Tesseract-ocr 安装与使用
Tesseract(识别引擎),一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
Tesseract-ocr安装很容易,在网上找到下载地址直接下载安装就可以,安装过程中需要 注意的是语言模块(根据自己的需要选择需要安装的语言包,建议安装中文简体和中文繁体),注意记住自己安装的路径
安装完成之后需要配置环境变量,配置完环境变量之后可以在cmd命令行中输入tesseract验证Tesseract-ocr能否使用。
除了需要配置Tesseract-ocr文件的环境变量外,还需要配置Tesseract-ocr文件下的tessdata(语言包)的环境变量。
像下面这样就代表安装成功,并可以使用了。

将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入
tesseract test.png output_1 –l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng(英语)。
原有图片

运行效果如下:

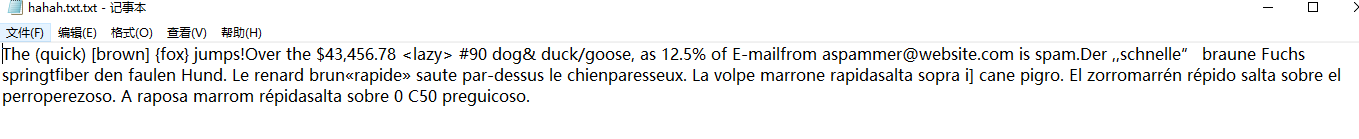
接下来是在python环境中使用Tesseract-ocr
需要安装PIL包和Pillow包以及pytesseract模块
安装完pytesseract模块后,找到该模块,在pytesseract.py文件中修改以下字段为你的Tesseract-OCR文件下的tesseract.exe可执行文件。
tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
错误:pytesseract.pytesseract.TesseractError: (1, 'Error opening data file \\Program Files\\Tesseract-OCR\\tessdata/eng.traineddata')
在py文件中指定tessdata_dir
testdata_dir_config = '--tessdata-dir "C:\\Program Files (x86)\\Tesseract-OCR\\tessdata"' textCode = pytesseract.image_to_string(img, config=testdata_dir_config)
问题解决
出现这个报错
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
修改pytesseract.py文件里的tesseract_cmd
tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
问题解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号