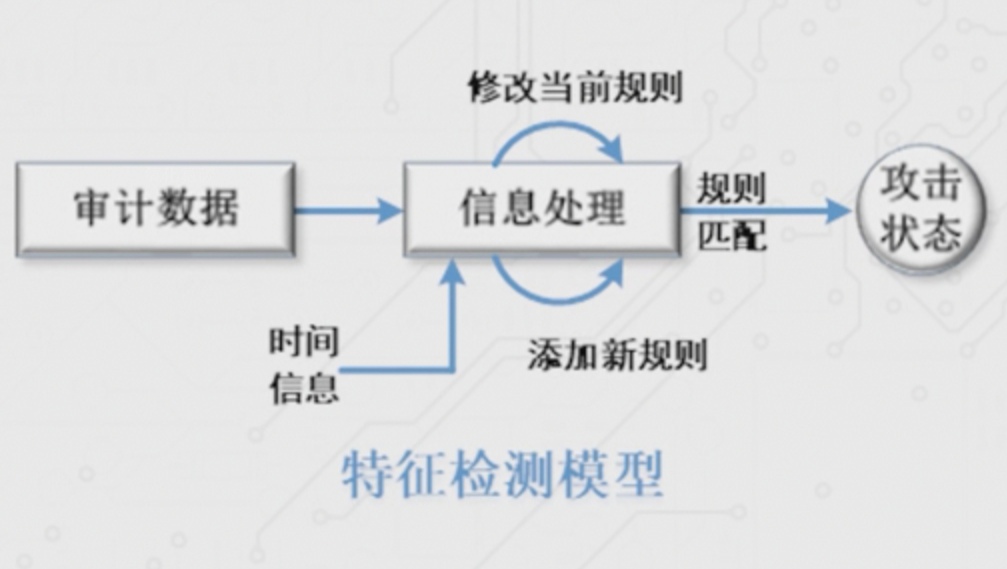
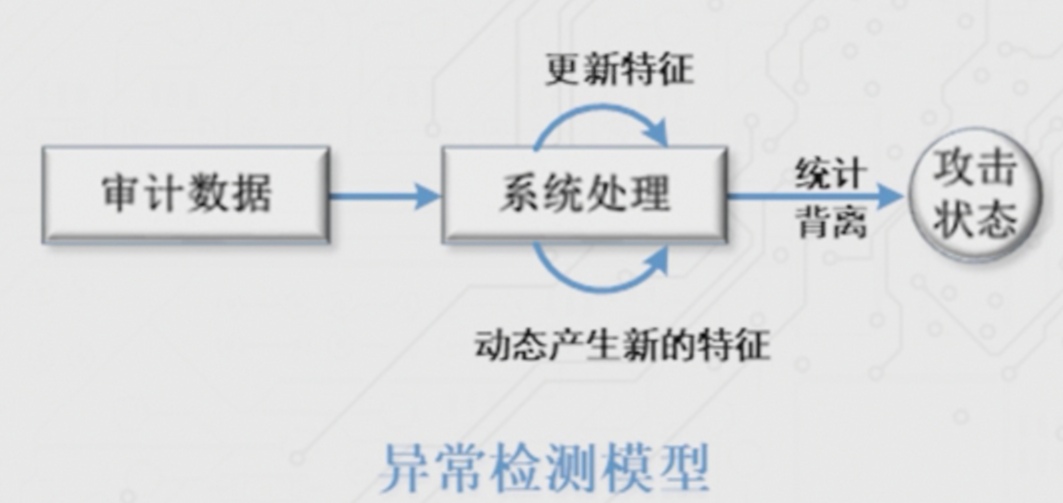
- 异常检测,检测未知攻击,用机器学习建立正常的用户使用模型,易产生误报和漏报。
4.4虚拟专用网VPN
-
使用本地IP地址,实现机构内部主机的地址分配,无需使用全球IP地址
-
原理

-
远程接入VPN:流动用户访问内部网络
二、程序题(80'+50')
对于你所完成题目,把实现思路和实现结果记录在博客中,把代码提交到github的仓库上。
背景
大学期间,你总是点子很多,你利用申请的专利,开了一家互联网公司,为客户提供高效、快捷的服务。
有一天,订单量突然大涨,欣喜之余,秘书却告诉你,今天的营业额跌到谷底,客服电话被打爆。
你发现,看似很多的订单请求,其实只是给你发了一个“hello”而已,服务器忙于应付大量的hello, 已经没办法给原有用户提供正常的服务了,基本处于瘫痪的状态。
经过讨论,可能是受到了黑客的DDos(分布式拒绝服务)攻击。黑客通过发送大量的无用的请求信息,占用你的服务器资源,让服务器没法给用户提供正常的服务。
做法
当务之急,是先恢复服务器,把攻击你的黑客都拉进黑名单,让服务器不要理会这些请求。
第一步,就是要把黑客检测出来。
你需要对请求进行审查,找出其中有问题的请求,然后把发送方拉黑。
这些请求长这个样子:发送方的名字由4个小写英文字母组成,后面跟着接收方和请求信息的大小,你可以通过请求信息的大小推测请求的内容。
发送方 接收方 请求信息的大小 发送方 接收方 请求信息的大小
abcd bob 64 abcd bob 64
khfd bob 265 abcd bob 64
okng bob 364 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
dasj bob 863 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
