

Root Out Elusive Production Bugs with These Effective Techniques
Posted on 2009-04-11 10:04 饭后爱 阅读(522) 评论(0) 编辑 收藏 举报This article discusses:
- ADPlus and dumps
- First-chance and second-chance exceptions
- Debugging managed and unmanaged hangs and crashes
Contents
Debugging Tools for Windows
Using ADPlus
Debugging Symbols
First-Chance Exceptions
Unmanaged First-Chance Exceptions
Managed First-Chance Exception
Unmanaged Thread Executing Endlessly
Managed Thread Executing Endlessly
Deadlocks
Unmanaged Deadlock Application
Managed Deadlock Application
Crashing
Conclusion
Errors in code are inevitable. No matter how much testing you have done, when your application is deployed in a production environment, errors will occur. These problems can manifest as standard exceptions, as hangs where the CPU is being used 100 percent of the time, as deadlocks, where a couple of threads are locked and will never release the other's resources, and as crashes, where the application dies a silent death.
In these cases, error logs often provide little or no help in pinpointing the exact line of code in which the problem originates. As you can't usually isolate the root cause by modifying code in a production environment, most developers try to recreate an identical production environment on their workstations. They copy the specific components, the customer's database (if any), and then try to reproduce the problem in their debugger. At best the error will be reproduced and the failing code found; at worst the same error won't occur at all. Recreating the exact same production environment is very difficult due to the large number of potential software and hardware configurations. Furthermore, it may not be feasible or permitted to copy large secure databases, or to even get the necessary configuration information from the client.
In this article, I will demonstrate how to solve each of the problems described using managed and unmanaged applications without having to recreate the production environment. For each example, I will show you how to find the root cause using the appropriate debugger commands. So that you can start using these techniques right away, I'll cover only the most important commands for these situations; if you're interested in digging further, refer to the other resources mentioned throughout the article.
Debugging Tools for Windows
The debugging tools for Windows® can be downloaded from Debugging Tools for Windows. The package includes a number of tools that will help developers with post-mortem debugging, the most useful of which is ADPlus. This is a console-based VBScript that can automatically create memory dump and log files. ADPlus effectively calls the console debugger (CDB) with a number of command-line options to obtain its output. The most useful feature is that you can create dump files for production issues when they occur.
Dump files contain a snapshot of the memory space of a process, and are most useful when that process is failing—hanging, crashing, or simply throwing an exception. There are two common types of dump files: full and mini dumps. A full mode dump is typically much larger than a mini dump because it contains all committed pages of memory owned by the application. A mini dump only includes selected parts of a process's memory (basically just call stacks). As an example, a full dump of notepad.exe editing a small text file may be about 20MB, whereas a mini dump would be around 7KB.
The best feature of dump files is the ability to capture a call stack. You can see exactly what your application was doing at the time the problem occurred. There is no ambiguity; the call stack reveals exactly what is happening within the process. Most of the time you can quickly identify the problem code and resolve the issue.
Using ADPlus
ADPlus can be started in either hang or crash mode. In hang mode, ADPlus takes a snapshot of the process at that point in time, so it should be run when the application is actually hanging. When the process memory is being dumped, the process is frozen. The debugger non-invasively attaches to the process; when the dump finishes, the debugger detaches and the process resumes execution.
A debugger attached to a process can receive two types of notifications for each thrown exception: first and second chance. The debugger gets the first chance to handle the exception. If the debugger allows the execution to continue and does not handle the exception, the application will see the exception as usual. If the application does not handle the exception, the debugger gets a second chance to see the exception. In this case the application would normally crash if the debugger was not present. Figure 1 shows the interaction between the debugger and the application to which it is being attached (the debuggee).
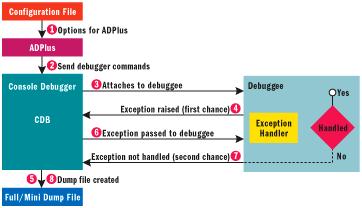
Figure 1 Interaction Between Debugger and Debuggee
Crash mode starts the CDB and attaches to the process specified. It remains attached to the process until either a second-chance exception is caught or the user presses Ctrl+C to detach from the debugger. In this case a full dump is taken of the process before it terminates. ADPlus can be left running in crash mode until a crash occurs. You should not notice any performance degradation when running in this mode unless many first-chance exceptions are being raised, causing mini dumps to be created frequently. This is not the only use for crash mode, however. One of the most useful and lesser known features of ADPlus is the creation of mini dump files when first-chance exceptions are raised. By capturing dump files for each exception raised, you can quickly find the root cause of the problem. ADPlus provides a configurable option called OutputDir to specify the folder in which to create dump files. Because some full dump files are huge, you must set up this folder on a drive with a lot of available space. It is painful to have ADPlus running in crash mode waiting weeks for a crash, and then have it fail to capture a dump because of insufficient space for the dump file.
WinDBG, one of the debuggers in the toolkit, is a powerful tool capable of both user-mode and kernel-mode debugging. It is effectively a GUI to the lower-level debuggers CDB/NTSD and KD. Although it is usually used to debug kernel mode device drivers and system services, WinDBG can also be used for common user-mode applications. When I discuss each error later on, I will show the specific WinDBG commands that are required to read and analyze the dump files.
