机器学习应用案例分享
1、聚类-Kmeans算法应用
观察学习与生活中可以用K均值解决的问题,从数据-模型训练-测试-预测完整地完成一个应用案例。
这是从网上摘录的数据--地址:https://www.scoregg.com/data/player?tournamentID=169
数据背景:2020英雄联盟季中杯挑战赛参赛选手的数据
目的:分析选手数据,分类为适合的位置(上单、打野、中单、ADC、辅助)
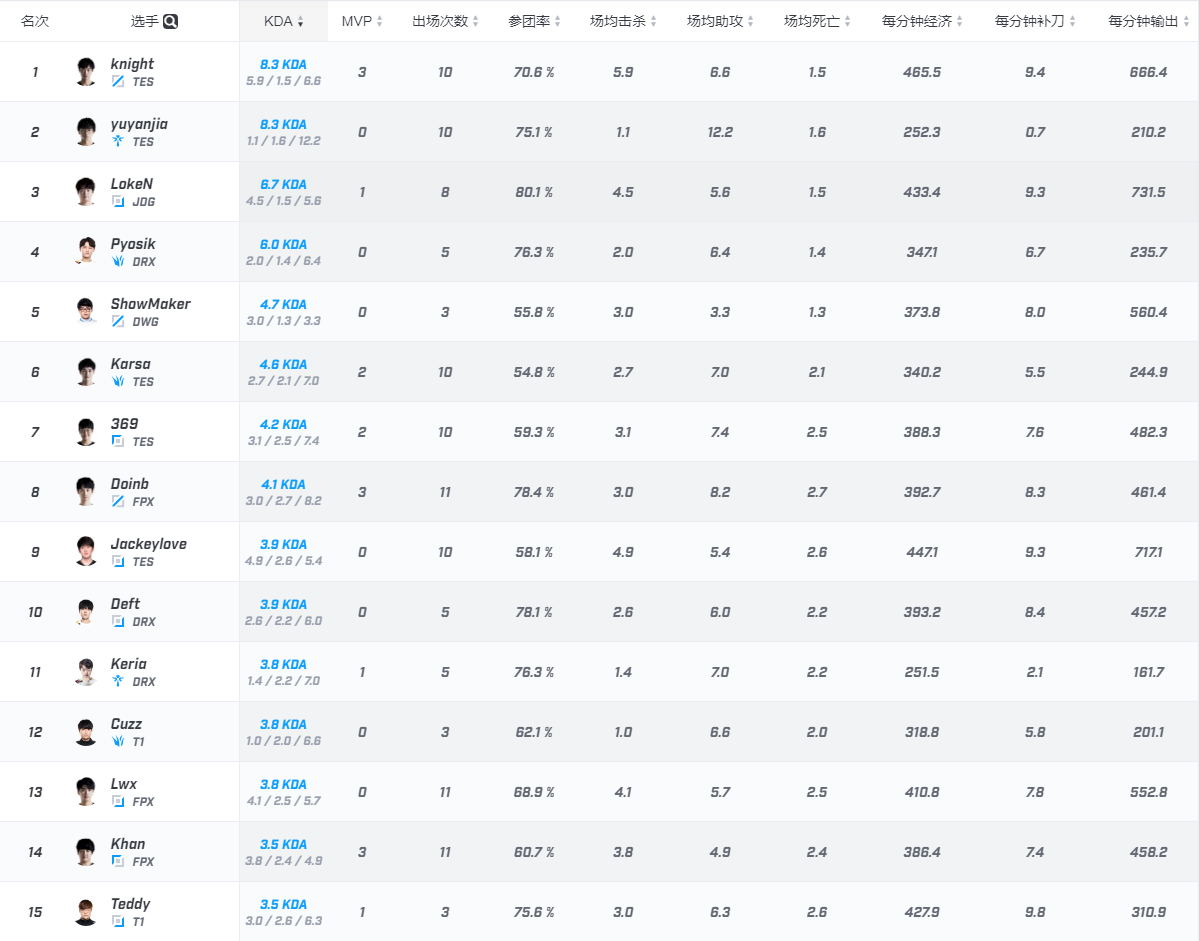
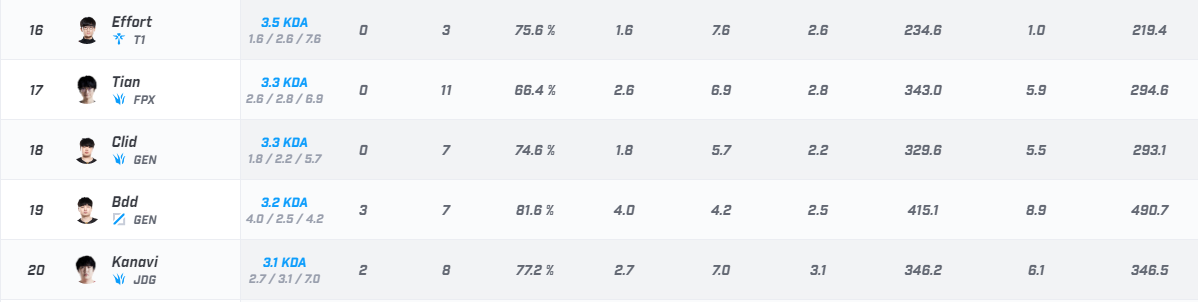
摘录为xlsx文件如下:
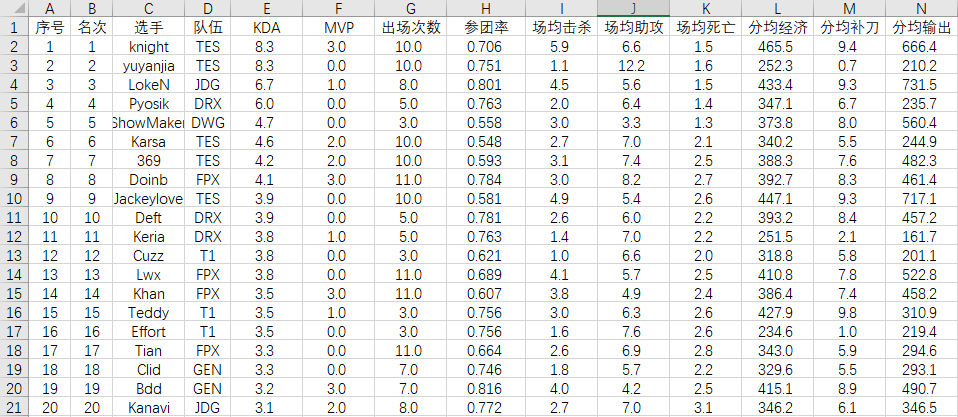
(1)读取数据并预处理
import pandas as pd #1.读取处理数据 #读取数据 data=pd.read_excel('C:/Users/Hoi/PycharmProjects/work0/机器学习期末作业/2020英雄联盟季中杯挑战赛选手数据.xlsx') #查看空值 print(data.isnull().any()) #数据预处理,把中文列和序号列删除 data=data.drop("序号",axis=1) data=data.drop("选手",axis=1) data=data.drop("队伍",axis=1) print(data)
(2)构建数据模型
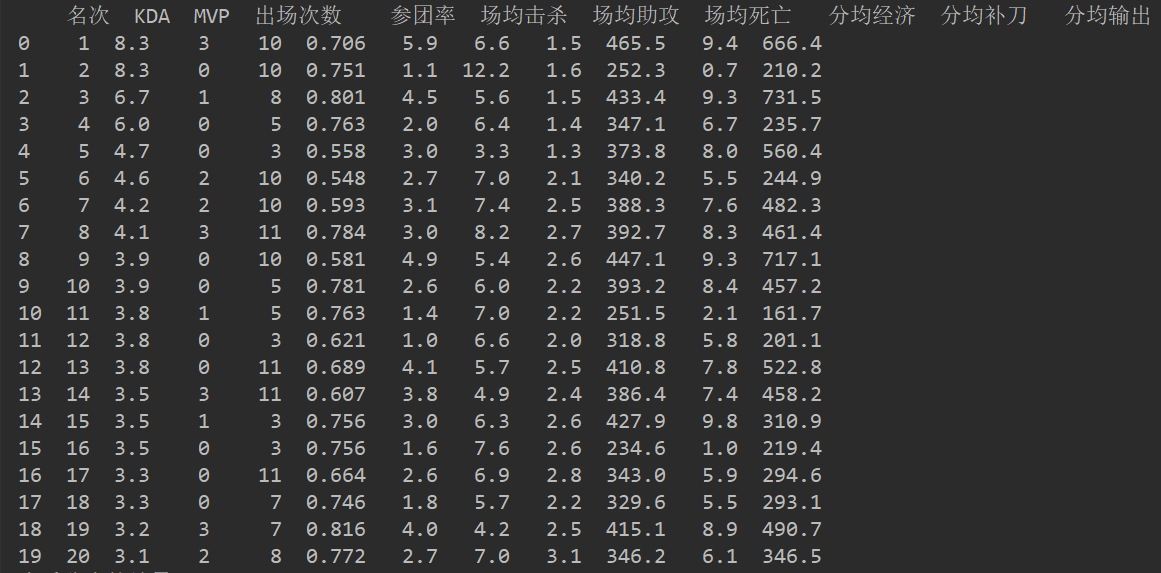
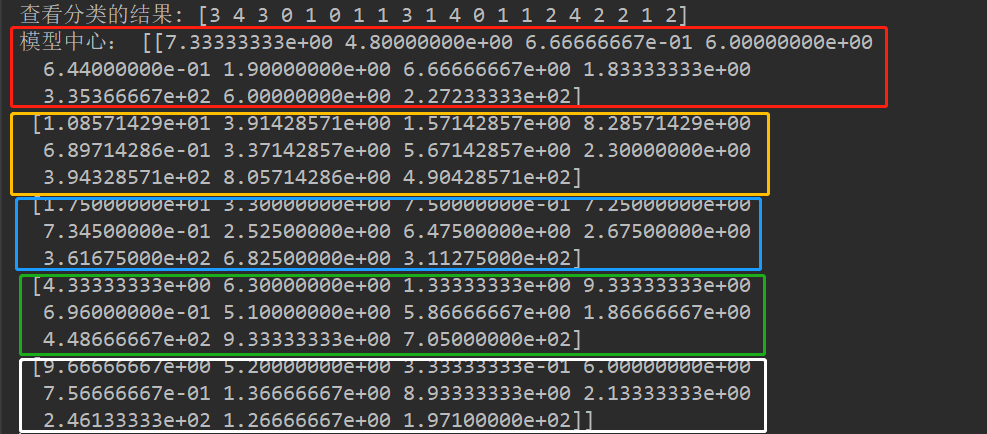
#2.构建数据模型 from sklearn.cluster import KMeans #分类 model=KMeans(n_clusters=5) #模型匹配训练 model.fit(data) #分类结果 pre=model.predict(data) print("查看分类的结果:",pre) #查看聚类中心 print("模型中心:",model.cluster_centers_) #新建序列lol lol = pd.Series(['上单','打野','中单','射手','辅助']) #统计每个类别的个数,找出聚类中心,连接表格,得到聚类中心对应分类的个数 end = pd.concat([lol,pd.Series(model.labels_).value_counts(),pd.DataFrame(model.cluster_centers_)], axis = 1) #重命名 end.columns =['选手分类'] +['分类个数']+ list(data.columns) #保存 end.to_csv("./选手分类表格.csv",encoding='gbk')

(3)分类可视化
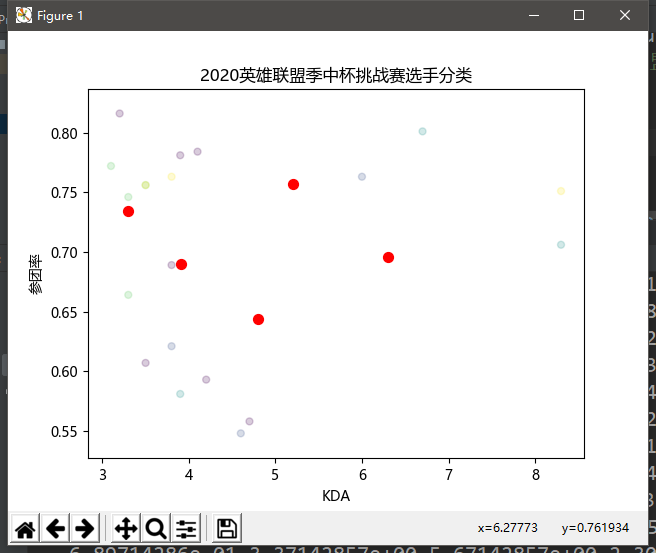
#3.分类可视化 import matplotlib.pyplot as plt import matplotlib as mpl #制作散点图 mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.scatter(data.values[:,1],data.values[:,4],c=pre,s=25,alpha=0.2) #画出用户分类点 plt.scatter(model.cluster_centers_[:,1], model.cluster_centers_[:,4], s=50,color='red') #画出聚类中心 plt.title("2020英雄联盟季中杯挑战赛选手分类") plt.xlabel("KDA") plt.ylabel("参团率") plt.show()
五个红点是数据的聚类中心作为参考值
(4)预测选手
选择预测的选手,预测归为哪一类

#4、预测 test=pd.DataFrame([[23,2.8,0,5,0.509,2,3.6,2,392,8.4,351]])#输入三组数据查看属于哪一类顾客 print("选手预测分类结果为:",model.predict(test))#输出分类结果

2、分类-朴素贝叶斯-中文文本分类
2.1.数据集:
- THUCNews中文文本数据集 http://thuctc.thunlp.org/
按学号未位下载相应数据集。
147:财经、彩票、房产、股票、
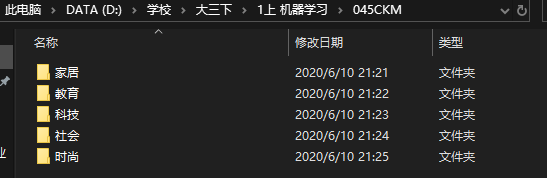
258:家居、教育、科技、社会、时尚、
0369:时政、体育、星座、游戏、娱乐
- 也可以自主编写爬虫程序,爬取一些分类文本数据,如 新浪新闻RSS订阅 http://rss.sina.com.cn/news/
四类以上
2.2.文本预处理
遍历每个个文件夹下的每个文本文件。
各种获取文件,写文件。