abcd bob 64 abcd bob 64
……
你的服务器就是那个可怜的Bob,而发送方有很多,有的是普通用户,而有的就是黑客了。
很明显,黑客在短时间给你发了大量的信息,发送方中的 abcd 就很有可能是黑客,因为他在短时间内给你发了很多信息量很小的请求(64,很可能只有hello),而且这些请求值总值已经超过了1500。本着宁错杀一千,不放过一个的原则,只要总的请求信息的大小超过T=1500,就把它拉黑。
描述
编程语言不限
热身题(20')
- 学习基本的文件读写
- 读提供的文件Request.txt
- 把里面的内容写到output.txt
基本题(60')
- 根据提供请求的输入Request.txt,把所有请求和对应的信息大小都存下来。
- (c语言:可以自己定义结构体,用上结构体数组,也可以用其他方法)
- (c++:可以考虑使用stl的库里的map)
- (推荐python:可以考虑使用字典)
- 统计每个发送方的总请求大小S,S超过T的就认定为黑客,把他们的名字存进你的黑名单里。
-输出黑客的个数,和这些黑客的名字。
例如:示例中有28个请求,其中abcd发了25个请求,这些请求的总和S是1600>1500=T,所以abcd被认为是黑客,就把abcd加到你的黑名单里去。 - 输入:
名字和信息大小用一个空格隔开,每条信息用一个换行隔开
lhyy bob 100
hzrr bob 700
cyxx bob 364
lhyy bob 700
lhyy bob 800
zzyy bob 300
zzyy bob 800
zzyy bob 600 - 输出:
第一行输出黑客的总个数,第二行输出黑客名,每个黑客名用一个换行隔开
2
lhyy
zzyy
基本思路:
- 用python的字典实现
- f.readlines()将文件中的文本逐行读取
- 用x = line.split(' ',2)将每一行分成三部分,储存在列表x[]中
- 将x[0]存为字典的key,x[2]存为value,对相同的key,value的值累加。