Debugging Symbols
Debugging symbols are essentially data containing source, line information, data types, variables, and functions that allow the debugger to provide symbolic names rather than the hex addresses of all the functions. Symbols are distributed in files with a PDB extension. Make sure to always create and store symbols for every build of your application, including release builds.
When opening a dump file in WinDBG, the debugger will look for the correct PDB file using an internal timestamp stored in the PE header of the DLL. This is why it is essential to create the PDB files as you release new builds. Options for enabling this within all configurations of a C# project are shown in Figure 2. The steps to enable this for C++ applications are available at Generating and Deploying Debug Symbols with Microsoft Visual C++ 6.0.
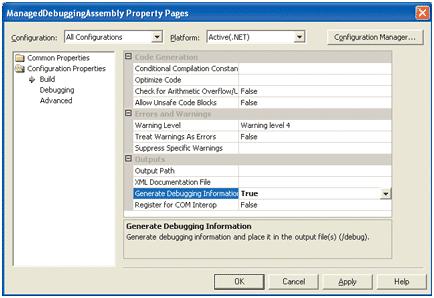
Figure 2 Generating Debugging Symbols for C# Projects
_NT_SYMBOL_PATH is an environment variable containing the path where debuggers, including WinDBG, will look for symbols. This path should point to both operating system symbols and any application symbols you've already created. To make it easy to obtain the correct symbols for the version of Windows you're using, including any installed service packs and hotfixes, Microsoft has created a symbol server which allows for the correct versions of all operating system symbols to be downloaded automatically. Simply set _NT_SYMBOL_PATH to the following:
SRV*<path to download symbols to>*http://msdl.microsoft.com/download/symbols
If you use a shared network drive, all other developers on your team can access the symbols you've downloaded and vice versa. Once they are downloaded, they will always be obtainable locally from the file system, unless new versions of DLLs are released.
When analyzing a dump file, you will also need to ensure that the debugger can find your application debugging symbols. The .sympath+ command can be used from within WinDBG to append the path of directories where your application debugging symbols are located:
0:000> .sympath+ C:"Assemblies"Tranmit.Sprinter.Invoicing"bin"release
Symbol search path is: SRV*""d:"windows"symbols*http://msdl.microsoft.com/download/symbols;C:"Assemblies"Tranmit.Sprinter.Invoicing"bin"release
Now that you have created separate PDB files for each DLL version, you will need to know which versions of your components were running when the dump was created. The simplest way to do this is by using the lmvm debugger command:
0:000> lmvm UnmanagedProductionDebuggingEngine
start end module name
01650000 0165e000 UnmanagedProductionDebuggingEngine (deferred)
Image path: d:"UnmanagedProductionDebuggingEngine.dll
Timestamp: Sat Oct 23 11:40:43 2004 (417A352B) Checksum: 00000000
File version: 1.0.0.0
Product version: 1.0.0.0
File flags: 0 (Mask 3F)
File OS: 4 Unknown Win32
File type: 2.0 Dll
File date: 00000000.00000000
You can easily see that version 1.0.0.0 of UnmanagedProductionDebuggingEngine.dll was running; therefore, you can point the symbol path to the correct PDB folder for this version.
A lot of articles on production debugging mention the importance of copying the symbols onto the client's server both for the operating system and the application. I strongly recommend against this. First, your application can be more easily reverse-engineered by clients with your PDBs. Second, this provides very little benefit anyway, as most of the dump analysis you do will be performed on your own development workstation and not on the client's site. The only advantage of having correct symbols installed on the server is that the text log files produced by ADPlus are more meaningful because they display call stacks with symbolic names. However, analysis of dump files usually requires more information than simply seeing the stack; it requires information such as variables and arguments on the stack.
First-Chance Exceptions
It is often useful to analyze exceptions that are thrown but not caught correctly, and there are situations in which exception information is lost. Perhaps you are using Visual Basic® in ASP pages and are making use of the On Error Resume Next statement. If the code doesn't handle errors in all cases, error information can be lost and useful information overwritten by other errors. Some exceptions may be caught and handled incorrectly by the application, which then subsequently causes other errors to occur. You may also have some .NET-based code that catches an exception and rethrows it, losing all important error information. Analyzing the contents of these initial exceptions may be crucial to pinpointing the cause of the error.
Before I look at an unmanaged application throwing a first-chance exception, there are some important points to go over. ADPlus does not by default create mini dumps for first-chance exceptions of type "unknown" and "C++." The documentation states that this is because it is quite common for applications to generate a significant number of these legitimately. If you're performing production debugging for C++ and Visual Basic components, you most certainly will want to enable mini dump creation for such exceptions. Visual Basic applications raise unknown exceptions when errors occur and C++ applications frequently throw C++ exceptions. Enabling mini dumps for these exceptions can only be done through XML configuration files, which ADPlus uses. An ADPlus config file is provided to show you the options that need to be set for some of the sample apps; other samples only require simple ADPlus command-line configuration.
Unmanaged First-Chance Exceptions
My first example is an unmanaged application, UnmanagedFirstChanceException, which throws an exception when attempting to read information from a configuration file using the C++ CStdioFile class and handles it (see Figure 3).
