
数据仓库ETL搭建
数据仓库ETL搭建
一、 数据抽取
数据源是指存储数据的源头,包括结构化数据、半结构化数据、非结构化数据等。
1.1结构化数据
可以采用直连数据库的方式进行抽取,一般采用JDBC(Java Database Connectivity)。这种方式的优点是数据抽取效率高,但会增加数据库负载,因此需要控制抽取时间,一般企业选择在凌晨进行结构化数据的抽取。另外,也可以通过数据库日志方式进行抽取,这种方式对数据库产生的影响极小,但需要解析日志。
1.2半结构化数据和非结构化数据
一般进行抽取所采用的方式为监听文件变动。这种方式的优点是比较灵活,可以实时抽取变动的内容,但需要解决增量抽取和数据格式转换等问题。
1.3数据抽取方式
在抽取数据时,一般会采以下两种方式:
(1)全量同步:将全部数据抽取到目标系统中,一般用于数据初始化装载。
(2)增量同步:检测数据变动,只抽取发生变动的数据,一般用于数据更新。
二、数据转换
2.1数据转换
数据转换主要是将抽取的数据进行标准化处理,使其符合目标系统和业务需求。
对于结构化数据,转换的逻辑相对简单,主要是对表结构和字段进行标准化处理。
对于半结构化数据和非结构化数据,转换的逻辑更为复杂,需要进行文本解析、数据提取、数据关联和数据格式转换等操作。
在数据转换过程中,需要根据数据源的不同,针对性地选择合适的转换工具,例如数据仓库ETL(Extract-Transform-Load)工具、ELT(Extract-Load-Transform)工具、自定义脚本等。同时,还需要根据业务需求和目标系统的要求,对转换规则进行定义和调整,以保证转换后的数据符合目标系统的要求。
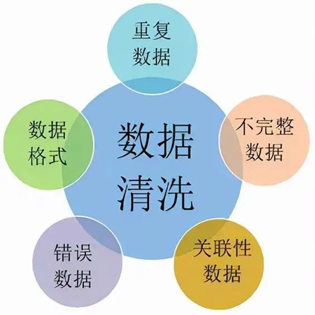
2.2数据清洗
数据清洗是数据转换的一个子集,主要是对原始数据进行清理、过滤、去重、处理异常数据等操作,以消除数据中的问题,如数据重复、二义性、不完整、违反业务或逻辑规则等,保证数据的准确性和稳定性。
三、数据加载
数据加载主要是将清洗、转换后的数据导入到目标数据源中,为企业业务提供数据支持。数据加载的方式有两种:全量加载和增量加载。
(1)全量加载是将所有数据都导入目标数据源中,适用于首次加载或者数据量较小的情况。
(2)增量加载是只将新增或修改的数据导入目标数据源中,以节省加载时间和系统资源,适用于数据量较大的情况。
数据加载可以采用多种工具和方式,如数据仓库ETL工具、手动编写的SQL脚本、程序编写等。其中数据仓库ETL工具是最常用的工具之一,能够提供可视化的操作界面和强大的处理能力,可大幅减少开发和维护工作量。
数据加载时,需要注意数据类型、长度、格式等问题,保证数据的完整性和准确性。同时,也要根据业务需求和目标系统的要求,对数据进行拆分、合并、计算等操作,使之符合业务需求和目标系统的要求。
四、数据仓库ETL工具推荐
根据数据源不同,数据仓库ETL工具可分为结构化数据ETL工具和非结构化/半结构化数据ETL工具。
4.1结构化数据ETL工具
4.1.1Sqoop
大数据领域很常见的一种ETL工具,主要职责是把结构化数据库提供JDBC连接上去之后进行数据抽取,使用并发处理的形式批量导入到大数据的数据仓库中。缺点是对国外的主流关系型数据库支持性更好,而且2.X版本改造后性能下降。
4.1.2Kettle
一个传统的可视化ETL工具,开源免费。缺点是面对特别复杂的业务逻辑,受制于组件的使用情况。
4.1.3Datastage
IBM公司开发的一款ETL工具,具有良好的跨平台性和数据集成能力,提供了可视化的ETL操作界面。缺点是价格远高于其他的ETL工具,而且需要占用较高的系统资源和硬盘空间。
4.1.4Informatica
一款易于配置和管理,能够快速实现ETL任务的ETL工具。缺点和Flume一样,价格高,占用空间大。
4.1.5Kafka
一个分布式流处理平台,也可以用作ETL工具,具有高吞吐量和低延迟性,但是开发和使用成本较高。而且Kafka的使用场景主要是数据流处理领域,不适合复杂的数据清洗和转换操作
4.2非结构化/半结构化数据ETL工具
4.2.1Flume
支持数据监控,在大数据平台上部署简单,亿级以上大数据同步性能较好。缺点是没有可视化界面,只能通过后台命令操作,并且不支持扩展开发,功能少,不支持数据清洗处理。
4.2.2FineDataLink
帆软推出的一款可视化ETL工具,具有ETL和ELT两种数据处理方式,操作简单,功能丰富,支持三十多种格式和结构的异构数据源。
4.2.3Logstash
一个开源的ETL工具,主要用于数据采集和转换。支持插件式架构、多个数据格式和编码。缺点是存在性能问题,不适合处理大量数据。而且配置复杂,不易于维护。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号