除去噪声,如格式转换,去掉符号,整体规范化。
2.3. jieba分词
下载、导入词库
增加专业词汇
维护自定义词库
可以用jieba.add_word('word')增加词,用jieba.load_userdict('wordDict.txt')导入词库。
使用jieba分词,将中文文本进行切割。
中文分词就是将一句话拆分为各个词语,因为中文分词在不同的语境中歧义较大,所以分词极其重要。
2.4.去掉停用词:维护停用词表
import os import jieba path = r'D:\学校\大三下\1上 机器学习\045CKM' with open(r'D:\学校\大三下\1上 机器学习\hit_stopwords.txt', encoding='utf-8') as f: stopwords = f.read().split('\n') def processing(tokens): tokens = "".join([char for char in tokens if char.isalpha()]) # 去掉非字母汉字的字符 tokens = [token for token in jieba.cut(tokens, cut_all=True) if len(token) >= 2] # 结巴分词 tokens = " ".join([token for token in tokens if token not in stopwords]) # 去掉停用词 return tokens tokenList = [] targetList = [] for root, dirs, files in os.walk(path): # 地址 print(root) # 子目录 print(dirs) # 详细文件名 print(files) for f in files: # 地址拼接 filePath = os.path.join(root, f) with open(filePath, encoding='utf-8') as f: content = f.read() # 获取类别标签 target = filePath.split('\\')[-2] targetList.append(target) tokenList.append(processing(content)) print(tokenList)
2.5.训练集与测试集划分