Figure 3 Unmanaged FirstChanceException
try {
// Load the configuration file into the first stream
CStdioFile configurationFile1(
_T("Configuration.xml"), CFile::modeRead);
if (IsWindows2000()) {
// Load the configuration file into a second stream
CStdioFile configurationFile2(
_T("Configuration.xml"), CFile::modeRead);
}
... // parses configuration file to obtain all settings
}
catch(CFileException *pException) {
cout << _T("Failed to find configuration file") << endl;
}
The code seems odd because it tries to read the config file into a CStdioFile object twice if it detects that it is running under Windows 2000. And since configuration information for the app isn't loaded in all cases, it is quite possible that this code block has never been tested prior to its release into production.
When the app is run in production, the message "Failed to find configuration file" is output. After you've verified that the file does indeed exist in the same location as the application, it is difficult to know where to start your diagnosis. On further reading through the code, it is clear that the CFileException object can be thrown from within the CStdioFile constructor for a variety of reasons other than file not found. If an attempt to reproduce this problem on your own developer workstation proves to be unsuccessful, you'll then need to determine why the exception is being thrown on the production system.
You need to run ADPlus in crash mode to obtain the first-chance exception for the CFileException object. But first, you need to create the configuration file ADPlus will use to create the mini dump file. Remember that you must use configuration files rather than command-line options because C++ exceptions need to be captured. The UnmanagedFirstChanceExceptionConfig.xml file provides the configuration required for ADPlus to catch the exception dump. Most of the time ADPlus will be used to attach to already running processes; in some cases this will not catch exceptions that occur when the process is starting. In this example, if the process starts and then exits very quickly, ADPlus will not be available to attach to the process in time. The ADPlus spawn option is therefore a good choice. It allows the debugger to spawn the process internally and begin monitoring it as soon as it starts. You will need to modify the spawn element in the configuration file to point to the full path of the executable on your machine.
When the configuration file has been created, ADPlus should be run using the following options:
adplus –c full_path_to_config_file
The UnmanagedFirstChanceExceptionConfig.xml config file, available on the MSDN®Magazine Web site in the code download for this article, will inform ADPlus to effectively start the UnmanagedFirstChanceException application in a suspended state, attach the debugger to the process, and then notify the primary thread of the process to resume execution. ADPlus will create another folder in the output directory that includes the process name, process identifier, and date/time stamp. Within this folder you should see two dump files, one created when the first-chance exception was raised, and the other when the process was shut down.
Open up WinDBG and press Ctrl+D to select and open the first-chance exception dump file you've created. Before you do anything else, you need to set the symbol path to the folder containing your application .pdb file. In a production system you have to find the version of the component the dump was created with, and then set the path to the folder with the correct .pdb file for this version. The lm v command will list all modules loaded into the process together with the version of the module. In the example, the symbol path can simply be set by using the !sympath+ command and appending the full path to the .pdb file found in the release folder of your application.
Once the dump file is loaded, enter kb to see a full call stack. Providing that all the symbol paths have been set correctly, the stack should look like the following:
0:000> kb
ChildEBP RetAddr Args to Child
WARNING: Stack unwind information not available. Following frames may be
wrong.
...
0012fec4 7c1cd441 0000000B 00000002 003252d8
MFC71!AfxThrowFileException+0x45
[f:"vs70builds"3077"vc"mfcatl"ship"atlmfc"src"mfc"filex.cpp @ 118]
0012ff00 00401034 00402110 00000000 00000000
MFC71!CStdioFile::CStdioFile+0x60
[f:"vs70builds"3077"vc"mfcatl"ship"atlmfc"src"mfc"filetxt.cpp @ 58]
012ff58 004010d7 7c90ee18 004013c8 0000001
UnmanagedFirstChanceException!LoadConfigurationData+0x34
[d:"unmanagedfirstchanceexception"unmanagedfirstchanceexception.cpp @ 53]
...
Child Extended Base Pointer (ChildEBP) points to the beginning of the local information for the current stack frame, RetAddr tells each call where to return when it's finished, and Args to Child contains three columns that represent the arguments passed to the called child or function. It is clear an exception is thrown from the CStdioFile constructor after the call to AfxThrowFileException. The documentation for this method reveals that it takes the cause of the exception as the first parameter. Now all you need to do is find the value of this parameter from the dump. The first argument to most routines shown on the stack is in the first column of DWORDs under the "Args to Child" heading in the stack trace. Here you can see the value of the first parameter to AfxThrowFileException is 0xB (11 in decimal).
If you review the Afx header file in the MFC source code, you can see the different causes for an exception to be thrown. The value 11 indicates a sharing violation:
class CFileException : public CException {
DECLARE_DYNAMIC(CFileException)
public:
enum {
none, generic, fileNotFound, badPath, tooManyOpenFiles,
accessDenied, invalidFile, removeCurrentDir, directoryFull,
badSeek, hardIO, sharingViolation,
lockViolation, diskFull, endOfFile
};
Because the symbols contain line number information, you can also see from the call stack that the exception was thrown on line 53 of the LoadConfigurationData method. It is now very clear that a sharing violation was thrown because the Configuration.xml file was already opened at the point the second CStdioFile was being created. You have now pinpointed why the exception was raised, so you can proceed to fix the issue.
This shows that because of environment conditions it's not always possible to reproduce problems. The developer was trying to reproduce the problem on his Windows XP workstation rather than the Windows 2000 operating system used in production. This meant that two calls were not being made to open the same file.