- 遍历整个字典的value,若value>1500,则将对应的key存入输出文件中(value在读入,分块以后为str,要用int()转为int类型)
- 每写入一次key,i的值加一,以便计算黑客数量
基本题代码地址
开放题(50')
-
问题一
- 总请求大小超过1500的不一定代表就是黑客,可能有的客户一次请求就达到了1500,从而导致失去大单
- 解决方案:设置两个判断标准,只有总量大而且发送次数多的发送方会被当做黑客
-
问题二
- 难以界定请求大小的合理范围,可能会因为定的上限导致问题,例如在总的统计数量很大的情况下(例如统计所有的历史记录),可能会使得所有用户的请求的大小都超过1500
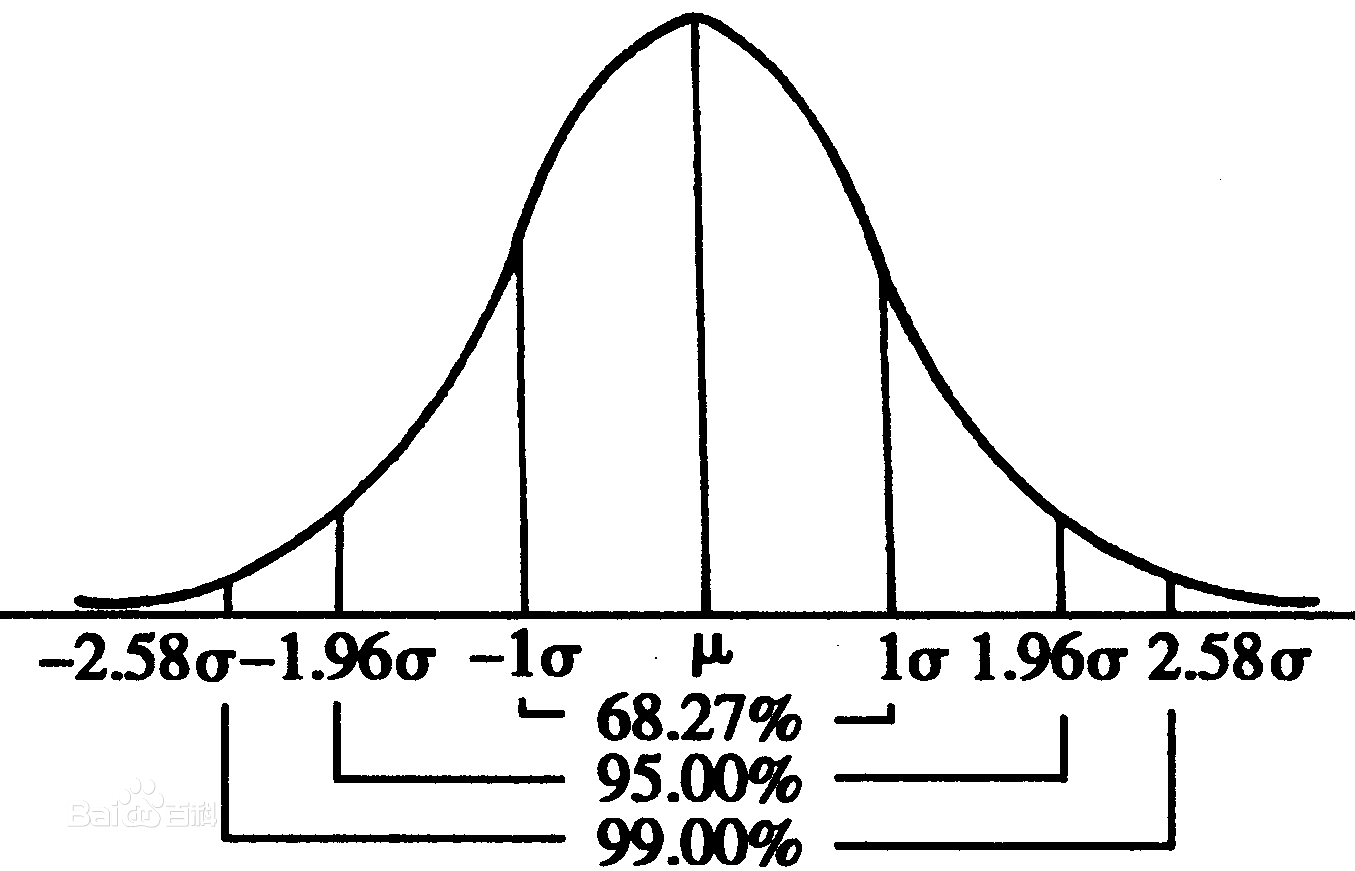
- 解决方案:统计所有用户的请求总大小,计算正态分布曲线
,将请求大小在P{|X-μ|<2σ}=2Φ外的发送方列为黑客
-
选做:实现你的方法
之所以选择正态分布判断是因为,正态分布在判断一些小概率、不可能事件中更为科学有效。
改进代码地址
修改代码时遇到的一些坑和教训: -
变量要做比较的时候,应注意其类型是否相同
-
python中的乘方与开方应使用“2”、“0.5”实现
-
变量命名要有意义,避免杂乱,影响思考和修改
修改过程中发现的问题: -
1.发送次数的上限难以确定,可能是因为样本数量不够大所导致的。
-
2.正态分布的合理范围难以确定,之前认为应该是X>(μ+2σ)是因为在百度百科上看到词条解释中有一句话:“由于“小概率事件”和假设检验的基本思想 “小概率事件”通常指发生的概率小于5%的事件,认为在一次试验中该事件是几乎不可能发生的。”,因为P{|X-μ|<2σ}=2Φ内的概率接近95%,故认为应该为2σ。但在改进过程中发现并非如此,95%的范围过于宽泛,容易把一些非黑客发送方纳入其中。而且因为第一个问题的存在,发送次数难以起到辅助判断的效果,导致在试验的时候结果与预期不符。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号