05-评分决策模型
5.评分决策模型
模型是策略流程中非常重要的一个环节:可以直接根据评分卡分数拒绝掉一部分客户,或着根据分数走不同的审批流程、使用不同的额度策略。
那么问题就在于,这个划分的切点到底应该定在哪里?到底违约概率高到什么程度的客户需要走人工电核?这个问题,可不是等频或等距切分就可以简单解决,下面介绍三种量化的方法。
5.1违约率&通过率
通过违约率和通过率切分可以说是最简单方法了,但是前提是已经有一个确定好的违约率or通过率。比如说,希望会有30%的客户通过,那就可以找全量样本(需要是无偏的)的分数30%分位数的水平,作为一个切分标准;或者说希望违约概率在5%以上的样本直接拒绝,那就寻找5%违约概率对应的分值即可。
5.2 KS值
KS(Kolmogorov-Smirnov)值衡量的是好坏样本累计分部之间的差值。好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。
KS的计算步骤如下:
(1)按照模型的结果对每个账户进行打分;
(2)所有账户按照评分排序,从小到大分为10组(或20组)
(3)计算每个评分区间的好坏账户数。
(4)计算每个评分区间的累计好账户数占总好账户数比率(good%)和累计坏账户数占总坏账户数比率(bad%)。
(5)计算每个评分区间累计坏账户占比与累计好账户占比差的绝对值(累计bad%-累计good%),然后对这些绝对值取最大值即得此评分模型的K-S值。
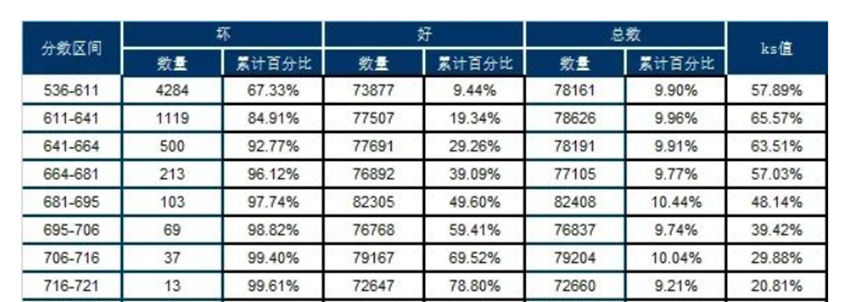
如上图所示,模型的KS值为65.57。按照KS值的算法,分组分的越多,KS值越大,最大的时候是将每一个账户当作一个分组。
模型的KS值有一些行业内的规范,一般要达到20以上才是一个可用的模型,但就效果来讲,KS值是越高越好。然而,过高又使人怀疑是否有使用未来变量的嫌疑,着实需要注意。
5.3 F-score
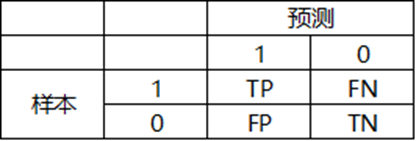
模型决策的过程通常是精准率和召回率的权衡,其中精准率precision = TP / (TP + FP),即被判定为坏中实际为坏的比例;召回率recall = TP / (TP + FN),即有多少坏样本被判断为坏样本,简单点说就是累计坏样本率。
而F-score,就是一个综合考虑了精准率和召回率的指标,是它们的加权调和平均值:
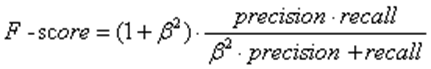
其中β是一个用于调整精准率和召回率权重的指标,在下面的例子中我们取β=1,认为两者权重是相等的。

可以看到在600分的时候,F-score取到了最大值,意味着这是在该衡量标准下最有效的切分点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号