Managed First-Chance Exception
The next example I'm going to look at is a first-chance exception generated from a .NET managed application. I've included a sample ASP page that uses COM interop to access a managed object (using Server.CreateObject) in the download with this article. To reproduce the issue, click on the "Load a purchase order" link in the managed issues section of the default.asp page. The page attempts to initialize a purchase order given an ID of 200 using the PurchaseOrder.InitializeFromID method, as shown in Figure 4. Although you can see the argument passed is incorrect, the client of this method will not have a clue from the message passed to the BusinessObjectException constructor.
Figure 4 Managed Exception Thrown
try {
if(id <= 1000) // ID must always be greater than 1000
throw new ArgumentOutOfRangeException( "id", id,
"InitializeFromID expects ID value to be greater than 1000");
}
catch(ArgumentOutOfRangeException exception) {
throw new BusinessObjectException( String.Format( "Failed to
initialize purchase order ID={0} from database", id), exception);
}
The techniques used to analyze these kinds of exceptions are very similar to those used for the unmanaged application, with a few differences. Since WinDBG doesn't support viewing internal common language runtime (CLR) data structures and call stacks, you'll need to use a WinDBG extension called Son of Strike (SOS). All dumps created to analyze .NET exceptions through SOS should be created as full dumps, even if only first-chance exceptions are raised, as SOS requires certain well-defined subsets of a process's memory to do its work. For the Microsoft .NET Framework 2.0, these sections are included in mini dumps.
Often exceptions in managed code are nested within other exceptions as internal exceptions, as exceptions are thrown from one layer to another and wrapped with an exception appropriate to that level. To avoid generating dumps for all of these inner exceptions, you can create a more targeted configuration file, which simply creates dumps only when a particular type of exception is thrown. This is shown in Figure 5.
Figure 5 ADPlus Config File
<ADPlus>
<Settings> <RunMode>CRASH</RunMode> </Settings>
<PreCommands> <Cmd> !load clr10"sos </Cmd> </PreCommands>
<Exceptions>
<Option> NoDumpOnFirstChance </Option>
<Option> NoDumpOnSecondChance </Option>
<Config>
<Code> clr </Code>
<Actions1> Log </Actions1>
<CustomActions1> !clr10"sos.cce
ManagedProductionDebuggingAssembly.BusinessObjectException
1; j ($t1 = 1) '.dump /ma /u
ManagedFirstChanceExceptionFull.dmp;gn' ; 'gn'
</CustomActions1>
<ReturnAction1> GN </ReturnAction1>
<Actions2> Void </Actions2>
<ReturnAction2> GN </ReturnAction2>
</Config>
</Exceptions>
</ADPlus>
If you start ADPlus using this configuration file and reproduce the problem, you should see only one dump file created for the code in Figure 4. After running the code, you will notice a slight pause while the dump file is created in the folder where the debugging tools were installed.
I will now use commands similar to those John Robbins highlighted in his excellent SOS column in the June 2003 issue of MSDN Magazine. To load the SOS extension, use the command !load clr10/sos.dll. Since you know the dump file will be stopped in the current thread that caused the exception, you can execute the !dumpstackobjects command to find the exception detail (see Figure 6).
Figure 6 !dumpstackobjects Command
0:022> !dumpstackobjects
succeeded
Loaded Son of Strike data table version 5 from "D:"WINDOWS"Microsoft.NET"Framework"v1.1.4322"mscorwks.dll"
ESP/REG Object Name
0147e920 058b41d8 ManagedProductionDebuggingAssembly.BusinessObjectException
0147e938 058b41d8 ManagedProductionDebuggingAssembly.BusinessObjectException
0147e94c 058b41d8 ManagedProductionDebuggingAssembly.BusinessObjectException
0147e970 058b41d8 ManagedProductionDebuggingAssembly.BusinessObjectException
0147e9b4 058b41d8 ManagedProductionDebuggingAssembly.BusinessObjectException
0147e9c8 058b4268 System.String Failed to initailise purchase order ID=2
0147e9cc 058b41d8 ManagedProductionDebuggingAssembly.BusinessObjectException
0147e9d0 058b4390 System.Collections.Specialized.NameValueCollection
Inspect the BusinessObjectException exception object by executing !dumpobj 058b41d8 (see Figure 7). As I am interested in the innermost exception's content, I'll also need to review the inner exception of this exception. The memory address of the inner exception object can be used to execute a further !dumpobj command against this address which outputs the inner exception, as shown in the code in Figure 8.
Figure 8 Inner Exception Info for Managed Exception
Name: System.ArgumentOutOfRangeException
MethodTable 0x79b984bc
EEClass 0x79b9854c
Size 72(0x48) bytes
mdToken: 0200003a (d:"windows"microsoft.net"framework"v1.1.4322"mscorlib.dll)
FieldDesc*: 79b985b0
MT Field Offset Type Attr Value Name
79b8fd3c 400001d 4 CLASS instance 00000000 _className
79b8fd3c 400001e 8 CLASS instance 00000000 _exceptionMethod
79b8fd3c 400001f c CLASS instance 00000000 _exceptionMethodString
79b8fd3c 4000020 10 CLASS instance 058abf90 _message
79b8fd3c 4000021 14 CLASS instance 00000000 _innerException
79b8fd3c 4000022 18 CLASS instance 00000000 _helpURL
...
