【面试】常见排序与搜索算法总结
00. 十大经典排序算法
排序算法分内部排序与外部排序,内部排序是数据记录在内存中进行排序,外部排序为排序数较大而需访问外存。常见的内部排序算法有:冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、计数排序、桶排序、基数排序等。概括如下:
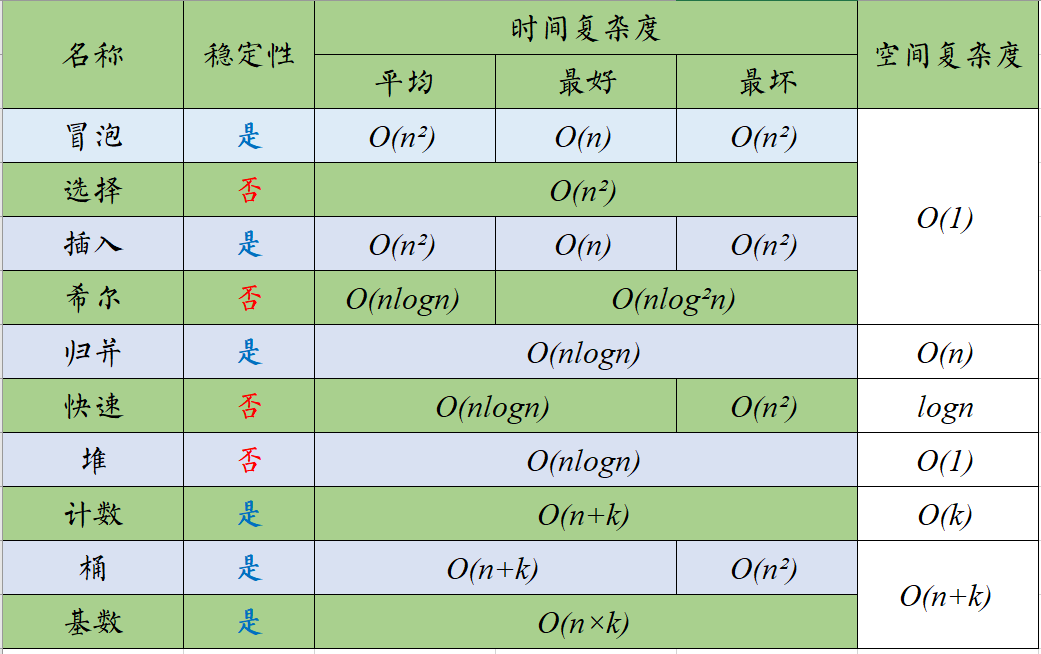
排序算法的稳定性
稳定性:稳定排序算法会让原本有相等键值的纪录维持相对次序。也就是如果一个排序算法是稳定的,当有两个相等键值的纪录R和S,且在原本的列表中R出现在S之前,在排序过的列表中R也将会是在S之前。
当相等的元素是无法分辨的,比如像是整数,稳定性并不是一个问题。然而,假设以下的数对将要以他们的第一个数字来排序。
(4, 1) (3, 1) (3, 7)(5, 6)
在这个状况下,有可能产生两种不同的结果,一个是让相等键值的纪录维持相对的次序,而另外一个则没有:
(3, 1) (3, 7) (4, 1) (5, 6) (维持次序)
(3, 7) (3, 1) (4, 1) (5, 6) (次序被改变)
1. 稳定排序
冒泡排序、插入排序、归并排序
2. 不稳定排序
选择排序、快速排序、希尔排序、堆排序
01. 冒泡排序
重复遍历要排序的数列,一次比较两个元素,如果顺序错误则交换。
算法步骤
- 比较相邻元素。若第一个比第二个大,则交换;
- 对每一对相邻元素做上述工作,从开始第一对至最后一对。结果最后一个为最大数,之后不再需要对比。
- 针对剩余元素重复上述步骤。
- 持续对越来越少的元素重复上述步骤,知道无数字比较。
动画演示