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.metrics import classification_report x_train, x_test, y_train, y_test = train_test_split(tokenList, targetList, test_size=0.3, stratify=targetList)
2.6.对处理之后的文本开始用TF-IDF算法进行单词权值的计算
vectorizer = TfidfVectorizer() X_train = vectorizer.fit_transform(x_train) X_test = vectorizer.transform(x_test) from sklearn.naive_bayes import MultinomialNB
2.7.贝叶斯预测种类
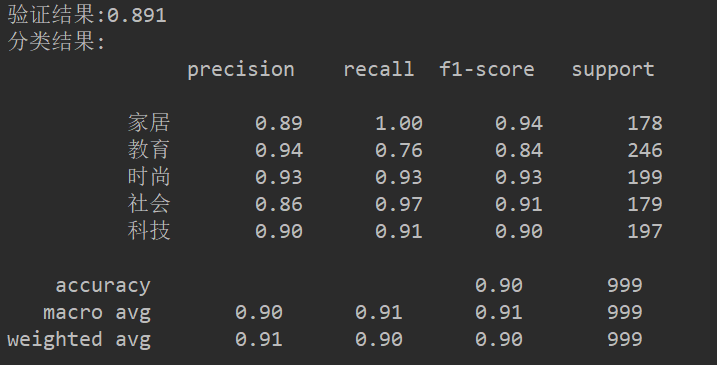
mnb = MultinomialNB() module = mnb.fit(X_train, y_train) y_predict = module.predict(X_test) scores = cross_val_score(mnb, X_test, y_test, cv=5) print("验证结果:%.3f" % scores.mean()) print("分类结果:\n", classification_report(y_predict, y_test))
2.8.模型评价
import collections testCount = collections.Counter(y_test) predCount = collections.Counter(y_predict) print('实际:', testCount, '\n', '预测', predCount)
2.9.新文本类别预测
nameList = list(testCount.keys()) testList = list(testCount.values()) predictList = list(predCount.values()) x = list(range(len(nameList))) print("类别:", nameList, '\n', "实际:", testList, '\n', "预测:", predictList)