Figure 7 Viewing Managed Exception Information
0:022> !dumpobj 058b41d8
Name: ManagedProductionDebuggingAssembly.BusinessObjectException
MethodTable 0x017c57ec
EEClass 0x07a24b30
Size 92(0x5c) bytes
mdToken: 02000004 (d:"windows"system32"managedproductiondebuggingassembly.dll)
FieldDesc*: 00000000
MT Field Offset Type Attr Value Name
...
79b8fd3c 4000020 10 CLASS instance 058b4268 _message
79b8fd3c 4000021 14 CLASS instance 058b416c _innerException
79b8fd3c 4000022 18 CLASS instance 00000000 _helpURL
79b8fd3c 4000023 1c CLASS instance 00000000 _stackTrace
79b8fd3c 4000024 20 CLASS instance 00000000 _stackTraceString
...
As you can see, there are no further inner exceptions because the _innerException property is null (all zeros); use !dumpobj 058abf90 to view the actual message. This produces the output shown in Figure 9, with the message contents highlighted.
Figure 9 Inner Exception Message Property Value
0:022> !dumpobj 058abf90
Name: System.String
MethodTable 0x79b8db58
EEClass 0x79b8dea4
Size 132(0x84) bytes
mdToken: 0200000f (d:"windows"microsoft.net"framework"v1.1.4322"mscorlib.dll)
String: InitializeFromID expects ID value to be greater than 1000
FieldDesc*: 79b8df08
MT Field Offset Type Attr Value Name
79b8db58 4000013 4 System.Int32 instance 58 m_arrayLength
79b8db58 4000014 8 System.Int32 instance 57 m_stringLength
79b8db58 4000015 c System.Char instance 49 m_firstChar
79b8db58 4000016 0 CLASS shared static Empty
>> Domain:Value 001676b0:0583126c <<
79b8db58 4000017 4 CLASS shared static WhitespaceChars
>> Domain:Value 001676b0:05831280 <<
The output at the top of Figure 8 indicates that the name of the innermost exception is ArgumentOutOfRangeException. The message shown in Figure 9 mentions a condition that the ID value passed must be greater than 1000. You can therefore conclude that the client ASP page is causing the error because bad values are being passed into the component. Why not just capture any ArgumentOutOfRangeException types in the ADPlus configuration file? You may not always have the source code available for third-party components. This approach works whether you have source code available or not.
A side note: sometimes when analyzing .NET exceptions, you may not have ADPlus running in crash mode while a .NET exception is thrown that only occurs occasionally. In this case you may still be able to examine the contents of .NET exceptions—they might be lying around in the managed heap because garbage collection hasn't occurred. Try taking a hang dump just after reproducing this issue and then run the !DumpHeap -type BusinessObjectException command. You can then use the address shown for the object and follow the same set of commands as for the address found when !dumpstackobjects was run.
Unmanaged Thread Executing Endlessly
Some applications take over the processor entirely for a moment, which is fine. However, when processor usage remains high for more than a few seconds, it can indicate a hung process. Another symptom of a hung application is unresponsiveness.
Hanging applications are usually caused by one of two things: an endless loop in code leaves a thread executing endlessly while eating up CPU cycles (called a live lock), or a thread in a state where it is waiting for a resource that never becomes available (called a dead lock). In both cases troubleshooting needs to focus on isolating the path of code executing leading up to the hang.
The next example I'll look at is an unmanaged app stuck in an endless loop. The code that runs an endless loop will be created in a COM object call Bank. To show also how dump files can be used in IIS, this component will be called from an ASP page.
ADPlus can create hang mode dumps for specific processes, by ID or name, or by using the IIS option. The IIS option takes dumps of all IIS-related processes, which includes Web apps run in low protection (inside INETINFO.exe), medium protection (in a single DLLHOST process for all apps), and high protection (in a separate DLLHOST process for each app). The IIS option may be impractical on production systems with many Web applications, so it is best to target only the specific Web application's DLLHOST process. You can use the tlist command-line tool with the –k option to list all dllhost processes including the Web application name. You will probably know which Web application is being unresponsive because your users will tell you! In any case, you can confirm this using the Performance Monitor Process and Thread objects.
Since many different instances of DLLHOST can exist for separate Web apps run in high protection, by default Performance Monitor differentiates them using the # symbol and a sequence number: DLLHOST, DLLHOST#1, DLLHOST#2, and so on. Threads within a process also use the same scheme to differentiate themselves. It would be better to use the actual identifiers for the process and threads when selecting counters to add, which you can do by running the following registry script:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE"SYSTEM"CurrentControlSet"Services"PerfProc"Performance]
"ThreadNameFormat"=dword:00000002
"ProcessNameFormat"=dword:00000002
The next thing to do is to ensure the Web application is started and the DLLHOST process is created by browsing to the default Web page. Open PerfMon and add the "% Processor Time" counter for all DLLHOST instances from the Process object.
Now reproduce the issue by navigating to the Get Bank Balance page in the unmanaged issues section. You should notice immediately that one of the DLLHOST instances is using up all of the processor time (see Figure 10). At this point you can take a hang dump of this specific process using the command-line option:
adplus –hang –p process id
Figure 10 CPU Utilization in DLLHOST Process
Once you have the process ID, clear the existing counter set, and create a new one for all threads in this process to find which thread is using all the CPU time within this process.