情况对比
- 最好情况:输入的数据为正序时 ,只需要冒泡一次即可
- 最坏情况:输入的数据为反序时
代码实现
def bubbleSort(arr):
for i in range(1, len(arr)):
for j in range(len(arr)-i):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
02. 选择排序
算法步骤
- 在未排序数组中搜索最小(大)元素,存放在排序序列的起始位置
- 从剩余未排序元素中继续搜索最小(大)元素,存档在上述元素后
- 重复第二步骤,直至所有元素均排序完毕
动画演示
代码实现
def selectionSort(arr):
for i in range(len(arr) - 1):
minIndex = i
for j in range(i+1, len(arr)):
if arr[j] < arr[minIndex]:
minIndex = j
if i != minIndex:
arr[i], arr[minIndex] = arr[minIndex], arr[i]
return arr
03. 插入排序
算法步骤
- 将第一待排序数组首元素看作一个有序序列,把第二个元素到最后一个元素当作未排序序列
- 从头至尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置
动画演示

代码实现
def insertionSort(arr):
# 从第二个位置,即下标为1的元素开始向前插入
for i in range(1, len(arr)):
for j in range(i, 0, -1):
# 从第i个元素开始向前比较,如果小于前一个元素,交换位置
if arr[j] < arr[j-1]:
arr[j], arr[j-1] = arr[j], arr[j-1]
return arr
情况对比
- 最好情况:输入的数据为正序时 ,只需要一次循环对比即可
- 最坏情况:输入的数据为反序时
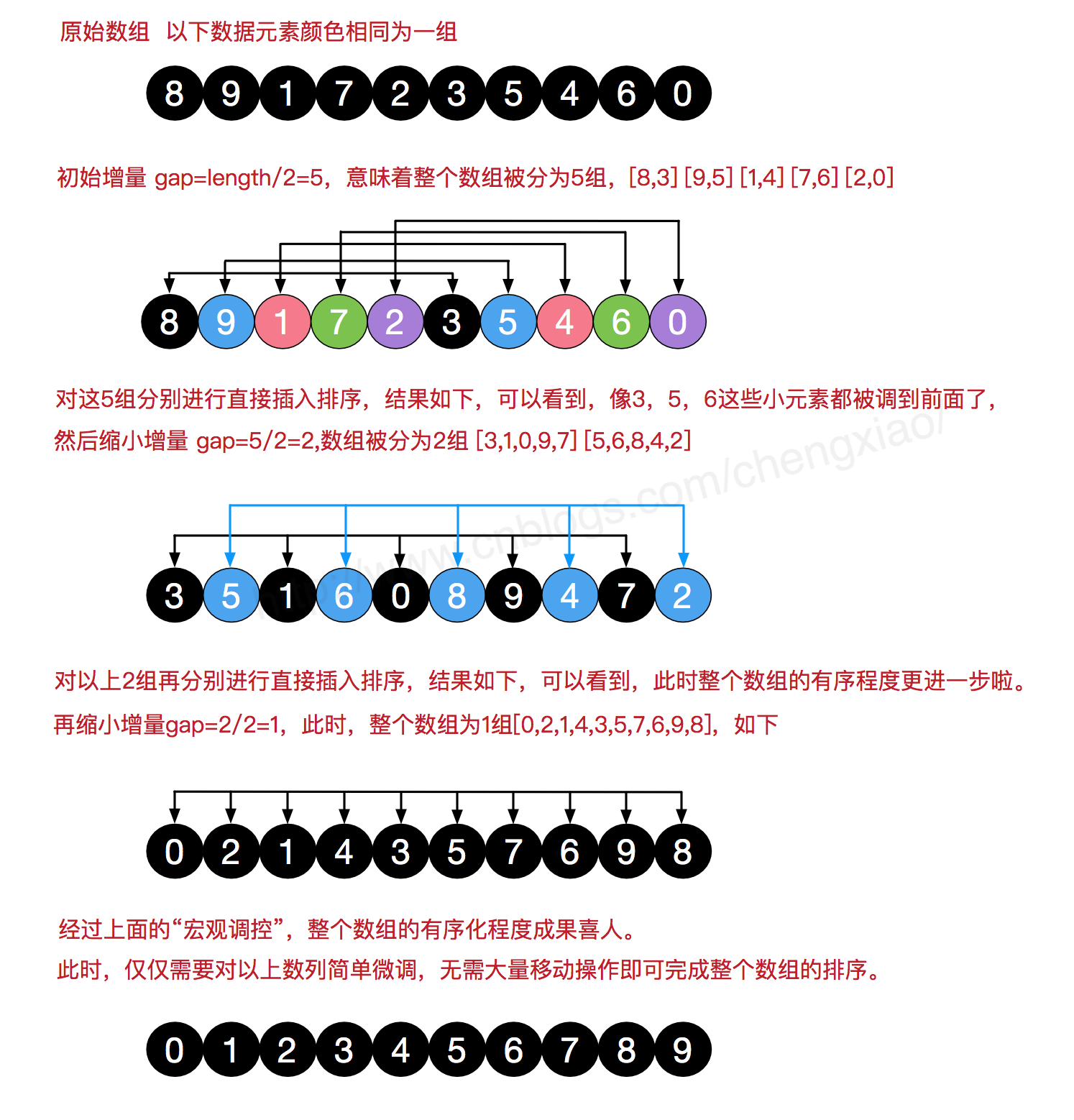
04. 希尔排序
- 实质: 分组插入排序
算法步骤
代码实现
def shell_sort(alist):
n = len(alist)
# 初始步长
gap = n // 2