If you have collected a hang dump of a process where no other Perfmon data is available, there is another method you can use to find the hanging thread. The !runaway extension displays information about the time consumed by each thread in the process. Because the runaway extension sorts by descending CPU time, the offending thread is usually the one at the top of the list. However, in long running processes the top threads are not always the offending threads, it can just be they are the most active. A better (but more laborious) way to identify a runaway thread is to compare two or more dumps a minute or so apart and try to spot those that have increased the most. As you can see in the code that follows, thread id 0x22c (decimal ID 556) is consuming the most CPU time, the same as the thread ID you found with the Performance Monitor counters.
0:000> !runaway
User Mode Time
Thread Time
22c 0 days 0:03:17.218
248 0 days 0:00:00.015
7a0 0 days 0:00:00.015
fa0 0 days 0:00:00.000
29c 0 days 0:00:00.000
Now that you have identified the hanging thread as 556, you need to find the corresponding thread number in WinDBG. Unfortunately, this mapping is required because of the way the threads are assigned and used in WinDBG. The ~ command prints the status for all threads in the current process:
0:000> ~
. 0 Id: f18.f28 Suspend: 1 Teb: 7ffdf000 Unfrozen
1 Id: f18.7a0 Suspend: 1 Teb: 7ffde000 Unfrozen
...
18 Id: f18.72c Suspend: 1 Teb: 7ffa5000 Unfrozen
19 Id: f18.22c Suspend: 1 Teb: 7ffa4000 Unfrozen
20 Id: f18.d60 Suspend: 1 Teb: 7ffa3000 Unfrozen
The columns from this command indicate, in order, the decimal WinDBG thread identifier, hex process ID, hex thread ID, the suspend count of the thread, address of thread environment block, and the thread status. The period before the 0 indicates this is the current thread. You can quickly see that the thread number for the hanging thread is number 19 (hex thread ID 22c).
Now that you have the thread number, look at the call stack for this thread by running the ~19kb command. ~19 means run the command for thread 19. Here are the results.
0:000> ~19kb
ChildEBP RetAddr Args to Child
0143f330 771273d0 016c2954 0003e948 0143f394
UnmanagedProductionDebuggingEngine!CBank::GetBalance+0x12
[d:"unmanagedproductiondebuggingengine"bank.cpp @ 34]
0143f350 771279e0 016c2954 0000001c 00000004 oleaut32!DispCallFunc+0x16a
0143f3e0 01653dc8 0017c284 016c2954 00000000
oleaut32!CTypeInfo2::Invoke+0x234
0143f404 7332ae0e 016c2954 00000001 73304dd0
...
You can clearly see that the function at the top of the call stack is GetBalance, currently executing line 34. Although your production components will require careful analysis to determine why it's entering an endless loop, this allows you to find the loop quickly.
Managed Thread Executing Endlessly
The managed application is very similar to the previous examples. A class Bank in the ManagedProductionDebuggingAssembly assembly contains the same behavior as the Bank COM object. Follow the same steps as in the "Unmanaged Thread Executing Endlessly" section to identify the thread using all the CPU time. When you've identified the thread, change the context in the debugger as before using ~<thread number>s and run the !clrstack command to see a managed call stack. The following shows the output for one test run:
0:022> !clrstack succeeded
Loaded Son of Strike data table version 5 from
"D:"WINDOWS"Microsoft.NET"Framework"v1.1.4322"mscorwks.dll"
Thread 22
ESP EIP
0147ea98 07d50078 [DEFAULT] [hasThis]
ValueClass System.Decimal
ManagedProductionDebuggingAssembly.Bank.GetBalance(String) at [+0x0] [+0x0]
d:"managedproductiondebuggingassembly"bank.cs:41
0147eb44 79240167 [FRAME: GCFrame]
...
Deadlocks
The next application to explore reproduces an unresponsive component. Although the net effect is also a hung application, the symptom is different because the CPU is not overutilized. This usually indicates a deadlock, but before I get into that, I need to examine multithreading.
Let's say you have created a class that performs work on CSV (comma-separated values) files, reading the data in and compiling statistics such as total number of records. If the class can be accessed by multiple clients at the same time, without a synchronization mechanism in place, the data could very easily become corrupted. For example, one thread, A, could be halfway through reading through all records in one CSV file when the operating system preempts it and schedules thread B to run. Thread B starts processing another file using the same shared variable as thread A to access the file. Thread B then gets preempted and Thread A is allowed to run again. At this point Thread A's file pointer is now pointing to a completely different file at a different location. The code on this thread will then run with undefined behavior, possibly causing the process to crash or data to become inconsistent.
You need to use a synchronization mechanism to ensure that while Thread A is reading the file, Thread B cannot change the shared variable until Thread A completes. A critical section is a mechanism that allows you to do this. At the point in the code that needs to be protected, you should enter the critical section; when you've finished running this section of code, you should leave the critical section. Only one thread in the process can be in the critical section at a particular time. Only when the thread leaves the critical section will another thread be allowed to enter. The Win32 API provides the EnterCriticalSection and LeaveCriticalSection methods and the .NET Framework provides the Monitor.Enter and Exit methods to allow you to do this. The Monitor class uses an internal CLR structure to provide synchronization; native Windows critical sections are not used.
Here's how a textbook deadlock occurs. Thread A acquires a resource using a critical section called CS1 to protect access. Thread B then runs and acquires a different resource using critical section CS2. Thread A runs and attempts to acquire critical section CS2 to access the resource that Thread B is using, blocking until Thread B releases it. If Thread B runs and attempts to acquire the critical section CS1 that Thread A owns, both threads will deadlock, as both are waiting for resources that are owned by each other. The result is a hung process—no code can execute on either thread now.
Note that many deadlocks occur due to other synchronization primitives such as events and mutexes. These require more elaborate debugging techniques and are outside the scope of this article.
If you find an application is unresponsive and you suspect a deadlock, you can take a hang dump when the application becomes unresponsive. Analysis of the dump file should reveal whether a deadlock has indeed occurred and which two threads in the process are deadlocked. Once you have identified the two threads, you can review their call stacks and hopefully determine why the deadlock has occurred.
Unmanaged Deadlock Application
To produce a sample unmanaged deadlock, open up the default.asp page in two browser windows. With both windows side by side, press the "Approve a purchase order" link in the unmanaged section in one window, and then the "Reject a purchase order" link in the unmanaged section in the other. You have 10 seconds in which to press on the second link to reproduce a deadlock. Now both requests from each window will be deadlocked. Now you can take a standard IIS hang dump.
Each page creates an instance of a PurchaseOrder object and calls either the Reject or Approve method. The implementation of the Approve method is shown in Figure 11.
Figure 11 Unmanaged Approve Method
STDMETHODIMP CPurchaseOrder::Approve()
{
AFX_MANAGE_STATE(AfxGetStaticModuleState());
{
CAccessLock<> lockLineItems(m_lockLineItems);
Sleep(10000);
{
CAccessLock<> lockObjectStatus(m_lockObjectStatus);
... // Approve the purchase order
}
}
return S_OK;
}
The CAccessLock class in the Approve method is effectively a wrapper around the CCriticalSection class, which calls the Lock method in the constructor and UnLock in the destructor. Two critical sections are acquired before the purchase order is approved, one to protect concurrent access to line items and the other one to protect the object state. The Reject method is similar; in this case the critical section m_lockObjectStatus is locked first and then m_lockLineItems is locked.
The first thing to do when analyzing a situation such as this is to verify the issue isn't 100 percent CPU utilization by looking at the results of the runaway extension. As you can see in the following, no threads are monopolizing the CPU:
0:000> !runaway
User Mode Time
Thread Time
1198 0 days 0:00:00.015
10f4 0 days 0:00:00.000
10dc 0 days 0:00:00.000
33c 0 days 0:00:00.000
c34 0 days 0:00:00.000
1628 0 days 0:00:00.000
Now you need to look at the critical sections in the process. You can view critical sections either by using WinDBG commands such as !cs to view all critical sections in the process, and then reviewing the call stacks of the other threads in the process waiting on these critical sections, or you can use a very handy WinDBG extension called SIEExtPub (available for download at Debugging Tools Download). The command !critlist displays a list of all critical sections in the process together with the thread owning the critical section and a list of all threads waiting on it. It will also identify deadlock situations:
0:000> !critlist
CritSec at a6a3c4. Owned by thread 16. Deadlocked on CritSec a6a3a4.
Waiting Threads: 15
CritSec at a6a3a4. Owned by thread 15. Deadlocked on CritSec a6a3c4.
Waiting Threads: 16
You can see that thread 16 owns a critical section that thread 15 is waiting on, but thread 16 is also waiting on a critical section held by thread 15, creating a classic deadlock situation. Once you have the thread numbers you can review the call stacks using the command ~<thread number>s to change status to the thread, then view the call stack. The stack for thread 15 is shown in Figure 12. The call stack for thread 16 is almost identical, the difference being a call to Reject instead of Approve.
Figure 12 Thread 15 Call Stack
0:015> kp
ChildEBP RetAddr
0143f254 7c90e9c0 ntdll!KiFastSystemCallRet
0143f258 7c91901b ntdll!ZwWaitForSingleObject+0xc
0143f2e0 7c90104b ntdll!RtlpWaitForCriticalSection+0x132
0143f2e8 00a659d7 ntdll!RtlEnterCriticalSection+0x46
0143f318 00a65ab3 UnmanagedProductionDebuggingEngine!CCriticalSection::Lock(void)+0x37 [d:"program files"microsoft visual studio .net 2003"vc7"atlmfc"include"afxmt.inl @ 72]
0143f338 771273d0 UnmanagedProductionDebuggingEngine!CPurchaseOrder::Approve(void)+0x63 [d:"unmanagedproductiondebuggingengine"purchaseorder.cpp @ 42]
From these call stacks, you can clearly see that the Reject method is waiting on a critical section called m_lockLineItems that the Approve method has acquired. The Approve method is also waiting on the critical section m_lockObjectStatus, which the Reject method has acquired (see Figure 13). Thread 15 is trying to acquire a lock that thread 16 owns and thread 16 is trying to acquire a lock that thread 15 owns. The solution is to make sure all critical sections are acquired in the same order; that is, m_lockLineItems is acquired followed by m_lockObjectStatus. This is a design pattern known as lock hierarchy. You can actually write code to enforce this, such that if you try to take a lock that violates the hierarchy, the application can throw an exception instead of deadlock.