while gap > 0:
# 按步长进行插入排序
for j in range(gap, n):
# 插入排序
while j >= gap and alist[j - gap] > alist[j]:
alist[j - gap], alist[j] = alist[j], alist[j - gap]
j -= gap # 单列中从右向左插入排序
# 得到新的步长
gap = gap // 2
时间复杂度
最坏时间复杂度:
05. 归并排序
算法步骤
先递归分解数组,再合并数组。比较两个数组的最前面的数,谁小就先取谁。取之后响应的指针向后移动一位,然后再比较,直至一个数组为空。最后,将另一个数组的剩余部分复制过来。
动画演示
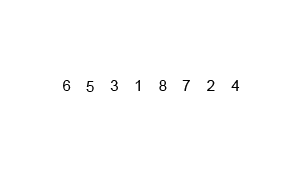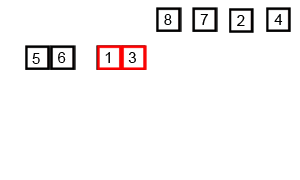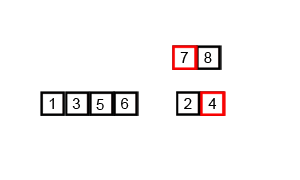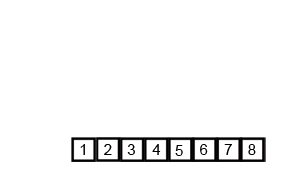
代码实现
def mergeSort(arr):
if len(arr) <= 1:
return arr
# 二分分解
num = len(arr) // 2
left = mergeSort(arr[:num])
right = mergeSort(arr[num:])
# 合并
return merge(left, right)
def merge(left, right):
#left与right的下标指针
l, r = 0, 0
res = []
while l < len(left) and r < len(right):
if left[l] < right[r]:
res.append(left[l])
l += 1
else:
res.append(right[r])
r += 1
# 最后,将另一个数组的剩余部分复制过来,没有则为空,如上图动画。
res += left[l:]
res += right[r:]
return res
06. 快速排序
算法步骤
- 选择arr中任意元素pivot为基准
- 将小于基准的元素移到左边,大于基准的元素移到右边
- arr被pivot分成两部分,继续对剩下的两部分做同样处理
- 直到所有元素不在需要上述步骤
动画演示

代码实现
def quickSort(arr, start, end):
if start >= end:
return
# 设定起始元素为要寻找位置的基准元素
pivot = arr[start]
low, high = start, end
while low < high:
# 如果low与high未重合,high指向的元素不比基准元素小,则high向左移动
while low < high and arr[high] >= pivot:
high -= 1
# 将high指向的元素放到low的位置上
arr[low] = arr[high]
# 如果low与high未重合,low指向的元素比基准元素小,则low向右移动
while low < high and arr[low] < pivot:
low += 1
# 将low指向的元素放到high的位置上
arr[high] = arr[low]
arr[low] = pivot
# 不用存储元素,先递归完左边,再递归右边,实际上操作的还是arr
quickSort(arr, start, low-1)
quickSort(arr, low+1, end)
quickSort(arr, 0, len(arr)-1)
空间复杂度
首先就地快速排序使用的空间是O(1)的,也就是个常数级;而真正消耗空间的就是递归调用了,因为每次递归就要保持一些数据;
最优的情况下空间复杂度为: ;每一次都平分数组的情况
最差的情况下空间复杂度为: ;退化为冒泡排序的情况
时间复杂度
- 最优:每一次取到的元素都刚好平分整个数组
- 最差:每一次取到的元素就是数组中最小/最大的(冒泡排序)
07. 堆排序
-
大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
-
小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;


大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
算法步骤
- 首先将待排序的数组构造出一个大根堆
- 取出这个大根堆的堆顶节点(最大值),与堆的最下最右的元素进行交换,然后把剩下的元素再构造出一个大根堆
- 重复第二步,直到这个大根堆的长度为1,此时完成排序。
- 构造初始堆
- 目的:构建一个完全二叉树,保证所有的父结点都比它的孩子结点数值大
a. 假设给定无序序列结构

b. 此时从最后一个非叶子结点开始,从左至右,从下至上进行调整


交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。

此时,就将一个无需序列构造成了一个大顶堆。
- 每次交换第一个和最后一个元素,输出(去掉)最后一个元素(最大值),然后把剩下元素重新调整为大根堆




代码实现
def heapSort(array):
# 遍历非叶子节点,建立堆结构数组
# 其中,len(array)//2 - 1 为最后一个非叶子节点的父节点
for i in range(len(array) // 2 - 1, -1, -1):
adjustHeap(array, i, len(array))
# 堆积树建立完成,开始排序
for j in range(len(array) - 1, 0, -1):
# 一开始最大元素是[0],然后被换到最后一个
# 从n-0,不断和[0]元素交换,重新堆排序(既把第2、3..n大的翻转到最上面)
array[0], array[j] = array[j], array[0]
adjustHeap(array, 0, j)
def adjustHeap(array, i, length):
# 对第i号进行堆调整
# 获取非叶子节点的数据
temp = array[i]
# 非叶子节点的左子节点
k = 2 * i + 1
# 遍历对比k后面的节点,把temp放入合理位置
while k < length:
# k + 1 < length 确保有左右节点才比较
if k + 1 < length and array[k] < array[k + 1]: # 如果左子节点比右子节点小,k就切换到右子节点
k += 1
# 如果子节点有更大的
if array[k] > temp:
# 父节点替换为更大的
array[i] = array[k]
# 记录当前最大点位置
i = k
else: # 直接打断,因为堆特点,后面层的更不满足
break
# k切换到下一个左子节点
k = 2 * k + 1
# 此时i是空位,i上层的都比temp大,temp放到这里
array[i] = temp
算法稳定性
堆排序是一种不稳定的排序方法。
在堆的调整过程中,关键字进行比较和交换所走的是该结点到叶子结点的一条路径,,因此对于相同的关键字就可能出现排在后面的关键字被交换到前面来的情况。
时间复杂度
堆的存储表示是顺序的。因为堆所对应的二叉树为完全二叉树,而完全二叉树通常采用顺序存储方式。
当想得到一个序列中第k个最小的元素之前的部分排序序列,最好采用堆排序。
因为堆排序的时间复杂度是,若,则可得到的时间复杂度为。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程