Figure 13 Unmanaged Deadlock Scenario
This example is quite simple. In the real world you may have cycles of locks indirectly with more than two threads deadlocked. Consider thread 1 waiting on thread 2 waiting on thread 3 waiting on thread 1.
Managed Deadlock Application
Finding two deadlocked threads in a managed application can often be done using the SOS !SyncBlk command. Follow the same steps to reproduce the problem as for the unmanaged deadlock application, except use the links "Approve a purchase order" and "Reject a purchase order" in the managed issues section from default.asp. Take a hang mode dump after the deadlock occurs and open the dump file. Use the !SyncBlk command to list all synchronization blocks with locks:
0:000> !syncblk
Loaded Son of Strike data table version 5 from
"D:"WINDOWS"Microsoft.NET"Framework"v1.1.4322"mscorwks.dll"
Index SyncBlock MonitorHeld Recursion Thread ThreadID Object
Waiting
4 0x01726ffc 3 1 0x1761ce8 0x1960 22 0x0596943c
ManagedProductionDebuggingAssembly.LockClass
Waiting threads: 21
5 0x01727028 3 1 0x184e58 0x1534 21 0x05969430
ManagedProductionDebuggingAssembly.LockClass
Waiting threads: 22
The output shows that threads 22 and 21 own a lock on objects of type LockClass. Thread 21 is waiting on 22 and Thread 22 is waiting on 21. Now you can use the ~*e !clrstack command to see a list of managed call stacks for threads 22 and 21 (see Figure 14).
Figure 14 Managed Call Stacks for Deadlocked Threads
Thread 21
ESP EIP
0x0143e9ac 0x7c90eb94 [FRAME: GCFrame]
0x0143ea60 0x7c90eb94 [FRAME: HelperMethodFrame] 0x79404fa0 is not a MethodDesc
0x0143ea8c 0x07c00136 [DEFAULT] [hasThis] Void ManagedProductionDebuggingAssembly.PurchaseOrder.Approve()
at [+0x3e] [+0x22] d:"managedproductiondebuggingassembly"purchaseorder.cs:16707566
...
Thread 22
ESP EIP
0x0147e9ac 0x7c90eb94 [FRAME: GCFrame]
0x0147ea60 0x7c90eb94 [FRAME: HelperMethodFrame] 0x79404fa0 is not a MethodDesc
0x0147ea8c 0x07c001bd [DEFAULT] [hasThis] Void ManagedProductionDebuggingAssembly.PurchaseOrder.Reject()
at [+0x3d] [+0x22] d:"managedproductiondebuggingassembly"purchaseorder.cs:16707566
...
In Figure 14, there are two instances of LockClass within the PurchaseOrder object, one for each of the locked objects. To identify which lock object is being waited on in thread 22, you need to dump the contents of the lock object. You can use !DumpObj 0x0596943c followed by !DumpObj 0x05969404 to dump the contents of the lockName field within the LockClass (see Figure 15).
Figure 15 Value of Lock Name
0:000> !DumpObj 0x05969404
Name: System.String
MethodTable 0x79b8db58
EEClass 0x79b8dea4
Size 44(0x2c) bytes
GC Generation: 0
mdToken: 0x0200000f (d:"windows"microsoft.net"framework"v1.1.4322"mscorlib.dll)
String: objectStatus
FieldDesc*: 0x79b8df08
MT Field Offset Type Attr Value Name
0x79b8db58 0x4000013 0x4 System.Int32 instance 13 m_arrayLength
0x79b8db58 0x4000014 0x8 System.Int32 instance 12 m_stringLength
0x79b8db58 0x4000015 0xc System.Char instance 0x6f m_firstChar
0x79b8db58 0x4000016 0 CLASS shared static Empty
>> Domain:Value 0x001676f0:0x058f126c <<
0x79b8db58 0x4000017 0x4 CLASS shared static WhitespaceChars
>> Domain:Value 0x001676f0:0x058f1280 <<
If you review the lock for thread 21 you will see it acquired the lineItems lock. Now focus on these locks in both the Approve and Reject methods in the PurchaseOrder class. The order the locks are acquired should be changed so they are both acquired in the same order in both methods.
Crashing
The most common cause of a crash in unmanaged apps is an access violation caused by illegal reads and writes of memory. If ADPlus is run in crash mode, a full dump will be created which can then be analyzed using the same techniques I discussed for a first-chance exception.
Although managed applications can call unmanaged code through either COM interop or platform invoke, second-chance exceptions that cause the application to crash rarely occur because access violations are converted into managed exceptions. In this case, the !dumpstack command can prove very useful to show a call stack with both managed and unmanaged calls.
Conclusion
This article has discussed the importance of postmortem analysis of production issues and its utility when using the dump files and WinDBG. A methodical approach to any issues discovered via dump files should be able to isolate the cause of most issues that are difficult or impossible to reproduce in-house. I suggest you walk through the examples using the download available for this article to familiarize yourself with the tools, and then apply these same techniques to the next production issue you look at that is difficult to reproduce. Once you start creating dumps, you will never look back!
Matt Adamson is a senior software engineer at Tranmit plc where he designs and develops n-tier applications using C# and C++. You can reach him at adamson_matthew@hotmail.com and mattadamson.blogspot.com.
Code download available at: Debugging.exe (194 KB)
Browse the Code Online

